







原文链接:https://arxiv.org/abs/2403.19104
简介:3D目标检测任务中,目前性能最优的传感器配置为激光雷达+摄像头(LC),但激光雷达的成本较高。毫米波雷达与摄像头(CR)目前已被广泛部署在车辆上,但其性能不及LC。本文提出摄像头-雷达知识蒸馏(CRKD)以减小LC与CR的性能差距。使用BEV作为共享特征空间,提出4种蒸馏损失,进行知识蒸馏。nuScenes数据集上的实验证明了本文方法的有效性。
0. 概述
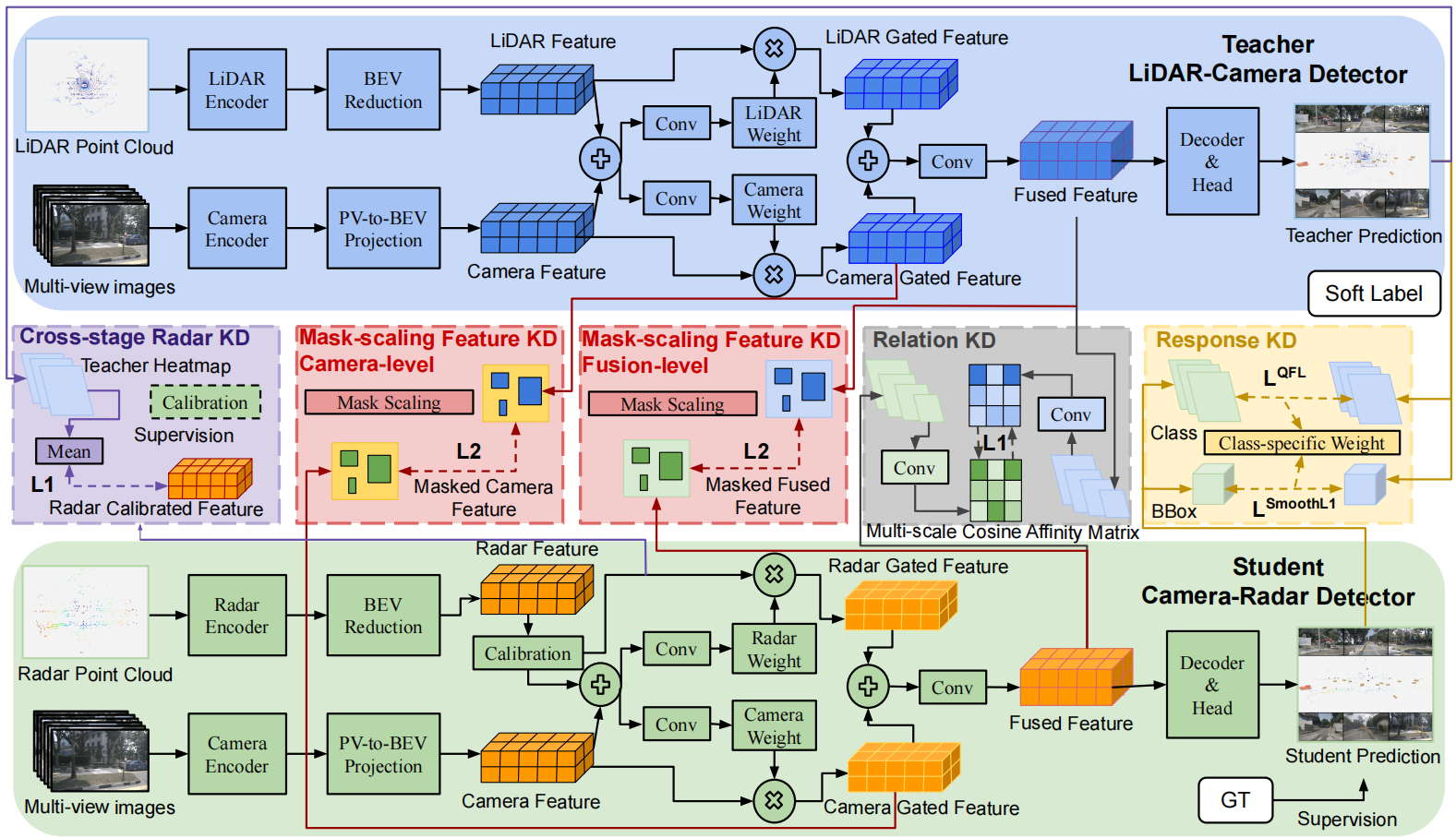
LC模型为教师模型,CR模型为学生模型,二者有相似的基于BEV的编码器-解码器结构(BEVFusion)。
本文的知识蒸馏模块包括:带有基于学习的校准模块的跨阶段雷达蒸馏,学习场景级的物体分布。掩膜缩放的特征蒸馏用于前景区域的特征模仿,并考虑视图变换的不精确性。关系蒸馏用于保留场景级的几何关系一致性。响应蒸馏利用逐类别的损失权重,以更好地利用CR模型的动态物体捕捉能力。
1. 模型结构细化
本文在BEVFusion的基础上添加门控网络,以学习单模态特征的注意力权重,以自适应地融合模态:
F ~ M 1 = F M 1 × σ ( Conv M 1 ( Concat ( F M 1 , F M 2 ) ) ) , F ~ M 2 = F M 2 × σ ( Conv M 2 ( Concat ( F M 1 , F M 2 ) ) ) \tilde F_{M_1}=F_{M_1}\times\sigma(\text{Conv}_{M_1}(\text{Concat}(F_{M_1},F_{M_2}))),\\ \tilde F_{M_2}=F_{M_2}\times\sigma(\text{Conv}_{M_2}(\text{Concat}(F_{M_1},F_{M_2}))) F~M1=FM1×σ(ConvM1(Concat(FM1,FM2))),F~M2=FM2×σ(ConvM2(Concat(FM1,FM2)))
其中 F ~ M i \tilde F_{M_i} F~Mi为门控特征, F M i F_{M_i} FMi为视图变换模块的输出特征, σ \sigma σ表示sigmoid函数。各模态的门控特征会通过卷积融合模块进行融合。
门控特征的引入不仅能分别提高师生模型的性能,还能使特征蒸馏更加有效。
记教师模型中的激光雷达特征为 F l T ∈ R C l T × H × W F_l^T\in\mathbb R^{C_l^T\times H\times W} FlT∈RClT×H×W,图像特征为 F c T ∈ R C c T × H × W F_c^T\in\mathbb R^{C_c^T\times H\times W} FcT∈RCcT×H×W;学生模型中的雷达特征为 F r S ∈ R C r S × H × W F_r^S\in\mathbb R^{C_r^S\times H\times W} FrS∈RCrS×H×W,图像特征为 F c S ∈ R C c S × H × W F_c^S\in\mathbb R^{C_c^S\times H\times W} FcS∈RCcS×H×W。师生模型的融合特征分别为 F f T , F f S F_f^T,F_f^S FfT,FfS。实验中, C c T = C c S C_c^T=C_c^S CcT=CcS且 C l T = C r S C_l^T=C_r^S ClT=CrS。
2. 跨阶段雷达蒸馏(CSRD)
由于激光雷达点云和雷达点云的物理意义不同(前者密集,捕捉几何级别的信息;而后者稀疏,可解释为带有速度的、物体级别的信息),直接进行特征模仿可能效果不佳。本文设计雷达特征图到教师模型预测的场景级物体热图 Y T ∈ R K × H × W Y^T\in\mathbb R^{K\times H\times W} YT∈RK×H×W的蒸馏路径( K K K为类别数)。
此外,由于雷达在距离和水平角上的测量有噪声,本文设计校准模块进行噪声补偿。具体来说,将 F r S F_r^S FrS送入卷积网络得到 F ^ r S ∈ R H × W \hat F_r^S\in\mathbb R^{H\times W} F^rS∈RH×W。
事实上,这里所谓的“校准模块”只是作者取的名字,其作用也未必就是噪声补偿。该模块实际上就是小型的BEV编码器。
CSRD损失如下:
L c s r d = 1 H × W ∑ i H ∑ j W ∥ Y ^ i , j T − F ^ τ i , j S ∥ 1 L_{csrd}=\frac1{H\times W}\sum_i^H\sum_j^W\|\hat Y_{i,j}^T-\hat F_{\tau\ i,j}^S\|_1 Lcsrd=H×W1i∑Hj∑W∥Y^i,jT−F^τ i,jS∥1
其中 Y ^ T ∈ R H × W \hat Y^T\in\mathbb R^{H\times W} Y^T∈RH×W为沿 K K K维求取均值后的 σ ( Y T ) \sigma(Y^T) σ(YT)。
3. 掩膜缩放特征蒸馏(MSFD)
由于前景和背景的极度不平衡,在3D目标检测任务中直接进行特征模仿没那么有效。因此,本文建立掩膜 M ∈ R H × W M\in\mathbb R^{H\times W} M∈RH×W,仅在前景区域进行蒸馏。
此外,由于前景区域的边界对蒸馏同样有效,以及物体运动和距离为视图变换施加的挑战,本文将前景区域扩大,以考虑潜在的不对齐。当物体距离在 [ r 1 , r 2 ] [r_1,r_2] [r1,r2]/ [ r 2 , ∞ ) [r_2,\infin) [r2,∞)内,或速度在 [ v 1 , v 2 ] [v_1,v_2] [v1,v2]/ [ v 2 , ∞ ) [v_2,\infin) [v2,∞)内时,掩膜的长宽会分别扩大到 α \alpha α/ β \beta β倍。
MSFD损失为
L m s f d = 1 H × W ∑ i H ∑ j W M i , j ∥ F i , j T − F i , j S ∥ 2 L_{msfd}=\frac1{H\times W}\sum_i^H\sum_j^WM_{i,j}\|F_{i,j}^T-F_{i,j}^S\|_2 Lmsfd=H×W1i∑Hj∑WMi,j∥Fi,jT−Fi,jS∥2
该损失被用于门控图像特征 F ~ c T , F ~ c S \tilde F_c^T,\tilde F_c^S F~cT,F~cS和融合特征 F f T , F f S F_f^T,F_f^S FfT,FfS之间。
4. 关系蒸馏(RelD)
类似MonoDistill,本文为师生模型保留场景中相似的几何关系。
计算亲和度矩阵,描述融合特征图的余弦相似度:
C i , j = F i ⊤ F j ∥ F i ∥ 2 ⋅ ∥ F j ∥ 2 C_{i,j}=\frac{F_i^\top F_j}{\|F_i\|_2\cdot\|F_j\|_2} Ci,j=∥Fi∥2⋅∥Fj∥2Fi⊤Fj
这里的 F i F_i Fi的含义不是很清楚,也许是将特征图拉直(flatten)后,位置 i i i处的特征向量。
场景级信息差异可用 L 1 L_1 L1损失衡量,得到RelD损失:
L r e l d = 1 H × W ∑ i H ∑ j W ∥ C i , j T − C i , j S ∥ 1 L_{reld}=\frac1{H\times W}\sum_i^H\sum_j^W\|C_{i,j}^T-C_{i,j}^S\|_1 Lreld=H×W1i∑Hj∑W∥Ci,jT−Ci,jS∥1
本文对师生模型的融合特征图计算该损失。
为蒸馏多尺度信息,本文使用下采样和卷积块,并计算多尺度RelD损失的均值作为最终损失。
5. 响应蒸馏(RespD)
教师模型的预测可作为学生模型的软标签。软标签和硬标签组合监督学生模型的训练,类似CMKD模型。
由于雷达有速度测量的优势,本文将动态类别的权重 w i w_i wi增大。
RespD损失包含分类损失与边界框回归损失。前者使用质量焦损失(QFL),后者使用SmoothL1损失:
L c l s = ∑ i = 1 K QFL ( P C i T , P C i S ) × w i , L c l s = ∑ i = 1 K SmoothL1 ( P B i T , P B i S ) × w i L_{cls}=\sum_{i=1}^K\text{QFL}(P_{C_i}^T,P_{C_i}^S)\times w_i,\\ L_{cls}=\sum_{i=1}^K\text{SmoothL1}(P_{B_i}^T,P_{B_i}^S)\times w_i Lcls=i=1∑KQFL(PCiT,PCiS)×wi,Lcls=i=1∑KSmoothL1(PBiT,PBiS)×wi
其中 P C i P_{C_i} PCi为第 i i i类的类别预测(分类概率), P B i P_{B_i} PBi为边界框预测。
6. 整体损失函数
整体损失为各蒸馏损失与检测损失的加权和。
总结:看上去本文是把现有的一些知识蒸馏模块进行改进并放到一个模型中;这些模块的泛用性较高,可以直接或略加修改用于其余任务。
















 35
35











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











