






习题6-1P 推导RNN反向传播算法BPTT.

习题6-2 推导公式(6.40)和公式(6.41)中的梯度.

习题6-3 当使用公式(6.50)作为循环神经网络的状态更新公式时, 分析其可能存在梯度爆炸的原因并给出解决方法.

习题6-2P 设计简单RNN模型,分别用Numpy、Pytorch实现反向传播算子,并代入数值测试.
import torch
import numpy as np
class RNNCell:
def __init__(self,weight_ih,weight_hh,bias_ih,bias_hh):
self.weight_ih=weight_ih
self.weight_hh=weight_hh
self.bias_ih=bias_ih
self.bias_hh=bias_hh
self.x_stack=[]
self.dx_list=[]
self.dw_ih_stack=[]
self.dw_hh_stack=[]
self.db_ih_stack=[]
self.db_hh_stack=[]
self.prev_hidden_stack=[]
self.next_hidden_stack=[]
self.prev_dh=None
def __call__(self,x,prev_hidden):
self.x_stack.append(x)
next_h=np.tanh(
np.dot(x,self.weight_ih.T)
+np.dot(prev_hidden,self.weight_hh.T)
+self.bias_ih+self.bias_hh)
self.prev_hidden_stack.append(prev_hidden)
self.next_hidden_stack.append(next_h)
self.prev_dh=np.zeros(next_h.shape)
return next_h
def backward(self,db):
x=self.x_stack.pop()
prev_hidden=self.prev_hidden_stack.pop()
next_hidden=self.next_hidden_stack.pop()
d_tanh=(db+self.prev_dh)*(1-next_hidden**2)
self.prev_dh=np.dot(d_tanh,self.weight_hh)
dx=np.dot(d_tanh,self.weight_ih)
self.dx_list.insert(0,dx)
dw_ih=np.dot(d_tanh.T,x)
self.dw_ih_stack.append(dw_ih)
dw_hh=np.dot(d_tanh.T,prev_hidden)
self.dw_hh_stack.append(dw_hh)
self.db_ih_stack.append(d_tanh)
self.db_hh_stack.append(d_tanh)
return self.dx_list
if __name__=='__main__':
np.random.seed(123)
torch.random.manual_seed(123)
np.set_printoptions(precision=6,suppress=True)
rnn_PyTorch=torch.nn.RNN(4,5).double()
rnn_numpy=RNNCell(rnn_PyTorch.all_weights[0][0].data.numpy(),
rnn_PyTorch.all_weights[0][1].data.numpy(),
rnn_PyTorch.all_weights[0][2].data.numpy(),
rnn_PyTorch.all_weights[0][3].data.numpy())
nums=3
x3_numpy=np.random.random((nums,3,4))
x3_tensor=torch.tensor(x3_numpy,requires_grad=True)
h3_numpy=np.random.random((1,3,5))
h3_tensor=torch.tensor(h3_numpy,requires_grad=True)
dh_numpy=np.random.random((nums,3,5))
dh_tensor=torch.tensor(dh_numpy,requires_grad=True)
h3_tensor = rnn_PyTorch(x3_tensor, h3_tensor)
h_numpy_list = []
h_numpy = h3_numpy[0]
for i in range(nums):
h_numpy = rnn_numpy(x3_numpy[i], h_numpy)
h_numpy_list.append(h_numpy)
h3_tensor[0].backward(dh_tensor)
for i in reversed(range(nums)):
rnn_numpy.backward(dh_numpy[i])
print("numpy_hidden :\n", np.array(h_numpy_list))
print("torch_hidden :\n", h3_tensor[0].data.numpy())
print("-----------------------------------------------")
print("dx_numpy :\n", np.array(rnn_numpy.dx_list))
print("dx_torch :\n", x3_tensor.grad.data.numpy())
print("------------------------------------------------")
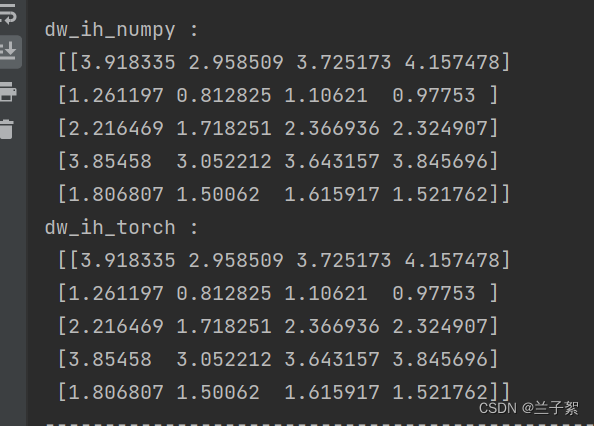
print("dw_ih_numpy :\n",
np.sum(rnn_numpy.dw_ih_stack, axis=0))
print("dw_ih_torch :\n",
rnn_PyTorch.all_weights[0][0].grad.data.numpy())
print("------------------------------------------------")
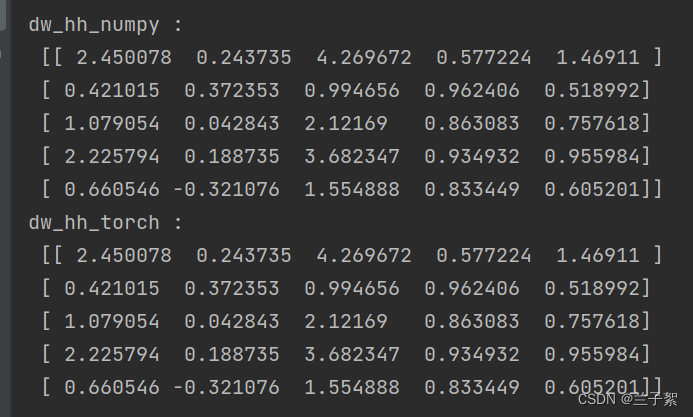
print("dw_hh_numpy :\n",
np.sum(rnn_numpy.dw_hh_stack, axis=0))
print("dw_hh_torch :\n",
rnn_PyTorch.all_weights[0][1].grad.data.numpy())
print("------------------------------------------------")
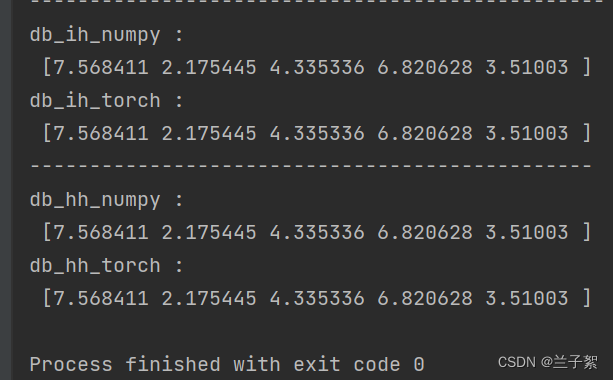
print("db_ih_numpy :\n",
np.sum(rnn_numpy.db_ih_stack, axis=(0, 1)))
print("db_ih_torch :\n",
rnn_PyTorch.all_weights[0][2].grad.data.numpy())
print("-----------------------------------------------")
print("db_hh_numpy :\n",
np.sum(rnn_numpy.db_hh_stack, axis=(0, 1)))
print("db_hh_torch :\n",
rnn_PyTorch.all_weights[0][3].grad.data.numpy())
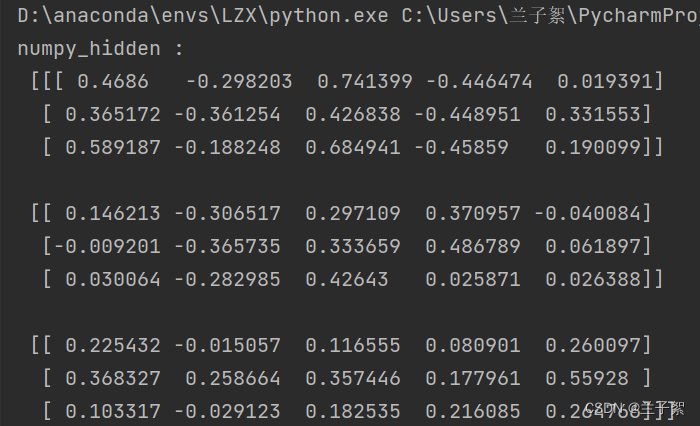
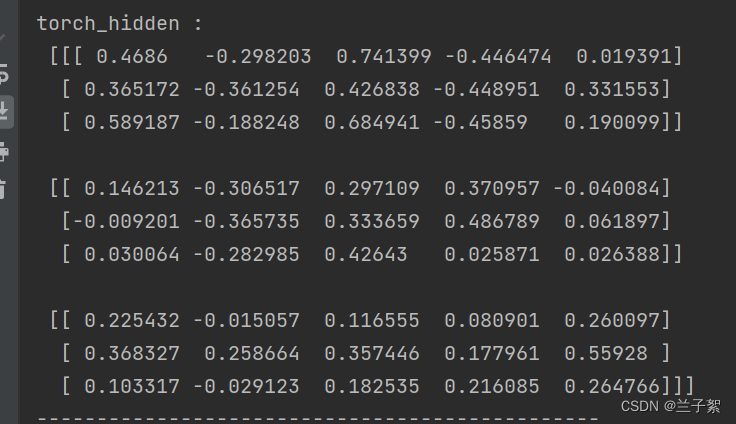
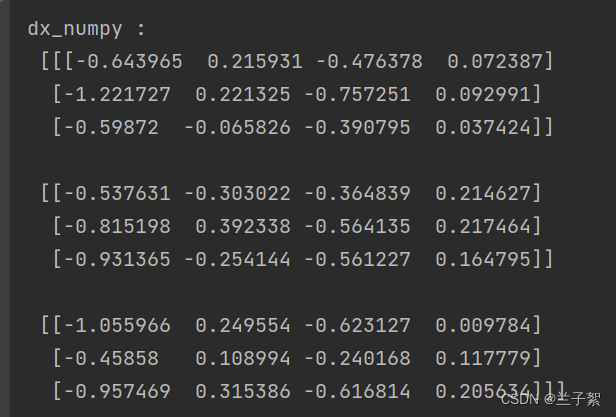
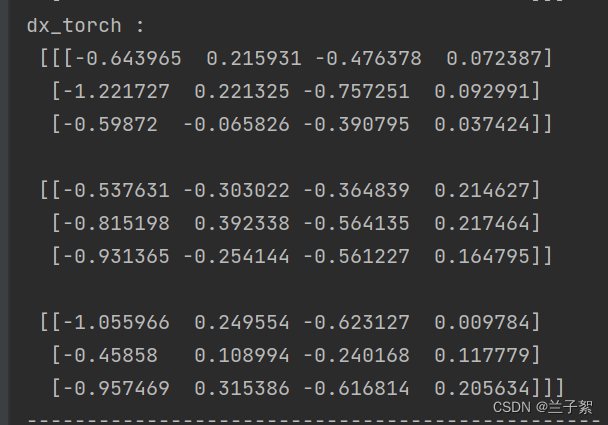
参考:















 341
341











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









