







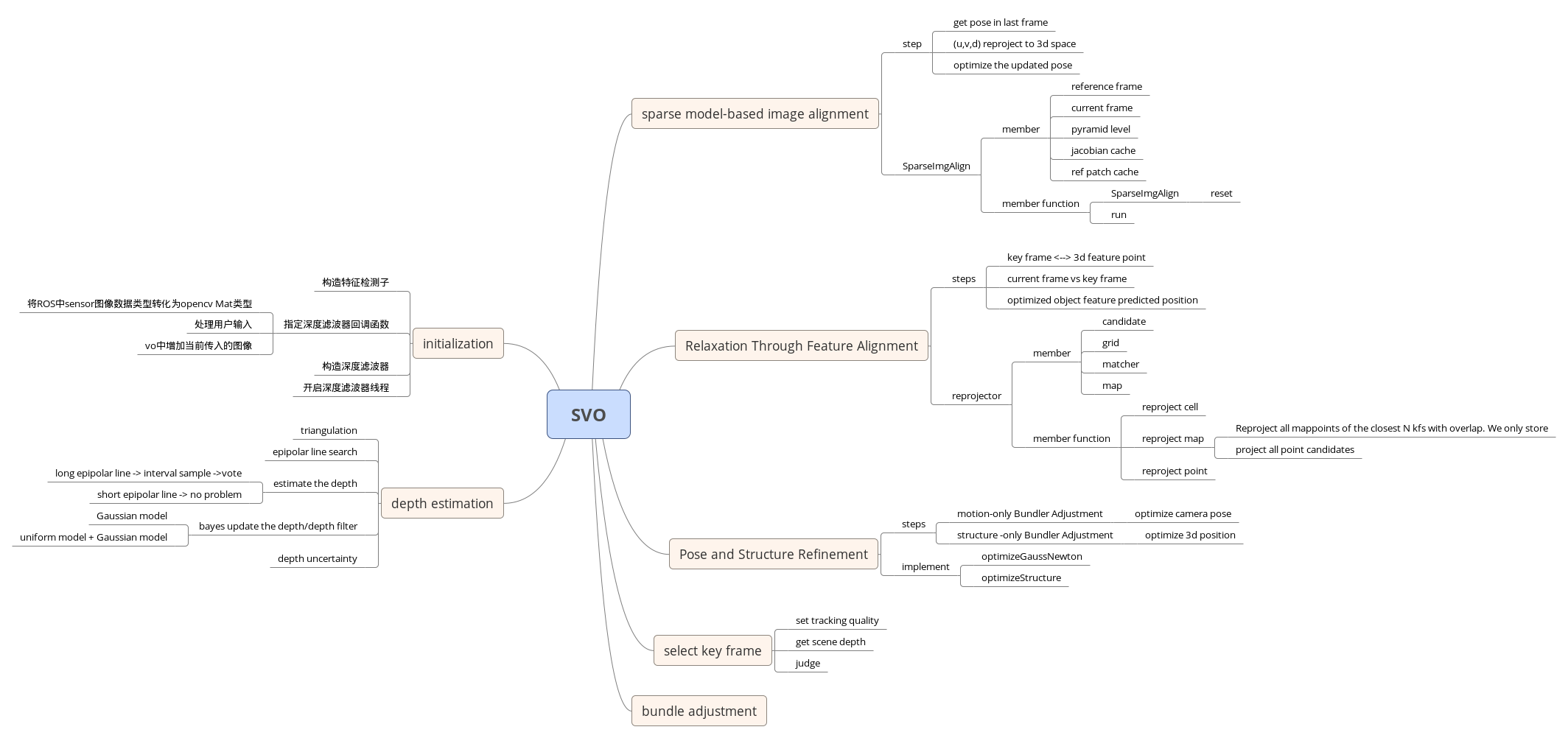
 本文深入剖析SVO的核心代码,包括稀疏图像对齐、特征对齐、位姿和结构优化以及地图管理。通过直接法优化图像块重投影残差获取位姿,接着详细讲解了`optimizeGaussNewton`和`Relaxation Through Feature Alignment`过程。文章还介绍了SVO中frame、point和feature成员,以及地图成员函数。
本文深入剖析SVO的核心代码,包括稀疏图像对齐、特征对齐、位姿和结构优化以及地图管理。通过直接法优化图像块重投影残差获取位姿,接着详细讲解了`optimizeGaussNewton`和`Relaxation Through Feature Alignment`过程。文章还介绍了SVO中frame、point和feature成员,以及地图成员函数。
在上文中我们从ROS的节点出发,一步步介绍了SVO ros节点的运行流程,下面我们将深入介绍SVO大的核心代码。SVO的核心主要分为3方面内容
- spase image alignment
- Feature alignment
- pose and Structure optimization
- map
首先给出总体的结构图。
首先参考论文中的内容,进行分析。使用直接法最小化图像块重投影残差来获取位姿。如图所示:其中红色的 Tk,k−1 为位姿,即优化变量。
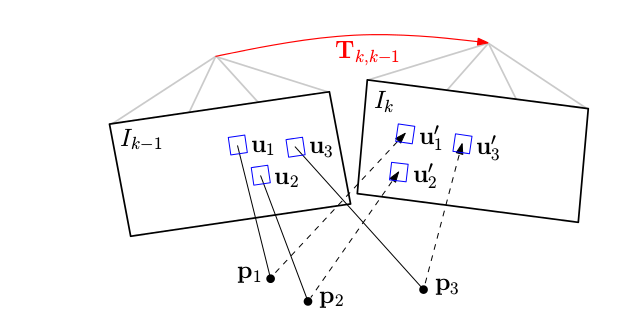
直接法具体过程如下:
1. 准备工作。假设相邻帧之间的位姿 Tk,k−1 已知,一般初始化为上一相邻时刻的位姿或者假设为单位矩阵。通过之前多帧之间的特征检测以及深度估计,我们已经知道第k-1帧中特征点位置以及它们的深度。
2. 重投影。知道 Ik−1 中的某个特征在图像平面的位置 (u,v) ,以及它的深度 d ,能够将该特征投影到三维空间 pk−1 ,该三维空间的坐标系是定义在 Ik−1 摄像机坐标系的。所以,我们要将它投影到当前帧 Ik 中,需要位姿转换 Tk,k−1 ,得到该点在当前帧坐标系中的三维坐标 pk 。最后通过摄像机内参数,投影到 Ik 的图像平面 (u′,v′) ,完成重投影。
3. 迭代优化更新位姿 。按理来说对于空间中同一个点,被极短时间内的相邻两帧拍到,它的亮度值应该没啥变化。但由于位姿是假设的一个值,所以重投影的点不准确,导致投影前后的亮度值是不相等的。不断优化位姿使得这个残差最小,就能得到优化后的位姿 Tk,k−1 。
将上述过程公式化如下:通过不断优化位姿 Tk,k−1 最小化残差损失函数。
Tk,k−1=argminTk,k−112∑i∈R∥δI(Tk,k−1,ui)∥2
δI(Tk,k−1,ui)=Ik(π(T<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4122
4122

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









