









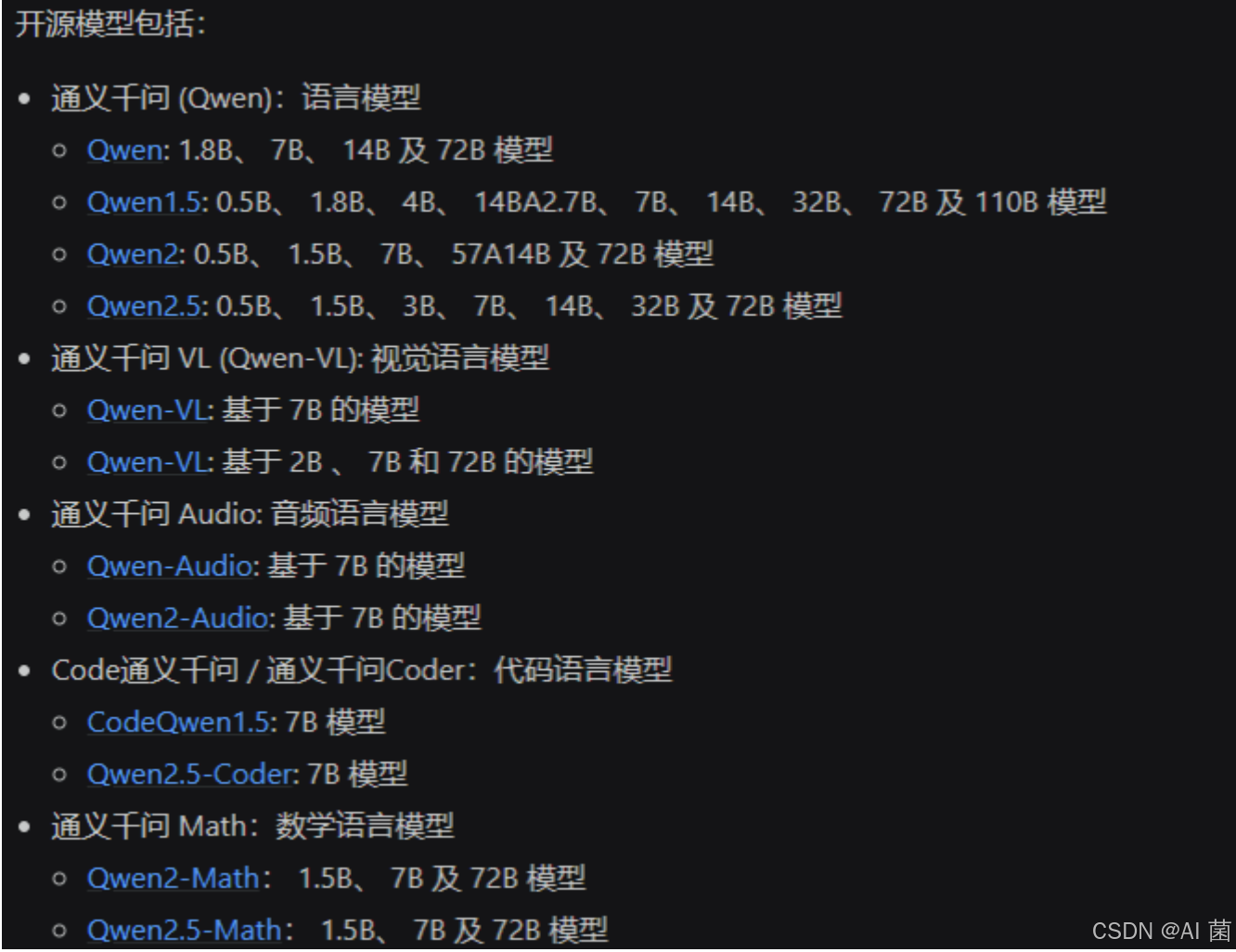
一、Qwen 简介
2023年8月,阿里首次开源通义千问第一代模型Qwen-7B,这是一个有70亿参数的通用语言模型。在此基础上,Qwen扩展了更多的参数版本,比如0.5B、14B、32B、72B等。与此同时,
Qwen也在不断扩展能力,可以支持更多的模态输入,比如先后开源了Qwen-VL视觉语言模型和Qwen-Audio音频语言模型。
二、Qwen2.5 解读
2.1 概要
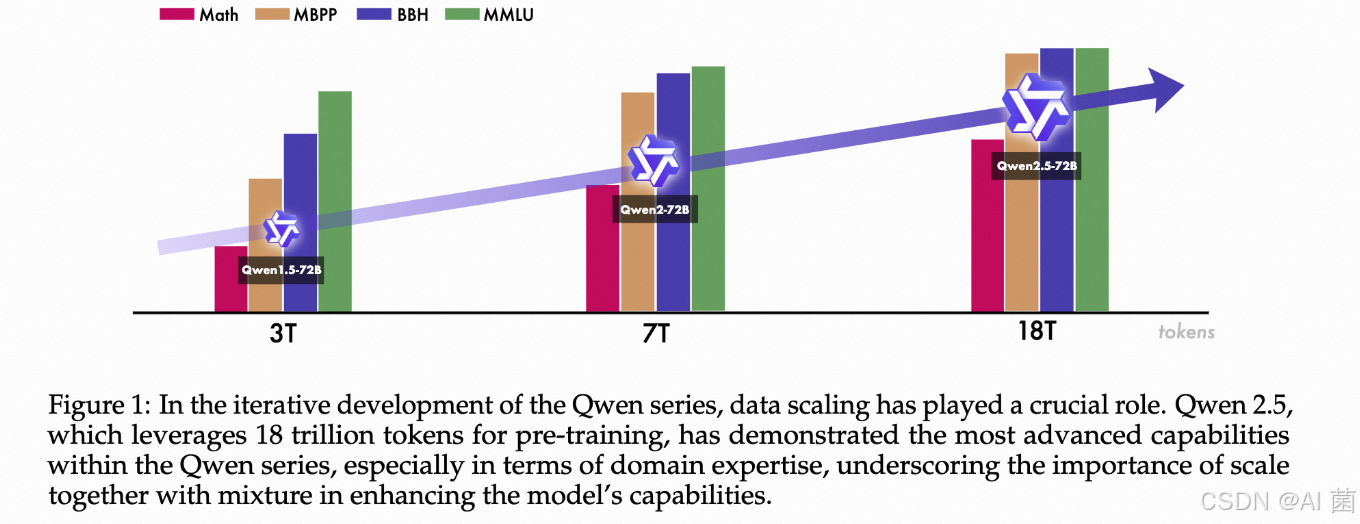
2024年9⽉发布了 Qwen2.5系列,涵盖了多种尺⼨的⼤语⾔模型、多模态模型、数学模型以及代码模型,能够为不同领域的应⽤提供强有⼒的⽀持。不论是在⾃然语⾔处理任务中的⽂本⽣成与问答,还是在编程领域的代码⽣成与辅助,或是数学问题的求解,Qwen2.5 都能展现出⾊的表现。每种尺⼨的模型均包含基础版本、以及量化版本的指令微调模型,充分满⾜了⽤⼾在各类应⽤场景中的多样化需求。具体版本内容如下:
• Qwen2.5: 0.5B, 1.5B, 3B, 7B, 14B, 32B, 以及72B;
• Qwen2.5-Coder: 1.5B, 7B, 以及即将推出的32B;
• Qwen2.5-Math: 1.5B, 7B, 以及72B。
2.2 模型架构
Qwen2.5系列是基于Transformer架构的语言模型,包括密集模型和MoE模型。
- 密集模型采用了Grouped Query Attention(GQA)、SwiGLU激活函数、Rotary Positional Embeddings(RoPE)以及QKV bias等技术来提高模型性能。
- MoE模型则使用了专门的MoE层替换标准的feed-forward网络层,并通过细粒度专家分割和共享专家路由等策略提高了模型能力。
2.3 改进方法
Qwen2.5系列模型经过预训练和后处理两个阶段的改进,在高质量预训练数据集的基础上,通过多阶段强化学习等技术进行后处理,提高了人类偏好、长文本生成、结构数据分析和指令遵循等方面的能力:
- 在预训练阶段,提高数据质量:采用了更加高质量的数据集和数据混合策略,包括更好的控制令牌和数学代码数据集,以及更好的合成数据。同时,他们还引入了长上下文预训练,将初始预训练阶段的上下文长度扩展到4,096个标记,最终扩展到32,768个标记。
- 在post-training阶段,扩充数据范围+两阶段强化学习:作者进行了两个关键的改进:一是增加了监督式微调数据覆盖范围,包括长期序列生成、数学问题解决、编程、指令遵循、结构理解、逻辑推理、跨语言转移和稳健系统指令等方面;二是采用了两阶段强化学习,分为离线RL和在线RL,以进一步提升模型的性能。
2.4 强化学习训练
第一阶段:离线强化学习
- 使用预先准备好的训练信号,这些信号通常是通过监督性微调(SFT)模型对新查询集进行采样生成的。
- 正样本和负样本是通过 质量检查和直接偏好优化(DPO) 训练生成的,这些信号在训练前已经确定,不会随着训练过程动态变化。
- 适用于那些标准答案存在但难以通过奖励模型实时评估的任务,例如数学、编程、指令遵循和逻辑推理等。
第二阶段:在线强化学习
- 使用动态生成的训练信号,这些信号是通过奖励模型对模型生成的响应进行实时评估得到的。
- 奖励模型会根据响应的质量(如真实性、帮助性、简洁性、相关性、无害性和去偏见等)动态调整训练信号。使模型能够更好地适应人类的偏好和期望。
- 适用于需要实时反馈和动态调整的任务,例如生成符合人类偏好的自然语言响应。例如对话生成、文本生成等。
2.5 实验评估
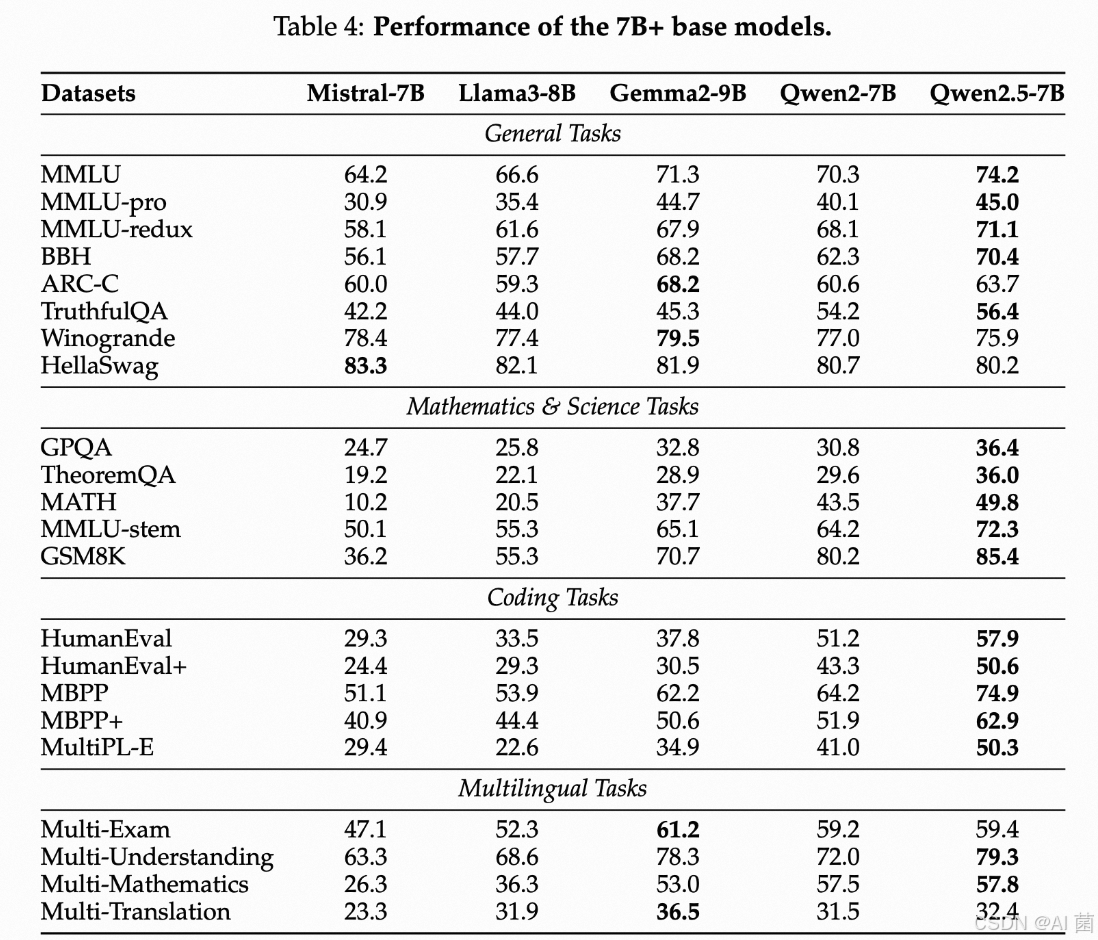
基础能力的测试
包括自然语言理解、编程、数学、科学知识、推理等方面。在多个公开数据集上结果显示,Qwen2.5系列模型在各个基准上都表现出色,特别是在小规模模型方面具有很强的优势。
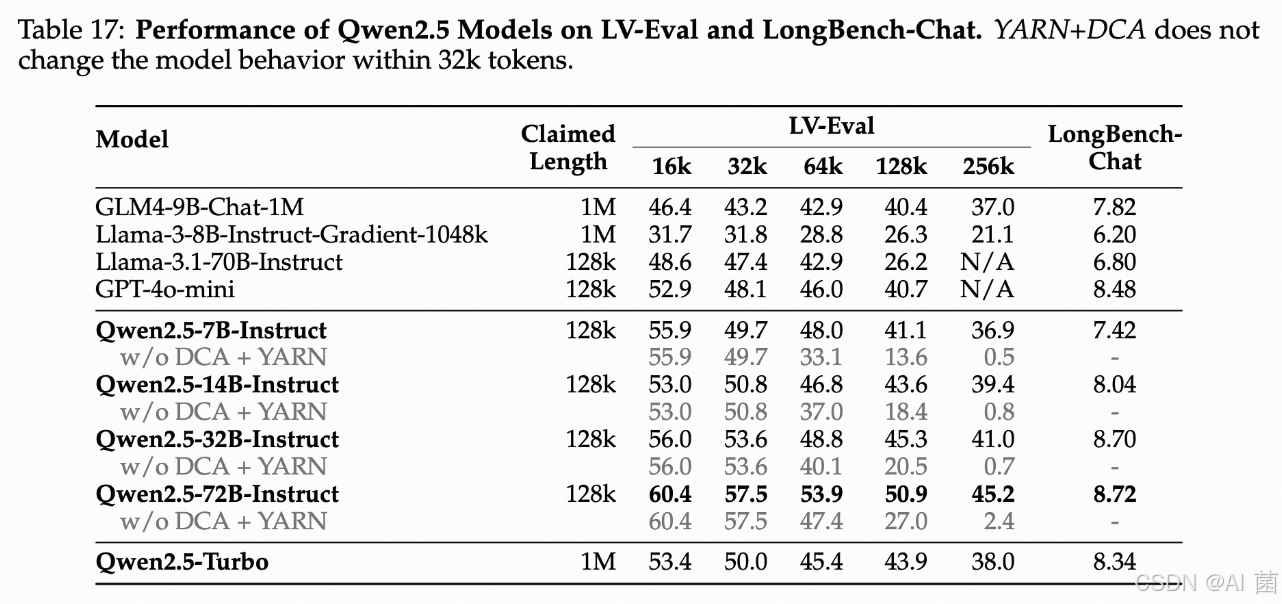
长上下文处理能力
使用了三个不同的基准来评估模型在这个方面的表现,并将其与其他现有的开源和专有的长上下文模型进行了比较。结果显示,Qwen2.5系列模型在这方面也表现出色,尤其是在超长上下文的情况下。
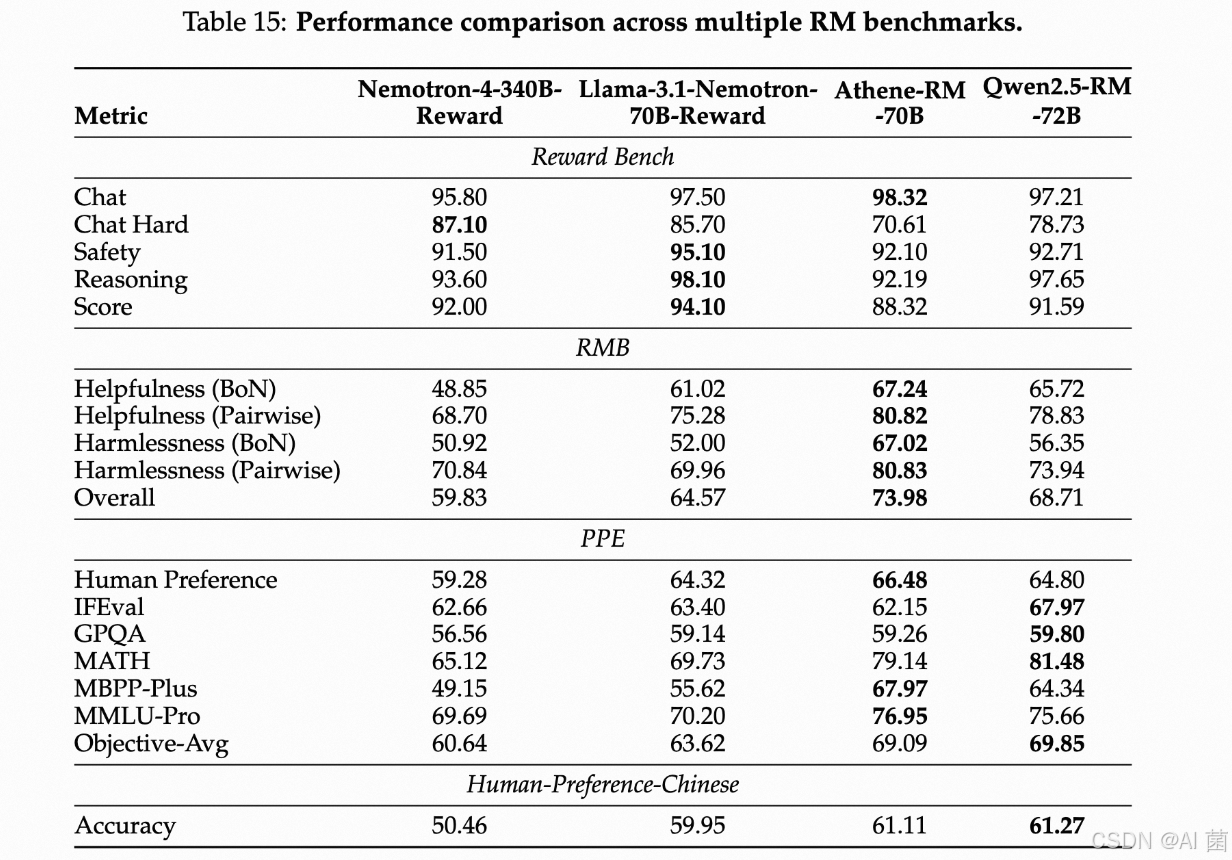
奖励模型评估
使用了多个不同的基准来评估模型在这个方面的表现,并将其与其他现有的奖励模型进行了比较。结果显示,目前还没有一种有效的奖励模型评估方法,因此需要进一步研究这个问题。



















 1013
1013

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











