







1. 小孔成像
在战国初期,我国学者墨子(公元前468年-公元前376年)和弟子们完成了世界上第一个小孔成像的实验,并记录在《墨经》中:“景到,在午有端,与景长。说在端。”,“景,光之人,煦若射,下者之人也高;高者之人也下。足蔽下光,故成景于上;首蔽上光,故成景于下。在远近有端,与于光,故景库内也。”
此文解释了小孔成倒像的原因,指出了光沿直线传播的性质。这是对光直线传播的第一次科学解释。
而西方世界直到公元前350年,古希腊学者亚里士多德提出光学法则,西方人从此了解小孔成像的光学原理。

2. 暗箱写生
十五世纪末期,人们根据小孔成像原理制作了暗箱(Camera Obscure),这实质上是相机的雏形。意大利人达文西在著作中记述了这种暗箱,描述人们利用该工具写生和绘画。
1553年,意大利人玻尔塔发表了《自然魔术》一书中详尽介绍暗箱的使用,利用这种工具,只要用铅笔将影像反射在画纸的,描绘出轮廓,再着色即可完成一幅很有真实感的完全符合真实比例的画像。

3. 银版照相
1822年,法国的涅普斯在感光材料上制出了世界上第一张照片,但成像不太清晰,而且需要8个小时的曝光。1826年,他又在涂有感光性沥青的锡基底版上,通过暗箱拍摄了现存最早的一张照片。
1838年,法国物理学家达盖尔发明盖尔的银版照相法,是利用镀有碘化银的钢板在暗箱里曝光,然后以水银蒸汽显影,再以普通食盐定影。此法得到的实际上是一个金属负像,但十分清晰而且可以永久保存。随后,达盖尔根据此方法制成了世界上第一台照相机,曝光时间需要20~30分钟。
1839年8月19日,法国政府宣布放弃对银版摄影术这项发明的专利,并公之于众。人们通常以这一天作为摄影术的开端。

4. 胶卷相机&数码相机
1866年德国化学家肖特与光学家阿具在蔡司公司发明了钡冕光学玻璃,产生了正光摄影镜头,使摄影镜头的设计制造,得到迅速发展。
随着感光材料的发展,1871年,出现了用溴化银感光材料涂制的干版,1884年,又出现了用硝酸纤维做基片的胶卷。
1888年美国柯达公司生产出了新型感光材料——一种柔软、可卷绕的“胶卷”。这是感光材料的一个飞跃。同年,柯达公司发明了世界上第一台安装胶卷的可携式方箱照相机。Kodak No.1就是柯达公司推出家用相机,其宣传口号便是“按下快门,剩下的由我完成”,这台相机可说是消费型相机的始祖。

1969年,CCD芯片作为相机感光材料在美国的阿波罗登月飞船上搭载的照相机中得到应用,为照相感光材料电子化,打下技术基础。
1981年,索尼公司经过多年研究,生产出了世界第一款采用CCD电子传感器做感光材料的摄像机,为电子传感器替代胶片打下基础。紧跟其后,松下、Copal、富士、以及美国、欧洲的一些电子芯片制造商都投入了CCD芯片的技术研发,为数码相机的发展打下技术基础。
1987年,采用CMOS芯片做感光材料的相机在卡西欧公司诞生。

回顾一下摄像头发展历程:

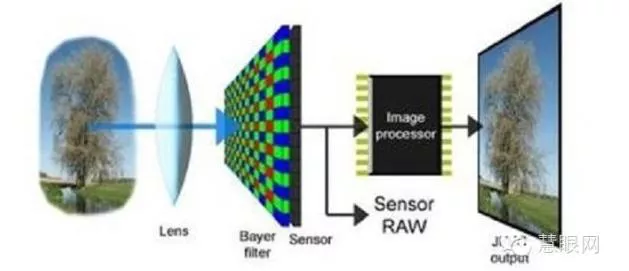
5. 摄像头模组内部结构及工作机理讲解

镜头:聚集光线,把景物投射到成像介质表面,有的是单镜头,有的成像效果要好,需要多层玻璃的镜头。
滤色片:人眼看到的景物是可见光波段,而图像传感器可辨识的光波段多大于人眼,因此增加了滤色片将多余的光波段过滤掉,使图像传感器能拍摄多人眼所见到的实际景物。
图像COMS传感芯片:即成像介质,将镜头投射到表面的图像(光信号)转换为电信号。
线路板基板:将图像传感器的电信号传输到后端,针对车载摄像头这里的线路基板会更多一些电路,需要把并行的摄像头信号转为串行传输,这样抗干扰能力更强一些。

摄像头模组的工作原理就是镜头把光线聚拢,然后通过IR滤光片把不需要的红外光滤掉,此时模拟信号进入到传感器COMS芯片,通过AD数字输出,这里有的是会放置ISP图像处理芯片在摄像头这边,把处理后的信号传输给到主机,有的是不放置ISP芯片,由主机那边的内置ISP芯片进行图像处理,这样摄像头端的散热会好很多,辐射也小。
6. 车载摄像头架构

车载摄像头的结构如上图所示,放置车身外面的,就需要组成完整的摄像头,如果是在车内DVR,不用考虑防水,就可以组装成上面的那种摄像头模组。

上图是我们比较常见的汽车上使用的相机模组的解剖。除了最外侧的铝壳以及密封圈和镜头之外,其实中间就是比较简单的几层板的设计,通常包括传感器的sensor板,图像处理器的小板,还包括一个串行器的板。为什么需要串行器,是因为通常相机传感器或ISP的图像数据输出总线是MIPI CSI标准,其特点是高速穿行,但是传输总线距离较短,否则无法保证信号的完整性。
所以在车辆上,我们需要将其转换成例如GMSL等适合在车上长距离传输的高速总线标准进行传输,所以相机模组内部通常会通过串行板进行总线的转换。另外同轴电缆既可以用来为模组提供电源,也可以传输图像数据。
7. 图像传感器CCD和COMS区别
CCD(Charge Coupled Device)感光耦合组件 CCD主要材质为硅晶半导体,基本原理类似 CASIO 计算器上的太阳能电池,透过光电效应,由感光组件表面感应来源光线,从而转换成储存电荷的能力。简单的说,当 CCD 表面接受到快门开启,镜头进来的光线照射时,即会将光线的能量转换成电荷,光线越强、电荷也就越多,这些电荷就成为判断光线强弱大小的依据。CCD 组件上安排有信道线路,将这些电荷传输至放大解码原件,就能还原所有CCD上感光组件产生的信号,并构成了一幅完整的画面。
CMOS(Complementary Metal-Oxide Semiconductor)互补性氧化金属半导体 CMOS的材质主要是利用硅和锗这两种元素所做成的半导体,使其在CMOS上共存着带N(带–电)和P(带+电)级的半导体,这两个互补效应所产生的电流即可被处理芯片纪录和解读成影像。

CMOS与CCD最大的差别是:放大器位置和数量 比较 CCD 和 CMOS 的结构,放大器的位置和数量是最大的不同之处。

CCD 每曝光一次,自快门关闭或是内部频率自动断线(电子快门)后,即进行像素转移处理,将每一行中每一个像素(pixel)的电荷信号依序传入“缓冲器”(电荷储存器)中,由底端的线路导引输出至 CCD旁的放大器进行放大,再串联 ADC(模拟数字数据转换器) 输出。

CMOS 的设计中每个像素旁就直接连着“放大器”,光电信号可直接放大再经由 BUS 通路移动至 ADC 中转换成数字数据。由于构造上的差异,CCD与CMOS在性能上的表现之不同。CCD的特色在于充分保持信号在传输时不失真(专属通道设计),透过每一个像素集合至单一放大器上再做统一处理,可以保持数据的完整性。而CMOS的制程较简单,没有专属通道的设计,因此必须先行放大再整合各个像素的数据。

7.1. 灵敏度差异
由于 CMOS 每个像素包含了放大器与A/D转换电路,过多的额外设备压缩单一像素的感光区域的表面积,因此在 相同像素下,同样大小之感光器尺寸,CMOS的感亮度会低于CCD。
7.2. 分辨率差异
在第一点“感亮度差异”中,由于 CMOS 每个像素的结构比CCD复杂,其感光开口不及CCD大,相对比较相同尺寸的CCD与CMOS感光器时,CCD感光器的分辨率通常会优于CMOS。不过,如果跳出尺寸限制,目前业界的CMOS 感光原件已经可达到1400万像素/全画幅的设计,CMOS 技术在亮率上的优势可以克服大尺寸感光原件制造上的困难,特别是全画幅24mm-by-36mm 这样的大小。
7.3. 噪声差异
由于CMOS每个感光二极管旁都搭配一个ADC放大器,如果以百万像素计算,那么就需要百万个以上的ADC放大器,虽然是统一制造下的产品,但是每个放大器或多或少都有些微的差异存在,很难达到放大同步的效果,对比单一个放大器的CCD,CMOS最终计算出的噪声就比较多。
7.4. 耗电量差异
CMOS的影像电荷驱动方式为主动式,感光二极管所产生的电荷会直接由旁边的晶体管做放大输出;但CCD却为被动式,必须外加电压让每个像素中的电荷移动至传输通道。而这外加电压通常需要12伏特(V)以上的水平,因此CCD还必须要有更精密的电源线路设计和耐压强度,高驱动电压使CCD的电量远高于CMOS。
7.5. 成本差异
CMOS 应用半导体工业常用的CMOS制程,可以一次整合全部周边设施于单芯片中,节省加工芯片所需负担的成本和良率的损失;相对地 CCD 采用电荷传递的方式输出信息,必须另辟传输信道,如果信道中有一个像素故障(Fail),就会导致一整排的信号壅塞,无法传递,因此CCD的良率比CMOS低,加上另辟传输通道和外加 ADC 等周边,CCD的制造成本相对高于CMOS。
7.6. 其他差异
IPA(Indiviual Pixel Addressing)常被使用在数字变焦放大之中,CMOS 必须依赖x,y画面定位放大处理,否则由于个别像素放大器之误差,容易产生画面不平整的问题。在生产制造设备上,CCD必须特别订制的设备机台才能制造,也因此生产高像素的CCD 组件产生不出日本和美国,CMOS 的生产使用一般的内存或处理器设备机台即可承担。综上所述,CCD与CMOS的特点决定了CMOS更适用于手机这类便携设备中使用,车载摄像头也是使用COMS的传感器,而CCD则更适用于单反相机这类专业设备上使用。
8. CMOS传感器的构成与关键参数
图像传感器的功能是光电转换。关键的参数有像素、单像素尺寸、芯片尺寸、功耗。技术工艺上有前照式(FSI)、背照式(BSI)、堆栈式(Stack)等。以下简单介绍。

图像传感器从外观看分感光区域(Pixel Array),绑线Pad,内层电路和基板。感光区域是单像素阵列,由多个单像素点组成。每个像素获取的光信号汇集在一起时组成完整的画面。

CMOS芯片由微透镜层、滤色片层、线路层、感光元件层、基板层组成。

由于光线进入各个单像素的角度不一样,因此在每个单像素上表面增加了一个微透镜修正光线角度,使光线垂直进入感光元件表面。这就是芯片CRA的概念,需要与镜头的CRA保持在一点的偏差范围内。

电路架构上,我们加入图像传感器是一个把光信号转为电信号的暗盒,那么暗盒外部通常包含有电源、数据、时钟、通讯、控制和同步等几部分电路。可以简单理解为感光区域(Pixel Array)将光信号转换为电信号后,由暗盒中的逻辑电路将电信号进行处理和一定的编码后通过数据接口将电信号输出。

9. 图像传感器关键参数
9.1. 像素
指感光区域内单像素点的数量,比如5Maga pixel,8M,13M,16M,20M,像素越多,拍摄画面幅面就越大,可拍摄的画面的细节就越多。
9.2. 芯片尺寸
指感光区域对角线距离,通常以英制单位表示,比如1/4inch,1/3inch,1/2.3inch等。芯片尺寸越大,材料成本越高。
9.3. 单像素尺寸
指单个感光元件的长宽尺寸,也称单像素的开口尺寸,比如1.12微米,1.34微米,1.5微米等。开口尺寸越大,单位时间内进入的光能量就越大,芯片整体性能就相对较高,最终拍摄画面的整体画质相对较优秀。单像素尺寸是图像传感器一个相当关键的参数。

9.4. 前照式(FSI)与背照式(BSI)
传统的CMOS图像传感器是前照式结构的,自上而下分别是透镜层、滤色片层、线路层、感光元件层。采取这个结构时,光线到达感光元件层时必须经过线路层的开口,这里易造成光线损失。
而背照式把感光元件层换到线路层的上面,感光层只保留了感光元件的部分逻辑电路,这样使光线更加直接的进入感光元件层,减少了光线损失,比如光线反射等。因此在同一单位时间内,单像素能获取的光能量更大,对画质有明显的提升。不过该结构的芯片生产工艺难度加大,良率下降,成本相对高一点。

9.5. 堆栈式(Stack)
堆栈式是在背照式上的一种改良,是将所有的线路层挪到感光元件的底层,使开口面积得以最大化,同时缩小了芯片的整体面积。对产品小型化有帮助。另外,感光元件周边的逻辑电路移到底部之后,理论上看逻辑电路对感光元件产生的效果影响就更小,电路噪声抑制得以优化,整体效果应该更优。业内的朋友应该了解相同像素的堆栈式芯片的物理尺寸是比背照式芯片的要小的。
但堆栈式的生产工艺更大,良率更低,成本更高。索尼的IMX214(堆栈式)和IMX135(背照式)或许很能说明上述问题。

10. 图像传感器之ISOCELL技术分析
10.1. 图像传感器好坏取决于单像素有效进光量
前一章我们谈到,图像处理器最为关键的参数是单像素尺寸,单像素尺寸越大则进光量越大,图像质量越优秀。因此我们可以简单的认为:决定图像传感器性能的最大的因素是单像素点的有效进光量,它决定每个像素点在单位时间内能捕获多少光线能量。假如单像素面积越大,则在相同时间里可以承载更多光线能量,便可以更明显的提升画质,更真实的还原图像场景。
数码相机和手机所采用的图像传感器单像素尺寸是不一样的,数码相机的更大,英寸拍摄效果更加出色。但单像素尺寸增大,相同像素的图像传感器面积则大幅增加,摄像头模组体积增大,模组高度增加,功耗大幅增加,发热量增加等,这样的变化在数码相机固然还可以接受,但放在追求便携的手机上面,无疑是不太合适的。
以HTC ONE为例,采用了单像素尺寸2微米的图像传感器,换来相当棒的画质效果,夜景拍摄尤为出色。但正因为单像素尺寸增加之后,手机摄像头受限于体积增加、发热量增加等因素迫不得已只能做到400万像素,令人难以接受。而苹果iPhone比较折中的选择了1.5微米单像素尺寸,虽然比较折中,但其只有800万的像素令人诟病。而在新一代iPhone6时为确保较好的拍摄效果继续选择1.5微米芯片,换来了前所未有的结构和外观牺牲,突出的摄像头设计堪称史上最丑苹果摄像头!除了增大单像素尺寸可以增加进光量之外,就没有别的方法了吗?
其实不然,ISOCELL技术在相同的像素尺寸情况下可做到优化,可有效提升进光量
10.2. ISOCELL技术解决什么问题
据三星公司发布的信息看,ISOCELL技术要解决的第一个问题就是增大单个像素的收缩能力,通过对成像动态范围的对比,改善光线强度最轻和最暗部分的图像质量。第二个问题就是随着像素变得越来越小,会发生彼此之间抗干扰能力的减弱,造成错误的感应光源颜色和数量,这个现象被称为串扰。光电二极管的微小探测器会将光能部分转化成为细微的电流,而这些电流有时会出现在不该出现的地方,造成对图像的影响。
发生串扰的原因有很多,而其中最大的可能性是光串扰。当一个像素接收到更多的光线,超过了自己的承受范围,那么电子就会发生串扰,而这完全是建立在错误的光二极管在信号传输过程中的电流漏出

比如单像素在捕获绿色光线时,一些光子很有可能泄露成蓝色或红色,导致在即使没有蓝色和红色的场景下出现电流,这样就会在原始图像上形成轻微的变形,从而产生噪点。这类问题虽然是不可避免的,但是通过ISOCELL技术可以尽量减小影响。
10.3. ISOCELL技术原理 ISOCELL

ISOCELL本质上是在现有BSI技术上的一种进化,可以解决上面提到的串流问题。简单地说,便是通过在形成隔离像素与相邻像素之间形成物理屏障,缩小它们的间隔区,避免BSI传感器中单个像素间形成的干扰问题,让像素能够获得吸收更多光子,获得更好的照片效果。
从官方数据来看,ISOCELL相比BSI能够将每种颜色的像素孤立起来,提高传感器捕光能力,可以预计减少30%的像素串扰。但是这并不意味着最终的成像质量同样会提高30%,但是却可以更好的提升清晰度和色彩表现,让图像看起来更丰富。三星搭载了ISOCELL技术的图像传感器,画质和色彩表现有目共睹。
11. 摄像头工作原理
摄像头对于模组工程是那么的熟悉,有多少人又真正了解摄像头从硬件到软件的工作流程。我们了解摄像头的工作原理,对于开展工作,辅助的解决遇到的一些问题,很有帮助。下面我们析摄像头从寄存器角度是怎么工作的。如何阅读摄像头规格书(针对驱动调节时用到关键参数,以格科GT2005为例)。
每个摄像头的sensor都有Datasheet规格书,也就是一个器件所有的说明,精确到器件每一个细节,软件关心的寄存器、硬件关心的电气特性、封装等等。
camera的总体示意图如下:控制部分为摄像头上电、IIC控制接口,数据输出为摄像头拍摄的图传到主控芯片,所有要有data、行场同步和时钟号。GT2005/GT2015是CMOS接口的图像传感器芯片,可以感知外部的视觉信号并将其转换为数字信号并输出。
我们需要通过MCLK给摄像头提供时钟,RESET是复位线,PWDN在摄像头工作时应该始终为低。PCLK是像素时钟,HREF是行参考信号,VSYNC是场同步信号。一旦给摄像头提供了时钟,并且复位摄像头,摄像头就开始工作了,通过HREF,VSYNC和PCLK同步传输数字图像信号。数据是通过D0~D7这八根数据线并行送出的。

11.1. Pixel Array
GT2005阵列大小为 1268 列、1248 行,有效像素为 1616 列, 1216 行。也就是说摄像头为1600X1200的时候,像素点要多于这个,去除边缘一部分,保证图像质量吧。
11.2. IIC
这个不用说了,摄像头寄存器初始化的数据都从这里传输的,所有的IIC器件都一样的工作,来张图吧,后面做详细分析;

下面这一部分在调试驱动的过程中比较重要了:
11.3. MCLK
电子元件工作都得要个时钟吧,摄像头要工作,这个就是我们所要的时钟,在主控制芯片提供,这个时钟一定要有,要不然摄像头不会工作的。
11.4. 上下电时序
这个要接规格书上来,注间PWDN、RESETB这两个脚,不同的摄像头不太一样,这个图是上电时序,上电时参考一下,知道在那里看就行;

11.5. PCLK \D1~D7
摄像头得到的数据要传出来吧,要有数据,当然数据出来要有时钟和同步信号了,看下它的时序,和LCD显示的时序一样,道理是一样的:

11.6. 主要的寄存器
分辨率、YUV顺序、X轴、Y轴镜相、翻转以上工作完成后,也许还有一些问题,分辨率太小;YUV顺序不对图像不对;XY图像方向。这些工作完成后,如果还有什么细节的问题,如果你想花时间,看规格书里面的寄存器可以解决的,如果不想看,找模组厂的FAE,他们专业的,很快会帮你搞定。
11.7. 摄像头的硬件接口

12. 摄像头镜头
一个摄像头效果好不好,70%的光学参数是由镜头决定的,虽然从单价上来说没有COMS芯片贵,但是性能上是非常重要的。
针对镜头相关的参数讲解一波,这个其实对于买手机,买单反的同学来说还是非常有用的。

我们这里以一款车载DVR的隐藏式宽FOV角度的镜头为例子。

镜筒的材质一般都是金属,但是也有塑胶的,金属的镜筒从质量,耐高低温等各项指标都会更好,但是也有缺点,金属的套筒在螺丝扭的时候会产生金属机械粉末,会有掉入到COMS感光区域的风险,而且金属的套筒硬度比较硬,底板打螺丝的时候容易导致底板有COMS芯片的PCBA变形,从而导致成像后的解析度发生变化。
镜头的材质主要是两种,一种是玻璃,一种是塑胶。
玻璃镜片:以G为缩写,面型多为球面,玻璃研磨加工;
塑胶镜片:以P为缩写,面型多为非球面,注塑加工。
手机摄像头为追求轻薄短小,多为1-4pcs的玻璃镜片或塑胶镜片组成的定焦镜头。如2P,3P,3G,1G1P,2G2P等。
镜头的材质车载里面一般都是使用的是玻璃,玻璃的耐高温,耐擦挂性能都非常好,表面硬度玻璃会好于塑胶,当然玻璃也有缺点,价格贵,而且摄像头整体的厚度变厚了,但是在车载里面这些相对于性能要求而言,都必须要使用到玻璃镜头,所以这里可以看到6G,就是使用6个玻璃片。
13. 镜头的光学参数讲解
13.1. 焦距(Focal Length或EFFL)
是指一个光学系统从起像方主面到焦点间的距离,它反映了一个光学系统对物体聚焦的能力。

13.2. BFL 后焦
镜头最后一镜片面到成像面的距离
这里的如上图所示是 5.85mm
13.3. Mechanical BFL法兰距
镜筒端(前/后)到成像面的距离
这里如上图所示是 5.08mm±0.2mm
13.4. 镜头总长和光学总长(TTL)
光学总长是指从系统第一个镜片表面到像面的距离;而镜头总长是指最前端表面(一般指Barrel表面)到像面(例如Sensor表面)的距离。一般来说,镜头太长或太短其设计都会变得困难,制造时对工艺要求较高,这个镜头的总长度是22.7mm±0.3mm。
13.5. 相对孔径(FNo.)
一个光学系统成像亮度指标,一般简称F数(如传统相机上所标识),在同样的光强度照射下,其数值越小,则像面越亮,其数值越大,则像面越暗。对于一般的成像光学系统来说,F2.0-3.2就比较合适, 如果要求F数越小,则设计越难,结构越复杂,制造成本就越高。这里的FNo为F2.1。
13.6. 视场角(FOV)
一个光学系统所能成像的角度范围。角度越大,则这个光学系统所能成像的范围越宽,反之则越窄。在实际产品当中,又有光学FOV和机械FOV之分,光学FOV是指SENSOR或胶片所能真正成像的有效FOV范围,机械FOV一般大于光学FOV, 这是有其他考虑和用途, 比如说需要用机械FOV来参考设计Module或者手机盖的通光孔直径

这里的FOV角度理论上是越大越好,比如做隐藏式行车记录仪DVR的摄像头,这个时候就需要记录到的两边的图像越宽越好,越方便信息的完整性。当然这个FOV的角度直接影响到最终摄像头测距的距离,所以这个FOV角度也是最好根据摄像头的实际应用来选择。

13.7. 光学畸变(Opt distortion)和TV畸变(TV distortion):
畸变是指光学系统对物体所成的像相对于物体本身而言的失真程度。光学畸变是指光学理论上计算所得到的变形度。
TV畸变则是指实际拍摄图像时的变形程度,DC相机的标准是测量芯片(Sensor)短边处的变形。一般来说光学畸变不等于TV畸变,特别是对具有校正能力的芯片来说。畸变通常分两种:桶形畸变和枕形畸变,比较形象的反映畸变的是哈哈镜,使人变得又高又瘦的是枕型畸变,使人变得矮胖的是桶型畸变。

这个一般都比较重视的是TV失真,越小越好,这样对于后面芯片的处理也就越简单,这里的镜头的TV失真是小于21%。
13.8. 相对照度(Relative illumination又简写为RI):
它是指一个光学系统所成像在边缘处的亮度相对于中心区域亮度的比值,无单位。在实际测量的结果中,它不仅同光学系统本身有关,也同所使用的感光片(SENSOR)有关。同样的镜头用于不同的芯片可能会有不同的测量结果。
这个车载镜头的RI指标是≥53%。
13.9. CRA 主光线出射角通过光阑中心光线的成像面入射角
不同的视场具有不同的CRA值,将所有视场的CRA做成一条曲线,即所谓的CRA曲线。图纸中所示的CRA值为Sensor有效像高处的数值。

13.10. MTF
它从一定程度上反映了一个光学系统对物体成像的分辨能力。一般来说,MTF越高,其分辨力越强,MTF越低,其分辨力越低。由于MTF也只是从一个角度来评价镜头的分辨率,也存在一些不足,故在目前的生产中, 大多数还是以逆投影检查分辨率为主。

14. IR Filter(滤光片)
它主要用于调整整个系统的色彩还原性。它往往随着芯片的不同而使用不同的波长范围,因为芯片对不同波长范围的光线其感应灵敏度不一样。对于目前应用较广的CMOS和CCD感光片它非常重要,早期的CCD系统中,采用简单的IRF往往还不能达到较好的色

IR-Cut:透过率为50%时的红外光线频率,650±10nm @ T=50%

所以这里可以看到车载摄像头的镜头的红外滤光片基本上都是650nm±10nm的滤光片。
IR镀膜的规格对镜头的色彩还原性有较大的影响,另外结合sensor的特性,对镀膜进行优化,会改善镜头色彩还原能力,所以在有的摄像头拍照出来的色彩还原效果比较差的时候,软件优化都无能为力的时候,可以考虑IR镀膜来调整。

15. 车载镜头需要满足的信赖性实验要求
15.1. 高低温存储和高低温冲击
这个主要验证镜头会不会在极限温度下产生变形,导致图像失真。
15.2. 耐腐蚀实验
譬如后拉摄像头,是在车子外面的,本身就风吹雨晒的,很容易有腐蚀液体在镜头表面,而且也会有车子清洗的时候会有玻璃洗涤液等腐蚀,所以车载镜头需要过耐腐蚀的实验。
15.3. 耐振动实验
这个是必须要过的,本身汽车的振动就会传递到摄像头这边,镜头作为一个刚性材料,需要在各种路况或者运输途中的振动都能完好如初,满足车载振动的实验要求。

15.4. IPX9K防水等级要求
一个摄像头防水好不好,底子牢靠不牢靠,其实最根本的除了连接处的防水做好以为,影响最大的就是镜头本身防水等级是否够高,一般摄像头整体防水是IPX6的 等级,但是镜头基本上要过IPX9K的等级,这样才能保障摄像头整体的防水能力,如果是车内的DVR行车记录仪,不会放置在车外,这个防水等级要求可以降低。

15.5. 耐盐雾实验
这个也是车载必须的实验之一,汽车难免会驾驶到海边等恶劣的环境中去,这时候空气中的盐雾成分就会比较大,一般的金属都会被腐蚀,时间久了以后就会锈穿,直接就坍塌掉,所以一般金属器件外表面会有涂覆防锈油,这样可以过耐盐雾的实验标准要求。
15.6. 百格试验
用HB铅笔在镜头G1外露面均匀划百格线(横10条,竖10条)用擦拭纸蘸酒精擦拭被涂画的地方。观察镜头表面,从圆心至外3/4圆处有1—2条膜伤为可采纳品,表面膜层无任何脱落为佳品。出现网状膜伤,判定不良。
这个实验主要目的是验证镜头表面的耐擦性能,特别是倒车后视的摄像头,看看下图中的保时捷的倒车后视摄像头,在尾箱正中间,这个位置非常容易被溅起来的小石头刮花镜头表面,如果刮花了,整个显示图像就非常不清晰了,所以需要镜头能耐比较强的擦刮实验,这里的百格实验就是这个目的。

15.7. 紫外线照射试验
测试镜头放进30W的紫外线老化试验箱,紫外线灯照射镜头240H,实验后所有性能和功能正常。
我们都知道紫外光很强,会把一些塑胶或者玻璃黄化掉,想想汽车在太阳暴晒后,座椅的颜色都会晒黄一样的道理,镜头有的是玻璃,有的是塑胶,塑胶就容易被紫外线晒黄变,所以车载镜头一定要过此试验标准。
16. 摄像头解析力
其实解析力就是和摄像头的分辨率基本上是线性相关的额,我们看一个摄像头的分辨率高不高,最重要的就是几百万像素的摄像头。

比较老的倒车后视摄像头就是30W像素的,那个时候看倒车图像就非常模糊,现在无论是前视的DVR,倒车后视,还是360环视的摄像头,基本上都是100W的摄像头起步了,特斯拉Model 3前视三摄像头采用的三个CMOS图像传感器分辨率均为1280 x 960像素(120万像素),供应商为安森美半导体(ON Semiconductor)子公司Aptina。该摄像头捕捉的图像信息供给特斯拉Model 3驾驶员辅助自动驾驶仪控制模块单元使用。
可能有朋友会说,手机都上千万的像素摄像头,车载摄像头是没有这个技术能力?其实还真不是,手机因为本身摄像头的能力就要求非常高,需要拍照出来像单反的效果,所以摄像头本身的像素就非常高,而且传输也直接通过MIPI进入到主控去处理。
反过来看看车载摄像头,这部分车载摄像头拍照出来的图像主要是给机器使用的,做一些自动驾驶或者行车监控的,这部分100W的像素完全能够满足机器需要的数据了,数据越多,对于主机处理的能力及算力就越高,但是自动驾驶效果提升反而没有好处。
加上车载摄像头传输的信号需要一个串行器去传输,这个串行器目前还不能传输上千万像素的芯片,传输2K的视频就非常不错了,而且这部分车载主机需要去处理整车8-10个摄像头,如果每个摄像头都是上千万的像素,这个处理器的难度也增大,成本也增大,所以车载摄像头并不是像手机拼像素的能力,而且处理图像的算法能力才是王道。
测试解析度一般都是通过一个标准的解析度卡进行测试,可以提供实际拍摄的垂直分辨率和水平分辨率等辅助测试。

分辨率测试采用了国际标准的ISO12233解析度分辨率卡进行测试,采取统一拍摄角度和拍摄环境。而分辩率的计算又使用了HYRes软件,分开垂直分辨率和水平分辨率两部分进行,
可以简单理解就是按照标准的距离用摄像头去拍这个卡片,然后通过软件去读取这个摄像头拍摄的值,直接软件上就可以获取中心和四周的解析度的值,当然如果没有购买软件,也可以人肉眼去读取这个值,这样的误差由于人眼的视力因素,会有很大的偏差。

一般针对200W像素的摄像头,需要中心解析度≥800线,四周解析度≥700。
17. 摄像头灵敏度
灵敏度是以32000K色温,2000LUX照度的光线照在具有89-90%的反射系数的灰度卡上,用摄像机拍摄,图像电平达到规定值时,所需的光圈指数F,F值越大,灵敏度越高。

灵敏度越高最低照度越低,摄像机质量也越高。如果照度太低或太高时,摄像机拍摄出的图像就会变差。照度低可能会出现惰性拖尾。照度太高会出现图像“开花”现象。
18. 摄像头信噪比
所谓信噪比指的是信号电压对于噪声电压的比值,通常用S/N符号来表示,信噪比又分亮度信噪比和色度信噪比。
当摄像机摄取亮场景时,监视器显示的画面通常比较明快,观察者不易看出画面干扰噪点,而当摄像机摄取较暗的场景时,监视器显示的画面就比较昏暗,观察者此时很容易看到画面中雪花状的干扰噪点。摄像机的信噪比越高,干扰噪点对画面的影响就越小。
车载中可以接受的信噪比是40db,当信噪比达到55db的时候,这时候噪声基本看不出来。
19. 摄像头图像处理ISP初步介绍

我们看一看车载摄像头模组的关键参数,是不是还有几个没有阐述,比如白平衡、自动增益控制、色彩还原等等,上述摄像头描述就是主机控制,这里就有一个关键器件需要讲解一下,图像信号处理器ISP,这些活都是图像处理器ISP需要干的活。
下图展示了车载系统的基本组成:黄色的箭头代表数据的传输,蓝色的箭头代表控制信号的传输

相机的图像处理流程大致是这样的:
从相机感受到电荷之后,转化成每个像素的数字信号,它的输出我们可以叫做一个bayer pattern,当bayer pattern进入到ISP之后,经过一系列的图像处理才会变成可以正常预览或者拍照形成的图像。
图像处理中有一些比较关键的步骤,比如我们会做白平衡,因为人眼的视觉会对所看见的颜色做一定的纠正,比如看在黄光照射的范围里,我们看到的黄光打亮白纸不再是白纸。所以很重要的是白平衡的矫正,白平衡的矫正之后会做demosaic,将每个像素的全部颜色通道全部还原回来。
然后每个Sensor的特性或者因为一些原因导致的偏色,需要通过颜色校正的矩阵乘法来做更正。再之后需要转到ycbcr域去做例如针对亮度通道或颜色通道的降噪或者补偿。总体来说,这是一个非常简单的流程,实际上在车载应用中的流程非常复杂,涉及到更多的如HDR多帧曝光,合成,tone mapping等算法。
ISP 放置的位置非常关键:
这里有的是会放置ISP图像处理芯片在摄像头这边,把处理后的信号传输给到主机,有的是不放置ISP芯片,由主机那边的内置ISP芯片进行图像处理,这样摄像头端的散热会好很多,辐射也小。
比如倒车后视摄像头,摄像头距离主机距离都是5-8米,根据车身长度决定,这部分一般是把ISP放置在摄像头模组那端,这样传输过来的信号都是ISP那边进行降噪处理后的信号,抗干扰能力也更强,缺点就是体积会变大,散热要求非常高。
譬如有的行车记录仪DVR摄像头,这部分摄像头距离控制主机CPU非常近,而且对于造型要求也比较高,就会把ISP放置在CPU这边(很多DVR的CPU都内置了ISP芯片),无论是成本还是设计都是最优方案。
前面有提到了,摄像头出来的信号一定要经过ISP处理,那ISP要怎么处理这些信号,有哪些处理,这些其实都是涉及到色彩相关的内容,首先我们进行色彩相关内容的科普,然后再讲解ISP怎么处理这些信号。
camera sensor效果的调整,涉及到众多的参数,如果对基本的光学原理及sensor软/硬件对图像处理的原理能有深入的理解和把握的话,对我们的工作将会起到事半功倍的效果。否则,缺乏了理论的指导,只能是凭感觉和经验去碰,往往无法准确的把握问题的关键,不能掌握sensor调试的核心技术,无法根本的解决问题。
20. 色彩原理
人眼对色彩的识别,是基于人眼对光线存在三种不同的感应单元,不同的感应单元对不同波段的光有不同的响应曲线的原理,通过大脑的合成得到色彩的感知。一般来说,我们可以通俗的用RGB三基色的概念来理解颜色的分解和合成。
理论上,如果人眼和sensor对光谱的色光的响应,在光谱上的体现如下的话,基本上对三色光的响应,相互之间不会发生影响,没有所谓的交叉效应。

但是,实际情况并没有如此理想,下图表示了人眼的三色感应系统对光谱的响应情况。可见RGB的响应并不是完全独立的。

下图则表示了某Kodak相机光谱的响应。可见其与人眼的响应曲线有较大的区别。

21. sensor的色彩感应的校正
既然我们已经看到sensor对光谱的响应,在RGB各分量上与人眼对光谱的响应通常是有偏差的,当然就需要对其进行校正。不光是在交叉效应上,同样对色彩各分量的响应强度也需要校正。通常的做法是通过一个色彩校正矩阵对颜色进行一次校

该色彩校正的运算通常是由sensor模块集成或后端的ISP完成,软件通过修改相关寄存器得到正确的校正结果。值得注意的一点是,由于RGB -> YUV的转换也是通过一个3*3的变换矩阵来实现的,所以有时候这两个矩阵在ISP处理的过程中会合并在一起,通过一次矩阵运算操作完成色彩的校正和颜色空间的转换。
22. 颜色空间及变化
实际上颜色的描述是非常复杂的,比如RGB三基色加光系统就不能涵盖所有可能的颜色,出于各种色彩表达,以及色彩变换和软硬件应用的需求,存在各种各样的颜色模型及色彩空间的表达方式。这些颜色模型,根据不同的划分标准,可以按不同的原则划分为不同的类别。

对于sensor来说,我们经常接触到的色彩空间的概念,主要是RGB,YUV这两种(实际上,这两种体系包含了许多种不同的颜色表达方式和模型,如sRGB,Adobe RGB,YUV422,YUV420 …),RGB如前所述就是按三基色加光系统的原理来描述颜色,而YUV则是按照 亮度,色差的原理来描述颜色。
不比其它颜色空间的转换有一个标准的转换公式,因为YUV在很大程度上是与硬件相关的,所以RGB与YUV的转换公式通常会多个版本,略有不同。
常见的公式如下:
Y = 0.30R + 0.59G + 0.11B
U = 0.493(B - Y) = - 0.15R - 0.29G + 0.44B
V = 0.877(R - Y) = 0.62R - 0.52G - 0.10B
但是这样获得的YUV值存在着负值以及取值范围上下限之差不为255等等问题,不利于计算机处理,所以根据不同的理解和需求,通常在软件处理中会用到各种不同的变形的公式,这里就不列举了。
体现在Sensor上,我们也会发现有些Sensor可以设置YUV的输出取值范围。原因就在于此。
从公式中,我们关键要理解的一点是,UV 信号实际上就是蓝色差信号和红色差信号,进而言之,实际上一定程度上间接的代表了蓝色和红色的强度,理解这一点对于我们理解各种颜色变换处理的过程会有很大的帮助。
23. 色温定义
色温的定义:将黑体从绝对零度开始加温,温度每升高一度称为1开氏度(用字母K来表示),当温度升高到一定程度时候,黑体便辐射出可见光,其光谱成份以及给人的感觉也会着温度的不断升高发生相应的变化。于是,就把黑体辐射一定色光的温度定为发射相同色光光源的色温

常见光源色温:

随着色温的升高,光源的颜色由暖色向冷色过渡,光源中的能量分布也由红光端向蓝光端偏移。
值得注意的是,实际光源的光谱分布各不相同,而色温只是代表了能量的偏重程度,并不反映具体的光谱分布,所以即使相同色温的光源,也可能引起不同的色彩反应。
人眼及大脑对色温有一定的生理和心理的自适应性,所以看到的颜色受色温偏移的影响较小,而camera的sersor没有这种能力,所以拍出来的照片不经过白平衡处理的话,和人眼看到的颜色会有较大的偏差(虽然人眼看到的和白光下真实的色彩也有偏差)。
太阳光色温随天气和时间变化的原因,与不同频率光的折射率有关:

波长长的光线,折射率小,透射能力强,波长短的光线,折射率大,容易被散射,折射率低,这也就是为什么交通灯用红色,防雾灯通常是黄色,天空为什么是蓝色的等等现象的原因。
知道了这一点,太阳光色温变化的规律和原因也就可以理解和分析了。
24. 色温变化时的色彩校正
所以从理论上可以看出,随着色温的升高,要对色温进行较正,否则,物体在这样的光线条件下所表现出来的颜色就会偏离其正常的颜色,因此需要降低sensor对红色的增益,增加sersor对蓝光的增益。
同时在调整参数时一定程度上要考虑到整体亮度的要保持大致的不变,即以YUV来衡量时,Y值要基本保持不变,理论上认为可以参考RGB->YUV变换公式中,RGB三分量对Y值的贡献,从而确定RGAIN和BGAIN的变化的比例关系。但实际情况比这还要复杂一些,要考虑到不同sensor对R,B的感光的交叉影响和非线性,所以最佳值可能和理论值会有一些偏差。
25. 自动白平衡处理
自动白平衡是基于假设场景的色彩的平均值落在一个特定的范围内,如果测量得到结果偏离该范围,则调整对应参数,校正直到其均值落入指定范围。该处理过程可能基于YUV空间,也可能基于RGB空间来进行。对于Sensor来说,通常的处理方式是通过校正R/B增益,使得UV值落在一个指定的范围内。从而实现自动白平衡。
特殊情况的处理
在自动白平衡中,容易遇到的问题是,如果拍摄的场景,排除光线色温的影响,其本身颜色就是偏离平均颜色值的,比如大面积的偏向某种颜色的图案如:草地,红旗,蓝天等等,这时候,强制白平衡将其平均颜色调整到灰色附近,图像颜色就会严重失真。
因此,通常的做法是:在处理自动白平衡时,除了做为目标结果的预期颜色范围外,另外再设置一对源图像的颜色范围阙值,如果未经处理的图像其颜色均值超出了该阙值的话,根本就不对其做自动白平衡处理。由此保证了上述特殊情况的正确处理。
可见,这两对阙值的确定对于自动白平衡的效果起着关键性的作用。
某平台的例子

可以看到随着色温的升高,其变化规律基本符合上节中的理论分析。不过这里多数参数与理论值都有一些偏差,其中日光灯的色温参数设置与理论值有较大的偏差,实际效果也证明该日光灯的参数设置使得在家用日光灯环境下拍摄得到的照片颜色偏蓝。修改其参数后实拍效果明显改善。(再查一些资料可以看到通常会有两种荧光灯色温 4000 和 5000K,目前所接触到的应该是5000K居多)
具体参数的调整,应该在灯箱环境下,使用各种已知色温的标准光源对标准色卡拍摄,在Pc机上由取色工具测量得到其与标准色板的RGB分量上的色彩偏差,相应的调整各分量增益的比例关系。为了更精确的得到结果,曝光量增益的设置在此之前应该相对准确的校正过。
26. 亮度及曝光控制篇
26.1. 感光宽容度
从最明亮到最黑暗,假设人眼能够看到一定的范围,那么胶片(或CCD等电子感光器件)所能表现的远比人眼看到的范围小的多,而这个有限的范围就是感光宽容度。
人眼的感光宽容度比胶片要高很多,而胶片的感光宽容度要比数码相机的ccd高出很多!了解这个概念之后,我们就不难了解,为什么在逆光的条件下,人眼能看清背光的建筑物以及耀眼的天空云彩。而一旦拍摄出来,要么就是云彩颜色绚烂而建筑物变成了黑糊糊的剪影,要么就是建筑物色彩细节清楚而原本美丽的云彩却成了白色的一片。
再看人眼的结构,有瞳孔可以控制通光量,有杆状感光细胞和椎状感光细胞以适应不同的光强,可见即使人眼有着很高的感光宽容度,依然有亮度调节系统,以适应光强变化。
那么对于camera sensor来说,正确的曝光就更为重要了!
26.2. 自动曝光和18%灰
对于sensor来说,又是如何来判断曝光是否正确呢?很标准的做法就是在YUV空间计算当前图像的Y值的均值。调节各种曝光参数设定(自动或手动),使得该均值落在一个目标值附近的时候,就认为得到了正确的曝光。
那么如何确定这个Y的均值,以及如何调整参数使得sensor能够将当前图像的亮度调整到这个范围呢?
这就涉及到一个概念 18%灰,一般认为室内室外的景物,在通常的情况下,其平均的反光系数大约为18%,而色彩均值,如前所述,可以认为是一种中灰的色调。这样,可以通过对反光率为18%的灰板拍摄,调整曝光参数,使其颜色接近为中等亮度的灰色(Y值为128)。然后,对于通常的景物,就能自动的得到正确的曝光了。

当然这种自动判断曝光参数的AE功能不是万能的,对于反光率偏离通常均值的场景,比如雪景,夜景等,用这种方法就无法得到正确的曝光量了。所以在sensor的软件处理模块中,通常还会提供曝光级别的设定功能,强制改变自动曝光的判断标准。比如改变预期的亮度均值等。
26.3. 曝光参数的调整
曝光强度的调整,可以通过改变曝光时间,也可以通过改变亮度增益AG来实现。
曝光时间受到桢频的限制,比如摄像时要求15帧每秒的话,这时候曝光时间最长就不能超过1/15s,可能还有别的条件限制,实际的曝光时间还要短,在光线弱的情况下,单独调整曝光时间就无法满足帧频的需要了。
这时候还可以调整增益AG,来控制曝光的增益,降低曝光时间。但是,这样做的缺点是以牺牲图像质量为代价的,AG的增强,伴随的必然是信噪比的降低,图像噪声的增强。
所以,以图像质量为优先考虑的时候,曝光参数的调节通常是优先考虑调节曝光时间,其次在考虑曝光增益。当然曝光时间也不能过长以免由于抖动造成图像的模糊,而在拍摄运动场景时,对曝光时间的要求就更高了。
27. 抗噪处理
AG 的增大,不可避免的带来噪点的增多,此外,如果光线较暗,曝光时间过长,也会增加噪点的数目(从数码相机上看,主要是因为长时间曝光,感光元件温度升高,电流噪声造成感光元件噪点的增多),而感光元件本身的缺陷也是噪点甚至坏点的来源之一。因此,通常sensor集成或后端的ISP都带有降噪功能的相关设置。
27.1. 启动时机
根据噪点形成的原因,主要是AG或Exptime超过一定值后需要启动降噪功能,因此通常需要确定这两个参数的阙值,过小和过大都不好。
从下面的降噪处理的办法将会看到,降噪势附带的带来图像质量的下降,所以过早启动降噪功能,在不必要的情况下做降噪处理不但增加处理器或ISP的负担,还有可能适得其反。而过迟启动降噪功能,则在原本需要它的时候,起不到相应的作用。
27.2. 判定原则和处理方式
那么如何判定一个点是否是噪点呢?我们从人是如何识别噪点的开始讨论,对于人眼来说,判定一个点是噪点,无外乎就是这一点的亮度或颜色与边上大部分的点差异过大。从噪点产生的机制来说,颜色的异常应该是总是伴随着亮度的异常,而且对亮度异常的处理工作量比颜色异常要小,所以通常sensor ISP的判定原则是一个点的亮度与周围点的亮度的差值大于一个阙值的时候,就认为该点是一个噪点。
处理的方式,通常是对周围的点取均值来替代原先的值,这种做法并不增加信息量,类似于一个模糊算法。
对于高端的数码相机,拥有较强的图像处理芯片,在判定和处理方面是否有更复杂的算法,估计也是有可能的。比如亮度和颜色综合作为标准来判定噪点,采用运算量更大的插值算法做补偿,对于sensor固有的坏点,噪点,采用屏蔽的方式抛弃其数据(Nikon就是这么做的,其它厂商应该也如此)等等。
27.3. 效果
对于手机sensor来说,这种降噪处理的作用有多大,笔者个人认为应该很有限,毕竟相对数码相机,手机sensor的镜头太小,通光量小,所以其基准AG势必就比相机的增益要大(比如相当于普通家用数码相机ISO800的水平),这样才能获得同样的亮度,所以电流噪声带来的影响也就要大得多。
这样一来,即使最佳情况,噪点也会很多,数据本身的波动就很大,这也就造成我们在手机照片上势必会看到的密密麻麻的花点,如果全部做平均,降低了噪点的同时,图像也会变得模糊,所以手机噪点的判断阙值会设得比较高,以免涉及面过大,模糊了整体图像。这样一来一是数据本身就差,二是降噪的标准也降低了,造成总体效果不佳。
28. 变焦
28.1. 通过插值算法
对图像进行插值运算,将图像的尺寸扩大到所需的规格,这种算法就其效果而言,并不理想,尤其是当使用在手机上的时候,手机上的摄像头本身得到的数据就有较大的噪声,再插值的话,得到的图像几乎没法使用。实际上,即使是数码相机的数码变焦功能也没有太大的实用价值。如果插值算法没有硬件支持,则需要在应用层实现。我司某平台的数码变焦用的就是该种办法。
28.2. 一种伪数码变焦的形式
当摄像头不处在最大分辨率格式的情况下,比如130万像素的sensor使用640*480的规格拍照时,仍旧设置sersor工作在1280*960的分辨率下,而后通过采集中央部分的图像来获取640*480的照片,使得在手机上看来所拍物体尺寸被放大了一倍。也有很多手机采用的是这种数码变焦方式,这种办法几乎不需要额外的算法支持,对图像质量也没有影响,缺点是只有小尺寸情况下可以采用。此外在DV方式下也可以实现所谓的数码变焦放大拍摄功能。(这应该是一个卖点,对Dv来说,这种数码变焦还是有实际意义的)要采用这种变焦模式,驱动需要支持windowing功能,获取所需部分的sensor图像数据。
29. 频闪抑制功能
何谓频闪
日常使用的普通光源如白炽灯、日光灯、石英灯等都是直接用220/50Hz交流电工作,每秒钟内正负半周各变化50次,因而导致灯光在1秒钟内发生100(50×2)次的闪烁,再加上市电电压的不稳定,灯光忽明忽暗,这样就产生了所谓的“频闪”。
下表显示了几种光源的光强波动情况:

因为人眼对光强变化有一定的迟滞和适应性,所以通常看不出光源的亮度变化。但是依然还是会增加眼睛的疲劳程度。所以市场上才会有所谓的无频闪灯销售。
如今主流车载摄像头的像素并不高,通常在200万以下,但对可靠性、耐温、实时性等要求都高于消费级产品。此外针对流媒体后视镜,以及变道预警、车道保持等驾驶辅助功能,有一个很重要的要求是消除LED灯闪烁现象,这是车载应用的特殊要求。
对于camera sensor来说,没有人眼的迟滞和适应过程,所以对光源亮度的变化是比较敏感的。如果不加抑制,在预览和DV模式下,可能会有明显的图像的明亮变化闪烁的现象发生。
在视频处理上,“LED闪烁”是指在录像时拍摄到的LED灯闪烁的状况。

“LED闪烁”是由LED驱动方式而产生的现象,LED灯以交流方式驱动,为让人眼感觉不到闪烁及亮暗变化,驱动频率一般在90Hz以上,即最慢脉冲周期为11毫秒左右,LED在11毫秒周期内实现一次亮灭,为节能及延长使用寿命,占空比通常不超过50%,如果相机曝光时间较短(例如3毫秒),则有可能曝光时间正好对上LED被关灭期,这时候图像传感器抓到的就是LED灭掉的图像,如果是LED阵列,在这种情况下拍到的图像将可能是一部分亮,一部分暗,这就是“LED闪烁”现象。

因此,LED闪烁是数字成像技术所固有的现象,拍摄到的闪烁是由于曝光时间横跨LED交流驱动亮暗周期而造成,是“真正”的影像。但这样“真正”的影像,传输到监视屏幕由人类或电子系统来识别时,会造成误判。如果流媒体后视镜没有防LED闪烁能力,遇到配备了LED车灯的汽车时,容易导致危险,驾驶者可能将图像传感器传出的闪烁车灯误认作转向灯或双闪灯。
在高级驾驶辅助系统中,LED闪烁造成的危害更大。LED闪烁会导致系统无法正常检测电子路标与交通信号灯,无法区分转向灯与车尾灯。
如何解决呢?考虑到频闪的周期性,在一个周期内,光源亮度的累积值,应该是大体一致的,所以,如果控制曝光的时间是频闪周期的整倍数,那么每一帧图像的亮度就大体是一致的了,这样就可以有效地抑制频闪对图像亮度的影响。
所以,在自动曝光的模式下,sensor会根据频闪的频率,调整曝光时间为其周期的整倍数。因为各地的交流电的频率不同,所以有50Hz/60Hz之分。
在具体设置相关Sensor寄存器的时候,要根据电流频率和sensor的时钟频率,分辨率等,计算出频闪周期对应的时钟周期数等。

分离像素技术图像传感器中,有大小两种像素,其中小像素降低敏感度,延长曝光时间,保证最慢速率驱动LED的每一个周期的亮起时间都被捕捉到,大像素曝光时间维持正常,两种像素获取的图像做合成处理,最终得到的图像将不会有闪烁现象。
因为小像素的动态范围有限,所以这种解决方案最终还是会牺牲一些动态范围,难以将图像传感器的全部动态范围发挥出来。但汽车应用场景复杂,经常会遭遇亮暗变化大的场景,所以对动态范围的要求一直很高,如果能在高动态范围基础上实现去闪烁功能,显然能应用到更广泛的场景中。
豪威科技推出的图像处理器(ISP)OAX4010,可以在不牺牲动态范围的基础上,实现去闪烁功能。OAX4010搭配OX01A10/OX02A10,可以对一帧图像在“像素单元级实现三次曝光”,即长曝光、短曝光和超短曝光,然后ISP对这三幅图像进行实时处理,在去闪烁(需要长时间曝光)的同时,维持住120dB的动态范围。
30. 摄像头ISP的关键信号处理
其实前面学习了图像和色彩相关内容,我们可以知道,ISP需要处理的内容还蛮多的,我们最常见的就是畸变校正,白平衡,去噪声、空间转换、WDR合成宽动态。

景物通过 Lens 生成的光学图像投射到 sensor 表面上,经过光电转换为模拟电信号,消噪声后经过 A/D 转换后变为数字图像信号,再送到数字信号处理芯片(DSP)中加工处理。所以,从 sensor 端过来的图像是 Bayer 图像,经过黑电平补偿、镜头矫正、坏像素矫正、颜色插值、Bayer 噪声去除、白平衡矫正、色彩矫正、gamma 矫正、色彩空间转换(RGB 转换为 YUV)、在 YUV 色彩空间上彩噪去除与边缘加强、色彩与对比度加强,中间还要进行自动曝光控制等,然后输出 YUV(或者 RGB)格式的数据,再通过 I/O 接口传输到 CPU 中处理。
我们以海思的ISP芯片支持的功能如下:
ISP 模块支持标准的Sensor图像数据处理,包括自动白平衡、自动曝光、Demosaic、坏点矫正及镜头阴影矫正等基本功能,也支持WDR、DRC、降噪等高级处理功能。
ISP 主要支持的图像处理功能如下:
支持黑电平校正
支持静态以及动态坏点校正,坏点簇矫正
支持 bayer 降噪
支持固定噪声消除
支持 demosaic 处理
支持紫边校正(CAC)
支持 gamma 校正
支持动态范围压缩(DRC)
支持 Sensor 内部合成宽动态功能(Sensor Built-in WDR)
Hi3559AV100 最大支持 4 合 1 宽动态功能(WDR),Hi3519AV100/Hi3516CV500 最大
支持 2 合 1 宽动态功能(WDR)
支持自动白平衡
支持自动曝光
支持自动对焦
支持 3A 相关统计信息输出
支持镜头阴影校正
支持图像锐化
支持数字防抖(Hi3516CV500 不支持)
支持自动去雾处理
支持颜色三维查找表增强
支持局部对比度增强
支持亮度着色(Hi3516CV500 不支持)
支持 3D 降噪
前面很多ISP处理的色彩相关内容已经有描述了,我们重点讲讲WDR 宽动态指标,这个在车载摄像头中对于自动驾驶非常非常重要的指标,譬如经常有机构反馈的太阳光太强的时候,摄像头拍出来的图片就曝光了,显示不清楚,或者由太阳很强的地方突然进入隧道,这个时候拍出来的图片就太暗,看不清楚内容,其实这个都和WDR宽动态指标密切相关。
31. 什么是sensor 的动态范围dynamic range
sensor的动态范围就是sensor在一幅图像里能够同时体现高光和阴影部分内容的能力,实际上就指的是摄像头同时可以看清楚图像最亮和最暗部分的照度对比。
用公式表达这种能力就是:
db
i_max 是sensor的最大不饱和电流—-也可以说是sensor刚刚饱和时候的电流 i_min是sensor的底电流(blacklevel);
为什么HDR在成像领域是个大问题?
在自然界的真实情况,有些场景的动态范围要大于100dB。
人眼的动态范围可以达到100dB。

上图的传感器只有16个象素,这些象素能在传感器曝光过程中迅速吸收光子。一旦这些象素满载,光子便会溢出。溢出会导致信息(细节)损失,以红色为例,高光溢出使满载红色的象素附近的其他象素的值都变成255,但其实它们的真实值并没有达到255。这样会造成高光部分的信息缺失,另一方面,用来描述昏暗环境的象素没有足够的时间接收光子量,得出的象素值为0,这样反而会导致昏暗部分的信息缺失。
Sensor 的动态范围:高端的 >78 dB; 消费级的 60 dB 上下;
所以当sensor的动态范围小于图像场景动态范围的时候就会出现HDR问题—-不是暗处看不清,就是亮处看不清,有的甚至两头都看不清。

暗处看不清–前景处的广告牌和树影太暗看不清。

亮处看不清–远处背景的白云变成了一团白色,完全看不清细节。
解决HDR问题的数学分析
根据前边动态范围公式
dB
从数学本质上说要提高DR,就是提高,减小
;
对于10bit输出的sensor,,
,动态范围DR = 60;
对于12bit输出的sensor,DR = 72;
所以从数学上来看,提高sensor 输出的bit width就可以提高动态范围,从而解决HDR问题。可是现实上却没有这么简单。提高sensor的bit width导致不仅sensor的成本提高,整个图像处理器的带宽都得相应提高,消耗的内存也都相应提高,这样导致整个系统的成本会大幅提高。所以大家想出许多办法,既能解决HDR问题,又可以不增加太多成本。
解决HDR问题的5种方法
从sensor的角度完整的DR 公式:

32. 解决高动态HDR的方法
解决HDR问题的常规有5种方法
从sensor的角度完整的DR 公式:
Qsat :Well Capacity idc: 底电流,tint:曝光时间,σ:噪声。
32.1. 提高Qsat –Well capacity
就是提高感光井的能力,这就涉及到sensor的构造,简单说,sensor的每个像素就像一口井,光子射到井里产生光电转换效应,井的容量如果比较大,容纳的电荷就比较多,这样i_max的值就更大。普通的sensor well只reset一次,但是为了提高动态范围,就产生了多次reset的方法。通过多次reset,imax增加到i‘max,上图就是current to charge的转换曲线。但这种方法的缺点是增加FPN,而且sensor的响应变成非线性,后边的处理会增加难度。
32.2. 多曝光合成
本质上这种方法就是用短曝光获取高光处的图像,用长曝光获取阴暗处的图像。有的厂家用前后两帧长短曝光图像,或者前后三针长、中、短曝光图像进行融合
If (Intensity > a) intensity = short_exposure_frame
If (Intensity < b) intensity = long_exposure_frame
If (b<Intensity <a) intensity = long_exposure_frame x p + short_exposure_frame x q当该像素值大于一个门限时,这个像素的数值就是来自于短曝光,小于一个数值,该像素值就来自于长曝光,在中间的话,就用长短曝光融合。这是个比较简化的方法,实际上还要考虑噪声等的影响。

Current to charge曲线显示:imax增加a倍。
这种多帧融合的方法需要非常快的readout time,而且即使readout时间再快,多帧图像也会有时间差,所以很难避免在图像融合时产生的鬼影问题。尤其在video HDR的时候,由于运算时间有限,无法进行复杂的去鬼影的运算,会有比较明显的问题。于是就出现了单帧的多曝光技术。
32.3. 单帧空间域多曝光
最开始的方法是在sensor的一些像素上加ND filter,让这些像素获得的光强度变弱,所以当其他正常像素饱和的时候,这些像素仍然没有饱和,不过这样做生产成本比较高,同时给后边的处理增加很多麻烦。所以下面的这种隔行多曝光方法更好些。

如上图所示,两行短曝光,再两行长曝光,然后做图像融合,这样可以较好的避免多帧融合的问题,从而有效的在video中实现HDR。同时由于video的分辨率比still要低很多,所以这个方法所产生的分辨率降低也不是问题。这个方法是现在video hdr sensor的主流技术。
32.4. logarithmic sensor
实际是一种数学方法,把图像从线性域压缩到log域,从而压缩了动态范围,在数字通信里也用类似的技术使用不同的函数进行压缩,在isp端用反函数再恢复到线性,再做信号处理。
缺点一方面是信号不是线性的,另一方面会增加FPN,同时由于压缩精度要求对硬件设计要求高。
32.5. 局部适应 local adaption
这是种仿人眼的设计,人眼会针对局部的图像特点进行自适应,既能够增加局部的对比度,同时保留大动态范围。这种算法比较复杂,有很多论文单独讨论。目前在sensor 端还没有使用这种技术,在ISP和后处理这种方法已经得到了非常好的应用。

上图就是用方法2 + 方法5处理后的HDR图像。亮处与暗处的细节都得到了很好的展现。
除了HDR sensor,HDR image processing也需要用相应的能力来支持HDR,例如:
Multi-Exposure Combining: 拿到数据之后使用合成方法合成;
High Bit-Depth Processing: 支持高带宽,比如12比特或20比特的图像数据处理;
Tone Mapping to Low Big-Depth: 通过非线性的压缩算法将高bit数据压缩到低bit数据,并保留相应的图像细节。
33. 车载图像处理芯片ISP处理模式
这里可以看到摄像头可以通过外置的ISP来满足HDR宽动态的要求,从而让机器能够很好的识别到图像内容,但是这也是一把双刃剑,我们可以看到很多情况下需要三帧合成一帧,对于需要自动驾驶快速处理图像内容来说,HDR的弊端就是导致整个图像的延迟变长了。
我们举最常见的摄像头为例,以60HZ的摄像头为例,一帧图像到下一帧图像的时间间隔为16.67ms,假如我们忽略传输过程中的延时,那么主机接收到下一帧率的图像至少需要16ms的间隔,此时如果我们启动HDR,三帧合成一帧,那么就相当于变为 20HZ的摄像头图像了,那么传输到主机的时间变为50ms的间隔,比原来16.67ms的时间延长了约为34ms,这个时间在高速行驶的时候,至关重要,按照120km/h的高速行驶,这个距离就已经是1.12米了。
特别是后拉摄像头过来的延时,会导致驾驶人员对于后面车距判断的失误,如果是单目摄像头机器做辅助驾驶,对于距离是通过两帧去计算距离的,这个对于距离的计算也会有很大的误差,所以HDR是一把双刃剑,如果要这部分宽动态HDR图像,那么摄像头的帧率必须提高,提高到120HZ的摄像头,这个时候成本又增加了,所以要以低成本不增加摄像头帧率情况下,做出非常好效果的HDR,这个对于ISP芯片及算法厂家来说都是一个考验。
所以一般ISP芯片有两种场景处理模式:主要包括线性模式和WDR 模式两种典型应用,内部是可以选择是否启动WDR宽动态。
线性模式的图像质量关注维度主要包括图像亮度合理性,色彩还原准确、图像整体清晰度锐利以及图像的整体通透性等;

WDR模式的图像质量关注维度主要包括图像整体的动态范围合理,即亮区不过曝,暗区细节能够看得见,色彩还原尽量准确、图像整体清晰度锐利以及图像整体通透性等维度。

ISP和图像相关内容阐述完,其实我们发现评价一个车载摄像头系统的指标,除了摄像头本身的分辨率、信噪比、灵敏度以为,还需要增加ISP处理图像的效果能力的重要指标。
白平衡处理能力、图像自动增益能力、色彩还原性、畸变和图像校正能力、FOV角度等等。
前面章节阐述了摄像头内部的工作原理,一系列的图像效果的处理,包括白平衡、畸变校正、色彩还原等一系列图像的处理,如果我们是做一台手机基本上到这里就结束了,处理完就给到显示屏做显示,但是这里的图像需要给到CPU主机做自动驾驶,涉及到自动驾驶的视觉技术,视觉技术需要解决的是“摄像头拍到的是什么物体。
摄像头拍到的图像,需要机器识别能读懂是什么物体,需要进行后续图像分割、物体分类、目标跟踪、世界模型、多传感器融合、在线标定、视觉SLAM、ISP 等一系列步骤进行匹配与深度学习,其核心环节在于物体识别与匹配,或者运用AI 自监督学习来达到感知分析物体的目的,需要解决的是“我拍到的东西是什么”的问题。
34. 图像分隔技术
数字图像处理是一个跨学科的领域,尽管其发展历史不长,但由于图像处理在军事、遥感、气象等大型应用中有不断增长的需求,并且心理学、生理学、计算机科学等诸多领域的学者们以数字图像为基础研究视觉感知,因此,针对图像处理和分析问题的新方法层出不穷,逐渐形成了自己的科学体系。
图像分割是图像分析的第一步,是计算机视觉的基础,是图像理解的重要组成部分,同时也是图像处理中最困难的问题之一。所谓图像分割是指根据灰度、彩色、空间纹理、几何形状等特征把图像划分成若干个互不相交的区域,简单的说就是在一副图像中,把目标从背景中分离出来。这里属于图像算法中的万里长征第一步,也是最重要的一步。
34.1. 基于深度学习的图像分割
目前,受到广泛关注的深度学习也应用于图像分割问题中。神经网络是深度学习中的重要方法,基于神经网络的图像分割方法的基本思想是通过训练多层感知机来得到线性决策函数,然后用决策函数对像素进行分类来达到分割的目的。这种方法需要大量的训练数据。神经网络存在巨量的连接,容易引入空间信息,能较好地解决图像中的噪声和不均匀问题。
什么是神经网络,什么是深度学习。
百度百科中对深度学习的定义是深度学习(DL, Deep Learning)是机器学习(ML, Machine Learning)领域中一个新的研究方向,它被引入机器学习使其更接近于最初的目标——人工智能(AI, Artificial Intelligence)。这个定义太大了,反而让人有点不懂,简答来说,深度学习就是通过多层神经网络上运用各种机器学习算法学习样本数据的内在规律和表示层次,从而实现各种任务的算法集合。各种任务都是啥,有:数据挖掘,计算机视觉,语音识别,自然语言处理等。
可能有人会问那么深度学习,机器学习还有人工智能的关系是怎么样的呢?在这个博客中有详细介绍:一篇文章看懂人工智能、机器学习和深度学习,我们这里直接拿出结论:
AI:让机器展现出人类智力
机器学习:抵达AI目标的一条路径
深度学习:实现机器学习的技术
深度学习从大类上可以归入神经网络,不过在具体实现上有许多变化,并不像大家听到的一样,觉得这两个概念其实是同一个东西
从广义上说深度学习的网络结构也是多层神经网络的一种。更简单来说,多层神经网络 做的步骤是:特征映射到值。特征是 人工 挑选。深度学习 做的步骤是 信号->特征->值。特征是由 网络自己 选择。
深度学习的核心是 特征学习,旨在通过分层网络获取分层次的特征信息,从而解决以往需要人工设计特征的重要难题。深度学习是一个框架,包含多个重要算法:
Convolutional Neural Networks(CNN)卷积神经网络
AutoEncoder自动编码器
Sparse Coding稀疏编码
Restricted Boltzmann Machine(RBM)限制波尔兹曼机
Deep Belief Networks(DBN)深度信念网络
Recurrent neural Network(RNN)多层反馈循环神经网络神经网络
对不同的任务(图像,语音,文本),需要选用不同的网络模型才能达到更好的效果。
此外,最近几年 增强学习(Reinforcement Learning) 与深度学习的结合也创造了许多了不起的成果,AlphaGo就是其中之一。
34.2. 人类视觉原理
深度学习的许多研究成果,离不开对大脑认知原理的研究,尤其是视觉原理的研究。
1981 年的诺贝尔医学奖,颁发给了 David Hubel(出生于加拿大的美国神经生物学家) 和TorstenWiesel,以及 Roger Sperry。前两位的主要贡献,是“发现了视觉系统的信息处理”——可视皮层是分级的。如下图所示

进而通过大量试验研究,发现了人类的视觉原理,具体如下:从原始信号摄入开始(瞳孔摄入像素 Pixels),接着做初步处理(大脑皮层某些细胞发现边缘和方向),然后抽象(大脑判定,眼前的物体的形状,是圆形的),然后进一步抽象(大脑进一步判定该物体是只气球)。
下面是人脑进行人脸识别的一个示例。如下图所示:

总的来说,人的视觉系统的信息处理是分级的。从低级的V1区提取边缘特征,再到V2区的形状或者目标的部分等,再到更高层,整个目标、目标的行为等。也就是说高层的特征是低层特征的组合,从低层到高层的特征表示越来越抽象,越来越能表现语义或者意图。而抽象层面越高,存在的可能猜测就越少,就越利于分类。
对于不同的物体,人类视觉也是通过这样逐层分级,来进行认知的。如下图所示:

那么可以很自然的想到:可以不可以模仿人类大脑的这个特点,构造多层的神经网络,较低层的识别初级的图像特征,若干底层特征组成更上一层特征,最终通过多个层级的组合,最终在顶层做出分类呢?答案是肯定的,这也是许多深度学习算法(包括CNN)的灵感来源。
34.3. 神经网络
首先什么是神经网络呢?神经网络也指的是人工神经网络(Artificial Neural Networks,简称ANNs),是一种模仿生物神经网络行为特征的算法数学模型,由神经元、节点与节点之间的连接(突触)所构成,如下图所示:

每个神经网络单元抽象出来的数学模型如下,也叫感知器,它接收多个输入,产生一个输出,这就好比是神经末梢感受各种外部环境的变化(外部刺激),然后产生电信号,以便于转导到神经细胞(又叫神经元)。如下图所示:

单个的感知器就构成了一个简单的模型,但在现实世界中,实际的决策模型则要复杂得多,往往是由多个感知器组成的多层网络,如下图所示,这也是经典的神经网络模型,由输入层、隐含层、输出层 构成。如下图所示:

人工神经网络可以映射任意复杂的非线性关系,具有很强的鲁棒性、记忆能力、自学习等能力,在分类、预测、模式识别等方面有着广泛的应用。
35. 具体在图像分隔中的神经网络算法:
具体原理如下:
通过下采样+上采样:Convlution + Deconvlution/Resize
结合多尺度特征融合:特征逐点相加/特征channel维度拼接
像素级别的segbement map:对每一个像素点进行判断类别
网络结构的选择将直接影响图像分割效果,常见的网络结构包括:VGG、FCN、Deconvnet、SegNet、Mask-RCNN。Image Segmentation(图像分割)网络结构比较。

在图像分割的发展过程中,按照目的不同,逐渐从普通分割发展到语义分割,再从语义分割发展到实例分割:
- 普通分割将不同分属不同物体的像素区域分开。如前景与后景分割开,狗的区域与猫的区域与背景分割开。
- 语义分割在普通分割的基础上,分类出每一块区域的语义(即这块区域是什么物体)。如把画面中的所有物体都指出它们各自的类别。
- 实例分割在语义分割的基础上,给每个物体编号。如这个是该画面中的汽车A,那个是画面中的汽车B。
实例分割是目前最具挑战的任务之一,下面将主要对基于Mask R-CNN的主流图像分割方法和实例分割新方法Deep Snake进行介绍。
图像分割技术发展至今,Mask R-CNN 的Pipeline几乎是目前做instance segmentation的大多数工作参考的方案。

Mask R-CNN将Object Detection与Semantic Segmentation合在了一起做。它的特点主要有以下几点:
第一,神经网络有了多个通道输出。Mask R-CNN使用类似Faster R-CNN的框架,Faster R-CNN的输出是物体的bounding box和类别,而Mask R-CNN则多了一个通道,用来预测物体的语义分割图。也就是说神经网络同时学习两项任务,可以互相得到反馈,训练模型参数权重。
第二,在语义分割中使用Binary Mask。原来的语义分割预测类别需要使用0 1 2 3 4等数字代表各个类别。在Mask R-CNN中,检测分支会预测类别。这时候分割只需要用0 1预测这个物体的形状面具就行了。
第三,Mask R-CNN基本的pipeline是先检测物体矩形框,然后在矩形框中做逐像素分割。并且提出了RoiAlign用来替换Faster R-CNN中的RoiPooling。RoiPooling的思想是将输入图像中任意一块区域对应到神经网络特征图中的对应区域。RoiPooling使用了化整的近似来寻找对应区域,导致对应关系与实际情况有偏移。这个偏移在分类任务中可以容忍,但对于精细度更高的分割则影响较大。为了解决这个问题,RoiAlign不再使用化整操作,而是使用线性插值来寻找更精准的对应区域。效果就是可以得到更好地对应。实验也证明了效果不错。
但是这样的处理方式其实有一些局限性,也是今天本文主要介绍的Deep Snake在处理实例分割时擅长解决的问题:
- 在Mask R-CNN矩形框中做逐像素分割会受限于矩形框的准确度。
如果矩形框精度差,如覆盖到一部分物体,那就算框中的分割精度做的再高,也无法得到正确的instance mask。
- 逐像素分割在生产和后续计算中计算量巨大
因为逐像素分割计算量大,所以网络一般将矩形框区域downsample为28x28的网格,然后进行分割,之后再把分割结果upsample到原图大小。这个upsample根据Mask R-CNN论文里的统计是有15ms的,比较费时。另一个问题是,在28x28网格上做分割会损失精度。即使28x28的网格上的分割结果完全正确,upsample到原图的mask仍然是很粗糙的。
- 逐像素分割不适用于一些物体
比如细胞和文本,因此不适合OCR(光学字符识别)。
36. Deep Snake
针对主流图像分割方法在实例分割中面对的问题,Deep Snake考虑到逐像素分割有诸多限制,因此选择用contour来表示物体的形状。contour是一组有序的点,而且是首尾相连的。比如图片中猫的边缘就是一个contour。

与稠密像素相比contour的两大优势
- 计算量远远小于稠密像素,参数量也比较少。
这样使得实例的分割的速度上限更高,也能更廉价地使用分割结果。这里举个例子就是跟踪任务。现在跟踪任务主要还是使用box做跟踪,用物体的像素点做跟踪任务计算量会很大。如果把像素点换成用contour做跟踪任务就会好很多。因此contour也更适用于细胞、文字这些物体的分割。
- 传统的图像分割领域一直都有用contour做分割。
有一个很经典的论文是Snakes:Active contour models. [2]。而本文中介绍的方法DeepSnake,顾名思义其实就是用深度学习的方法实现了传统Snake。传统Snake做图像分割的时候要求先给定一个初始的 contour。这个contour大概围绕着目标物体。
Deep Snake的优化
传统Snake的一个很大问题是他的目标函数和最优化都是人工设定的,对数据的噪声比较敏感,容易收敛到局部最优点。为了解决这个问题,Deep Snake用深度学习来做这个优化过程。
contour是一组有序的、首尾相连的点,可以看作一个cycle graph。这种cycle graph每个节点的邻居节点为2,顺序固定,所以可以定义卷积核。论文引入Circular convolution来处理contour,下图是Circular convolution的示例图:

- Blue nodes 代表定义在contour的 输入特征值

- Yellow nodes 代表卷积核,Green nodes为卷积输出,circular convolution为

和传统Snake类似,给定一个初始 contour,基于图片的特征图,给contour的每个节点提取一个特征值,得到一个定义在contour上的特征。然后用Circular convolution构成的网络进行contour上的特征工程,最后映射为指向物体轮廓的补偿,用于变形contour。
传统的Snake要求有一个比较准确的初始化 contour才能比变形得比较好,所以初始化contour对后续的变形十分关键。
受到ExtremeNet的影响,作者用物体extreme points来构造初始contour。物体的extreme point是物体在图片中最上边、最左边、最下边和最右边的点。在每个点上延伸出一条线段,然后将线段连接起来,得到一个八边形,把这个八边形作为initial contour。

- 通过预测extreme point来得到initial contour,然后将initial contour变形为物体边缘:

- 用detector检测得到一个矩形框,将矩形框四条边的中点连接起来,就得到一个菱形contour。通过Deep Snake来处理这个轮廓,从而得到extreme point。用extreme point构造Octagon contour,然后用Deep Snake来处理这个contour,从而得到物体轮廓。
37. 特斯拉图像识别原理阐述

特斯拉利用8个摄像头来识别现实世界中的物体。摄像头获取的图像包括行人、其他车辆、动物或障碍物,这不仅对特斯拉车辆驾驶员的安全很重要,对其他人也很重要。专利称,重要的是,摄像头能够及时准确地识别这些物体。


从算法的代码层面来说,特斯拉把它们的深度学习网络称为HydraNet。其中,基础算法代码是共享的,整个HydraNet包含48个不同的神经网络,通过这48个神经网络,就能输出1000个不同的预测张量。理论上来说,特斯拉的这个超级网络,能同时检测1000种物体。完成这些运算并不简单,特斯拉已经耗费了7万个GPU小时进行深度学习模型训练。

虽然工作量很大,但由于大部分工作由机器承担,特斯拉的人工智能团队仅由几十人组成,与其他自动驾驶公司数百人甚至数千人的规模相比,确实规模不大。
完成2D的图像还不算牛掰的,毕竟云端有超级计算机可以去训练,本地的芯片也是自己开发的,可以很好的匹配算法,特斯拉真正牛掰的地方,通过视觉完成3D的深度信息,并可以通过视觉建立高精度地图,完成一些底下停车场的附件驾驶场景。
特斯拉全车共配备了8个摄像头,一个毫米波雷达和12个超声波雷达,监测外部环境,向自动驾驶电脑实时传送信息。

简单来看,特斯拉的摄像头、毫米波雷达、超声波雷达以及惯性测量单元记录下当前车辆所处的环境数据,并将数据发送给特斯拉的自动驾驶电脑。自动驾驶电脑在进行算法的计算之后,将速度和方向信息传递给转向舵以及加速、制动踏板,实现对车辆的控制。
不过,在日常行驶过程中,摄像头作为传感器捕捉的内容都是二维图像,并没有深度信息。

也就是说,虽然二维图像已经可以区分公路和路旁的人行道,但并不知道现在车辆距离“马路牙子”还有多远。由于缺失这样一个重要信息,自动驾驶的运算可能并不准确,操作可能出错。因此,捕捉或者建立一个三维的图景很有必要。
特斯拉使用三目相机的,它可以通过比较两个摄像头图像的差异判断物体的远近,获得物体的深度信息。通过中央处理器对输入图像进行感知、分割、检测、跟踪等操作,输出给导航网络端进行语义建图及匹配定位,同时通过目标识别形成相应的ADAS系统目标属性。
特斯拉还有更厉害的地方,那就是算法可以预测流媒体视频中每一个像素的深度信息。也就是说,只要算法足够好,流媒体视频更加清晰,特斯拉的视觉传感器所捕捉的深度信息甚至可以超过激光雷达。

在实际的自动驾驶应用中,泊车入位和智能召唤两个使用场景下就能充分利用这套算法。在停车场行驶时,车辆之间的距离很小,即使是驾驶员驾驶,稍不留神也很容易出现刮蹭事故。对于机器来说,停车场场景的行驶更加困难。在预测到深度信息之后,车辆可以在超声波雷达的辅助之下,快速完成对周围环境的识别,车辆泊车就会更加顺利。
在完成深度信息的预测之后,这部分信息会显示在车机上,同时也会直接参与控制转向、加速、制动等驾驶动作。不过,转向、加速、制动这些驾驶策略没有固定的规则,有一定灵活性。因此,自动驾驶的驾驶策略没有最佳,只有更好。
怎么提高神经网络的算法效率:
为什么这么多厂家只有百度敢挑战视觉为主的辅助驾驶方案,不使用激光雷达,其中很大一个原因就是神经网络算法相当耗费芯片算力和内存资源,本地端的芯片要算力足够强大,对于神经网络的算法要有优化。

对于神经网络来说,其实很多的连接并不是一定要存在的,也就是说我去掉一些连接,可能压缩后的网络精度相比压缩之前并没有太大的变化。基于这样的理念,很多剪枝的方案也被提了出来,也确实从压缩的角度带来了很大效果提升。
需要特别提出的是,大家从图中可以看到,深度学习神经网络包括卷积层和全连接层两大块,剪枝对全连接层的压缩效率是最大的。下面柱状图的蓝色部分就是压缩之后的系数占比,从中可以看到剪枝对全连接层的压缩是最大的,而对卷积层的压缩效果相比全连接层则差了很多。
所以这也是为什么,在语音的加速上很容易用到剪枝的一些方案,但是在机器视觉等需要大量卷积层的应用中剪枝效果并不理想。

对于整个Deep Learning网络来说,每个权重系数是不是一定要浮点的,定点是否就能满足?定点是不是一定要32位的?很多人提出8位甚至1位的定点系数也能达到很不错的效果,这样的话从系数压缩来看就会有非常大的效果。从下面三张人脸识别的红点和绿点的对比,就可以看到其实8位定点系数在很多情况下已经非常适用了,和32位定点系数相比并没有太大的变化。所以,从这个角度来说,权重系数的压缩也会带来网络模型的压缩,从而带来计算的加速。
这些都需要非常资深的软件算法团队去优化,同时需要懂得底层芯片的资源情况,而百度在人工算法这方面非常具有优势,所以有勇气去挑战视觉为主的自动驾驶 Apollo Lite方案。
百度表示,摄像头是相对成熟的传感器,除具备轻巧低成本和符合车规的优势外,高分辨率高帧率(成像频率)的成像技术发展趋势意味着图像内蕴含的环境信息更丰富,同时视频数据也和人眼感知的真实世界最为相似,但和三维点云数据相比,二维图像中的信息更难挖掘,需要设计更强大的算法、大量数据的积累和更长期的研发投入。
近年来,汽车ADAS高级驾驶辅助系统装车率正在快速增长。纵览各大厂商,这些技术基本上集中在L2-L3级自动驾驶,而为了实现这些功能,单车感知系统中,摄像头的使用量基本上都在5个以上。比如说特斯拉8个、小鹏P7为14个、威马W6是7个、而背靠阿里巴巴与上汽的智己汽车将之增加到15个。

这些摄像头都分布在哪里,一个智能汽车至少要多少个摄像头呢,主要功能是什么作用呢,这些摄像头的角度和像素要求都有什么不同?
38. ADAS摄像头分类

从主流车企代表车型的自动驾驶感知方案来看,都广泛采用了多种传感器融合的方案。以通用 Cruise AV 为例,通用目标是实现 L4 级别的自动驾驶,全车搭载 5 个 Velodyne 的 VLP16 16 线激光雷达、21 个毫米波雷达(其中有 12 个由日本 ALPS 提供的 79GHz 的毫米波雷达)以及16 个摄像头。

在 L3 以下级别自动驾驶中起着主导作用。根据 ADAS 不同的功能需要以及安装位置,车载摄像头包括前视、环视、后视、侧视以及内置摄像头,不同位置的摄像头功能各异,是实现自动驾驶必不可少的构成部分。

从上面的配置来看,智能汽车至少需要5个摄像头以上,一个前视+4个环视摄像头是最基本的配置,有的汽车厂家算法高级一些,把环视摄像头中的其中一个也同步作为后视的功能,这样最少就需要5个摄像头的配置。
38.1. 前视摄像头
由于前方探测过程采用了基本都是一致性的目标图像输出,通俗的讲,很多情况下都是无法变换图像大小的探测类型,这就导致当图像分辨率过低时,其探测距离不足,无法提前针对远距离小目标进行探测;而图像分辨率过高时,其探测的FOV不足,无法及时的对方便车道突然切入的目标进行反应。

单双目镜头都是通过摄像头采集的图像数据获取距离信息,在前视摄像头的位置发挥重要作用;但二者的测距原理存在差别,单目视觉通过图像匹配后再根据目标大小计算距离,而双目视觉是通过对两个摄像头的两幅图像视差的计算来测距。
单目摄像头发展较早,目前技术发展已较为成熟,量产推广成本较低;但受限于单个摄像头定焦的局限,在不同距离下焦距切换难,难以兼顾测量的距离和范围。双目、多目摄像头在一定程度上克服了单个摄像头的局限,基于多个摄像头的配合能够获得更广的覆盖范围和更精准的数据。
但多个摄像头的硬件成本和以及相应的算法要求均较高,相应得配套设施发展尚不完善,现阶段很难量产并推广。单目摄像头由于芯片算力较低,成本较低,且与毫米波雷达、超声雷达搭配已能满足 L3 以下需求,因此短期内单目摄像头仍然是车载摄像头的主流方案。

我们看看视觉为主的辅助驾驶的特斯拉前视摄像头的设计。

特斯拉就是一个钢铁直男,既不选择单目,也不选择双目,前视摄像头直接就选择三目摄像头。
这个三目摄像头安装于挡风玻璃后,由3个组成:前视宽视野、主视野、窄视野摄像头。
宽视野:大角度鱼眼镜头能够拍摄到交通信号灯、行驶路径上的障碍物和距离较近的物体,非常适用于城市街道、低速缓行的交通场景。最大监测距离 60 米。
主视野:覆盖大部分交通场景,最大监测距离 150 米。
窄视野:能够清晰地拍摄到远距离物体,适用于高速行驶的交通场景。最大监测距离250米。
通过这个三目摄像头,钢铁直男把鱼和熊掌不可兼得的问题解决了,既有宽FOV角度的摄像头,像十字路路况比较复杂的路况就需要宽角度,高速路上需要有远距离的摄像头,一起解决了这个问题。
摄像头的图像分辨率和帧率也是需要重点考虑的。在解决了自动驾驶中央控制器的算力和带宽问题后,摄像头图像分辨率尽量越大越好,且考虑到车辆驾驶过程中需要具体解决的场景问题,一般是前向探测过程分辨率越大越好,当前主推的前视摄像头探测分辨率为800万像素。
前视摄像头是ADAS的核心摄像头,涵盖测距、物体识别、道路标线等,因此算法复杂,门槛较高,所以看一个汽车视觉算法是否牛掰,直接看能否有能力上多目前视摄像头。
38.2. 环视摄像头
开过车的朋友都比较有痛点,特别是倒车的时候,需要眼观六路,耳听八方,哪怕是有倒车后视和倒车雷达,旁边两边的环境也是要随时关注的,所以最开始360全景图像的痛点是解决全方位可以看到图像来停车

由于要拼接成一幅360°图像的画面,理论上3个摄像头也是可以完成拼接的,但是在车辆上的位置就不方便布置,基本上只能放置在车顶的位置了,同时软件算法拼接难度也增大,所以目前都是至少需要4个摄像头,而且是需要宽FOV广角摄像头。
安装位置:车辆前后车标(或附近)、以及集成于左右后视镜上的一组摄像头环视摄像头,作用在于识别出停车通道标识、道路情况和周围车辆状况,使用多个摄像头的图像进行拼接,为车辆提供360度成像,因为车声周边情况的探测需求,一般安装在车前方的车标或格栅等位置。

360环视的图像信息比较多,在很多车型都是有一个360图像处理器,在这个处理器中进行图像的拼接算法处理,把拼接好的图像在通过视频传输芯片,传输给到座舱控制器进行显示,这样对于座舱的主芯片的算力就降低了很多的要求,当然现在座舱域控制器的CPU芯片算力越来越强,处理这个360环视毫无压力,这样对于主机厂而言就可以节省一个360处理器,成本节省不少。

360摄像头的图像主要是给驾驶员使用的,这个图像的精度要求就没有那么高,而且观测的距离位置也比较近,所以图像的像素要求没有那么高,而且像素越高对于处理器的处理能力也更高,目前360环视摄像头都是100W-200W像素的摄像头就完完全全可以满足要求了。
38.3. 侧视摄像头
侧方探测中,当前采用的毫米波雷达技术主要是应用在自动变道上,原理也很简单,主要是毫米波雷达依靠了车辆目标的反射点进行。这里我们需要澄清一点,侧角雷达对于车辆目标的探测通常只能保证其探测到相邻车道的车辆目标,而对于第三车道的车辆目标的探测几乎是束手无策的,这一过程对自动驾驶带来的潜在危险影响也是比较巨大的。比如当自车在从当前车道切入到第二车道,而第三车道同时有车切入第二车道时,如果本车道车辆无法对该切入车辆进行有效检测,其结果就是导致两车很可能相撞。

此外,侧方雷达无法实现对侧方车道线的有效探测,无法弥补由于前视摄像头探测局限所带来的盲区,也无法为侧向融合的Freespace提供支撑,所以智能汽车一般需要增加侧视摄像头。
侧视摄像头主要是用于盲点监测BSD,根据安装位置可以实现前视或后视作用。目前大部分主机厂会选择安装在汽车两侧的后视镜下方的位置,未来可能取代倒后镜。

侧方前视:90 度角侧方前视摄像头能够监测到高速公路上突然并入当前车道的车辆,在进入视野受限的交叉路口时也可提供更多的安全保障。

侧方后视摄像头:监测车辆两侧的后方盲区,在变道和汇入高速公路时起着重要作用。
特斯拉环绕车身共配有 8 个摄像头,可以形成360°的视野,对周围环境的监测距离最远可达 250 米。8个摄像头可以分为3个前视、2个侧方前视、2个侧方后视以及1个后视摄像头

侧视摄像头性能要求
- 侧视摄像头探测的目标一般是侧方车道目标
侧方车道的场景匹配库中一般针对自动驾驶安全驾驶的场景较少,同时对于其侧方探测距离也比前方探测要求更近,因此侧方探测的分辨率要求可以稍比前视低一些,推荐一般采用200万像素的摄像头即可满足要求。当然如果不考虑成本和处理效率,也可以参照前视摄像头方案进行传感器搭载。
- 环视一般采用 135 度以上的广角镜头。
- 相机的安装位置和相机的配置很大程度上决定了视觉感知的范围和精度。
基于对目前运行设计域(ODD)的理解,侧视相机配置除了必须达到车规标准的信噪比,低光照的性能以外,还需要满足以下参数要求:

- 此外,针对摄像头布置位置而言
主要关注的点包含防水防尘等级以及其探测范围内是否有可遮挡其探测的部分。而对于侧视摄像头来说,由于一般需要布置在车辆侧方位,一般可布置的位置是参照全景摄像头的布置位置,放在外后视镜下方,甚至专用翼子板附近。这就对摄像头本身硬件模组的大小、尺寸、重量等提出了新的要求。一个基本的典型相机安装方案草案,推荐的安装位置如下:

基于目前已知信息,以及相关开发中的一些经验,视角交叉可以保证以相对窄角的相机同时有效覆盖本车车身近距离和远距离。侧前和侧后的功能略有不同,侧前侧场景检测。安装位置和 Pitch 角度可偏高,FOV 略宽,侧后主要是检测远后、近后临近车道的车辆,用于高速入口并线、本车换线。Pitch 角度可偏低,yawn 角度更接近与本车中线平行,FOV 略窄。具体参数可能在设计过程中需要调整。
38.4. 后视摄像头
后视摄像头主要是用于倒车过程中,便于驾驶员对车尾后面影像的捕捉,实现泊车辅助功能。

安装位置:一般安装在尾箱或后挡风玻璃上
38.5. DMS 内置摄像头
由于现有自动驾驶仅仅位于L2-3级,还需要人类驾驶员干预。因此,驾驶员监控系统DMS成为一个解决方案出现在ADAS中。现有的DMS解决方案主要是采用近红外摄像头的AI识别来完成。这个摄像头在驾驶员前方,能够完整的拍到驾驶员面部信息。
安装位置:无固定位置,方向盘中、内后视镜上方、A柱或集成于仪表显示屏处均有。

特斯拉的车内摄像头的位置就是在内后视镜上方,这个位置是很多车厂都希望放到的一个位置,识别率更精准一些。
39. 典型新能源汽车摄像布局位置
我们把车上摄像头的位置及作用都阐述了一遍,我们再来看看几款常见的新能源汽车他们采用的摄像头个数及布局。


其摄像头系统由1个3目前视摄像头(同特斯拉类似),4个环视摄像头,车顶两个前向侧视摄像头,1个后视,以及1个车内DMS摄像头。
威马W6
威马发布了其大致能实现L3级自动驾驶的,W6,全车有7个摄像头。其中两个是高清智能摄像头,最大探测距离超过150米,据网上信息来看,应该是一个前视一个后视。此外还有4个高清环视摄像头(100万像素,20m),以及一个DMS摄像头。

40. 车规级摄像头设计要求及选型规格汇总
因此,ADAS的摄像头硬件模组爆炸图如下,相应的性能设计中主要考虑如下因素:图像传输方式、输出分辨率、帧频、信噪比、动态范围、曝光控制、增益控制、白平衡、最低照度、镜头材质、镜头光学畸变、模组景深、模组视场角、额定工作电流、工作温度、存储温度、防护等级、外形尺寸、重量、功能安全等级、接插件/线束阻抗等。

具体来看,为应对复杂多样的使用环境,车载摄像头需要具备高动态性,其温度范围一般为-40 度~80 度,同时需要具备较高的防磁抗震性能,此外还需满足 8-10 年的基本使用寿命要求。性能方面,考虑到芯片处理负担,车载摄像头的像素要求较低,一般为100万-200 万像素,功率一般也在 10W 以下。
车载摄像头环境条件更为严苛,也相应具有更高的价值量。相较于传统的工业摄像头和手机摄像头,车载摄像头需要在高低温、湿热、强微光和振动等各种复杂工况条件下保持稳定的工作状态,因此车载摄像头具有更高的安全等级要求和工艺性能要求。考虑到安全因素,汽车厂商倾向于选择技术成熟、品质有保障的零部件厂商,因此车载零部件厂商进入市场体系获得评级需要更长的认证周期,行业壁垒较高。
前视、环视、后视摄像头常见的结构造型

上图左边是SVC(环视),RVC(倒车后视)的摄像头架构,由于该摄像头是布局在车外,需要做很好的防水要求,同时需要长距离传输,需要视频对传芯片传输,通常采用同轴传输方式,主要是从成本方面考虑的,双绞线的成本太贵,车厂根本承担不了,7-8米的后拉摄像头的车规级双绞线线材的成本需要去到100RMB,所以可以看到车外的摄像头传输一般采用同轴线传输。
上图右边是FVC也即是前视摄像头,此类摄像头一般不用组装成完整的摄像头成品,一般都是使用在车内,只需要出货摄像头模组即可,防水要求等级也低,同时传输到CPU的距离也近,一般采用MIPI信号传输,通过FPC线材短距离传输就可以给到CPU那端,成本和性能都能有保障,非常低的成本方案。
前视摄像头选型汇总:


可以看到前视的摄像头所需要的FOV角度都不大,一般都选择H方向在40-50°左右,频率为30-60HZ,需要高动态的的摄像头100db,像素一般在100W-200W之间,主流的还是在100W的摄像头。
倒车摄像头选型汇总:


可以看到倒车后视由于需要看的距离并不远,重点关注的角度范围要款一些,方便倒车时的视线,所以FOV角度都达到H 大于130°,同时像素也需要大于100W像素,在显示屏上看到的图像才高清,这里的摄像头由于是做倒车后视使用,一般从成本角度出发,不使用宽动态的摄像头,只需要大于70db就行,摄像头的刷新率也只需要30HZ以上就行。
环视摄像头选型汇总:


可以看到环视摄像头的指标同前视指标非常相同,都需要宽动态,同时传输接口也是GSML传输协议为主,FOV可视角度非常大,因为要做图像拼接,所以这里的视角需要H大于170°,非常广角的摄像头要求,同时刷新频率需要大于30HZ以上。
41. 车载摄像头系统架构简单阐述
如下图表示了下一代自动驾驶系统方案基础架构。其关键要素中,图像处理Soc部分主要涵盖了对摄像头图像的传感输入图像处理ISP及目标融合,当然雷达或激光雷达也可以将原始数据作为输入信息进行目标输入。而逻辑控制单元MCU负责处理Soc的目标融合结果,并输入至运动规划及决策控制模型单元进行处理,其处理的结果用于生成车辆控制指令,控制车辆的横纵向运动。

对于图像处理软件模型而言,主要放在Soc芯片中进行。其中的软件模块主要包括图像信号处理ISP、神经网络单元NPU、中央处理器CPU、编解码单元CODEC、MIPI接口输出、逻辑运算MCU接口输出。

其中两个最耗费算力的计算单元包括图像信号处理ISP及神经网络单元优化NPU。

以上优化的结果一方面是生成图像基础信息结果,通过输入给中央处理单元CPU进行综合信息处理分配。一方面应用于编解码单元CODEC,进行解码后的图像通过MIPI接口输出至视频娱乐影音系统进行显示,同时进行环境语义解析后的结果输入至ADAS逻辑控制单元MCU,该模块可以通过与其他环境信息数据源(如毫米波雷达、激光雷达、全景摄像头、超声波雷达等)进行信息融合后生成环境融合数据,并最终用于车辆的功能应用控制。

当然如果考虑到智能行车辅助控制会有部分信息输入给其他智能控制单元进行信息融合,则需要将生成的结果通过以太网输入到网关,由网关进行转发后输入至其他单元,比如智能泊车系统、人机交互显示系统等。
42. 车载摄像头产业链上下游组成

车载摄像头产业链主要涉及上游材料、中游元件和下游产品三个主要环节;而在这个产业链中,镜头组、图像传感器( CMOS )以及数字处理芯片( DSP ),具有较高的技术壁垒。

成本构成上,图像传感器CMOS占车载摄像头成本的半壁江山。此外,模组封装、光学镜头分别占比25%及14%,前三者合计占比近90%。
行业迎高速扩张,未来五年市场规模达 270 亿美元

车载摄像头覆盖率较低,市场潜力巨大。要完全实现自动驾驶,汽车必须配置五类摄像头,伴随智能驾驶等级提升,单车车载摄像头数量增长,单车摄像头配置数量至少为 12个,L5预计需要12-15颗(感知+环视+DMS/OMS)。
据 Yole 数据,全球平均每辆汽车搭载摄像头数量将由2018 年的 1.7 颗增加至 2023 年的 3 颗,且随着自动驾驶的升级,这一数量将进一步增加。

随着车载摄像头技术的成熟,域控制器应用,摄像头“去芯片”化带动单品价格下探,像素提高拉升单价,但总体呈下降趋势,据 ICVTank 数据,2020 年车载摄像头价格预计为 145 元,带芯片及算法前视摄像头1,000元左右,无芯片500万像素仅200元,未来这一价格有望进一步下降,并将进一步推动车载摄像头覆盖率和单车配置数量提升。

随着ADAS和自动驾驶的逐步深入,预计未来车载摄像头市场规模仍保持高速增长,根据ICVTank,全球车载摄像头市场规模将有望从2019年的112亿美元增长至2025年的至270亿美元,CAGR 达15.8%。
43. 车载摄像头产业链重点物料讲解

43.1. 车载摄像头镜头
车载摄像头镜头组市场,国内的舜宇光学领先优势明显。舜宇光学的车载摄像头镜头出货量为全球第一,根据前瞻产业研究院整理数据显示,2019 年舜宇光学的市场占有率达到 34%,其后的厂商以依次为韩国的 Sekonix、kantatsu 和日本的 fujifilm,行业前四大公司市场占有率CR4 达到 78%。舜宇光学作为全球领先的国内镜头厂商,于 2004 年进入车载镜头领域,在 2012年时其出货量已稳居全球第一位,成为行业领导者。
目前,舜宇的车载系列产品包括前视、后视、环视、侧视和内视镜头等,在车载镜头领域提出了良好的产品解决方案,其主要客户涵盖奔驰、宝马、奥迪、丰田等众多欧美、日韩及国内汽车厂商。此外,联创电子作为国内光学镜头的龙头企业之一,于 2015 年进入车载镜头领域并实现了突破性发展。
目前,公司有 2 颗镜头通过 MobileyeEyeQ4 认证,8 颗镜头通过 MobileyeEyeQ5 认证,产品获得法雷奥、麦格纳、安波福等核心 Tier 厂商认可,并为奔驰、宝马、特斯拉等知名车企提供相关产品。
43.2. 图像传感器CMOS:索尼一家独大
摄像头核心组件CMOS头部厂商均为海外企业,索尼一家独大,2019年全球市场份额近50%

豪威科技和索尼将手机 CIS 与汽车 CIS 相结合,掌握了大小像素曝光技术;此外,豪威科技还多次推出高像素产品 OX08A、OX08B,实现车用 CIS 领域高像素的突破。2019 年韦尔股份完成对豪威的收购,借助豪威在技术和市场占有率方面的优势,未来韦尔股份有望实现进一步的市场扩张和发展。
国内企业多点开花,车载 CMOS 传感器国产替代趋势明显。除了韦尔股份之外,比亚迪半导体经过多年发展实现了车规级 CIS 的突破,推出了国内首款 130 万像素车规级图像传感器并于 2018 年实现批量装车。思特威于 2020 年收购深圳安芯微电子有限公司(Allchip),积极扩展汽车领域产品线。
安芯微拥有多款自主研发的 SOC 系列图像传感器产品,在车用 CIS领域具有较强竞争力,未来,思特威有望在车用 CIS 领域实现突破性发展。格科微积极布局汽车 CIS 领域,产品已经应用于行车记录仪、车内摄像头、360 度环视、倒车后视和驾驶员疲劳检测等终端应用,与联咏、晨星半导体、杰理JL、富瀚、凌阳等主流品牌商有合作关系。
44. 车载摄像头及系统集成方案国产持续发力中

车载摄像头模组领域集中度较高,海外企业占据着主要市场份额,从竞争格局来看,当前全球车载摄像头行业市场份额前三为松下、法雷奥和富士通:其中松下所占市场份额最大,达到20%;法雷奥和富士通市占率分别为11%和10%。当前全球车载摄像头行业CR3为41%,全球前十企业则占据了96%的市场份额,全球车载摄像头行业集中度处于较高水平。
自主方面,舜宇光学、欧菲光等手机摄像头封装领域市占率较高的厂商正凭借其消费电子领域的工艺积累,进入车载市场。
据盖世汽车研究院,2020 年,我国车载摄像头模组出货量达4400 万个,CAGR 为20.6%,未来增长潜力巨大。国内企业加速发展,未来有望凭借成本优势在模组封装端占据更大份额。
系统集成方面,国内厂家展露头角。

系统集成方面,传统 Tier 1 供应商占据主导,国内德赛西威、华域汽车等企业产品已在国内品牌汽车中得到使用。法雷奥、大陆、海拉、松下、索尼在摄像头前装市场占据主导地位。国内企业近年来加速布局。德赛西威作为国内最早布局车载摄像头的企业之一,实现了高清车载摄像头和环视系统的量产,目前已为吉利、广汽和奇瑞等国内品牌提供车载摄像头等相关配套产品;
此外公司还开发出一系列如自动泊车系统以及夜视系统等摄像头相关的驾驶辅助系统,在吉利星越、奇瑞捷途等车型中得到了应用。华域汽车作为国内最大的汽车零部件企业之一,积极布局车载摄像头领域,通过视觉传感系统以及外部信息实现了自适应巡航控制(ACC)、前向碰撞报警(FCW)、盲点探测(BSD)等多项自动驾驶功能,公司还布局了诸如自动泊车系统、360 度汽车行驶环境扫描系统的高级驾驶辅助系统,可以满足 L3 及以下的自动驾驶需求。
华阳集团自成立以来一直专注于汽车电子领域,经过多年发展,已发展成为中国大型汽车电装企业之一,拥有丰富的产品线,公司积极布局车载摄像头领域,引进高清摄像头自动生产线,相继推出了 360 环视系统和“煜眼”技术,并开始应用于自动驾驶汽车,其中搭载“煜眼”系统的摄像头产品于 2020 年在新宝骏 E300 上迎来量产。
车载摄像头发展较为成熟,是应用最广泛的“汽车之眼”。我们认为车载摄像头不仅是目前自动驾驶的核心传感器,也将在未来高等级自动驾驶中发挥主导作用。随着自动驾驶等级提高,单车摄像头数量将持续提升,由 L2 的 1-2 个提升到 L3 的 3-6 颗,未来高等级自动驾驶有望达到 10 颗以上,相应带动车载摄像头市场高速增长,未来五年全球 CAGR 约为 16%,中国 CAGR 约为 32%。
总的摄像头产业链如下图所示:


















 421
421

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









