









译自aras的博客,总共3篇文章,讲述unity5优化自己渲染器的过程
吸取大神调试与优化经验,了解unity5内部渲染器的优化方法
介绍过去后,让我们来进行实际工作

在以前的文章已经提到的,首先我尝试想起/找出现有代码,做一些分析并且写下突出的地方。
分析多个项目主要揭示了两件事:
1. 渲染代码使用多线程真的比使用我们现有的“一个主线程和一个渲染线程” 更广阔。这里有一个从unity5的timeline profiler的截屏:
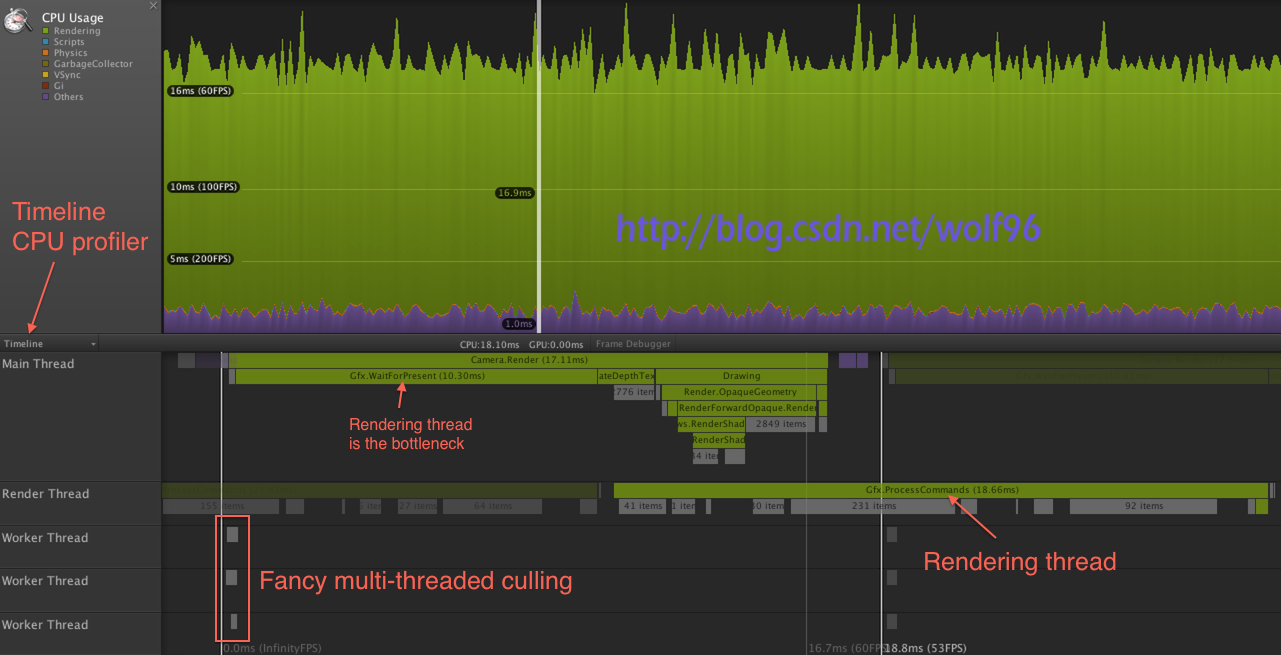
在这种特殊情况下, CPU的瓶颈是渲染线程,大部分的时间都花费在了 glDrawElements(这在MacBookPro; 在蝴蝶效应这个demoGPU简化场景处理了6000drawcall)。主线程只是结束等待渲染线程之后再追上。依靠硬件,平台,图形API等。瓶颈能在任何地方出现,比如 相同的程序在更快的PC在DX11下 主线程和渲染相比消耗的时间相同。
culling sliver在似乎不错,最终我们希望我们所有渲染代码都能那样不错。这里放大剔除部分:
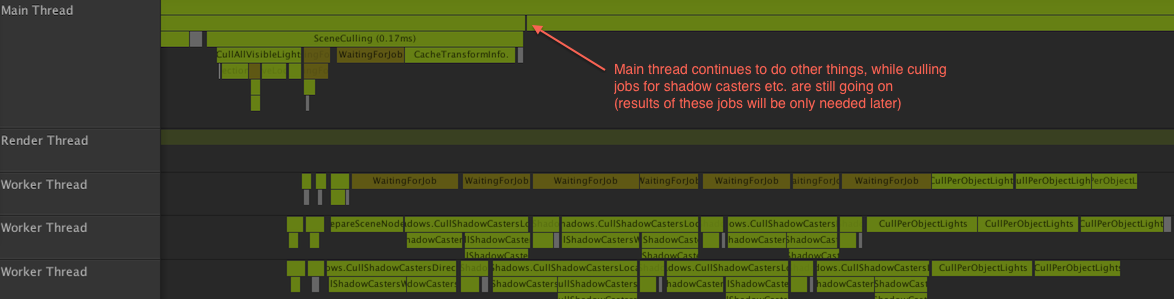
2.没有“优化这一个函数,使所有事情都两倍快”的地方:( 重排数据将是一个漫长的旅程,移除多余的决策,移除这里和那里的小的事情,直到我们能达到“每个线程两倍快”。如果。
渲染线程分析的数据并不是特别有趣。大部分的时间(下面突出加亮显示的一切) 是OpenGL运行运行时间/驱动。添加一些注释关于我们做了什么蠢事情而导致驱动做了太多多余的事情(我不知道, 没有好的原因切换不同的顶点布局等),但是另外在我们的方面没有看太多。大部分剩余时间都消耗在动态批处理上了
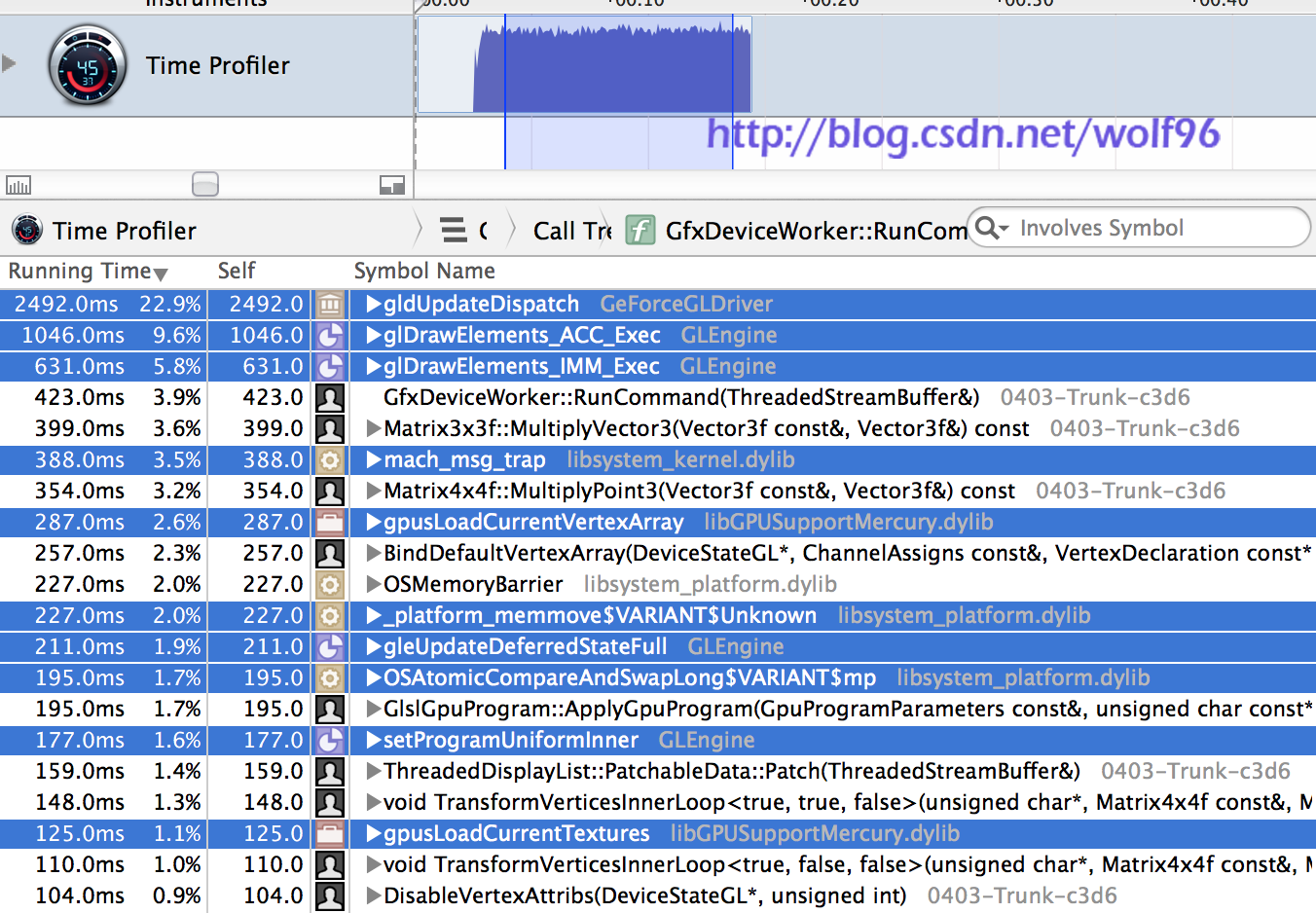
看看在主线程消耗非常大的函数,我们得到了这些:
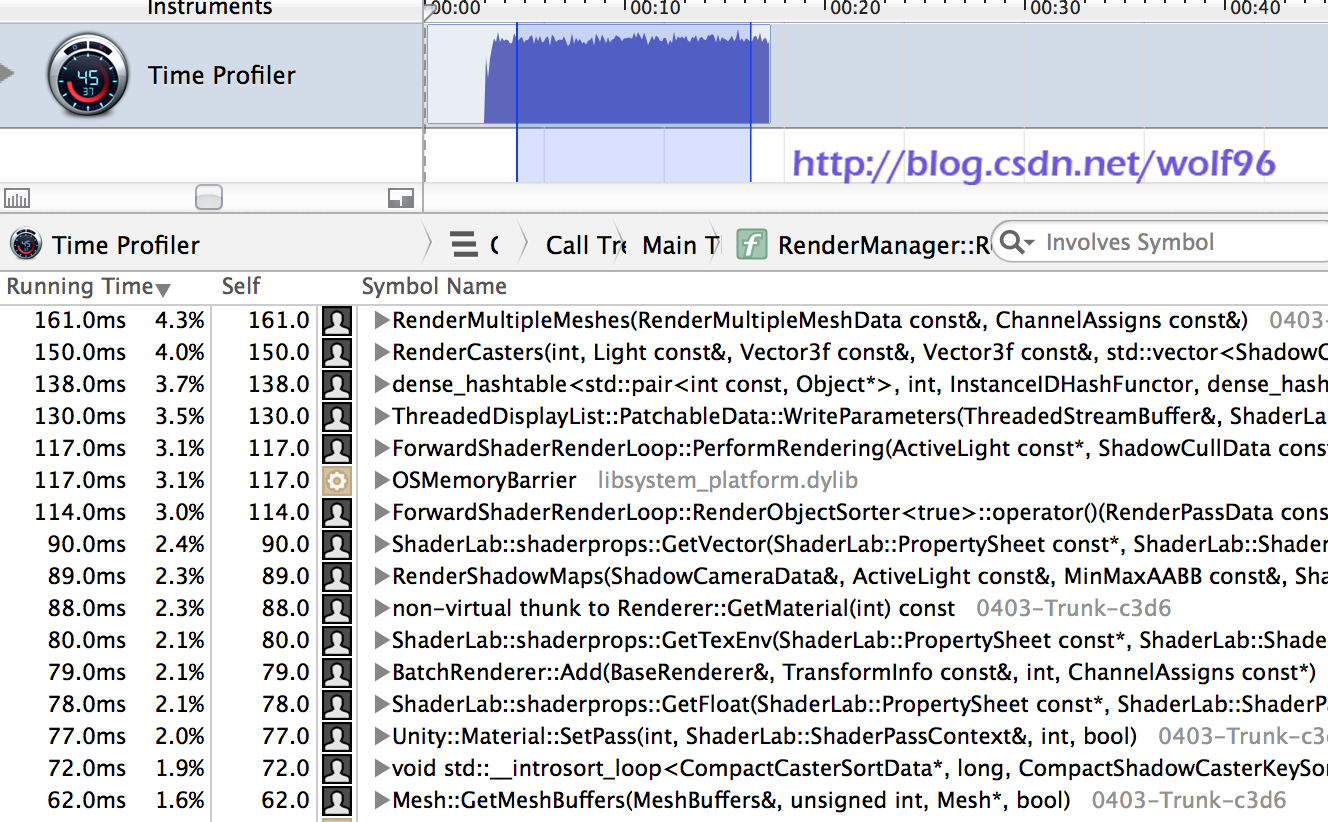
现在当然有问题产生(为什么这么多哈希表查找?为什么排序要这么长时间?等等,看看上面的列表),但关键是,没有在一个地方优化什么就能带来魔法性能效益和一匹小马(此处比喻)。
观察1:材质“显示列表”总是被重建
在我们的代码中,在渲染线程中一个材质能预先重新记录我们叫做一个“显示列表”。认为他是一个小的命令缓冲,存储一群指令(“设置光栅状态对象,设置这个着色器,这只这些贴图”)。关于他们的最重要的事情:它们存储了所有参数(最终贴图的值,shader uniform变量值,等等)。当“applying”一个显示列表,我们只需要把它切换出渲染线程,不需要 找出材质属性值或其他事情一切都很好,除了当在材质中一些事情改变了使得记录的显示列表无效。在unity中,每个shader的内部经常有很多shader的变形种类,并且当选择一个不同的shader变形,我们需要请求一个不同的显示列表。如果使用一种方式场景被建立引起相同的材质去交替不同的列表,然后我们就产生了问题。
在这几个标准的项目中到底发生了什么问题;简短的故事“在forward渲染的多个逐像素光源是导致这种事情的原因”,结果是我们有代码来处理这个分支,它只是需要被完成---所以我找到了它,在当前代码库编译它非常奏效。现在的材质能预记录不止一个“显示列表”,这个问题也消失了。
PC(酷睿i7 5820 k), 在主线程一个场景从9.52ms到7.25ms是相当可怕的。
剧透:这一变化最大的好处是在受影响的场景,从我做了每件事几乎用了两个星期。那个代码甚至不是我“写的”,我只是从一些被忽视的分支里得到的。所以,耶!一个很简单的改变使得性能提升了30%!
观察2:哈希表查找太多了
从上面的观察名单,,发现“为什么哈希表查找如此之多”的问题。在渲染代码中,很多年前我加了一句像这样的:
Material::SetPassWithShader(Shader* shader, ...)
调用的代码已经知道了哪个shader应该被设立。材质也知道这个shader,但是它存储了一些东西我们叫做PPtr(“persistent pointer固执指针”)它本质上是一个句柄。指针直接避免做一个句柄指向指针(handle->pointer)的查找(目前是一个哈希表查找,由于各种复杂的原因,很难做一个基于数组的处理系统)
结果是,在许多改变之后,Material::SetPassWithShader完成了两次handle->pointer查找,即使它已经有了实际的着色器指针作为参数!修复:

上图翻译:
通过应用程序清理和优化材质。
SetPassWithShader在某些点被增加来避免一个PPtr deref。结果是,现在它还是做“两次”m_shader PPtr derefs!那不是一个糟糕的优化。
所以把它们都清理掉;有一个Material.SeShaderPass 它直接取得它需要的,避免废弃并且到subshader中去。并只是在pass指针基于直接缓存显示列表。这允许移除特殊的情况为阴影caster passes复制代码。
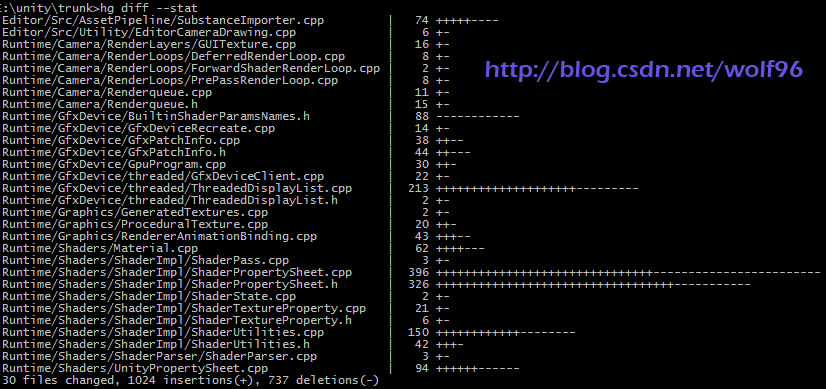
VikingVillageStatic 工作台项目,i7 5820k,主线程 Camera.Render 7.25ms->6.59ms 17个文件改变,有135个插入的地方和213个删除的地方:
Ok我们的结果是好的,可以衡量的并且非常简单的实现了性能优化,也是的代码库更加小巧,多么好的一件事情。
小的调整
在上面Mac的渲染线程性能分析中,我们自己的代码在 BindDefaultVertexArray消耗了2.3%,感觉消耗得太多了。结果,它循环所有可能的顶点组件类型并检查一些东西。使得使用shader代码循环只在顶点组件部分。稍微快了一些一个项目使用GetTextureDecodeValues很多次,它是用来计算色彩空间的,HDR和光照贴图纹理解压缩为常数。一个可选“intensity multiplier”参数,在所有的调用地方都被明确的设置为1.0,只有一个除外,它做了一系列的sRGB数学操作 。我察觉到,在代码中使得一些pow()调用消失了 。增加到一个“look later” 清单中:为什么在第一个地方我们调用这个函数这么频繁呢?
一些代码在渲染循环中计算出drawcall对边界批处理需要放在哪里 (也就是说:去哪里切换到一个新的shader,等等),是比较一些状态作为单独的bool。把它们打包到位域中并且比较一个整数。没有可观察到性能变好,但是实际上代码变少了,所以一场胜利:)
(位域是指信息在存储时,并不需要占用一个完整的字节, 而只需占几个或一个二进制位。例如在存放一个开关量时,只有0和1 两种状态, 用一位二进位即可。所谓“位域”是把一个字节中的二进位划分为几 个不同的区域, 并说明每个区域的位数。每个域有一个域名,允许在程序中按域名进行操作。 这样就可以把几个不同的对象用一个字节的二进制位域来表示。)
注意到,弄清楚哪个顶点缓冲和顶点布局被物体查询网格数据使用,在内存中是一个非常远的部分。基于用途类型重排数据(渲染数据,碰撞数据,动画数据等等)
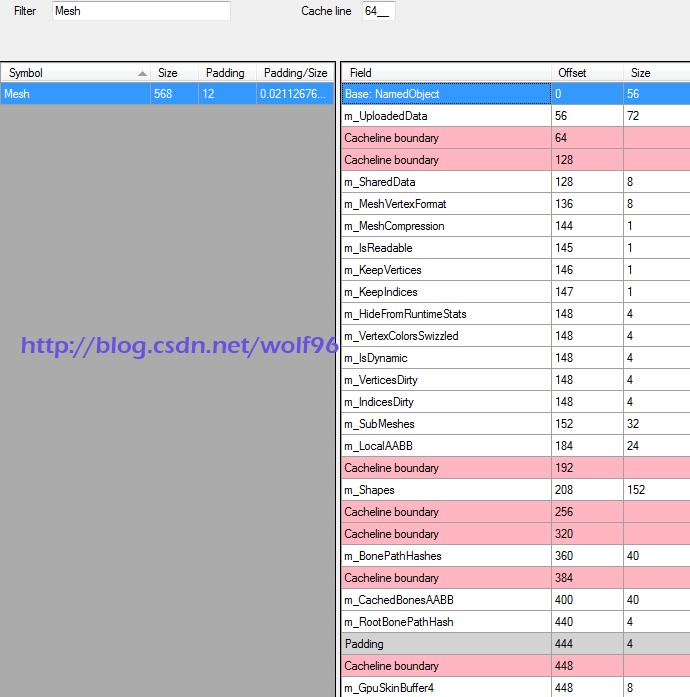
也减少了数据包装漏洞msinilo的优秀的CruncherSharp (在这种方法上做了一些调整:))(下图为CruncherSharp )我听说有一个小工具对Linux(pahole)。在Mac上有 struct_layout但是它可以永远在unity中执行并且Python 脚本经常有一些溢出异常引起失败。
浏览代码的时候,发现 我们追踪每个贴图的mipmap bias的方法非常复杂。当纹理跟踪所有将要使用的的材质属性表时时,它设置每一个纹理;通知它们在任何mip bias上的改变,并且bias 是从性能表和 一起应用的每个纹理中获得,每次设置一个纹理在图形驱动上。天啊。固定的。因为这改变了我们图形抽象API的接口,这意味着改变所有11个渲染后端; 几个相当微不足道的改变但感觉很恐怖(我甚至连局部的建立它们的一半都不能)。不要害怕,我们有建造场来检查编译错误,和测试程序组来逆向检查!

上图翻译:
使纹理mip bias 健全的处理。
当bias是纹理阶段的一部分,它只这样怪异的,不是纹理。或者也许是其它的东西。
现在它只是纹理过滤器filter/变形warp/各向异性aniso的一部分设置,并且只有当它被改变时才被应用。
Gone:
Bias应用在每个和所有gfxdevice.SetTexture 调用中,
Texture::NotifyMipBiasChanged,(博主注:先通知mip bias改变了)
TexEnv::TextureMipBiasChanged, (博主注:再调用改变mip bias纹理)
TexEnvData::mipBias。(博主注:再确确实实执行bias操作)
80个文件改变了,插入了228,删除了263。
没有明显的性能差别,但是感觉不那么复杂了。加一个“look later”清单:我们追踪每个纹理有很多相同的数据;有些关于非二次幂限制的纹理(NPOT)的UV缩放。这些天我怀疑它没有存在的理由,如果可能的话继续观察并且移除它。
并且也做了一些其他一些类似的局部调整,它们每个都很简单,让一些特殊的地方更好一些,但是不会观察到任何性能改进。也许把它们放大一百倍才能看到一些明显的影响,但是它们有更多的可能性 我们需要重做一些要严重事情去得到更好的结果。
材质属性表的布局
一件一直困扰我的事情是我们怎么存储材质属性。每次我把代码库给新程序员看,在那我翻着白眼说:“噢耶,我们在材质中存储纹理、矩阵、颜色等,在分离的STL map中。令人厌恶。令人厌恶。”。(
Map是标准关联式容器(associative container)之一,一个map是一个键值对序列,即(key ,value)对。它提供基于key的快速检索能力,在一个map中key值是唯一的。map提供双向迭代器,即有从前往后的(iterator),也有从后往前的(reverse_iterator)。
map要求能对key进行<操作,且保持按key值递增有序,因此map上的迭代器也是递增有序的。如果对于元素并不需要保持有序,可以使用hash_map。
http://www.cnblogs.com/skynet/archive/2010/06/18/1760518.html)
有这个流行的想法认为c++ STL容器在高性能代码中没有立足之地, 而且没有好游戏使用它(不是真的),如果你使用它你一定很愚蠢并被嘲笑(我不知道…也许?)。所以,嘿,我如何把这些maps 替换为一个更好的数据布局?必须让一切更好一百万倍,对吗?
在Unity中,shader的参数可以来自两个地方:每个材质的数据,或“全局”材质参数。前者通常是“diffuse texture漫反射纹理”,后者就像“fog color雾的颜色”或者“Camera projection相机的投射”(博主注:漫反射纹理贴图参数是每个shader中都是特有的,雾的颜色在unity的RenderSettings 每个shader都共有)(每个实例的参数都有点复杂MaterialPropertyBlock等等,但是现在先让我们忽略)
我们之前的数据布局大概是这样的:
map<PropertyName, float> m_Floats;
map<PropertyName, Vector4f> m_Vectors;
map<PropertyName, Matrix4x4f> m_Matrices;
map<PropertyName, TextureProperty> m_Textures;
map<PropertyName, ComputeBufferID> m_ComputeBuffers;
set<PropertyName> m_IsGammaSpaceTag; // which properties come as sRGB values
我取而代之的是(简化,只显示数据成员;dynamic_array很像std::vector,但更加有EASTL风格):
// Data layout:
// - Array of name+type information for lookups (m_Names). Do
// not put anything else; only have info needed for lookups!
// - Location of property data in the value buffer (m_Offsets).
// Uses 4 byte entries for smaller data; don't use size_t!
// - Byte buffer with actual property values (m_ValueBuffer).
// - Additional data per-property in m_GammaProps and
// m_TextureAuxProps bit sets.
//数据布局:
//-数组名只要 名称+类型就好有(m_Name)信息来查找。不要再加别的东西
//只要有关键信息用来查询就好
//-性能数据的位置在value buffer (m_Offsets)中。使用4byte来记录小数据
//不要使用size_t!
//- 实际的属性值(m_ValueBuffer)使用Byte缓存
//-追加的数据 每个属性在m_GammaProps和m_TextureAuxProps设置为bit。
//
// All the arrays need to be kept in sync (sizes the same; all
// indexed by the same property index).
//所有数组需要保持同步(大小相同;相同属性的索引)
dynamic_array<NameAndType> m_Names;
dynamic_array<int> m_Offsets;
dynamic_array<UInt8> m_ValueBuffer;
// A bit set for each property that should do gamma->linear
// conversion when in linear color space
//在一个线性空间时都该做gamma->linear转换,对于每个属性用一个bit来设置
dynamic_bitset m_GammaProps;
// A bit set for each property that is aux for a texture
// (e.g. *_ST for texture scale/tiling)
// 对于每个属性来说一个bit设置是一个纹理的辅助aux
// (如. *_ST for texture scale/tiling)
dynamic_bitset m_TextureAuxProps;
当一个新属性被添加到一个属性表,它只是附加于所有的数组。属性名称/类型信息和属性位置在数据缓冲中保持分离,所以当查找属性时,我们甚至不获取对搜索本身不需要的数据。
最大的外部变化是在这之前,一个是需要找到一个属性值并且存储一个直接指针指向它(被用于预记录材质显示列表,在重演它们之前能够“patch in临时接入” 全局shader属性的数值)现在每当改变数组大小都会引起指针无效;所以取而代之,能存储在指针中的所有的代码,必须改变去存储偏移offsets在属性列表中。所以,最后有一些代码被修改了。
寻找属性已经从一个O(logN)的操作(贴图查找)转变到一个O(N)操作。如果你学过计算机科学你就知道这不是个好事,它是一个典型的taught。然而,我看了各种项目并且找到典型的情况,属性表总共包含5-30个属性(大多数在10左右);并且一个线性的扫描所有查找的数据紧挨着在内存中其他的数据,这与STL map查找map节点能随意的远离其他点作对比并不是那么糟(如果发生了这件事,每个节点能作为一个CPU缓冲存储器丢失)。从几个不同的项目的性能作分析,其中一部分是“查找属性”在PC、笔记本电脑和iPhone上一直很快。
可是这一变化带来了魔法一样性能改进的吗?并没有,它稍微改善了平均帧时间并且内存消耗得更少,特别是当有大量不同材质的时候。但是做了“只是用被打包的数组代替了STL maps ”节能有魔法般的结果吗?并不是。嗯,至少我不必再边翻我的眼睛边把这段代码展示给别人看了,就是这样。
效果
这个工作大约用了两周时间(我估计只有75%---其余花在了其它不相关的修正,代码检查等)所有的平台创建并且测试通过的一个状态;准备好请求。40个提交,135个文件,大概2000行代码改变了。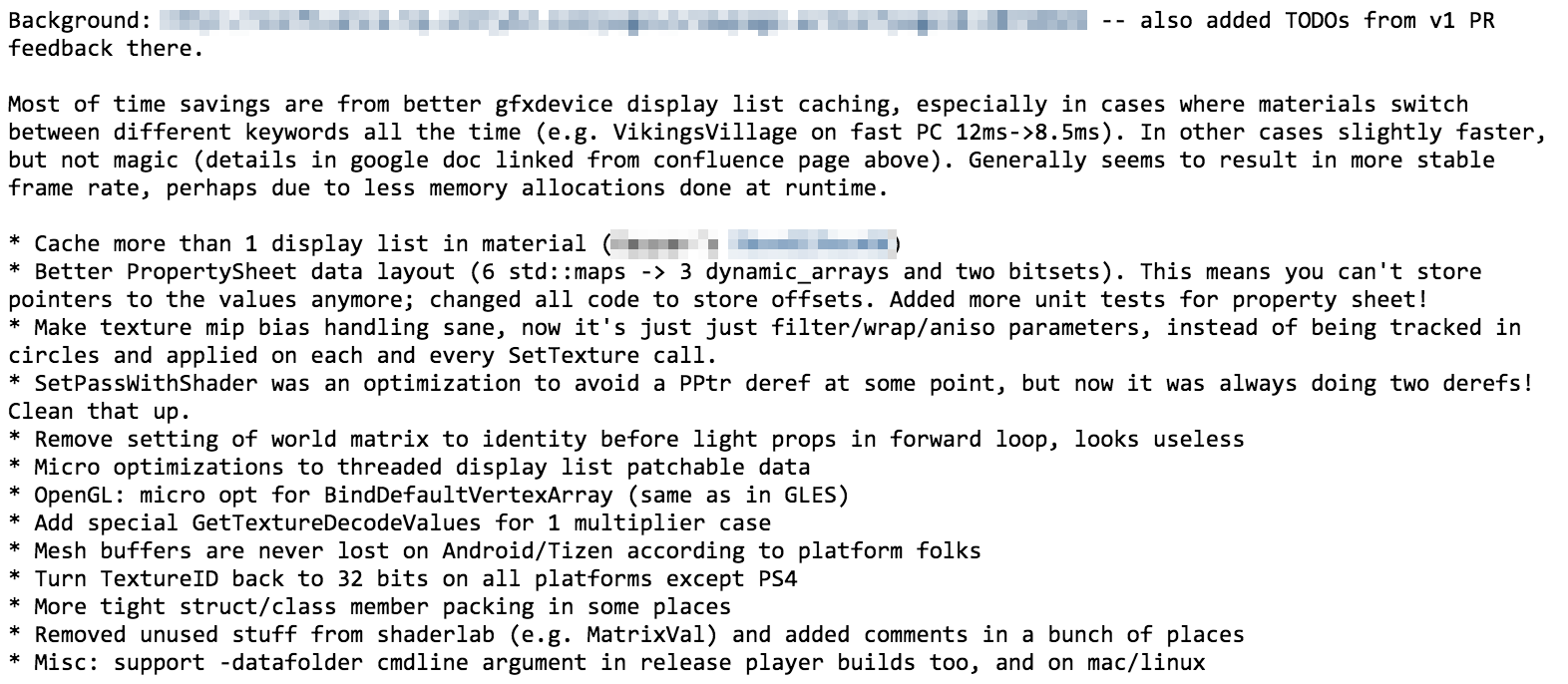
上图翻译:
大多数时间存储是从一个更好的gfxdevice 显示列表的超高速缓存,特别是材质总是选择不同的关键字这种情况(例如,Viking Village这款游戏在很快的PC 12ms-8.5ms)在其他情况下稍微快一些,但是也不是特别快(结合上面的,在google链接文档的细节)。一般来说结果的帧率更加稳定,也许由于在运行中很少内存分配。
材质不止一个显示列表在缓冲存储器中
更好的属性表数据布局(6 std::map-> 3 dynamic_array 和 2 bitsets)。这意味着你不能把指针当做值来存储;改变了所有代码来储存offsets。增加了更多的单位测试和性能表!
让 texture mip bias健全的处理,现在它只有 filter/wrap/aniso 参数,替代了被循环追踪并且应用在每个SetTexture调用。
SetPassWithShader曾做了一个优化在某些点上来避免一个PPtr deref,但是现在它总是做两次derefs!把它清理掉。
移除世界matrix的设置替换成 light props 在正向循环之前统一一致,似乎没有用
稍微优化了线程显示列表可修补数据
OpenGL:稍微优化了BindDefaultVertexArray (像GLES)
1multiplier的情况时增加了特殊的GetTextureDecodeValues
根据platform folks,网格缓冲永远不会再安卓/Tizen泰泽系统上丢失
撤回TextureID 到所有32位平台除了ps4
更多密封的结构体/类打包在某些地方
从shaderlab上移除了不用的东西(如 MatrixVal)并且在很多地方加了注释
杂项:支持-数据包 命令行在发布玩家创建也有争议,并且在mac/linux上
大部分的性能改进确实来自两个地方(显示列表被重建;避免无用哈希表查找)。不确定其他改变的变化-总体感觉他们是改变的最好的,如果只是因为现在我对代码库有一个好的理解,并且已经添加了大量的注解注释 什么&为什么。我现在甚至也有很长的列表“这里那里怪异的地方需要改进”。
花了我近两周的时间得到了现在这个结果,这样值得吗?很难说。有时我花费了一个星期,但我感觉什么也没做,所以比这更好:)
总体来讲我还是不确定“优化”是不是我的强项。我想我很擅长只有几件事:
1. 调试困难问题-调试困难的问题——我能很快想出合理的假设和方法逐个击破问题。
2. 理解一些变化或一个系统的含义----其他系统将会被影响并列有什么会/将会有问题交互产生。
3. 关于在代码库中事情被其他的事情解决了有很好的环境认识----我经常能找出,几个人在同一件事情上重叠工作,并且告诉他们“哟,你俩应该协调整合一下”
这些是对优化有用的技能吗?我不知道。我当然不能兼顾指令延迟和执行端口和TLB misses 在我的大脑里。但是也许如果我练习一下会更好?谁知道呢
不知道下一步该走哪条路,我看到几条可行的道路:
1. 继续改进,并且希望他们大多数的效果都很好,单独几点可能会失望,因为真的很难权衡
2. 开始放眼更大的地方,找出完全可以避免的很多我们目前完成的工作,即更严重的事情是“重塑”结构。
3. 一旦一些清理完成,切换到帮助别人的“多线程多材料”的方法。
4. 优化太难了!让我们更多的玩摇滚史密斯直到情况好转
我想我将和几个人讨论并做更多上面讲到的事情。下次见!
博主总结:aras的代码风格非常好,并且他在写代码的时候就有许多注释,因此优化起来很有效率,优化的地方也很准确。aras也很善用分析器。。。。总之,看了之后受益匪浅。。希望unity越来越牛x。
待译。。。















 12万+
12万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









