






今天给大家推荐一个涨点发顶会的好方向:GNN+强化学习。这俩热点的结合可以轻松实现“1+1>2”的效果。
GNN能够深入挖掘图中的模式和关系,而RL(强化学习)擅长在动态环境中进行序列决策,尤其是在需要长期规划和适应环境变化的情况下。两者结合起来,可以开发出能够同时学习图结构表示和做出最优决策的智能模型。
-
MAG-GNN:提出了一种基于强化学习的图神经网络方法,称为MAG-GNN,通过使用强化学习(RL)来定位具有区分性的子图集合,从而降低了子图GNN的计算复杂度,同时保持了良好的表达能力。实验结果表明,MAG-GNN在多个数据集上取得了与最先进方法相竞争的性能,并且比许多子图GNNs取得了更好的效果。
-
SAC-CAI-EGCN:提出了一种结合了强化学习、因果推断和图神经网络的SDN(Software-Defined Networking)路由方案。在GEANT2网络拓扑的实验中,SAC-CAI-EGCN方法在数据包丢失率上优于SPR约66.4%,在延迟上减少了约65.0%,并在吞吐量上提高了约23.8%。这些数据表明SAC-CAI-EGCN在网络性能上实现了显著的改进。
-
AttackGNN:提出了一种新颖的强化学习(RL)代理程序AttackGNN,用于生成对抗性示例(即电路),以欺骗GNN技术。该方法可以针对四种关键的硬件安全问题(IP盗版、检测/定位硬件木马、逆向工程和硬件混淆技术破解)生成成功的对抗性示例。
-
疫苗优先分配策略:探讨了一种结合图神经网络(GNN)和深度强化学习(DRL)的疫苗优先分配策略,旨在有限的疫苗供应下减少疫情的整体负担。在模拟评估中,该框架实现了比基线策略减少7%到10%的感染和死亡,展示了其在优化疫苗分配策略方面的显著效果。
这种策略也存在挑战,如需大量数据、计算资源等。目前的研究也着力于改善这一结合的有效性和效率,这些进展展示了GNN和RL结合的强大潜力。我整理出 多篇最新论文,并附上开源代码,方便大家复现找灵感。!
欢迎来到AI科研Paper,这里集 AI 知识、技术、资源于一体,为 AI 爱好者、从业者、研究者提供全方位的服务与支持。我们致力于成为 AI 爱好者与从业者的学术服务助力。
论文精选
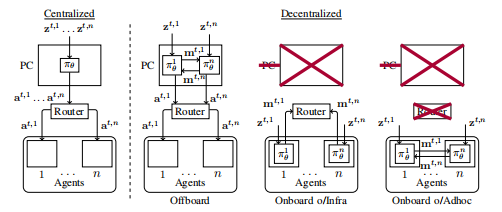
论文1:A Framework for Real-World Multi-Robot Systems Running Decentralized GNN-Based Policies
用于现实世界多机器人系统运行去中心化的基于GNN策略的框架
方法
-
分布式执行:提出了一个基于ROS2的系统框架,允许完全去中心化的GNN策略执行。
-
案例研究:通过一个需要机器人之间紧密协调的案例研究来演示框架,展示了在去中心化多机器人系统上成功部署基于GNN的策略。
-
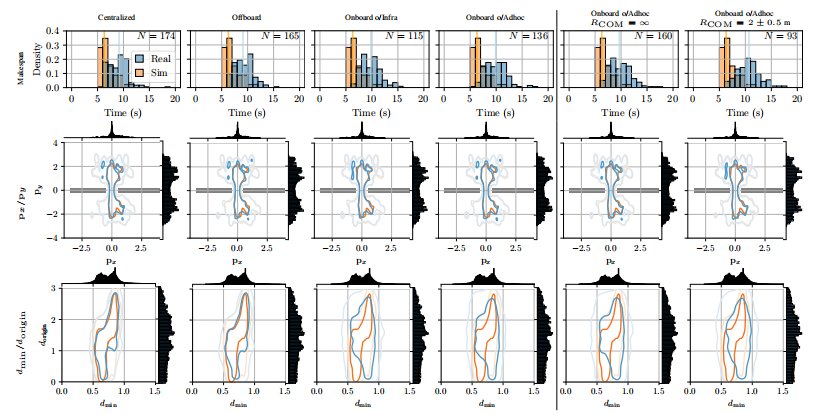
网络配置:介绍了不同的评估模式和网络配置,包括集中式、离板式、基于基础设施的船上式和基于Adhoc网络的船上式。
创新点
-
去中心化执行:首次在现实世界中部署基于GNN的策略到完全去中心化的多机器人系统,使用ROS2和Adhoc通信网络,成功率高达90.1%,比集中式模式低5.7个百分点。
-
框架设计:提出了一个基于ROS2的软件和网络框架,支持在模拟和现实世界中运行GNN和其他消息传递算法,允许以集中式或去中心化方式执行GNN策略。
-
性能比较:通过实验比较了集中式执行和三种去中心化策略执行之间的性能变化,包括离板式、基于基础设施的船上式和基于Adhoc网络的船上式,显示出在不同网络配置下的性能差异。
论文2:Graph Neural Network Reinforcement Learning for Autonomous Mobility-on-Demand Systems
用于自动驾驶按需出行系统的图神经网络强化学习
方法
-
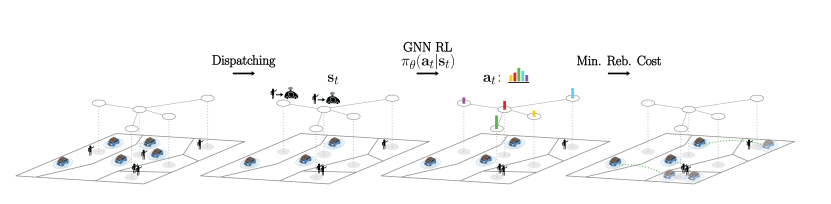
深度强化学习框架:提出了一个控制自动驾驶按需出行系统(AMoD)的深度强化学习框架,通过图神经网络实现系统重新平衡。
-
图结构利用:利用图结构来表示城市交通网络,通过图卷积网络(GCN)进行信息传播和决策。
-
节点级决策:将AMoD控制问题转化为节点级决策问题,每个节点代表城市的一个区域。
创新点
-
策略可转移性:展示了通过图神经网络学习的行为策略在不同城市间具有显著的零样本转移能力,如城市间泛化、服务区域扩展和适应复杂城市拓扑结构。
-
性能提升:在成都和纽约的真实出行数据上评估,与基于控制的方法和学习型方法相比,提出的框架在性能上接近最优,成都服务区域扩展实验中,与完全重新训练的模型相比,仅下降2.5%。
-
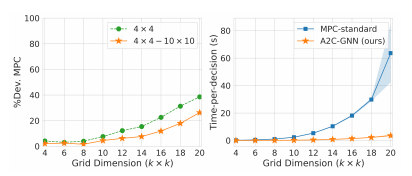
计算效率:与基于模型预测控制(MPC)的传统控制策略相比,基于图神经网络的强化学习方法在计算上更为高效,尤其是在大型网络中。
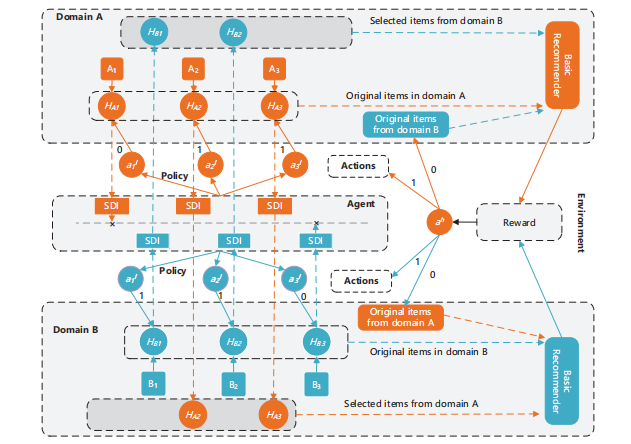
论文3:Reinforcement Learning-enhanced Shared-account Cross-domain Sequential Recommendation
增强型共享账户跨域序列推荐
方法
-
强化学习解决方案:提出了一种基于强化学习的解决方案RL-ISN,包含基础跨域推荐器和基于强化学习的领域过滤器。
-
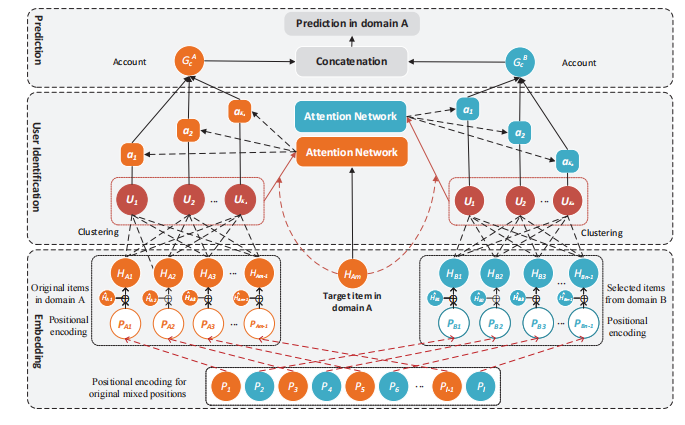
用户识别网络:通过聚类用户混合行为作为潜在用户,并利用注意力模型进行用户识别。
-
层次化强化学习任务:将领域过滤器设计为层次化强化学习任务,高层任务决定是否修改整个转移序列,低层任务决定是否移除序列中的每个交互。
创新点
-
用户特定账户表示:通过关注最近行为来学习更准确的用户特定账户表示,提高了推荐准确性。
-
跨域推荐性能提升:通过强化学习增强的领域过滤器,减少了不相关领域信息的影响,提升了跨域推荐性能,在HVIDEO数据集上比基线方法提升了56.71%。
-
层次化强化学习策略:通过层次化强化学习策略,更有效地过滤不相关交互,提高了跨域推荐系统的性能。
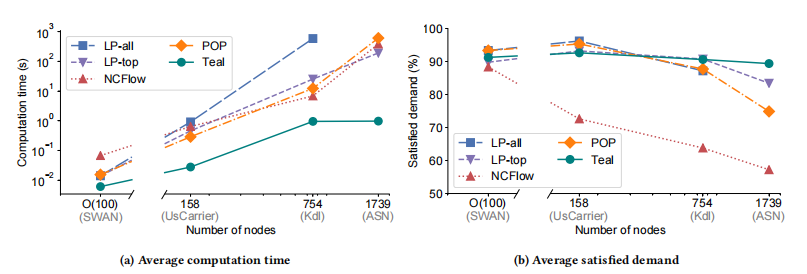
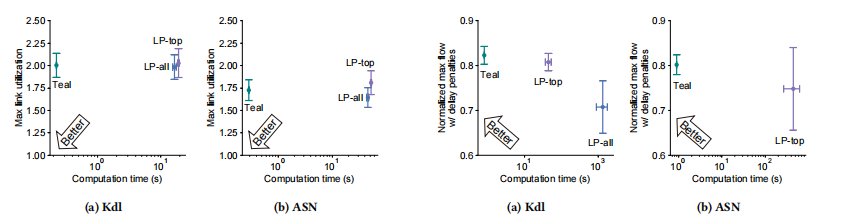
论文4:Teal: Learning-Accelerated Optimization of WAN Traffic Engineering
Teal:广域网流量工程的基于学习的加速优化
方法
-
流中心图神经网络(FlowGNN):设计了一种流中心的图神经网络来捕获广域网(WAN)的连通性和网络流量,学习流量特征作为下游分配的输入。
-
多智能体强化学习(RL)算法:采用多智能体强化学习算法独立分配每个流量需求,同时优化中心流量工程(TE)目标。
-
交替方向乘子法(ADMM):使用ADMM这一高度可并行化的优化算法进行微调,以减少约束违规,例如过载的链路。
创新点
-
流中心图神经网络(FlowGNN):通过显式表示与流量相关的实体—边缘和路径—作为TE特定GNN的节点,Teal能够捕捉WAN的连通性并在嵌入空间中编码图结构输入,相比传统的全连接神经网络更有效地处理WAN拓扑结构。
-
多智能体强化学习(RL)算法:Teal通过独立处理每个需求,使用共享策略网络,显著减少了问题的规模和学习过程中的参数数量,使得策略网络更加紧凑,并且在WAN拓扑大小上具有鲁棒性。在大型拓扑中,Teal实现了6-32%的流量需求满足度提升,并达到了197-625倍的速度提升。
-
交替方向乘子法(ADMM):Teal利用ADMM算法进行快速迭代微调,有效减少了链路过载等约束违规问题,提高了解决方案的整体质量,同时保持了计算过程的高度并行性,使得在大型WAN拓扑上的应用成为可能。
-
性能提升:在拥有超过1700个节点的大型WAN拓扑上,Teal生成了接近最优的流量分配,运行速度比生产优化引擎快几个数量级。与现有的TE加速方案相比,Teal在满足更多流量需求的同时,实现了197-625倍的加速。
需要的同学私信我
回复“GNN+强化学习”即可全部领取

















 1804
1804

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









