








1.背景
2022年,Z Chen等人受到白鹭捕食行为和自然行为启发,提出了白鹭群优化算法(Egret Swarm Optimization Algorithm, ESOA)。

2.算法原理
2.1算法思想
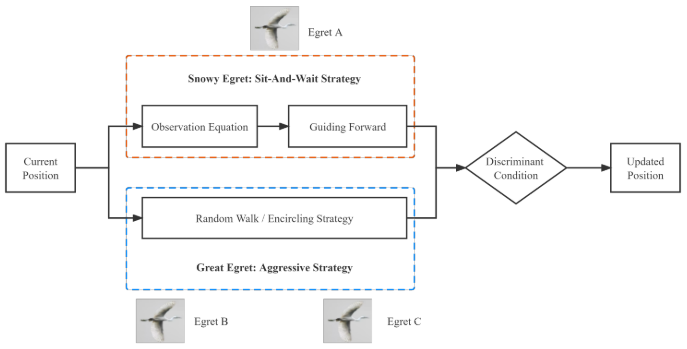
ESOA通过三个主要部分实现优化:坐等策略、主动策略和判别条件。坐等策略利用伪梯度估计器引导搜索过程,帮助算法稳定地找到最可能的解。主动策略通过随机漫游和包围机制,加强对解空间的探索,提高找到最优解的机会。判别条件则用于平衡这两种策略,确保在探索和开发之间达到合理的平衡。
2.2算法过程
坐等策略
A(∗)是白鹭对自己当前位置可能存在猎物的估计方法,y为猎物在当前位置的估计:
y
^
i
=
A
(
x
i
)
(1)
\hat{y}_i=A(\mathbf{x}_i)\tag{1}
y^i=A(xi)(1)
估计方法参数化:
y
^
i
=
w
i
⋅
x
i
(2)
\hat{y}_i=\mathbf{w}_i\cdot\mathbf{x}_i\tag{2}
y^i=wi⋅xi(2)
其中,wi∈Rn为估计方法的权值。误差ei:
e
i
=
∥
y
^
i
−
y
i
∥
2
/
2
(3)
e_i=\|\hat{y}_i-y_i\|^2/2\tag{3}
ei=∥y^i−yi∥2/2(3)
梯度与梯度方向:
g
^
i
=
∂
e
^
i
∂
w
i
=
∂
∥
y
^
i
−
y
i
∥
2
/
2
∂
w
i
=
(
y
^
i
−
y
i
)
⋅
x
i
,
d
^
i
=
g
^
i
/
∣
g
^
i
∣
.
(4)
\begin{aligned} &\hat{g}_{i} =\frac{\partial\hat{e}_{i}}{\partial\mathbf{w}_{i}} \\ &=\frac{\partial\|\hat{y}_{i}-y_{i}\|^{2}/2}{\partial\mathbf{w}_{i}} \\ &=(\hat{y}_{i}-y_{i})\cdot\mathbf{x}_{i}, \\ &\mathbf{\hat{d}}_{i} =\mathbf{\hat{g}}_{i}/|\mathbf{\hat{g}}_{i}|. \end{aligned}\tag{4}
g^i=∂wi∂e^i=∂wi∂∥y^i−yi∥2/2=(y^i−yi)⋅xi,d^i=g^i/∣g^i∣.(4)
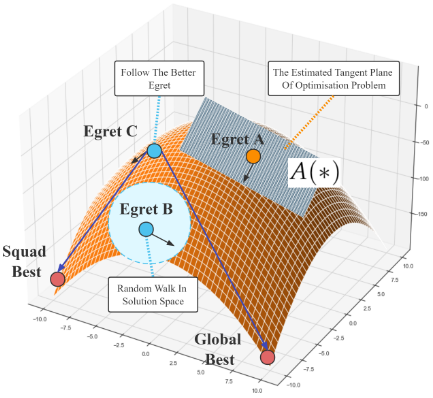
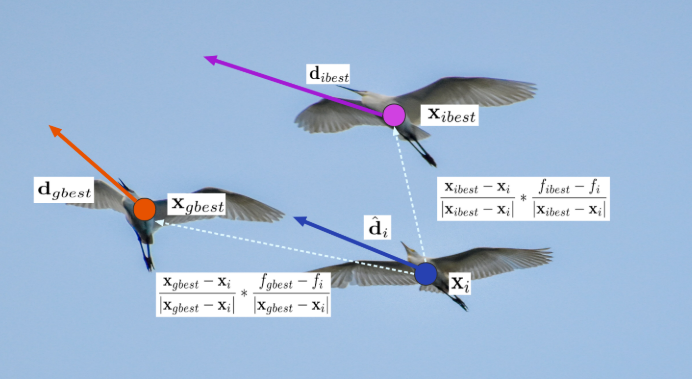
白鹿捕食过程中借鉴最优白鹿位置以及自身位置,dh,i∈Rn为小队最佳位置的方向改正量,dg,i∈Rn为所有小队最佳位置的方向改正量:
d
h
,
i
=
x
i
b
e
s
t
−
x
i
∣
x
i
b
e
s
t
−
x
i
∣
⋅
f
i
b
e
s
t
−
f
i
∣
x
i
b
e
s
t
−
x
i
∣
+
d
i
b
e
s
t
.
d
g
,
i
=
x
g
b
e
s
t
−
x
i
∣
x
g
b
e
s
t
−
x
i
∣
⋅
f
g
b
e
s
t
−
f
i
∣
x
g
b
e
s
t
−
x
i
∣
+
d
g
b
e
s
t
.
(5)
\begin{gathered} \mathbf{d}_{h,i}={\frac{\mathbf{x}_{ibest}-\mathbf{x}_{i}}{|\mathbf{x}_{ibest}-\mathbf{x}_{i}|}}\cdot{\frac{f_{ibest}-f_{i}}{|\mathbf{x}_{ibest}-\mathbf{x}_{i}|}}+\mathbf{d}_{ibest}. \\ \mathbf{d}_{g,i}={\frac{\mathbf{x}_{gbest}-\mathbf{x}_{i}}{\left|\mathbf{x}_{gbest}-\mathbf{x}_{i}\right|}}\cdot{\frac{f_{gbest}-f_{i}}{\left|\mathbf{x}_{gbest}-\mathbf{x}_{i}\right|}}+\mathbf{d}_{gbest}. \end{gathered}\tag{5}
dh,i=∣xibest−xi∣xibest−xi⋅∣xibest−xi∣fibest−fi+dibest.dg,i=∣xgbest−xi∣xgbest−xi⋅∣xgbest−xi∣fgbest−fi+dgbest.(5)
梯度gi,参数rh∈[0,0.5],rg∈[0,0.5]:
g
i
=
(
1
−
r
h
−
r
g
)
⋅
d
^
i
+
r
h
⋅
d
h
,
i
+
r
g
⋅
d
g
,
i
(6)
\mathbf{g}_i=(1-r_h-r_g)\cdot\hat{\mathbf{d}}_i+r_h\cdot\mathbf{d}_{h,i}+r_g\cdot\mathbf{d}_{g,i}\tag{6}
gi=(1−rh−rg)⋅d^i+rh⋅dh,i+rg⋅dg,i(6)
自适应权值更新:
m
i
=
β
1
⋅
m
i
+
(
1
−
β
1
)
⋅
g
i
,
v
i
=
β
1
⋅
v
i
+
(
1
−
β
1
)
⋅
g
i
2
,
W
i
=
w
i
−
m
i
/
v
i
.
(7)
\begin{aligned} &\mathbf{m}_{i} =\beta_{1}\cdot\mathbf{m}_{i}+(1-\beta_{1})\cdot\mathbf{g}_{i}, \\ &\mathbf{v}_{i} =\beta_1\cdot\mathbf{v}_i+(1-\beta_1)\cdot\mathbf{g}_i^2, \\ &\mathbf{W}_{i} =\mathbf{w}_{i}-\mathbf{m}_{i}/\sqrt{\mathbf{v}_{i}}. \end{aligned}\tag{7}
mi=β1⋅mi+(1−β1)⋅gi,vi=β1⋅vi+(1−β1)⋅gi2,Wi=wi−mi/vi.(7)
下一个采样位置xa,i:
x
a
,
i
=
x
i
+
s
t
e
p
a
⋅
exp
(
−
t
/
(
0.1
⋅
t
m
a
x
)
)
⋅
h
o
p
⋅
g
i
,
y
a
,
i
=
f
(
x
a
,
i
)
(8)
\mathbf{x}_{a,i}=\mathbf{x}_{i}+step_{a}\cdot\exp(-t/(0.1\cdot t_{max}))\cdot hop\cdot\mathbf{g}_{i},\\y_{a,i}=f(\mathbf{x}_{a,i})\tag{8}
xa,i=xi+stepa⋅exp(−t/(0.1⋅tmax))⋅hop⋅gi,ya,i=f(xa,i)(8)
主动策略
白鹭B倾向于随机寻找猎物:
x
b
,
i
=
x
i
+
s
t
e
p
b
⋅
tan
(
r
b
,
i
)
⋅
h
o
p
/
(
1
+
t
)
,
y
b
,
i
=
f
(
x
b
,
i
)
(9)
\mathbf{x}_{b,i}=\mathbf{x}_{i}+step_{b}\cdot\tan\left(\mathbf{r}_{b,i}\right)\cdot hop/(1+t),\\y_{b,i}=f(\mathbf{x}_{b,i})\tag{9}
xb,i=xi+stepb⋅tan(rb,i)⋅hop/(1+t),yb,i=f(xb,i)(9)
白鹭C倾向于积极地追捕猎物,因此采用包围机制作为其位置更新:
D
h
x
i
b
e
s
t
−
x
i
,
D
g
=
x
g
b
e
s
t
−
x
i
,
x
c
,
i
=
(
1
−
r
i
−
r
g
)
⋅
x
i
+
r
h
⋅
D
h
+
r
g
⋅
D
g
,
y
c
,
i
=
f
(
x
c
,
i
)
.
(10)
\begin{aligned} &\mathbf{D}_{h} \mathbf{x}_{ibest}-\mathbf{x}_{i}, \\ &\mathbf{D}_{g} =x_{gbest}-x_{i}, \\ &\mathbf{x}_{c,i} =(1-\mathbf{r}_{i}-\mathbf{r}_{g})\cdot\mathbf{x}_{i}+\mathbf{r}_{h}\cdot\mathbf{D}_{h}+\mathbf{r}_{g}\cdot\mathbf{D}_{g}, \\ &y_{c,i}=f(\mathbf{x}_{c,i}). \end{aligned}\tag{10}
Dhxibest−xi,Dg=xgbest−xi,xc,i=(1−ri−rg)⋅xi+rh⋅Dh+rg⋅Dg,yc,i=f(xc,i).(10)
h是当前位置和这个白鹭小队最佳位置之间的差距矩阵,Dg是所有白鹭小队最佳位置之间的差距矩阵。xc,i为白鹭c的期望位置,stepb∈(0,1]为白鹭B的步长因子。Rh和rg是[0,0.5]随机数。
判别条件
在白鹭小组的每个成员决定了自己的计划后,小组选择最优方案并一起采取行动。xs,i为第i个白鹭班的解矩阵:
x
s
,
i
=
[
x
a
,
i
x
b
,
i
x
c
,
i
]
,
y
s
,
i
=
[
y
a
,
i
y
b
,
i
y
c
,
i
]
,
c
i
=
a
r
g
m
i
n
(
y
s
,
i
)
,
x
i
=
{
x
s
,
i
∣
c
i
i
f
y
s
,
i
∣
c
i
<
y
i
o
r
r
<
0.3
,
x
i
e
l
s
e
(11)
\begin{aligned}&\mathbf{x}_{s,i}=[\mathbf{x}_{a,i}\quad\mathbf{x}_{b,i}\quad\mathbf{x}_{c,i}],\\&\mathbf{y}_{s,i}=[y_{a,i}\quad y_{b,i}\quad y_{c,i}],\\&c_{i}=argmin(\mathbf{y}_{s,i}),\\&\mathbf{x}_{i}=\begin{cases}\mathbf{x}_{s,i}|_{c_i}&if&\mathbf{y}_{s,i}|_{c_i}<y_i&or&r<0.3,\\\mathbf{x}_{i}&&else\end{cases}\end{aligned}\tag{11}
xs,i=[xa,ixb,ixc,i],ys,i=[ya,iyb,iyc,i],ci=argmin(ys,i),xi={xs,i∣cixiifys,i∣ci<yielseorr<0.3,(11)
伪代码

3.结果展示
使用测试框架,测试ESOA性能 一键run.m
CEC2017-F14
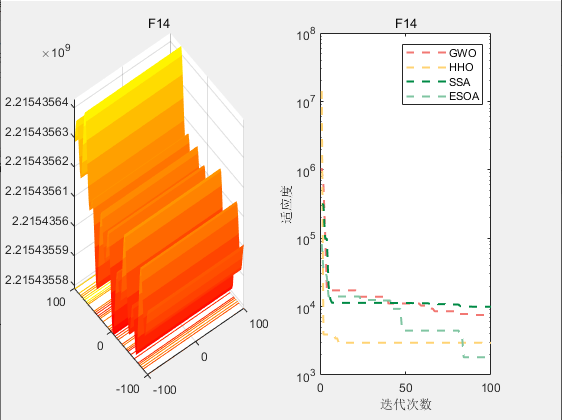
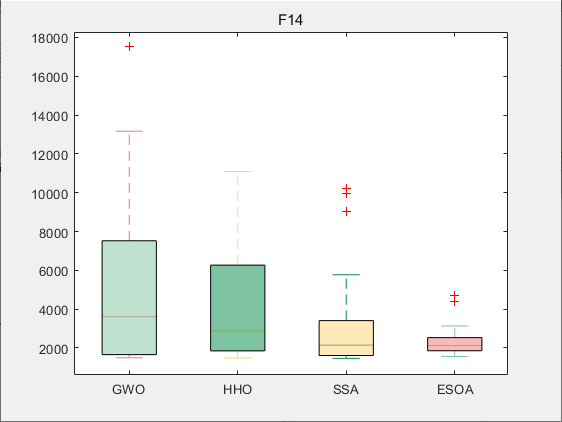

4.参考文献
[1] Chen Z, Francis A, Li S, et al. Egret swarm optimization algorithm: an evolutionary computation approach for model free optimization[J]. Biomimetics, 2022, 7(4): 144.
















 1835
1835

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











