










1.算法原理
——复现文章:DMT-OMPA:基于动态矩阵变换的高效对抗性海洋捕食者算法在工程设计优化中的创新应用(DMT-OMPA: Innovative applications of an efficient adversarial Marine Predators Algorithm based on dynamic matrix transformation in engineering design optimization)
2.摘要
本文介绍了一种创新的海洋捕食者算法(MPA)变体,称为基于动态矩阵转换的对抗性海洋捕食者算法(DMT-OMPA),旨在提高工程优化策略的效率。传统的MPA存在几个缺点,包括在初始化阶段解决方案多样性和覆盖率不足、容易陷入局部最优,以及在迭代后期搜索能力不足,这些都负面影响了算法的效率和有效性。为了解决这些问题,DMT-OMPA结合了对抗学习机制和动态矩阵转换策略,显著增强了全局搜索能力。
3.改进点
Transformation matrix
采用一种类似于仿射变换的方法来指导种群的搜索行为:
P
r
a
y
→
C
⊗
P
r
a
y
+
C
ˉ
⊗
P
r
a
y
B
(1)
Pray\to C\otimes Pray+\bar{C}\otimes Pray_B\tag{1}
Pray→C⊗Pray+Cˉ⊗PrayB(1)
其中,Pray代表粒子群的当前位置,而C和
C
ˉ
\bar{C}
Cˉ分别代表仿射变换中的变换矩阵和平移向量。C作为协作搜索矩阵,不仅指导个体间的协作和信息共享,还通过
C
ˉ
\bar{C}
Cˉ引入随机性和多样性到搜索过程中,
C
ˉ
\bar{C}
Cˉ是𝐶矩阵元素的逆二进制操作。如果所有元素为0,则逆元素设为1,从而显著增强算法的全球搜索能力。矩阵C起始为所有元素等于1的下三角矩阵,并通过两个连续操作巧妙地转变为矩阵C。
C
inf
=
[
1
0
⋯
0
1
1
⋯
0
⋮
⋮
⋱
⋮
1
1
⋯
1
]
∼
[
0
1
⋯
0
1
0
⋯
1
⋮
⋮
⋱
⋮
1
1
⋯
0
]
=
C
(2)
C_{\inf}=\left[\begin{array}{cccc}1&0&\cdots&0\\1&1&\cdots&0\\\vdots&\vdots&\ddots&\vdots\\1&1&\cdots&1\end{array}\right]\sim\left[\begin{array}{cccc}0&1&\cdots&0\\1&0&\cdots&1\\\vdots&\vdots&\ddots&\vdots\\1&1&\cdots&0\end{array}\right]=C\tag{2}
Cinf=
11⋮101⋮1⋯⋯⋱⋯00⋮1
∼
01⋮110⋮1⋯⋯⋱⋯01⋮0
=C(2)
这种变换方法不仅体现了传统仿射变换的本质,还融入了随机性元素,确保每个个体的搜索路径具有独特性和创新性。
Dynamic search strategy
将动态搜索策略与海洋捕食者算法(MPA)中的鱼类聚集(FAD)效应结合,意味着在全局搜索中利用动态搜索策略的精确性和效率。这种策略使算法能够寻找局部最优解,同时保留逃离这些区域并探索更广泛搜索空间的能力:
{
M
=
P
r
a
y
g
b
e
s
t
+
t
∗
(
P
r
a
y
r
1
−
P
r
a
y
r
2
)
P
r
a
y
→
C
⊗
P
r
a
y
+
C
ˉ
⊗
M
(3)
\begin{cases}&M=Pray_{\mathrm{gbest}}+t*(Pray_{r1}-Pray_{r2})\\&Pray\to C\otimes Pray+\bar{C}\otimes M\end{cases}\tag{3}
{M=Praygbest+t∗(Prayr1−Prayr2)Pray→C⊗Pray+Cˉ⊗M(3)
其中,t是差分矩阵的系数因子/步长,控制每次迭代中个体位置更新的步长。通过Prayr1和Prayr2的随机排列生成差分矩阵,实现对每个个体更新方向的动态调整。
Enhanced Opposition Learning method (EOL)
引入了一种创新的“增强对立学习策略”(EOL),以扩展算法的搜索能力,并加速海洋捕食者算法(MPA)的收敛:
X
=
l
b
+
r
a
n
d
(
g
r
o
u
p
_
s
i
z
e
,
d
i
m
)
×
(
u
b
−
l
b
)
(4)
X=lb+\mathrm{rand}(\mathrm{group_{\_}size,dim})\times(ub-lb)\tag{4}
X=lb+rand(group_size,dim)×(ub−lb)(4)
在生成初始解决方案之后,为了提高搜索效率并促进算法的快速收敛,引入了改进的对立学习策略(EOL):
O
B
L
P
r
a
y
=
1
+
s
i
z
e
(
dim
,
2
)
−
X
(5)
\mathrm{OBLPray}=1+\mathrm{size}(\dim,2)-X\tag{5}
OBLPray=1+size(dim,2)−X(5)
伪代码

4.结果展示
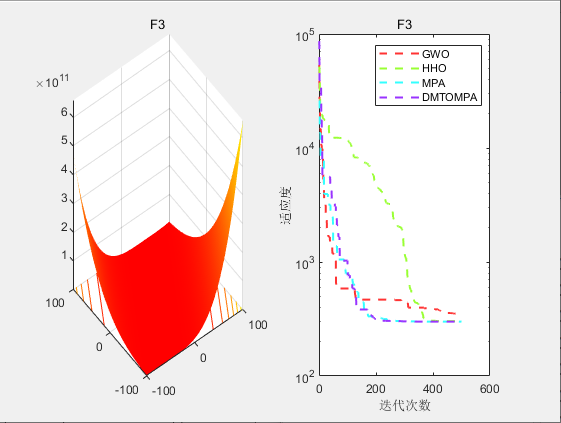
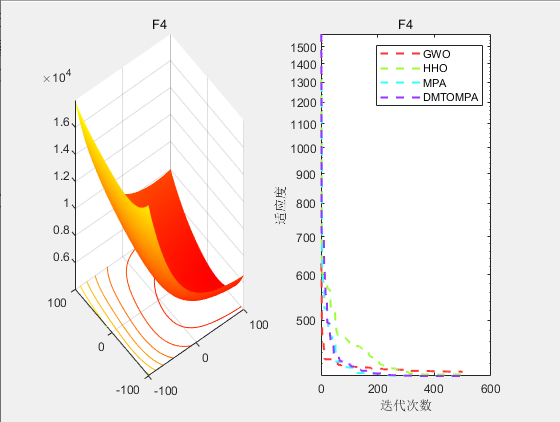
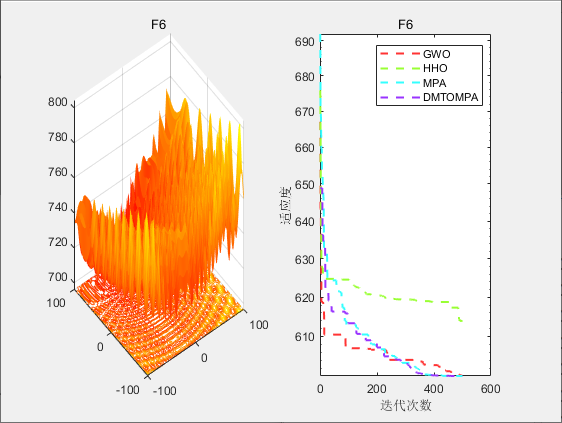
5.参考文献
[1] Zhang Z, Chu S C, Nguyen T T, et al. DMT-OMPA: Innovative applications of an efficient adversarial Marine Predators Algorithm based on dynamic matrix transformation in engineering design optimization[J]. Computer Methods in Applied Mechanics and Engineering, 2024, 431: 117247.



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











