











1.摘要
蜘蛛黄蜂优化(SWO)算法是一种基于群体智能的优化方法,模拟雌性蜘蛛黄蜂的捕猎、筑巢和交配行为,具备快速搜索和高精度的优点。然而,在处理复杂的优化问题时,SWO算法常常面临局部最优、早期收敛较慢以及权衡率参数需要手动调整等问题。因此,本文提出了多策略改进的蜘蛛黄蜂优化算法(MISWO),该算法通过引入灰狼算法增强早期收敛性,优化初始种群的适应度,从而提高全局优化能力。同时,结合自适应步长操作算子和高斯变异,能够在不同优化阶段自动调整搜索范围,提升优化精度并有效避免局部最优。
2.蜘蛛黄蜂优化算法SWO原理
3.改进策略
基于灰狼算法初始化种群
蜘蛛黄蜂优化(SWO)算法虽然具有较强的种群多样性,有助于搜索最优解,但这种多样性往往会影响算法的收敛性能。本文提出了一种结合灰狼算法初始化种群策略,其首先通过GWO算法初始化蜘蛛黄蜂种群,使得初始种群分布更加集中,优化方向更为明确,从而加速算法的收敛过程:
S
W
I
→
=
L
+
r
∗
(
H
−
L
)
G
I
→
=
F
l
(
S
W
i
→
)
\overrightarrow{SW_{\mathrm{I}}}=\mathbf{L}+\mathbf{r}*(\mathbf{H}-\mathbf{L})\\\overrightarrow{G_{\mathrm{I}}}=F_{l}\left(\overrightarrow{SW_{\mathrm{i}}}\right)
SWI=L+r∗(H−L)GI=Fl(SWi)
自适应步长算子和动态权衡率
在蜘蛛黄蜂优化(SWO)算法的捕猎行为中,采用两种不同的步长进行解空间探索:大步长搜索用于维持种群的全局搜索能力,小步长搜索则专注于已知解的邻域探索。雌性黄蜂通过持续的大步长搜索寻找适合后代的蜘蛛:
S
W
i
→
t
+
1
=
S
W
i
→
t
+
μ
1
∗
(
S
W
a
→
t
−
S
W
b
→
t
)
\overrightarrow{SW_\mathrm{i}}^{t+1}=\overrightarrow{SW_\mathrm{i}}^t+\mu_1*\left(\overrightarrow{SW_a}^t-\overrightarrow{SW_b}^t\right)
SWit+1=SWit+μ1∗(SWat−SWbt)
其中,
μ
1
\mu_1
μ1控制蜘蛛黄蜂的移动方向:
μ
1
=
∣
r
n
∣
∗
r
1
\mu_1=\begin{vmatrix}rn\end{vmatrix}*r_1
μ1=
rn
∗r1
使用小步长探索被丢弃蜘蛛周围的区域:
S
W
i
→
t
+
1
=
S
W
c
→
t
+
μ
2
∗
(
L
+
r
2
∗
(
H
−
L
)
)
\overrightarrow{SW_i}^{t+1}=\overrightarrow{SW_c}^t+\mu_2*(\mathbf{L}+\mathbf{r}_2*(\mathbf{H}-\mathbf{L}))
SWit+1=SWct+μ2∗(L+r2∗(H−L))
蜘蛛黄蜂优化(SWO)算法在更新种群时采用两种随机选择的搜索方法,但由于使用固定步长,限制了算法在早期快速识别高质量解的能力,并影响了后期的收敛精度。为了解决这一问题,本文引入了自适应步长操作算子
h
h
h,该操作算子确保在早期阶段保持全局搜索能力,并在后期加快收敛速度:
h
=
(
e
−
t
t
max
)
20
h=\left(e^{-\sqrt{\frac{t}{t_{\max}}}}\right)^{20}
h=(e−tmaxt)20
为了防止蜘蛛黄蜂优化(SWO)算法在搜索过程中陷入局部最优解,本文引入了高斯变异策略。高斯变异利用高斯分布生成变异向量,能够在均值附近产生较高概率的数据点,进而在当前最优解附近进行精细搜索,提升局部搜索能力。将高斯变异引入自适应步长操作算子和搜索阶段更新:
{
S
W
→
i
t
+
1
=
(
S
W
→
i
t
+
μ
1
∗
(
S
W
→
a
t
−
S
W
→
b
t
)
∗
h
)
+
G
a
u
s
s
S
W
→
i
t
+
1
=
(
S
W
→
c
t
+
μ
2
∗
(
L
+
r
2
→
∗
(
H
−
L
)
)
∗
h
)
+
G
a
u
s
s
\left\{\begin{array}{c}\overrightarrow{SW}_{\mathrm{i}}^{t+1}=\left(\overrightarrow{SW}_{\mathrm{i}}^{t}+\mu_{1}*\left(\overrightarrow{SW}_{a}^{t}-\overrightarrow{SW}_{b}^{t}\right)*h\right)+Gauss\\\overrightarrow{SW}_{\mathrm{i}}^{t+1}=\left(\overrightarrow{SW}_{\mathrm{c}}^{t}+\mu_{2}*(\mathbf{L}+\overrightarrow{r_{2}}*(\mathbf{H}-\mathbf{L}))*h\right)+Gauss\end{array}\right.
⎩
⎨
⎧SWit+1=(SWit+μ1∗(SWat−SWbt)∗h)+GaussSWit+1=(SWct+μ2∗(L+r2∗(H−L))∗h)+Gauss
权衡率
T
R
TR
TR控制着捕猎和交配行为之间的平衡:
{
F
(
H
)
or
F
(
N
)
rand
<
T
R
F
(
M
)
otherwise
\left\{\begin{array}{c}F(H)\text{or}F(N)\text{rand}<TR\\F(M)\text{otherwise}\end{array}\right.
{F(H)orF(N)rand<TRF(M)otherwise
其中,
F
(
H
)
,
F
(
N
)
F(H),F(N)
F(H),F(N)表示狩猎或筑巢行为,
F
(
M
)
F(M)
F(M)表示交配行为。自适应步长算子表述为:
T
R
n
=
1
−
(
e
(
t
t
max
−
1
)
∗
rand
(
)
)
TR_n=1-\left(e^{\left(\sqrt{\frac{t}{t_{\max}}}-1\right)*\operatorname{rand}()}\right)
TRn=1−(e(tmaxt−1)∗rand())
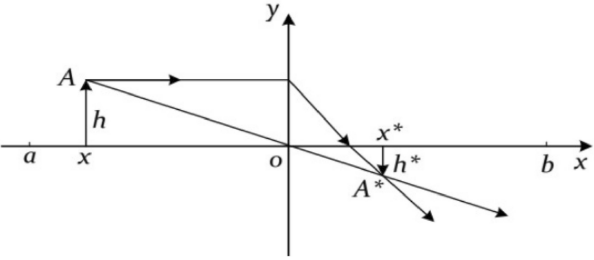
动态透镜成像反向学习策略
反向学习通过计算当前种群位置的反向解来扩展搜索空间,从而显著提升优化性能并加速收敛。然而,随着迭代的进行,反向学习在帮助算法逃脱局部最优解方面可能逐渐失效,导致收敛精度下降。本文提出了动态透镜成像反向学习策略,其灵感来自于凸透镜成像原理,该策略通过模拟透镜成像效应,动态调整搜索范围:
x
∗
=
(
a
+
b
)
2
+
(
a
+
b
)
2
k
−
x
k
x^*=\frac{(a+b)}{2}+\frac{(a+b)}{2k}-\frac{x}{k}
x∗=2(a+b)+2k(a+b)−kx
其中,参数
k
k
k表述为:
k
=
(
1
0
3
+
(
3
t
t
max
)
1
2
)
10
k=\left(10^3+\left(\frac{3t}{t_{\max}}\right)^{\frac12}\right)^{10}
k=(103+(tmax3t)21)10
4.结果展示
CEC2005








5.参考文献
[1] Sui J, Tian Z, Wang Z. Multiple strategies improved spider wasp optimization for engineering optimization problem solving[J]. Scientific Reports, 2024, 14(1): 29048.



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











