







BEVDistill 是一种针对多视角3D目标检测的跨模态特征蒸馏方法,核心思想是通过对齐视觉(相机)和点云(LiDAR)模态的鸟瞰图(BEV)特征表示,将点云模态的知识迁移到纯视觉模型中,从而提升检测性能。其关键技术点包括:
-
跨模态BEV特征对齐
- 通过设计模态间和模态内的对比学习损失(contrastive loss),缩小两种模态在BEV空间的特征分布差异,例如使用动态权重调整(Dynamic Weighting)解决模态间特征尺度不一致问题。
-
自适应RoI蒸馏
- 提出基于检测任务需求的自适应区域选择策略,在BEV空间中对关键区域(如物体边界、高密度区域)进行知识蒸馏,而非全局特征迁移。使用 L d i s t i l l = ∑ i α i ⋅ ∣ ∣ f 0 l i d a r i − f c a m e r a i ∣ ∣ 2 L_{distill} = \sum_{i}\alpha_i \cdot ||f_{0lidar}^i - f_{camera}^i||^2 Ldistill=i∑αi⋅∣∣f0lidari−fcamerai∣∣2 实现局部特征对齐,其中αiαi为区域重要性权重。
-
多阶段训练策略
- 第一阶段:用点云数据预训练强教师模型(LiDAR-based)
- 第二阶段:冻结教师模型参数,联合优化视觉BEV编码器和跨模态对齐模块
- 最终仅保留纯视觉推理分支,实现无LiDAR的部署
论文:https://arxiv.org/pdf/2211.09386.pdf
代码:https://github.com/zehuichen123/BEVDistill
概述
从多个图像视图中进行 3D 物体检测是视觉场景理解的一项基本且具有挑战性的任务。由于其成本低、效率高,多视图 3D 物体检测已显示出良好的应用前景。然而,由于缺乏深度信息,通过透视图准确检测物体极其困难。当前的方法倾向于采用重型主干作为图像编码器,使其不适用于实际部署。与图像不同,LiDAR 点在提供空间线索方面更胜一筹,从而实现高精度定位。在本文中,我们探索了将基于 LiDAR 的检测器用于多视图 3D 物体检测。我们没有直接训练深度预测网络,而是将图像和 LiDAR 特征统一在鸟瞰 (BEV) 空间中,并在师生范式中自适应地跨非同质表示传递知识。为此,我们提出了 BEVDistill,这是一种用于多视图 3D 物体检测的跨模态 BEV 知识蒸馏 (KD) 框架。大量实验表明,所提出的方法在竞争激烈的基线 BEVFormer 上的表现优于当前的 KD 方法,而且在推理阶段不会引入任何额外成本。值得注意的是,我们的最佳模型在 nuScenes 测试排行榜上取得了 59.4 NDS,与各种基于图像的检测器相比,达到了新的最佳水平。代码将在 https://github.com/zehuichen123/BEVDistill 上提供。
1 INTRODUCTION
3D 物体检测旨在定位 3D 空间中的物体,是 3D 场景理解的关键要素。它已广泛应用于各种应用,例如自动驾驶(Chen 等人,2022a;Shi 等人,2020;Wang 等人,2021b)、机器人导航(Antonello 等人,2017)和虚拟现实(Schuemie 等人,2001)。最近,多视角 3D 物体检测因其低成本和高效率而引起了极大关注。由于图像具有辨别性外观和密集像素的丰富纹理,因此检测器即使在很远的距离也可以轻松发现和分类物体。尽管具有良好的部署优势,但仅从相机视图准确定位实例极其困难,这主要是由于单目图像的不适定性质。因此,最近的方法采用重型主干(例如 ResNet-101-DCN(He et al.,2016)、VoVNetV2(Lee & Park,2020))进行图像特征提取,使其不适用于实际应用。
LiDAR 点可捕捉精确的 3D 空间信息,为基于相机的物体检测提供自然引导。鉴于此,最近的研究(Guo et al., 2021b;Peng et al., 2021)开始探索将点云纳入 3D 物体检测以提高性能。其中一项工作(Wang et al., 2019b)将每个点投影到图像上以形成深度图标签,然后训练深度估计器以明确提取空间信息。这种范式会生成中间产品,即深度预测图,因此会引入额外的计算成本。另一项工作(Chong et al., 2021)是利用师生范式进行知识转移。(Chong et al., 2021)将 LiDAR 点投影到图像平面,为教师模型构建 2D 输入。由于学生和老师模型在结构上完全相同,因此可以在该框架下自然地进行特征模仿。虽然它解决了不同模态之间的对齐问题,但它错过了追求强大的基于 LiDAR 的老师的机会,这在知识蒸馏 (KD) 范式中确实很重要。最近,UVTR (Li et al., 2022a) 提出在体素空间中提炼跨模态知识,同时保持各个检测器的结构。然而,它直接迫使 2D 分支模仿 3D 特征,而忽略了不同模态之间的差异。
在本文中,通过仔细研究二维和三维空间中表示的非同质特征,我们探索了将知识蒸馏纳入多视角三维物体检测的方法。然而,存在两个技术挑战。首先,图像和 LiDAR 点的视图不同,即相机特征处于透视视图中,而 LiDAR 特征处于 3D/鸟瞰视图中。这种视图差异表明自然的一对一模仿(Romero et al., 2014)可能并不合适。其次,RGB 图像和点云在各自的模态中拥有各自的表示。因此,直接模仿特征可能不是最优的,这在二维检测范式中很常见(Yang et al., 2022a; Zhang & Ma, 2020)。
我们通过设计一个跨模态 BEV 知识蒸馏框架(即 BEVDistill)来解决上述挑战。我们不是构建单独的深度估计网络或明确将一个视图投影到另一个视图中,而是将所有特征转换为 BEV 空间,同时保留几何结构和语义信息。通过共享的 BEV 表示,来自不同模态的特征可以自然对齐,而不会丢失太多信息。之后,我们通过密集和稀疏监督自适应地传输空间知识:(i)我们引入软前景引导蒸馏来进行非同质密集特征模仿,(ii)提出了一种稀疏式实例蒸馏范式,通过最大化互信息来有选择地监督学生。
在竞争性 nuScenes 数据集上的实验结果证明了我们的 BEVDistill 的优越性和泛化性。例如,在单帧和多帧设置下,我们分别在竞争性多视图 3D 检测器 BEVFormer (Li et al., 2022c) 上实现了 3.4 NDS 和 2.7 NDS 的改进。此外,我们还对轻量级主干进行了广泛的实验,并进行了详细的消融研究以验证我们方法的有效性。值得注意的是,我们的最佳模型在 nuScenes 测试排行榜上达到了 59.4 NDS,在所有已发布的多视图 3D 检测器中取得了新的最先进结果。
2 RELATED WORK
2.1 VISION-BASED 3D OBJECT DETECTION
基于视觉的 3D 物体检测旨在检测物体的位置、比例和旋转,这在自动驾驶 (Xie et al., 2022; Jiang et al., 2022; Zhang et al., 2022) 和增强现实 (Azuma, 1997) 中非常重要。其中一项工作是直接从单幅图像中检测 3D 框。Mono3D (Chen et al., 2016) 利用传统方法将 2D 物体提升到 3D 空间,并附带语义和几何信息。考虑到位于不同距离的物体出现在不同的尺度上,D4LCN (Ding et al., 2020) 提出利用深度预测进行卷积核学习。最近,FCOS3D (Wang et al., 2021a) 将经典的 2D 范式 FCOS (Tian et al., 2019b) 扩展到单目 3D 物体检测。它通过预测回归目标的二维属性将其转换为图像域。此外,PGD(Wang 等人,2022b)引入了关系图来改进对象定位的深度估计。MonoFlex(Zhang 等人,2021)认为位于不同位置的物体不应被平等对待,并提出了自动调整的监督。
另一项工作是从多视角图像中预测物体。DETR3D (Wang et al., 2022c) 首先通过引入一个新概念:3D 参考点,将 DETR (Carion et al., 2020) 融入 3D 检测。之后,Graph-DETR3D (Chen et al., 2022b) 通过使用动态图特征聚合丰富特征表示来扩展它。与上述方法不同,BEVDet (Huang et al., 2021) 利用 Lift-splat-shoot (Philion & Fidler, 2020) 将图像明确投影到 BEV 空间,然后使用传统的 3D 检测头。受最近开发的注意力机制的启发,BEVFormer (Li et al., 2022c) 以可学习的注意力方式自动化 cam2bev 过程并实现卓越的性能。 PolarFormer (Jiang et al., 2022) 将极坐标引入 BEV 空间的模型构建中,大大提高了性能。此外,BEVDepth (Li et al., 2022b) 通过使用投影的 LiDAR 点明确监督深度预测来改进 BEVDet,并实现了最佳性能。
2.2 KNOWLEDGE DISTILLATION IN OBJECT DETECTION
大多数用于物体检测的知识发现方法侧重于在两个同质检测器之间传递知识,方法是强制学生的预测与老师的预测相匹配(Chen et al., 2017; Dai et al., 2021; Zheng et al., 2022)。最近的研究(Guo et al., 2021a; Wang et al., 2019a)发现模仿特征表示对检测更有效。一个重要的挑战是确定应该从教师模型中提取哪些特征区域。FGFI(Wang et al., 2019a)选择与 GT 的 IoU 大于某个阈值的锚框所覆盖的特征。PGD(Yang et al., 2022a)仅关注几个关键的预测区域,使用分类和回归分数的组合作为质量衡量标准。
尽管有大量研究讨论了物体检测中的 KD,但只有少数研究考虑了多模态设置。MonoDistill (Chong et al., 2021) 将点投影到图像平面中,并应用经过修改的基于图像的 3D 检测器作为老师来提取知识。这样的范式自然地解决了对齐问题,但是,它错失了追求更强大的基于点的老师模型的机会。LIGA-stereo (Guo et al., 2021b) 利用 LiDAR 的信息,通过使用 SECOND (Yan et al., 2018) 的中间输出来监督基于视觉的模型的 BEV 表示。最近,UVTR (Li et al., 2022a) 提出了一种简单的方法,通过直接正则化学生和老师模型之间的体素表示。它们都选择模仿模型之间的特征表示,同时忽略不同模态之间的差异。
3 METHODS
在本节中,我们将详细介绍我们提出的 BEVDistill。我们首先在图 1 中概述了整个框架,并在第 3.1 节中阐明了教师和学生模型的模型设计。之后,我们在第 3.2 节中介绍了跨模态知识蒸馏方法,该方法由两个模块组成:密集特征蒸馏和稀疏实例蒸馏。
3.1 BASELINE MODEL
学生模型。我们采用当前最先进的基于摄像头的检测器 BEVFormer (Li et al., 2022c) 作为学生模型。它由用于特征提取的图像主干、用于 cam2bev 视图转换的空间交叉注意模块和用于 3D 对象检测的 Transformer 头组成。此外,它还提供了一个时间交叉注意模块来感知后续的多帧信息,以便做出更好的预测。
教师模型。为了与学生模型保持一致,我们选择 Object-DGCNN (Wang & Solomon, 2021) 作为我们的教师模型。为了简单和通用,我们用 vanilla 多尺度注意力模块替换了 DGCNN 注意力模块。它首先将 3D 点投射到 BEV 平面,然后使用基于 Transformer 的标签分配进行一对一监督。我们通过从预先训练的 CenterPoint 模型初始化模型来训练模型,并在知识提炼过程中修复所有参数。
3.2 BEVDISTILL
BEVDistill 遵循常见的知识蒸馏范式,以 3D 点云检测器作为老师,以图像检测器作为学生。与之前的知识蒸馏方法不同,之前的知识蒸馏方法对学生和老师模型(主干除外)保持相同的架构,而 BEVDistill 则探索了非同质表示的更具挑战性的环境。
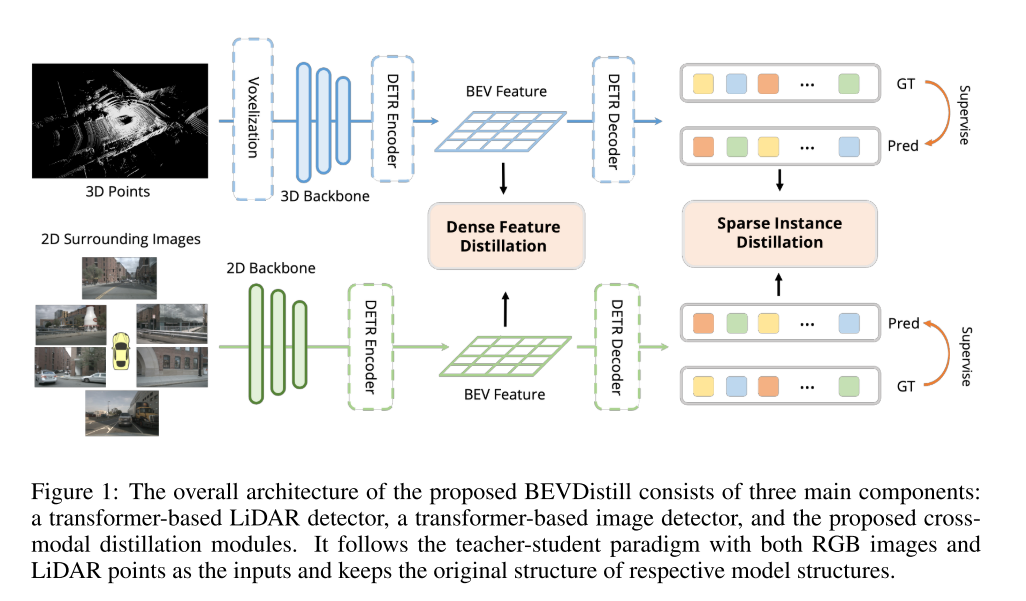
3.2.1 DENSE FEATURE DISTILLATION
为了对特征蒸馏进行密集监督,我们首先需要确定从两个模型生成的 BEV 特征。对于学生,我们直接采用 BEVTransformerEncoder 生成的 BEV 特征图 F2D。为了对齐老师和学生之间的特征表示,我们为老师模型选择由 Transformer 编码器输出的相同 BEV 特征 F3D。与直接模仿从 3D 主干中提取的 BEV 特征的 LIGA-Stereo(Guo 等人,2021b)不同,我们将这种监督推迟到 Transformer 编码器之后(如图 1 所示),这为网络提供了更多机会来对齐不同模态的信息。
以前的研究(Romero 等人,2014;Li 等人,2022a)直接迫使学生模仿老师的特征图并实现显着的性能提升:
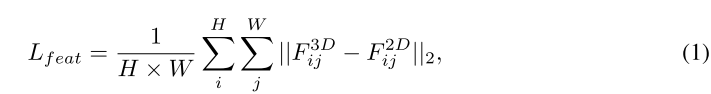
其中 H,W 表示蒸馏特征图的宽度和高度,|| · ||2 是 L2 范数。然而,这种策略在跨模态特征设置下可能效果不佳。虽然通过将两个特征投影到 BEV 平面可以消除视图差异,但不同模态之间仍然存在域差异:尽管使用点云和经过仔细对齐的图像捕获了相同的场景,但表示本身在不同模态下可能会有所不同。例如,图像包含前景和背景区域的像素,但只有当存在反射射线的物体时,LiDAR 点才会出现。
考虑到只有当点存在时,区域 3D 特征才能包含有意义的信息,我们对前景区域内的蒸馏进行了正则化。此外,我们注意到前景的边界也可以提供有用的信息,因此,我们引入了类似于 (Zhou et al., 2019) 的软监督方式,而不是对每个前景区域进行硬监督。具体来说,我们在 BEV 空间中为每个地面真实中心 (xi, yi) 绘制高斯分布,
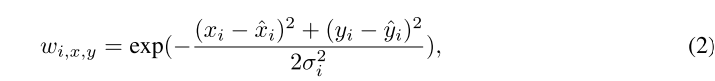
其中 σ i σ_i σi 是一个常数(默认设置为 2),表示对象大小的标准偏差。由于特征图与类别无关,我们将所有 w i , x , y w_{i,x,y} wi,x,y 合并为一个单一的掩码 W。对于同一位置的不同 w i , x , y w_{i,x,y} wi,x,y 之间的重叠区域,我们只需取它们的最大值。
之后,我们强制学生用前景引导的掩码 W 模仿特征以进行密集特征蒸馏:
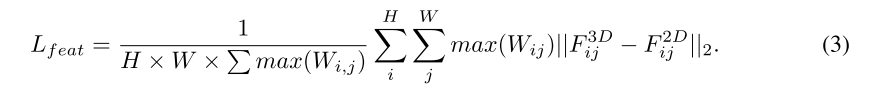
这种前景引导的重新加权策略允许模型专注于来自老师的前景区域,同时避免模仿背景区域中无用的空 3D 特征。这种方式与以前的同质知识蒸馏工作(Yang et al.,2022c)中的发现相反。
3.2.2 SPARSE INSTANCE DISTILLATION
在密集预测设置下,可以轻松进行实例级蒸馏,其中只需要像素到像素的映射即可进行监督。但是,BEVDistill 中的学生和教师模型都采用稀疏预测风格。因此,需要集合到集合的映射来确保实例级蒸馏。为了实现这一目标,我们只需遵循 (Wang & Solomon, 2021) 中的做法来构建学生和教师预测之间的对应关系。
具体来说,假设教师模型中第 i 个查询输出的分类和定位预测为 cTi 和 bT i ,学生可以表示为 cS i 和 bS i ,则可以在教师和学生的输出集之间找到一个 ˆσ 的排列,其cost最低:
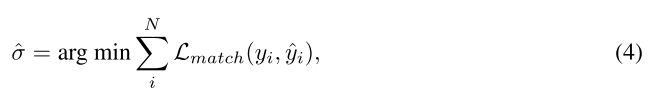
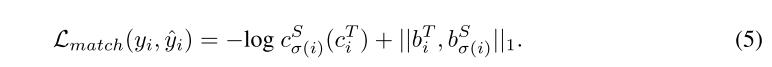
其中 Lmatch(yi, ˆyi) 是成对cost成本。
然而,我们根据经验发现这种原始蒸馏方法在跨域监督方式下效果不佳。有两个主要问题阻碍了模型进一步的性能提升。一方面,并非所有来自教师的预测都应被视为有价值的线索,因为大多数预测都是具有低分类分数的假阳性。另一方面,虽然分类逻辑可以表示丰富的知识(Hinton 等人,2015),但当输入数据不同时,它可能不成立。直接提取这些预测会给模型带来很大的噪音并降低性能
为了解决这个问题,我们利用从教师模型中得出的可靠质量分数来衡量实例级伪标签的重要性,并使用该分数作为软加权因子来消除教师做出的潜在噪音预测。具体来说,我们将分类分数 ci(分类信息)和预测与地面真相 bGT i(定位信息)之间的 IoU 一起考虑以制定质量分数
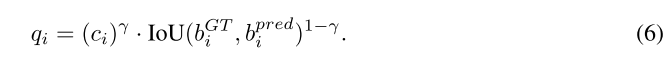
质量分数作为指导学生应该更重视教师的预测的指标。因此,最终的实例级蒸馏可以写成:
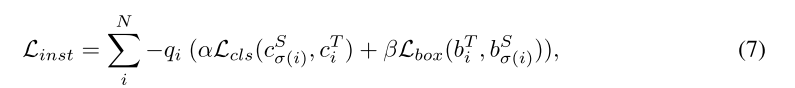
其中 Lcls 是 KL 散度损失,Lbox 是 (Wang & Solomon, 2021) 中的 L1 损失,α、β 是重新加权的因子,用于平衡监督(默认设置为 1.0 和 0.25)。鉴于类别的预测概率质量函数包含比独热标签更丰富的信息,学生模型被证明受益于这种额外的监督(Hinton 等人,2015 年)。
然而,这种低维预测分布(类数)意味着只有少量的知识被编码,从而限制了可以迁移的知识,尤其是在跨模态设置下。此外,表征知识通常是结构化的,具有跨不同维度的隐含复杂相互依赖性,而 KL 目标则独立处理所有维度。为了解决这个问题,我们不是最小化两个分布的 KL 散度,而是选择直接最大化来自教师和学生网络的倒数第二层(logits 之前)的表示 hS、hT 之间的互信息 (mutual information, MI):
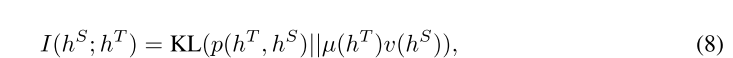
其中 p(hT, hS) 为联合分布,边际分布 µ(hT)、v(hS)。
然后,我们定义一个以 η 为条件的分布 q,该分布可捕捉该对是一致 (q(η = 1)) 还是不一致 (q(η = 0)):
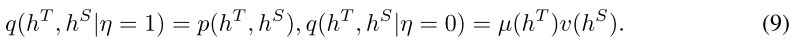
利用贝叶斯规则,我们可以得到 η = 1 的后验概率:
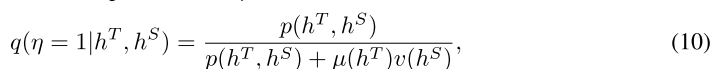
对两边取对数,我们得到
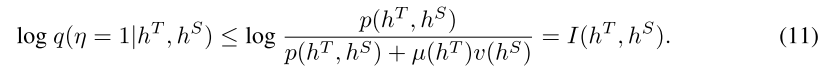
因此,可以将目标转化为最大化 MI 的下限。由于 q(η = 1|hT, hS) 没有闭式,我们利用一个称为批评家 (Tian et al., 2019a) 的神经网络 g 来近似 NCE 损失(详细实现见附录 A):

NCE Loss(Noise Contrastive Estimation Loss)
目的:NCE 是一种将密度估计问题转换为二分类问题的方法,常用于近似难以计算的概率分布,比如训练 word2vec 等模型。,它通过将目标分布与噪声分布对比,从而简化计算。在传统的最大似然估计中,我们需要计算一个非常复杂的归一化常数,但是通过 NCE,可以仅通过对比样本的概率来避免直接计算这个常数。
在标准的 NCE 损失中,我们通常需要计算一个条件概率,例如例如 q(η=1∣hT,hS),即给定 hT 和 hS 时,正样本的概率。
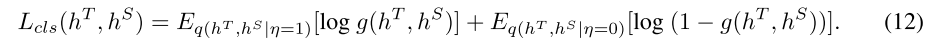
如何近似 NCE 损失:
NCE 损失本质上是在对比正负样本的过程中计算一个目标值。批评家网络通过其输出的值来近似这个过程,相当于通过一个神经网络来对噪声样本和真实样本进行评分,最终优化模型参数。
为此,最终的稀疏实例蒸馏损失可以表示为:
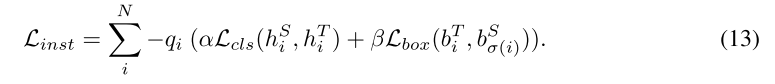
参考
https://zhuanlan.zhihu.com/p/685450088


















 143
143

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











