






参考雷达惯性里程计论文阅读笔记—FAST-LIO2 (二) - 知乎 (zhihu.com)
一、摘要
本文介绍了 FAST-LIO2:一种快速、稳健且通用的 LiDAR 惯性里程计框架。 FASTLIO2 建立在高效紧耦合迭代卡尔曼滤波器的基础上,具有两个关键创新,可实现快速、稳健和准确的 LiDAR 导航(和映射)。第一个是直接将原始点注册到地图(并随后更新地图,即映射)而不提取特征。这可以利用环境中的细微特征,从而提高准确性。手动设计的特征提取模块的消除也使其自然适应不同扫描模式的新兴激光雷达;第二个主要创新是通过增量 k-d 树数据结构 ikd-Tree 维护映射,该结构支持增量更新(即点插入、删除)和动态重新平衡。与现有的动态数据结构(octree、R∗-tree、nanoflann k-d tree)相比,ikd-Tree 在整体性能优越的同时自然支持对树的下采样。我们对来自各种开放 LiDAR 数据集的 19 个序列进行了详尽的基准比较。与其他最先进的 LiDAR 惯性导航系统相比,FAST-LIO2 始终以更低的计算负载实现更高的精度。还对具有小 FoV 的固态 LiDAR 进行了各种真实世界的实验。总体而言,FAST-LIO2 具有计算效率(例如,在大型室外环境中高达 100 Hz 的里程计和映射)、鲁棒性(例如,在旋转高达 1000 度 = s 的杂乱室内环境中可靠的姿态估计)、多功能(即,适用于多线旋转和固态激光雷达、无人机和手持平台,以及基于英特尔和 ARM 的处理器),同时仍能实现比现有方法更高的精度。
二、问题
- 目前的激光雷达传感器每秒产生数十万到数百万的大量三维点。在有限的星载计算资源下实时处理如此大量的数据,要求激光雷达测程方法具有较高的计算效率;
- 为了减少计算量,通常基于局部光滑性提取特征点,如边缘点或平面点。然而,特征提取模块的性能容易受到环境的影响。例如,在没有大平面或长边缘的无结构环境中,特征提取会导致特征点较少。当激光雷达视场(FoV)很小时,这种情况会更加严重,这是出现固态激光雷达[16]的典型现象。此外,根据扫描模式(如旋转、基于棱镜的[15]、基于mems的[14])和点密度的不同,LiDAR和LiDAR的特征提取也有所不同。因此采用激光雷达测程方法通常需要大量的手工工作;
- 激光雷达点的采样通常是连续的,而传感器经历连续的运动。这一过程造成了严重的运动失真,影响了里程计和映射的性能,特别是当运动是严重的。惯性测量单元(imu)可以缓解这个问题,但引入了额外的状态(如偏差、外部)来估计;
- 激光雷达通常有一个很长的测量范围(例如,数百米),但在扫描中扫描线之间的分辨率相当低。生成的点云测量稀疏地分布在一个大的3D空间中,需要一个大而密集的地图来登记这些稀疏的点。此外,地图需要支持有效的查询通信搜索,同时实时更新,纳入新的测量。
三、具体工作
1)我们开发了一种增量k-d树数据结构,ikd-Tree,以有效地表示一个大的稠密点云图。除了高效的最近邻搜索外,该数据结构还支持增量映射更新(即点插入、树上下采样、点删除)和以最小计算代价进行动态重新平衡。这些特性使得ikd-Tree非常适合激光雷达里程计和地图应用,在计算受限的平台上可以实现100hz里程计和地图,比如基于Intel i7的微型无人机车载计算机,甚至是基于arm的处理器。
2)由于ikd-Tree计算效率的提高,我们可以直接将原始点注册到地图上,这使得即使在剧烈运动和非常混乱的环境中,扫描配准也更加准确和可靠。我们将这种原始的基于点的配准方法称为直接方法,类似于视觉SLAM[21]。消除了手工设计的特征提取,使系统自然适用于不同的激光雷达传感器;
3)我们将这两项关键技术集成到一个紧密耦合的激光雷达-惯性里程测量系统FAST-LIO[22]中。该系统使用IMU通过严格的反向传播步长补偿每个点的运动,并通过流形迭代卡尔曼滤波器估计系统的完整状态。为了进一步加快计算速度,一个新的计算卡尔曼增益的数学等效公式被用来降低计算复杂度到状态维度(而不是测量维度)。这个新系统被称为FAST-LIO2,并在Github2上开源,以造福社区;
4)我们进行了各种实验来评估开发的ikd-Tree、直接点配准和整个系统的有效性。在18个不同大小序列上的实验表明,ikdTree在激光雷达里程测量和映射应用中,相对于现有的动态数据结构(八叉树、R∗树、纳米翼面k-d树)具有更好的性能 。通过对来自各种开放LiDAR数据集的19个序列进行详尽的基准比较,FAST-LIO2与其他最先进的LiDAR惯性导航系统相比,在较低的计算负荷下始终保持较高的精度。最后,我们展示了FAST-LIO2在具有挑战性的现实世界数据上的效果,这些数据是由新兴的固态激光雷达在非常小的视场下收集的,包括剧烈运动(例如,旋转速度高达1000℃=s)和无结构环境。
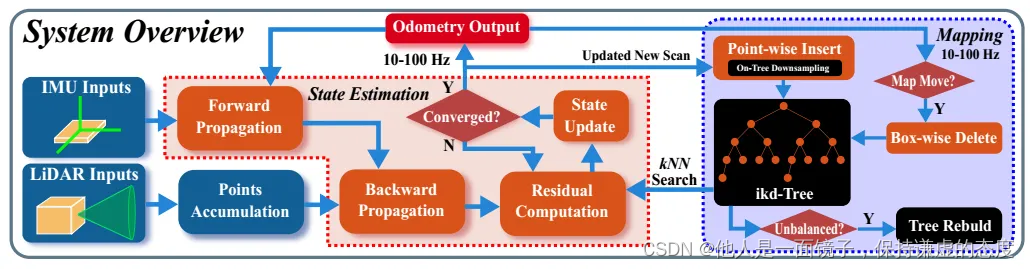
3.1 Overall pipeline
顺序采样的LiDAR原始点每10ms (100Hz更新)到100ms (10Hz更新)积累一次,累积的点云称为一次扫描。为了执行状态估计,新扫描中的点通过紧密耦合迭代卡尔曼滤波框架(红色的大虚线块)注册到大型局部地图中维护的映射点(即里程计)。大型局部地图中的全球地图点由增量k-d树结构的ikd-Tree组织(蓝色的大虚线块)。如果当前LiDAR的FoV范围越过地图边界,到LiDAR姿态的最远地图区域的历史点将从ikd-Tree中删除。因此,ikd-Tree跟踪一个大立方体区域内具有一定长度(本文中称为“地图大小”)的所有地图点,并用于计算状态估计模块中的残差。优化后的姿态最终将新扫描中的点注册到全局框架中,并通过以里程数计的速度插入到ikd-Tree中将它们合并到地图中。
Fov - 视场角 https://www.colorspace.com.cn/kb/2013/02/24/fov/
这里指 雷达视场:探测视野,包括水平和垂直两个方向,就像是我们打开手电筒照一面墙,光能覆盖的范围一样。机械式激光雷达能够360°旋转,所以水平FOV是360°。固态激光雷达的水平FOV会小一些,比如华为某款120°已经算是大视角了。水平FOV越大,能够探测的范围越广。垂直FOV只对多线束激光雷达有用。是指最上面一束激光和最下面一束激光形成的夹角。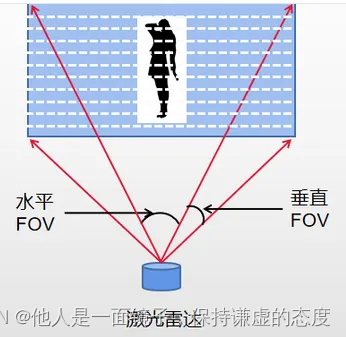
3.2 状态估计
FAST-LIO2的状态估计继承了FAST-LIO[22]的特点,是一种紧耦合迭代卡尔曼滤波器,并进一步引入了LiDAR-IMU外部参数的在线校准。
3.2.1 运动学模型
我们首先推导出(derive)系统模型,该模型由状态转移模型和度量模型组成。
(1) 状态转换模型
取第一个IMU框架(记为I)作为全局框架(记为G),记为ITL = (IRL, IpL)为LiDAR和IMU之间的未知外部属性,运动学模型为:
- 式中,GpI, GRI 表示IMU在全局框架中的位置和姿态,Gg是全局坐标系中的重力矢量,am和wm是IMU的测量值,na和nw表示am和wm的测量噪声,ba和bw表示nba和nbw驱动下的随机游动过程模型的IMU偏差,符号|a|^表示一个映射了叉乘运算的向量a∈R3的斜对称矩阵。
设i为IMU测量值的索引。根据[22]中定义的运算符□+,可以在IMU采样周期∆t处对连续运动学模型(1)进行离散化:
函数f、状态x、输入u和噪声w,定义如下:
(2) 测量模型
- 激光雷达通常一个接一个地采样点。因此,当 LiDAR 进行连续运动时,会以不同的姿势对结果点进行采样。为了纠正这种扫描中的运动,我们采用了[22]中提出的反向传播,它根据IMU测量值估计扫描中每个点相对于扫描结束时间的位姿的激光雷达位姿。估计的相对姿态使我们能够根据扫描中每个单独点的精确采样时间,将所有点投射到扫描结束时间。因此,扫描中的点可以被视为在扫描结束时同时采样的所有点。
- 设k为LiDAR扫描的索引,{Lpj, j=1,...,m}为第k次扫描在扫描结束时在本地LiDAR坐标系L上采样的点。由于激光雷达的测量噪声,每个测量点Lpj通常会受到由测距和定向噪声组成的噪声Lnj的污染。去除这些噪声,就得到了在激光雷达局部坐标系中的真点位置Lpjgt:
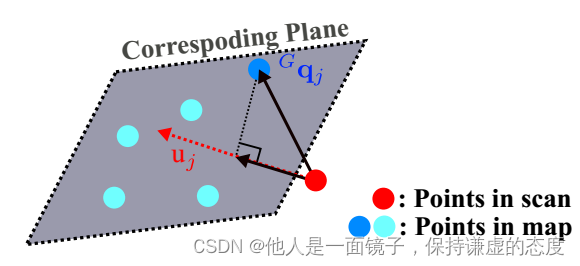
该真实的点,在使用相应的LiDAR姿态GTIk = (GRIk, GpIk)和外部属性ITL= (IRL, IpL)而投影到全球框架后,应该正好位于地图上的一个局部小平面补丁上,即:
式中,Guj是相应平面的法向量,Gqj是平面上的一点,如下图。
需要注意的是,GTIk和ITLk都包含在状态向量xk中。因此,第j个测量值Lpj可以从式(4)归纳为更紧凑的形式,如下。该式定义了状态向量xk的隐式测量模型。
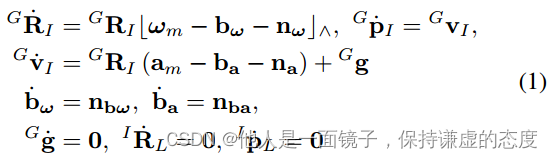

4、迭代卡尔曼滤波器
基于如下的基于流形的状态模型(2)和测量模型(5):
我们采用迭代卡尔曼滤波器直接对流形M执行[55]和[22]中的程序。它由两个关键步骤组成:每次IMU测量的传播和每次LiDAR扫描的迭代更新,这两个步骤都在流形M上自然地估计状态,从而避免了任何重正化。由于IMU测量通常比LiDAR扫描的频率更高(例如,IMU测量的频率为200Hz, LiDAR扫描的频率为10Hz ~ 100Hz),所以在更新之前通常需要执行多个传播步骤(其实就是IMU是预测结果,激光雷达观测修正)。
4.1 传播
假设上一次融合(即第k−1次)LiDAR扫描后的最优状态估计为x¯k−1,协方差矩阵P¯k−1。前向传播在IMU测量数据到达时进行。更具体地说,状态和协方差的前向传播,即设置(2)式中的过程噪声wi为零,有:
其中,Qi是噪声wi的协方差,矩阵Fxi~和Fwi的计算如下(更抽象的推导见[55],更具体的推导见[22]):
4.2 残差计算
假设在当前迭代更新时状态xk的估计值是xκk^,预测状态源于公式(6)中的传播,当k=0 (即第一次迭代前),xκk^=xk^。之后,我们将每个测量到的LiDAR点Lpj投影到全局框架,如下
并在ikd-Tree所表示的地图上搜索其最近的5个点。然后利用找到的最接近的相邻点,用测量模型(见(4)和(5))中使用的法向量Guj和质心Gqj拟合一个局部小平面补丁。此外,用测量方程(5)在xκk^处的一次近似可以得到:
其中,xκk~ = xk □- xκk^ (or xk = xκk^ □+ xκk~);Hκj是hj(xκk^ □+ xκk~,Lnj)关于xκk^在0处取值的雅可比矩阵;vj ∈ N (0,Rj)源于原始测量噪声Lnj; zkj称为残差:
4.3 迭代更新
前面获取的传播状态xk^和协方差Pk^对未知状态xk施加了一个先验高斯分布。具体来说,Pk^表示以下误差状态的协方差:
式中,Jκ为(xκk^ □+ xκk~) □- xk^ 对xkk^=0处的偏微分。
式中,A(.)-1 定义于公式(6),如下。
如下的δGθIk和δIθLk分别为IMU的姿态和转动的误差状态。
对于第一次迭代(以拓展的卡尔曼滤波器为例),有 xκk^ =xk^, Jκ =I。
除了先验分布外,我们也有一个源于测量(8)的状态分布:
结合(10)的先验分布和(12)的测量模型,可得到状态xk的后验分布,其等价表示为xkk~及其最大后验估计:
式中,有||x||2M = xT M−1 x。该最大后验估计问题可由下面的迭代卡尔曼滤波器解决:
需注意,卡尔曼增益K计算需要对状态维数矩阵求逆,而不是在之前的工作中使用的测量维数矩阵。上述过程将重复进行,直到收敛(即||xκ(k+1)^ □- xκk^||<无穷小)。收敛后的最优状态和协方差估计为:
通过状态更新x¯k,第k次扫描中的每个LiDAR点(Lpj)将通过(16)被转换到全局框架:
转换后的LiDAR点{Gp¯j}将被插入到由ikd-Tree表示的映射中。我们的状态估计在算法1中进行了总结。

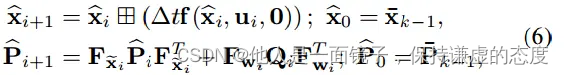
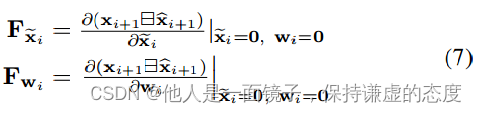
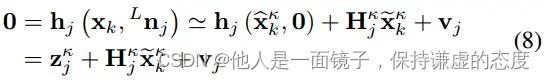

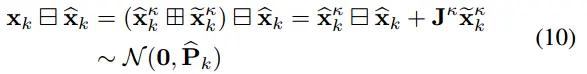

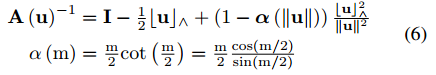
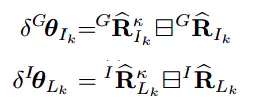
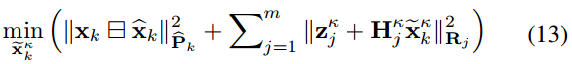
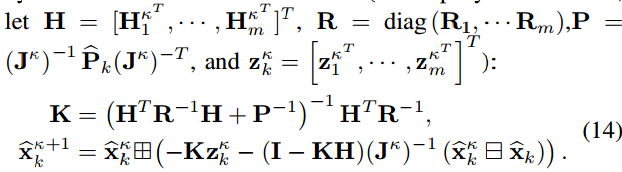

5、建图
在本节中,我们描述了如何增量地维护一个映射(即插入和删除),并通过ikd-Tree对其执行k-nearest搜索。为了从理论上证明ikdTree的时间效率,本文对时间复杂度进行了完整的分析。
5.1 地图管理
地图点被组织成一个ikd-Tree,该树以里程计速率合并新的点云扫描而动态增长。为了防止地图的大小不受约束,ikid - tree中只保留LiDAR当前位置周围长为L的大型局部区域中的地图点。2D 演示图如下所示。
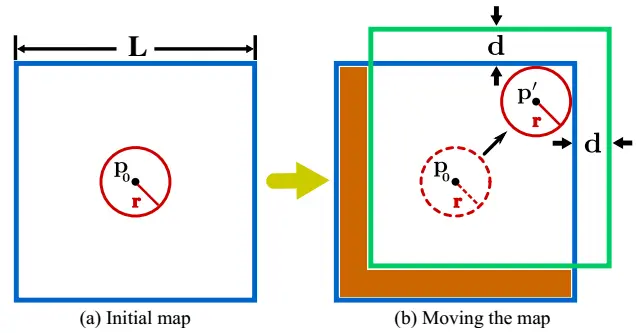
(a)中,蓝色矩形为长度为l的初始映射区域,红色圆形为以初始LiDAR位置p0为中心的初始探测区域。在(b)中,检测区域(虚线红色圆圈)移动到一个新的位置p0(带实红线的圆圈),该位置触碰了地图边界。根据距离d,地图区域被移动到一个新的位置(绿色矩形)。减法区域(橙色区域)中的点从地图(即 ikd-Tree)中移除。
将映射区域初始化为一个长为L的立方体,该立方体以初始LiDAR位置p0为中心。假设LiDAR的探测区域为以(15)得到的LiDAR当前位置为中心的探测球。
![]()
假设探测球的半径r = γ R,其中R为LiDAR视场(FOV)范围,γ为大于1的松弛参数。当LiDAR移动到检测球接触到地图边界的新位置p0时,地图区域会向增加LiDAR检测区域到接触边界的距离的方向移动。地图区域移动的距离设置为常数d = (γ−1)R。通过后中详细介绍的逐框删除操作,新映射区域和旧映射区域之间的减法区域中的所有点将从ikd-Tree中删除。
5.2 树形结构与构造
5.2.1 数据结构
ikd-Tree是一个二叉搜索树,ikd-Tree 中树节点的属性显示在"数据结构"中(Data Structure)。与许多仅在叶节点上存储点"桶"的k-d树的现有实现不同,我们的ikd-Tree将点存储在叶节点和内部节点上,以更好地支持动态点插入和树重新平衡。当使用单个 k-d 树 [41] 时,这种存储模式在 kNN 搜索中也显示出更有效,这就是我们的 ikd-Tree 的情况。由于点对应于 ikd-Tree 上的单个节点,我们将互换使用点和节点。

点信息(例如点坐标、强度)存储在 point 中。 属性 leftchild 和 rightchild 分别是指向其左右子节点的指针。用于分割空间的分割轴记录在 axis 中。根植于当前节点的(子)树的树节点数(包括有效和无效节点)保留在属性 treesize 中。当点从地图中删除时,节点不会立即从树中删除,而只是将布尔变量 deleted 设置为 true(有关详细信息,请参阅第Section V-C2 节)。 如果删除了以当前节点为根的整个(子)树,则将 treedeleted 设置为 true。 从(子)树中删除的点的数目汇总于属性 invalidnum 中。 属性 range 记录了(子)树上点的范围信息,被解释为包含所有点的受限制的轴对齐长方体。 受限制的长方体由其两个对角线顶点表示,每个顶点分别具有最小和最大坐标。
5.2.2 构造
构建 ikd-Tree 类似于在 [40] 中构建静态 k-d 树。ikd-Tree 沿最长维度递归地分割中点处的空间,直到子空间中只有一个点。 Data Structure 中的属性在构建过程中被初始化,包括计算树的大小和(子)树的范围信息。
[40] J. L. Bentley, “Multidimensional binary search trees used for associative searching,” Communications of the ACM, vol. 18, no. 9, pp. 509–517, 1975
5.3 增量更新
ikd-Tree 上的增量更新指的是增量操作,其次是第 V-D 节中详述的动态重新平衡。
followed by dynamic re-balancing detailed in Section. V-D. ?
支持两种类型的增量操作: 逐点操作和按框操作。 逐点操作在 k-d 树中插入、删除或重新插入单个点,而按框操作在给定的轴对齐长方体中插入、删除或重新插入所有点。在这两种情况下,点插入都进一步与树上降采样相集成,从而将地图保持在预定的分辨率。在本文中,我们仅解释 FAST-LIO2 的地图管理所需的逐点插入和按框删除。 读者可以参考我们在 Github 存储库中开源的 ikd-Tree 完整实现以及其中包含的技术文档以获取更多详细信息。
on-tree downsampling - 降/下采样:
https://blog.csdn.net/u012965373/article/details/80089315
point-wise insertion and box-wise delete ?
5.3.1 点插入与降采样
考虑到机器人应用,我们的 ikd-Tree 支持同时(simultaneous)点插入和地图缩减采样。 该算法在Algorithm 2 中有详细说明。对于来自状态估计模块(参见算法1)的{Gpj¯}中的给定点p和下采样分辨率l,该算法将空间均匀地划分成长度为l的立方体,然后找到包含点p的立方体CD(第2行)。该算法仅保留最靠近CD中心Pcenter的点(第3行),这是通过首先在k-d树上搜索CD中包含的所有点,并将它们与新点p一起存储在点数组V中(第4-5行)来实现的。最近点Pnearest是通过比较V中每个点到中心pcenter(第6行)的距离获得的。然后删除CD中现有的点(第7行),之后将最近的点pnearest插入到k-d树中(第8行)。箱式搜索的实现类似于SectionV-C2中介绍的箱式删除。

ikd-Tree上的点插入(线11-24)是递归地实现的。 该算法从根节点上搜索,直到发现空节点再追加一个新节点(第12-14行), 新叶节点的属性按照表一进行初始化。在每个非空节点上,将新点与存储在树节点上的点沿划分轴进行比较,以进一步递归(第15-20行)。

如SectionV-C3中所介绍的,那些被访问节点的属性(例如,treesize、range)由最新信息(第21行)更新。检查并维护用新点更新的子树的平衡标准,以保持ikd-Tree的平衡属性(第22行),如SectionV-D所述。
5.3.2 惰性标签按框删除
在删除操作中,我们使用惰性删除策略。也就是说,这些点不会立即从树中删除,而只是通过将属性deleted(参见数据结构,第6行)设置为true来标记为“已删除”。如果以节点T为根的子树上的所有节点都已被删除,则T的属性treedeleted将被设置为true。因此,属性deleted和treedeleted被称为懒惰标签。标有“已删除”的点将在重建过程中(参见SectionV-D)从树中移除。
箱式删除是利用属性范围中的范围信息和树节点上的惰性标签来实现。正如在SectionV-B中提到的,属性范围由外切的长方体CT表示。
伪代码如 Algorithm 3 所示。给定要从以T为根的(子)树中删除的点CO的长方体,该算法递归地向下搜索树,并将外切长方体CT与给定的长方体CO进行比较。如果CT和CO之间没有交集,则递归直接返回,而不更新树(第2行);如果外切长方体CT完全包含在给定的长方体CO中,则箱式删除将属性deleted和treedeleted设置为真(第5行),当(子)树上的所有点都被删除时,属性invalidnum等于treesize(第6行);对于CT相交但不包含在CO中的情况,如果当前点p包含在CO中,则首先将其从树中删除(第9行),之后该算法递归地查看子节点(第10-11行),而当前节点T的属性更新和余额维护在箱式删除操作之后被应用(第12-13行)。

5.3.3 属性更新
在每次增量操作之后,需根据最新的信息并借助函数AttributeUpdate更新被访问节点的属性。该函数通过汇总两个子节点上的相应属性和自身的点信息来计算属性treesize和invalidnum。通过合并两个子节点的范围信息和其上存储的点信息来确定属性range;如果两个子节点的treedeleted都为true并且节点本身被删除,则treedeleted被设置为true。
5.4 重新平衡
ikd-Tree在每次增量操作后会主动监控平衡属性,并通过仅重建相关的子树来动态地重新平衡自身。
5.4.1 平衡标准
平衡准则由两个子准则组成:α-平衡准则和α-删除准则。假设ikd树的子树以T为根,当且仅当它满足以下条件时子树是α-平衡的:
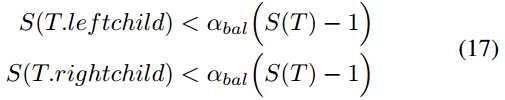
式中,αbal ∈(0.5, 1)和S(T)是节点T的属性treesize。
以T为根的子树的α-删除准则是:
![]()
式中,αdel ∈(0, 1 ), I(T)表示子树上无效节点的数量(即,节点T的属性invalidnum)。
如果ikd-Tree的子树满足这两个标准,则该子树是平衡的。如果所有子树都是平衡的,则整个树是平衡的。违反任何一个标准都将触发重新构建过程来重新平衡该子树:α平衡标准保持着树的最大高度。很容易证明α-平衡树的最大高度是log1/αbal(n)=n,其中n是树的大小;α-删除准则确保子树上的无效节点(即,标记为“已删除”)被移除以减小树的大小。降低k-d树的高度和大小允许将来高效的增量操作和查询。
5.4.2 重建&并行重建
假设在子树T上触发重建(见Fig 4),子树首先被展平成点存储数组V。在展平过程中,标记为“已删除”的树节点将被丢弃。然后同SectionV-B,用V中的所有点构建一个新的完全平衡的k-d树。在ikd-Tree上重新构建大型子树时,可能会出现相当大的延迟,并破坏FAST-LIO2的实时性能。为了保持较高的实时性,我们设计了一种双线程重建方法。我们提出的方法不是简单地在第二个线程中重建,而是通过操作记录器避免了两个线程中的信息丢失和内存冲突,从而始终保持knearest邻居搜索的完全准确性。
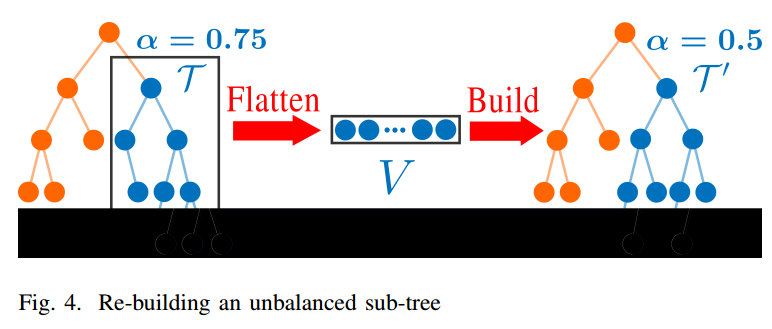
重建的方法参见 Algorithm 4。当违反平衡标准时,当子树的树大小小于预定值Nmax时,在主线程中重建子树;否则,在第二线程中重建子树。第二个线程上的重建算法如函数ParRebuild所示。将第二个线程中要重建的子树表示为t,将其根节点表示为T。第二个线程将锁定所有增量更新(即点插入和删除),但不锁定该子树上的查询(第12行)。然后,第二线程将子树t中包含的所有有效点复制到点数组V中(即,展平),同时保持原始子树不变,以用于重建过程中可能的查询(第13行)。展平后,原始子树被解锁,以便主线程进一步执行增量更新的请求(第14行)。这些请求将同时记录在一个名为operation logger的队列中。一旦第二个线程完成从点数组V构建新的平衡k-d树t‘(第15行),记录的更新请求将由函数IncrementalUpdates在t‘上再次执行(第16-18行)。

其中,并行重建开关被设置为false,因为它已经在第二个线程中。在所有未决请求被处理之后,原始子树t上的点信息与新子树t‘上的点信息完全相同,只是新子树在树结构中比原始子树更平衡。该算法从增量更新和查询中锁定节点T,并用新的节点T’替换它(第20-22行)。最后,该算法释放原始子树的内存(第23行)。
这种设计确保了在第二线程中的重建过程中,主线程中的映射过程仍然以里程计速率进行而没有任何中断,尽管由于暂时不平衡的k-d树结构而导致效率较低。我们应该注意,ockUpdates不会阻塞查询,查询可以在主线程中并行执行。相比之下,LockAll阻塞所有访问,包括查询,但它完成得非常快(即只有一条指令),允许在主线程中及时查询。函数LockUpdates和LockAll是通过互斥(mutex)实现的。
5.5 最近邻搜索
尽管与那些众所周知的k-d树库[43]-[45]中的现有实现类似,但最近搜索算法在ikd树上被彻底优化。使用[41]中详述的“边界重叠球”测试,充分利用树节点上的范围信息来加速我们的最近邻搜索。维护优先级队列q以存储迄今为止遇到的k个最近邻点以及它们到目标点的距离。当从树的根节点向下递归搜索树时,首先计算从目标点到树节点的立方体CT的最小距离dmin。如果最小距离dmin不小于q中的最大距离,则不需要处理该节点及其后代节点。此外,在FAST-LIO2(和许多其他激光雷达里程计)中,只有当邻近点在目标点周围的给定阈值内时,才会被视为内点,并因此用于状态估计,这自然为knearest邻近点的范围搜索提供了最大搜索距离[43]。在任一情况下,范围搜索通过将dmin与最大距离进行比较来删减算法,从而减少回溯量以提高时间性能。需要注意的是,我们的ikd-Tree支持并行计算架构的多线程k近邻搜索。
5.6 时间复杂度分析
ikd-Tree的时间复杂度分解为增量操作(插入和删除)、重建和k-最近邻搜索的时间。请注意,所有分析都是在低维(例如FAST-LIO2中的三维)假设下提供的。
5.6.1 增量操作
因为使用树上下采样的插入依赖于逐盒删除和逐盒搜索,所以首先讨论逐盒操作。假设n表示ikd树的树大小,ikd树上的逐盒操作的时间复杂度是:
目前感觉这部分内容不是重点, 故省略一些相关公式。
Lemma 1. Suppose points on the ...
具有树上下采样的插入的时间复杂度为:
Lemma 2. The time complexity of ...
ikd树的最大高度可以很容易地从等式(17)证明为log1/αbal(n)。而静态k-d树的时间复杂度为log2 n。因引理直接从[40]中获得,其中k-d树上的点插入的时间复杂度被证明为O(log n)。总结下采样和插入的时间复杂度得出结论,使用树上下采样的插入的时间复杂度是O(log n)。
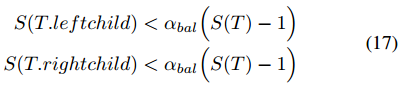
5.6.2 重建
重建的时间复杂度分为两类:单线程重建和并行双线程重建。在前一种情况下,重建由主线程递归执行。当维数k较低时,每一级花费排序的时间(即O(n))并且log n级的总时间是O(n log n) [40]。对于并行重建,在主线程中消耗的时间仅仅是展平(其暂停主线程进一步的增量更新,算法4,第12-14行)和树更新(其花费恒定时间O(1),算法4,第20-22行),而不是构建(其由第二线程并行执行,算法4,第15-18行),导致时间复杂度为O(n)(从主线程来看)。总之,对于双线并行重建,重建ikd树的时间复杂度为O(n ),对于单线程重建,时间复杂度为O(n log n)。
5.6.3 最近邻搜索
因为ikd树的最大高度保持不大于log1/αbal(n),其中n是树的大小,从根节点向下搜索到叶节点的时间复杂度是O(log n)。在搜索树上k-最近邻的过程中,回溯的次数与一个常数l¯成正比,而这个常数与树的大小无关[41]。因此,在ikd树上获得k-最近邻的期望时间复杂度是O(log n)。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









