







https://blog.csdn.net/m0_37380369/article/details/80256750 这里有一部分设置可供参考
https://blog.ch-wind.com/ue4-profiling-preview/ 参考了这篇文章
下面的优化内容有些乱 没有进行过整理 基本上都是一边学习一边添加的
物理方面查看
stat physics
动画
stat anim
粒子
stat particle
stat emitters
如果你想知道具体某个命令的作用可以通过类似r.vsync ? 按两次~ 进行说明查看

首先如果使用vr头显进行帧率显示的话 它通常会在45~90进行跳动
官方说明链接https://docs.unrealengine.com/en-US/Platforms/VR/DevelopVR/Profiling/Considerations/index.html
使用PC显示模拟vr的帧率的话 需要以Standalone模式启动 在启动命令行中 添加-emulatestereo 通过控制台或者蓝图设置
r.setres=2160x1200 r.vsync 0 r.screenpercentage 137 如果能跑到120帧左右的话是可以超过90帧的


显示帧率一种是内置的命令stat fps还有如果是oculus平台的话 可以使用oculus工具
位置在C:\Program Files\Oculus\Support\oculus-diagnostics
调试优化尽量泡在standlone模式同时在project setting中关闭framerate Editor模式的话还是不准确的
首先要先锁定是cpu的问题还是gpu的问题 如果是cpu的问题的话
通过命令stat unit 可以查看各个指标
其中Game Thread是游戏逻辑耗时 Draw 是cpu准备发送drawcall 发送的gpu GPU 是gpu 渲染的时间
Game和GPU哪一个接近frame 哪一个就是瓶颈
另一种判断是可以通过输入命令 r.ScreenPercentage x 通过修改x的值 修改输出分辨率 查看帧率变化 如果变化明显就说明问题出在gpu优化上
一般cpu出问题就是代码比较冗余
通过命令 stat StartFile statStopFile 获得运行数据 通过Session Fronted打开 确保CPU 是否占据重要影响 工具的方法具体查
这里主要是下面的位置是cpu 是否影响的关键

下面介绍的都是GPU方面的优化
首先分析GPU
简单快速的方法就是使用Setting中 Scalability 通过调整级别 大致锁定最耗gpu的项


其次 项目的TargetSetting需要设置为Mobile

gpu的优化除了上面的连接 还有一些主要的设置 一下的命令可以设置在Device Profile中


同时场景中添加PostProcessVolume 设置InfiniteExtent true
场景中PostVolume的AmbientOcclusion LensFlare ScreenSpaceReflections 的intensity需要设置为0
工程的ProjectSetting中 ForwardShading 启用
Anti_AliasingMethod 抗锯齿设置为MSAA
材质如果出现闪烁的话 就选中
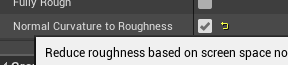
关闭垂直同步 r.VSync 0/1
- 查看当前抗锯齿方法的命令行是 r.DefaultFeature.AntiAliasing,结果有4个值,0,1,2,3。 0=关闭抗锯齿,1=FXAA,2=TAA(Default),3=MSAA(Forward shading Only)
GPU Profiling 快捷键 Ctrl + Shift +,(逗号)
Base Pass很高的话 查看DrawCall是否高 r.Earless 1 会增加Drawcall 降低BasePass
draw call的优化可以通过使用ue4 的static mesh instance技术或者Merge Actor 不过Merge Actor只是使用上方便一些 效率上不如instance
这种技术只适用于使用同一静态网格的多个物体,绘制的时候默认是按照绘制一次的draw call 不过缺点就是所有的会被当成同一个个体 用于剔除
使用方法就是在蓝图中添加
instancedstaticmesh 设置每个instance的坐标位置
r.SceneRendering 查找drawcall (ue4限制在1000)
测试occlu遮挡是否正常工作 r.VisualizeOccludedPrimitives 1
通过Pause命令暂停游戏 通过ToggleDebugCamera 进行游览 看看是否有本应被遮挡的物体显示出来 一般都是游戏动画没有做root motion原因导致的
Stat particles 查看粒子
DrawCall 解决
ShowFlag.staticmeshes /HUD/ particles/ skeletalmeshes
其他feature
ShowFlag.Translucency/ ambientocclusion/dynamicshadows/decals
Sg.ViewDistanceQuality 1/2/3 视觉有近至远 将不满足条件的物体剔除 需要在mesh Lod中设置distance
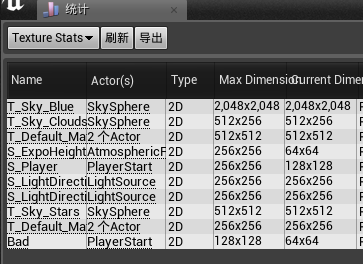
图片内存的优化可以通过Windows/Statisstics
如何有类似这种实际使用小于原始图片size的情况 可以进入图片Editor 设置大小


Vertex-bound
通常受到影响的就是场景中三角形的数量,如果印象没有错的话,当前UE4内部所有的面应该都是三角形的。会在这里产生瓶颈的还有阴影投射与曲面细分,关于曲面细分,官方有建议是尽量不要使用,在建模阶段直接进行细分是更加具有效率的。
UV Seam和Hard Edges会额外的增加计算的顶点计算的负担,要尽量避免减少使用的频度。
同时Morph Target与WolrdPostionOffset也会产生更多的顶点计算,Skinned Mesh也是如此,不过这些方面,除了WorldPostionOffset可以尽量避免使用之外,只能从游戏逻辑本身的设计上入手了呢。
如果有使用LandScape的话,尽量减少LandScape的面数可以很好的提高性能。
为了避免过量的顶点计算负担,对于远景物体尽量使用BillBoard或者Imposter meshes、Skyboxe texture来代替3D物体。
Memory-bound
可以通过stat RHI 进行gpu显存查询
如果有大量的材质使用了不同的贴图,导致Texture Sample的数量爆炸的话,就会自然的变成瓶颈。
UE4有使用Texture Streaming,如果存储空间爆炸了的话,就会出现贴图模糊的情况,这时候可以使用Stat Streaming指令进行分析。
![]()
对于使用相同的材质的情况,可以通过材质中的设定让他们共享Texture。同时在材质中启用GPU本身支持的压缩可以有效的减少存储空间的占用,尽量的使用Texture Packing也是非常的重要的。载入的时候尽量使用Mip级别较低的图片,可以有效的减少存储占用。在材质的贴图使用中,尽量的进行优化的配置也非常的重要。
![]()
对于不需要太精细的贴图可以限制其最大尺寸
![clip_image001[4]](https://blog.ch-wind.com/wp-content/uploads/2017/07/clip_image0014.png)
另外,光照贴图等也是被算作贴图占用存储空间的,因此也有在这里产生瓶颈的可能性。因此尽量的调低光照贴图的分辨率可以很好的提高性能。
使用Alt+0/Light Map Density可以对场景中的光照贴图密度进行分析。
在窗口>统计总也能进一步的对当前的存储使用状况进行分析 还可以通过Stat engine进行查看
前向渲染与延迟渲染
UE4面向VR可以区分前向渲染与延迟渲染,两方各有优劣,在优化上也会有所不同。引擎采用的前向渲染方式是Cluster Forward Shading(Forward+),详细的技术细节并没有关注过,不过通常前向渲染的光照计算成本会高些,尤其是光照数量较多时会产生明显的性能下降。
使用缓存区可视化功能,可以对延迟渲染使用的缓存进行查看。
按通道优化
优化的过程,通常是在玩家通常的地点放置观察摄像,然后通过这个固定点使用GPU Visualizer进行优化。
在使用GPU Visualizer时,会看到各个通道的性能消耗比例,这样就可以针对不同的通道进行优化了。
在打包模式下按下GPU Visualizer后,不会出现界面,但是相关数据会被记录到Log中。
在GPU Visualizer中对帧时间消耗进行排序可以帮助快速找到当前消耗的瓶颈,不过有的pass的消耗可能是不得已的,这里大概就是需要经验的地方了。pass根据工作方式大体上分别工作于屏幕空间和运算空间,像是PostProcess这样的后期处理以及延迟渲染的光照都是工作在屏幕空间的。而像是Z-Buffer的生成这一类的操作则是通过运算空间进行的。一般工作在屏幕空间的通道受到渲染分辨率的影响就会比较大,例如SSAO、AA等。而在运算空间的Pass就会受到Mesh的数量、面数、shader的复杂度的影响。
包括视锥剔除(frustum culling)、预计算遮挡剔除(precomputed visibility culling)和动态遮挡剔除(dynamic occlusion culling)等,用以判断各剔除的效率
光照
LightCompositionTasks_PreLighting
这个通道被SSAO以及非D-Buffer类型的Decals使用。
这里的性能消耗在屏幕分辨率上,通过在PostProcess中降低AO的半径和消退距离可以减少其产生的运算负担。
同时,非D-Buffer类的Decals也会对其产生影响。
Composition After Lighting
只影响Subsurface Profile的Shading Model的SSS效果的通道。
由于工作于屏幕空间,减少其在屏幕中的占比就可以有效的减少消耗。比如使用LOD之类的。
使用Subsurface的Shading Model或者Matcap之类的来进行替代也可以降低这里的消耗。
Compute Light Grid
用于计算光照是否需要渲染的相关性的pass,减少动态光照的数量就可以减低消耗。
Lights
![clip_image001[6]](https://blog.ch-wind.com/wp-content/uploads/2017/07/clip_image0016.png)
如果是使用ForwardRendering 那么light下面相关的计算会放在basepass中
延迟渲染的光照是基于DBuffer在屏幕空间呢进行演算的,因此受屏幕分辨率的影响也比较大。
无论是静态光照还是动态光照,都会受到光照本身的数量以及范围的影响。
而动态光照的效率额外的受到光照影响到的面数的影响。
光照的优化应该尽量的减少光照范围的重叠,避免大范围的动态光照,关闭没有太大必要性物体的动态阴影投射。光照的重叠等的查看可以通过调整视图

来进行有效的排查。
光照类型的性能消耗是点光源>直线光源>聚光灯,在使用光照时,如果能用IES或者光照函数进行替代的话,不要使用很多个光源组合成类似的效果。
同时光照函数通常的性能消耗大于IES,其消耗受到光照材质本身的复杂度的影响比较大。
在对光照范围进行优化时,可以通过关闭Use Inverse Squared Falloff,并自己设置Light Falloff Exponent来达到减小光照范围达到类似光照效果。
Filter Translucent Volume
这是半透明物体的光照计算时会用到的pass
![clip_image001[8]](https://blog.ch-wind.com/wp-content/uploads/2017/07/clip_image0018.png)
带光照的半透明物体的光照大多数来源于一系列面向视锥体的cascade处理过的体积贴图。 这样在体积内的任意点,光照均为单次,但缺点就是体积贴图的分辨率比较低,而且从观察者角度来说,只涵盖了有限的深度范围。
详细的说明可以参考官方文档:[带光照的半透明物体]。
这里产生了瓶颈的话要检查光照的数目、范围和影响到的物体的数量。
ShadowDepths
这个生成通过光源进行阴影投射的深度数据的pass。
作用与这里的消耗主要受到开启了投影的光的数目、动态光照影响的面数、以及阴影的质量的影响。
阴影的质量可以通过Sg.shadow quality进行全局的调节。
Shadow Projection
最终的的阴影投射,使用ShadowDepth中计算的Depthmap, 工作于屏幕空间,所以受分辨率影响,同时也会受到投影的光照数量和范围的影响。
基础通道
PrePass DOM_…
EarlyZPass,对非透明物体进行的早期的深度计算。
![]()
用于遮蔽计算,Decal, 如果不使用Dbuffer Decals的话可以关掉。虽然视频中是这样建议的,但是早期的深度计算可以在BasePass之前进行遮蔽计算,能让basepass以及之后所有的通道的计算减少很多。而且即便在这里不进行深度计算,会影响这里的运算量的变量依然会作用与后面的深度计算阶段,因此关闭EarlyZPass还是需要多做考虑的。另外要使用DBuffer Decals的话必须使用Opaque and masked的zpass计算,否则应该会出现奇怪的现象。
![clip_image001[12]](https://blog.ch-wind.com/wp-content/uploads/2017/07/clip_image00112.png)
性能上受到非透明物体的面数的影响,同时根据上面的选项不同也受到Masked的材质的影响。
HZB
Hierarchical Z-Buffer,用于计算HZB遮蔽,同时也会被屏幕空间内的射线演算使用,例如屏幕空间反射计算、AO等。同时被用于Mip的设置。
受屏幕空间的大小影响。据官方描述,HZB拥有较高的固定性能消耗,每个物体所造成的消耗较小。可以通过r.HZBOcclusion来调整运算的类型。
Base Pass
对非透明的物体进行演算并填充到GBuffer,使用缓冲区可视化模式可以在视图中看到效果。几乎所有的延迟渲染都受到其影响,因此才叫基础通道。
其计算结果包括base color, metallic, specular, roughness, normal, sss profile,并且Decals、Fog以及Velocity的计算也在此处。
其开销受到屏幕空间尺寸、物体数量、面数、Decals的数量、Shader的复杂度,生成的过程中包含光照贴图的推送,因此也会受到光照贴图的大小的影响。
可以通过Stat rhi指令检查各种贴图和triangle的消耗。
另外,前向渲染的光照也在这里进行,此时光照的数量也会影响到这里的消耗。
Translucency
半透明的材质以及光照演算,通过Stat gpu中的Translucency and Translucent Lighting可以进一步查看。
消耗受到屏幕空间大小以及屏幕内的半透明物体的数量影响,半透明物体的光照计算要尽量减少过度绘制。以及避免过多的需要进行半透明光照计算的光的数量。
其他
Particle Simulation/Injection
粒子模拟,这里只展示GPU粒子的消耗,性能主要受粒子数量以及是否开启了基于深度的粒子碰撞影响。
粒子的优化主要通过LOD以及设计上的优化进行。
Post process
UE4的后期处理功能比较多,AA、DOF、自动曝光以及很多其他的功能都在其中。
每种PP特效都会产生额外的性能消耗,如果使用了PP材质的话,其复杂度也会影响性能。
Relection Envirionment
反射捕捉控件的计算缓存
可以将显示模式调整为Reflections来查看各个控件对缓存的影响
通常的建议是,放一个大范围的低精度反射捕捉,然后在需要的地方尽量不重叠的放置高精度的捕捉控件。
影响性能的主要就是捕捉控件的数量及范围,也受屏幕空间的大小影响。
Render Velocities
速度主要用于TAA以及Motion Blur,受到移动物体的数量以及其面数的影响。
主要的优化策略是使用LOD。
Screen Space Reflections
屏幕空间反射通过以下连个指令来进行调节:
r.ssr.maxroughness 0.0-1.0
r.ssr.quality 0..4
其中Maximum roughness决定着计算的范围的大小。
补充:
stat rhi中的 draw all 与Triangle数目包含了后期与阴影等相关的数据 并不是只有几何图形
实际数据三角形可通过Statistics查看 drawcall可通过stat scenerendering 查看
使用intel 的gpa工具进行调试
https://software.intel.com/zh-cn/articles/unreal-engine-4-optimization-tutorial-part-1
ps:
材质中可以通过 Feature Level Switch 节点控制效果的切换
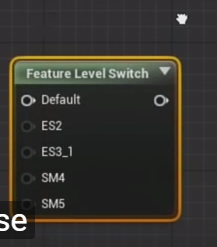
材质根据lod blend
在材质中check Dithered LOD Transition
PS:
粒子的优化
粒子尽量不要使用light模块 vr游戏的话 尽量不要使用gpu 粒子
材质的话也要使用unlit材质 如果一定要default lit的话也要设置light mode 按照顶点去进行计算
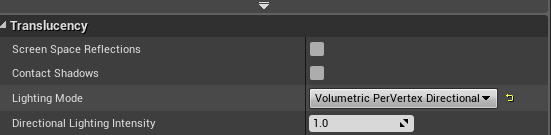
PS:
光源优化
补光类型的光源尽量不参与到动态物体的光照计算
Ps:剔除优化
剔除消耗查看
stat initviews
其中 Occlusion Cull代表遮挡剔除消耗的时间
frustum cull 视椎剔除剔除时间
DecompressionOcclusion 预计算可见性时间
下面的统计信息是具体的个数

剔除效果查看
FreezeRendering 然后移动镜头 应该被剔除的actor 不会显示
查看被剔除的物体 会以绿色框显示
r.VisualizeOccludedPrimitives 1
预计算可视剔除
http://timhobsonue4.snappages.com/culling-precomputed-visibility-volumes
是使用预计算的方式 减少默认的遮挡剔除
使用方法具体看官网 注意单元格的大小
这里说明的是如何确认是否起到效果就是通过观察stat InitViews中的 Occlusion Cull消耗时间 如果摄像机位于cell中的话 那么该项的消耗时间会很小
PS
查看tick使用命令 dumpticks 会在log文件中生成tick使用情况















 3741
3741











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









