







 MobileViT是作者在2021年提出的一种新型网络结构,它将Transformer融入MobileNetV2,旨在创建适用于移动设备的轻量级视觉模型。与传统的ViT不同,MobileViT不需要大量数据增强,且在ImageNet-1k上表现出优于MobileNetV3和DeiT的性能。MobileViT设计兼顾轻量化、通用性和低延迟,解决了Transformer缺乏局部特征的问题。通过多尺度采样训练策略,模型能获得更好的多尺度表达能力。实验结果显示,MobileViT在分类、检测和分割任务上均有出色表现,并且在速度上虽慢于CNN,但提供了更高的准确率。
MobileViT是作者在2021年提出的一种新型网络结构,它将Transformer融入MobileNetV2,旨在创建适用于移动设备的轻量级视觉模型。与传统的ViT不同,MobileViT不需要大量数据增强,且在ImageNet-1k上表现出优于MobileNetV3和DeiT的性能。MobileViT设计兼顾轻量化、通用性和低延迟,解决了Transformer缺乏局部特征的问题。通过多尺度采样训练策略,模型能获得更好的多尺度表达能力。实验结果显示,MobileViT在分类、检测和分割任务上均有出色表现,并且在速度上虽慢于CNN,但提供了更高的准确率。
论文: MOBILEVIT: LIGHT-WEIGHT, GENERAL-PURPOSE, AND MOBILE-FRIENDLY VISION TRANSFORMER
Github:https://github.com/chinhsuanwu/mobilevit-pytorch
2021,苹果公司

传统的视觉 transformers(ViTs),主要是在transformer中嵌入cnn,而本文基于在cnn中嵌入transformers,即在mobilenetv2中嵌入transformer,提出了轻量化的网络结构MOBILEVIT。最终在 ImageNet-1k 上达到78.4%的top-1准确性,比 MobileNetv3高出 3.2%,比 DeIT高出6.2%。在 MS-COCO检测任务上, MobileViT比MobileNetv3高出5.7%。
is it possible to combine the strengths of CNNs and ViTs to build a light-weight and low latency network for mobile vision tasks?
传统的ViTs需要大量的训练数据,大量的数据增强(data augmentation)以及正则化(L2 regularization),在分割类型任务需要比较昂贵的解码模块。而本文提出的MobileViT只需要正常简单的数据增强即可,不需要 CutMix,MixUp,Mosaic,DeIT-style等数据增强方式。
MobileViT主要的设计思想包括
- 轻量化light-weight
- 通用general-purpose
- 低延迟low latency
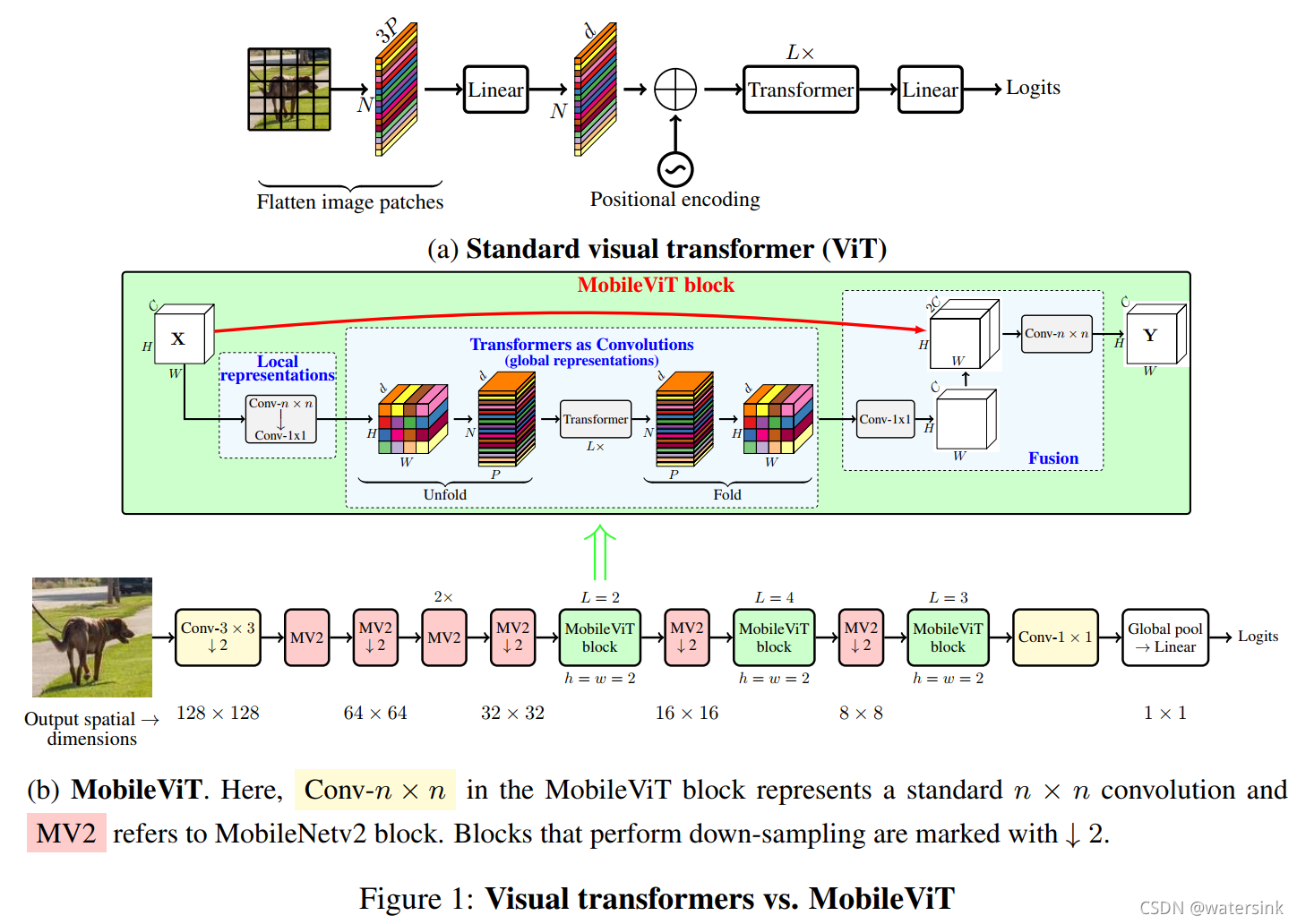
a表示传统的ViT设计结构,b表示本文提出的MobileViT,主要改进在于将MobileNetv2中的残差block替换为MobileViT block。
传统的cnn具有更好的局部特征能力,transformer具有更好的全局特征能力,将cnn和transformer进行结合,可以获得全局能力+局部能力,可以更好的解决transformer缺乏空域归纳偏置(spatial inductive bias)的问题。

如图灰色表示每个像素,黑色表示每个patch。MobileViT block,可以实现通过红色像素加入到蓝色像素中,得到全局的特征,而每一个蓝色的像素已经基于cnn编码了其8邻域的像素。
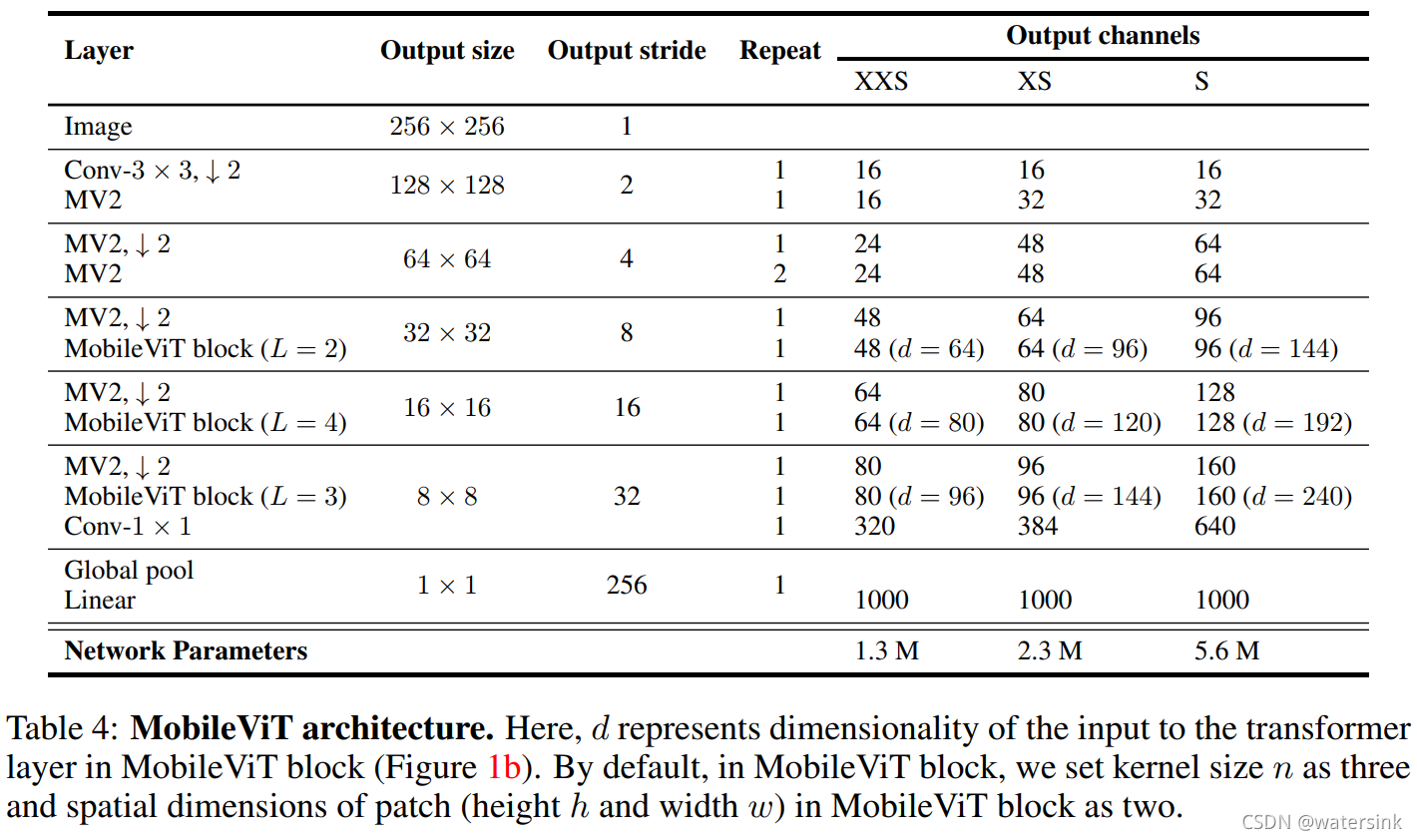
MobileViT包含3个基本模型,(S: small, XS: extra small, XXS: extraextra small)
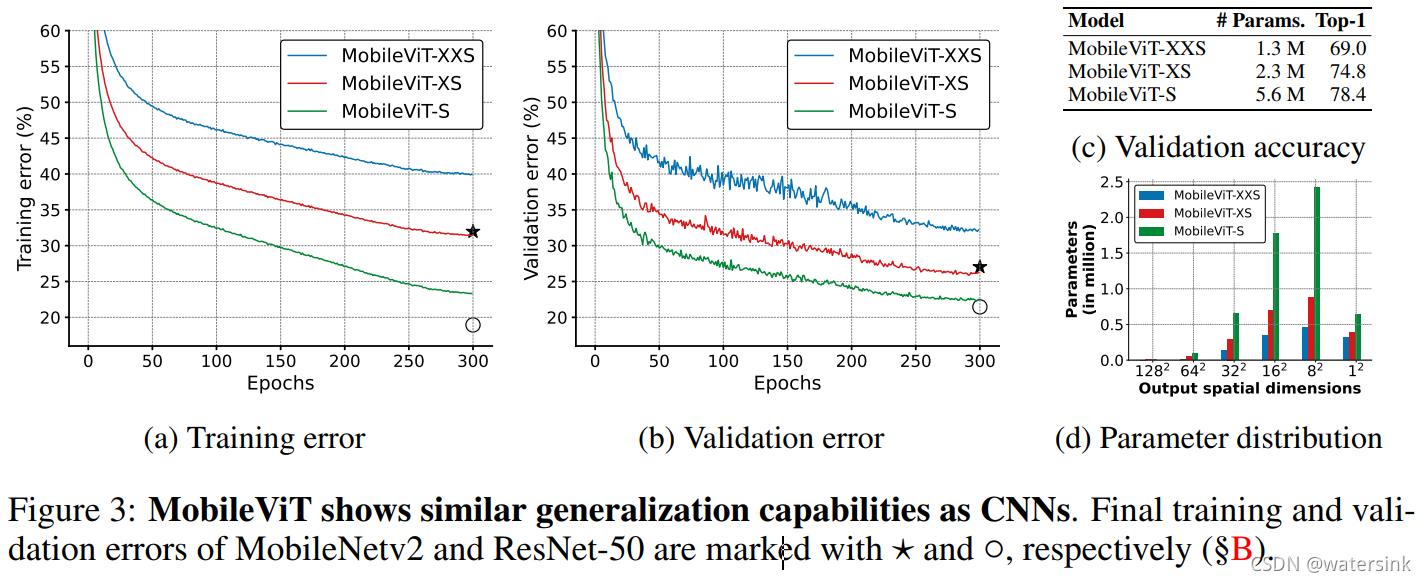
MobileViT的优点包括
- 更好的表现,精度更高,速度慢于cnn,Better performance
- 更好的泛化能力, Generalization capability
- 训练更加鲁棒,Robust
多尺度采样训练策略:
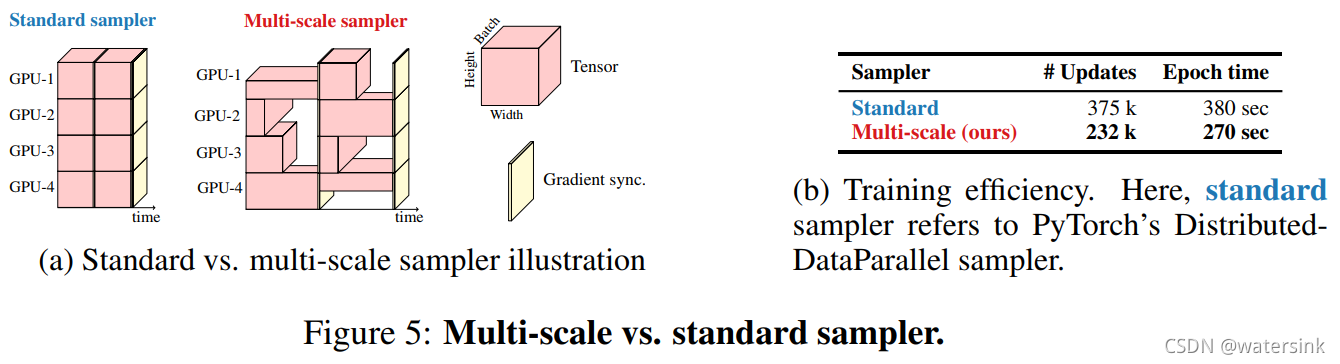
这里采用pytorch的DistributedDataParallel进行多尺度训练的加速,不仅会有训练速度的提升,同时还会有0.5%精度的提升,同时促使网络学习更好的多尺度表达能力。
实验结果:
分类结果, 
检测结果,
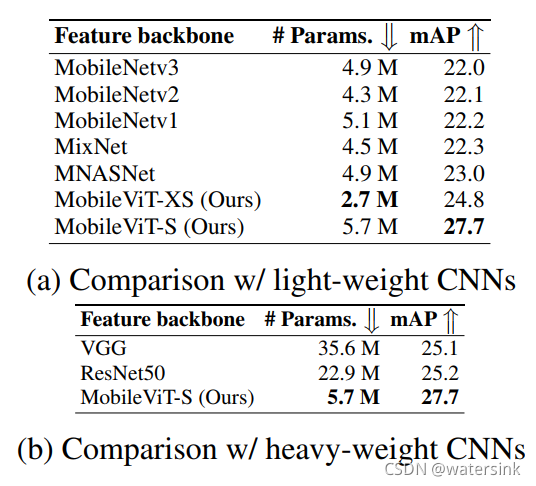
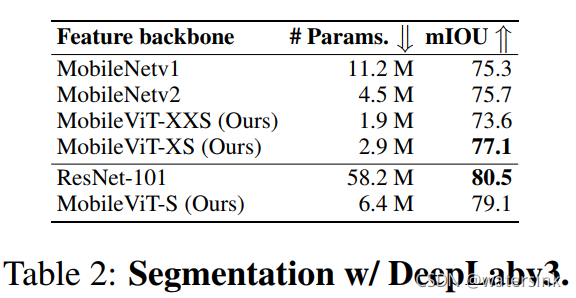
分割结果,
和cnn推理速度对比,


















 3382
3382

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









