







 TripletLoss是一种用于深度学习的损失函数,旨在优化模型,使得同类样本间距离最小,不同类样本间距离最大。它通过Anchor、Positive和Negative样本间的距离关系来避免平凡解。目标函数要求Positive与Anchor的距离小于Negative与Anchor的距离至少一个预设的margin值。合适的margin值对于避免过早收敛和区分相似图像至关重要。此外,TripletLoss的梯度行为对于网络训练也起到关键作用。
TripletLoss是一种用于深度学习的损失函数,旨在优化模型,使得同类样本间距离最小,不同类样本间距离最大。它通过Anchor、Positive和Negative样本间的距离关系来避免平凡解。目标函数要求Positive与Anchor的距离小于Negative与Anchor的距离至少一个预设的margin值。合适的margin值对于避免过早收敛和区分相似图像至关重要。此外,TripletLoss的梯度行为对于网络训练也起到关键作用。
1 Triplet loss
Triplet Loss,即三元组损失,其中的三元是Anchor、Negative、Positive。

通过Triplet Loss的学习后使得Positive元和Anchor元之间的距离最小,而和Negative之间距离最大。( 其中Anchor为训练数据集中随机选取的一个样本,Positive为和Anchor属于同一类的样本,而Negative则为和Anchor不同类的样本。)
换句话说,通过学习后,使得同类样本的positive样本更靠近Anchor,而不同类的样本Negative则远离Anchor。
1.2 目标函数

1.2.1 函数符号解释
| ||。。。|| | 欧氏距离 | ||||
 | Positive元和Anchor之间的欧式距离度量 | ||||
 | Negative和Anchor之间的欧式距离度量 | ||||
| α | Positive元和Anchor之间的欧式距离 和 Negative和Anchor之间的欧式距离 之间的最小差距 | ||||
| 式子最后的“+” | “[。。。]”内的值大于零的时候,就取“[。。。]”内的值 “[。。。]”内的值小于零的时候,就取0 ——>
|
1.3 margin取值
triplet loss 目的就是使 loss 在训练迭代中下降的越小越好,也就是要使得 Anchor 与 Positive 越接近越好,Anchor 与 Negative 越远越好。
当 margin 值越小时,loss 也就较容易的趋近于 0,于是AP距离不需要拉的太近,AN距离不需要拉的太远,就能使得 loss 很快的趋近于 0。——>这样训练得到的结果,不能够很好的区分和Anchor相似&和Anchor不同的图像。
当margin越大时,就需要使得网络拉近 AP距离,拉远 AN距离。如果 margin 值设置的太大,很可能最后 loss 保持一个较大的值,难以趋近于 0 。
因此,设置一个合理的 margin 值很关键,这是衡量相似度的重要指标。
换言之,margin 值设置的越小,loss 很容易趋近于 0 ,但很难区分相似的图像。margin 值设置的越大,loss 值较难趋近于 0,甚至导致网络不收敛,但可以较有把握的区分较为相似的图像。
1.3.1 为什么要加margin
我们希望 A和P的距离越近越好,A和N的距离越远越好,于是如果没有margin的话,我们希望:
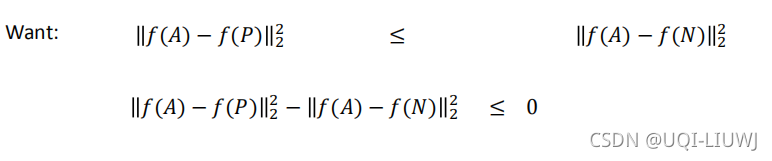
但是这会导致一个问题,就是平凡解:
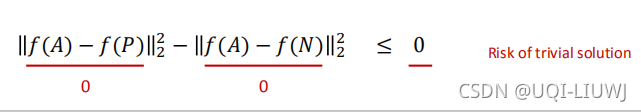
于是我们加了margin 来避免平凡解:
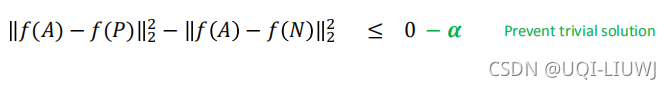
也即:
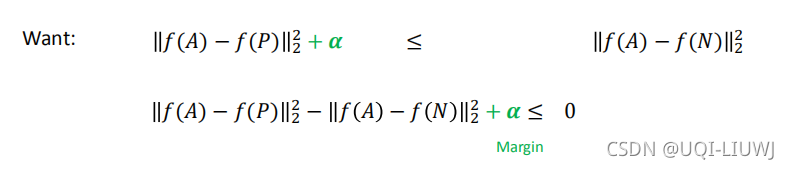
1.4 Triplet 梯度
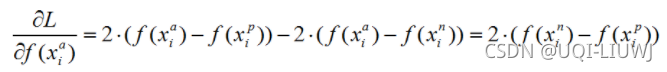
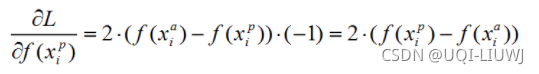
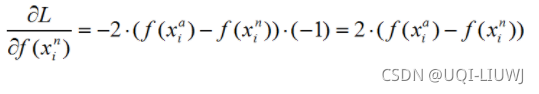


















 773
773

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











