









MLM之GLM-4:GLM-4-9B的简介、安装和使用方法、案例应用之详细攻略
背景痛点:目前主流的大语言模型如GPT-3等,在多轮对话能力、多语言能力、长文本理解能力以及对工具和代码调用能力等方面存在一定限制。
解决方案:
>> 在2024年6月5日,智谱AI重磅发布GLM-4系列开源模型,包括GLM-4-9B、GLM-4-9B-Chat等基础模型,以及GLM-4-9B-Chat-1M等支持长文档的模型。
>> GLM-4系列模型通过在预训练阶段采用自回归填空任务,加入额外任务数据,提升了多轮对话、多语言、长文本和工具调用等综合能力。
>> 并发布GLM-4V-9B多模态语言模型,支持视觉理解能力。
核心思路和步骤:
>> 使用自回归任务进行预训练,填空任务让模型学习全面理解上下文。
>> 在预训练阶段加入工具调用和代码执行等额外数据,使模型具备相关能力。
>> 提供开源实现,开放接口和基线,方便其他研究者使用和进一步优化模型。
>> 通过公开任务和数据集,验证模型在各个方面的优异性能,比如多轮对话、多语言、长文本等综合性能超越现有模型。
>> 发布GLM-4V-9B多模态模型,支持视觉理解任务,在评测中也表现出优异成绩。
GLM-4系列试图通过自回归预训练任务和额外数据,提升语言模型在综合能力方面的表现,并开源实现和接口,方便应用和研究。
目录
LLMs之GLM-130B/ChatGLM-1:《GLM-130B: AN OPEN BILINGUAL PRE-TRAINED MODEL》翻译与解读
LLMs之ChatGLM-2:ChatGLM2-6B的简介、安装、使用方法之详细攻略
LLMs之ChatGLM-3:ChatGLM3/ChatGLM3-6B的简介(多阶段增强+多模态理解+AgentTuning技术)、安装、使用方法之详细攻略
LLMs之GLM-4:GLM-4的简介(全覆盖【对话版即ChatGLM4的+工具调用+多模态文生图】能力→Agent)、安装和使用方法、案例应用之详细攻略
MLM之GLM-4:GLM-4-9B的简介、安装和使用方法、案例应用之详细攻略
LLMs之ChatGLM:ChatGLM系列模型(ChatGLM-1/ChatGLM-2/ChatGLM-3/ChatGLM-4)网络架构详解及其对比
LLMs之GLM:《ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools》翻译与解读
最低硬件要求:内存不少于 32 GB、支持 BF16 推理的 GPU 设备
3、基础功能调用:使用 GLM-4-9B 开源模型进行基本的任务
4、完整功能演示:GLM-4-9B的All Tools 能力、长文档解读和多模态能力的展示
(1)、All Tools:模型自主决定进行工具调用、连续调用多个工具、先调用工具后绘图
5、GLM-4-9B Chat 对话模型微调:支持lora、p-tuning v2、SFT
仅希望微调模型的对话能力而非工具能力:{system-user-assistant-observation-assistant}
带有工具调用的例子:{tools→system-user-assistant-observation-assistant}
deepspeed 配置文件:ds_zereo_2 / ds_zereo_3.json:
PEFT配置文件:`lora.yaml / ptuning_v2
第三步,开始微调:基于deepspeed 加速,单机多卡/多机多卡
GLM模型系列
LLMs之GLM-130B/ChatGLM-1:《GLM-130B: AN OPEN BILINGUAL PRE-TRAINED MODEL》翻译与解读
LLMs之GLM-130B/ChatGLM:《GLM-130B: AN OPEN BILINGUAL PRE-TRAINED MODEL》翻译与解读-CSDN博客
LLMs之ChatGLM-2:ChatGLM2-6B的简介、安装、使用方法之详细攻略
LLMs之ChatGLM2:ChatGLM2-6B的简介、安装、使用方法之详细攻略_一个处女座的程序猿的博客-CSDN博客
LLMs之ChatGLM-3:ChatGLM3/ChatGLM3-6B的简介(多阶段增强+多模态理解+AgentTuning技术)、安装、使用方法之详细攻略
LLMs之ChatGLM3:ChatGLM3/ChatGLM3-6B的简介(多阶段增强+多模态理解+AgentTuning技术)、安装、使用方法之详细攻略-CSDN博客
LLMs之GLM-4:GLM-4的简介(全覆盖【对话版即ChatGLM4的+工具调用+多模态文生图】能力→Agent)、安装和使用方法、案例应用之详细攻略
LLMs之GLM-4:GLM-4的简介(全覆盖【对话版即ChatGLM4的+工具调用+多模态文生图】能力→Agent)、安装和使用方法、案例应用之详细攻略-CSDN博客
MLM之GLM-4:GLM-4-9B的简介、安装和使用方法、案例应用之详细攻略
MLM之GLM-4:GLM-4-9B的简介、安装和使用方法、案例应用之详细攻略-CSDN博客
阶段性综合对比
LLMs之ChatGLM:ChatGLM系列模型(ChatGLM-1/ChatGLM-2/ChatGLM-3/ChatGLM-4)网络架构详解及其对比
https://yunyaniu.blog.csdn.net/article/details/139816980
LLMs之GLM:《ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools》翻译与解读
LLMs之GLM:《ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools》翻译与解读-CSDN博客
GLM-4的简介
GLM-4-9B 是智谱 AI 推出的最新一代预训练模型 GLM-4 系列中的开源版本。 在语义、数学、推理、代码和知识等多方面的数据集测评中, GLM-4-9B 及其人类偏好对齐的版本 GLM-4-9B-Chat 均表现出超越 Llama-3-8B 的卓越性能。除了能进行多轮对话,GLM-4-9B-Chat 还具备网页浏览、代码执行、自定义工具调用(Function Call)和长文本推理(支持最大 128K 上下文)等高级功能。本代模型增加了多语言支持,支持包括日语,韩语,德语在内的 26 种语言。我们还推出了支持 1M 上下文长度(约 200 万中文字符)的 GLM-4-9B-Chat-1M 模型和基于 GLM-4-9B 的多模态模型 GLM-4V-9B。GLM-4V-9B 具备 1120 * 1120 高分辨率下的中英双语多轮对话能力,在中英文综合能力、感知推理、文字识别、图表理解等多方面多模态评测中,GLM-4V-9B 表现出超越 GPT-4-turbo-2024-04-09、Gemini 1.0 Pro、Qwen-VL-Max 和 Claude 3 Opus 的卓越性能。
Github地址:https://github.com/THUDM/GLM-4/tree/main
Model List
| Model | Type | Seq Length | Download | Online Demo |
|---|---|---|---|---|
| GLM-4-9B | Base | 8K | 🤗 Huggingface 🤖 ModelScope | / |
| GLM-4-9B-Chat | Chat | 128K | 🤗 Huggingface 🤖 ModelScope | 🤖 ModelScope CPU 🤖 ModelScope vLLM |
| GLM-4-9B-Chat-1M | Chat | 1M | 🤗 Huggingface 🤖 ModelScope | / |
| GLM-4V-9B | Chat | 8K | 🤗 Huggingface 🤖 ModelScope | / |
评测结果
对话模型典型任务
| Model | AlignBench | MT-Bench | IFEval | MMLU | C-Eval | GSM8K | MATH | HumanEval | NaturalCodeBench |
|---|---|---|---|---|---|---|---|---|---|
| Llama-3-8B-Instruct | 6.40 | 8.00 | 68.6 | 68.4 | 51.3 | 79.6 | 30.0 | 62.2 | 24.7 |
| ChatGLM3-6B | 5.18 | 5.50 | 28.1 | 61.4 | 69.0 | 72.3 | 25.7 | 58.5 | 11.3 |
| GLM-4-9B-Chat | 7.01 | 8.35 | 69.0 | 72.4 | 75.6 | 79.6 | 50.6 | 71.8 | 32.2 |
基座模型典型任务
| Model | MMLU | C-Eval | GPQA | GSM8K | MATH | HumanEval |
|---|---|---|---|---|---|---|
| Llama-3-8B | 66.6 | 51.2 | - | 45.8 | - | 33.5 |
| Llama-3-8B-Instruct | 68.4 | 51.3 | 34.2 | 79.6 | 30.0 | 62.2 |
| ChatGLM3-6B-Base | 61.4 | 69.0 | 26.8 | 72.3 | 25.7 | 58.5 |
| GLM-4-9B | 74.7 | 77.1 | 34.3 | 84.0 | 30.4 | 70.1 |
由于 GLM-4-9B 在预训练过程中加入了部分数学、推理、代码相关的 instruction 数据,所以将 Llama-3-8B-Instruct 也列入比较范围。
长文本
在 1M 的上下文长度下进行大海捞针实验,结果如下:
在 LongBench-Chat 上对长文本能力进行了进一步评测,结果如下:
多语言能力
在六个多语言数据集上对 GLM-4-9B-Chat 和 Llama-3-8B-Instruct 进行了测试,测试结果及数据集对应选取语言如下表
| Dataset | Llama-3-8B-Instruct | GLM-4-9B-Chat | Languages |
|---|---|---|---|
| M-MMLU | 49.6 | 56.6 | all |
| FLORES | 25.0 | 28.8 | ru, es, de, fr, it, pt, pl, ja, nl, ar, tr, cs, vi, fa, hu, el, ro, sv, uk, fi, ko, da, bg, no |
| MGSM | 54.0 | 65.3 | zh, en, bn, de, es, fr, ja, ru, sw, te, th |
| XWinograd | 61.7 | 73.1 | zh, en, fr, jp, ru, pt |
| XStoryCloze | 84.7 | 90.7 | zh, en, ar, es, eu, hi, id, my, ru, sw, te |
| XCOPA | 73.3 | 80.1 | zh, et, ht, id, it, qu, sw, ta, th, tr, vi |
工具调用能力
我们在 Berkeley Function Calling Leaderboard 上进行了测试并得到了以下结果:
| Model | Overall Acc. | AST Summary | Exec Summary | Relevance |
|---|---|---|---|---|
| Llama-3-8B-Instruct | 58.88 | 59.25 | 70.01 | 45.83 |
| gpt-4-turbo-2024-04-09 | 81.24 | 82.14 | 78.61 | 88.75 |
| ChatGLM3-6B | 57.88 | 62.18 | 69.78 | 5.42 |
| GLM-4-9B-Chat | 81.00 | 80.26 | 84.40 | 87.92 |
多模态能力
GLM-4V-9B 是一个多模态语言模型,具备视觉理解能力,其相关经典任务的评测结果如下:
| MMBench-EN-Test | MMBench-CN-Test | SEEDBench_IMG | MMStar | MMMU | MME | HallusionBench | AI2D | OCRBench | |
|---|---|---|---|---|---|---|---|---|---|
| gpt-4o-2024-05-13 | 83.4 | 82.1 | 77.1 | 63.9 | 69.2 | 2310.3 | 55.0 | 84.6 | 736 |
| gpt-4-turbo-2024-04-09 | 81.0 | 80.2 | 73.0 | 56.0 | 61.7 | 2070.2 | 43.9 | 78.6 | 656 |
| gpt-4-1106-preview | 77.0 | 74.4 | 72.3 | 49.7 | 53.8 | 1771.5 | 46.5 | 75.9 | 516 |
| InternVL-Chat-V1.5 | 82.3 | 80.7 | 75.2 | 57.1 | 46.8 | 2189.6 | 47.4 | 80.6 | 720 |
| LLaVA-Next-Yi-34B | 81.1 | 79.0 | 75.7 | 51.6 | 48.8 | 2050.2 | 34.8 | 78.9 | 574 |
| Step-1V | 80.7 | 79.9 | 70.3 | 50.0 | 49.9 | 2206.4 | 48.4 | 79.2 | 625 |
| MiniCPM-Llama3-V2.5 | 77.6 | 73.8 | 72.3 | 51.8 | 45.8 | 2024.6 | 42.4 | 78.4 | 725 |
| Qwen-VL-Max | 77.6 | 75.7 | 72.7 | 49.5 | 52.0 | 2281.7 | 41.2 | 75.7 | 684 |
| Gemini 1.0 Pro | 73.6 | 74.3 | 70.7 | 38.6 | 49.0 | 2148.9 | 45.7 | 72.9 | 680 |
| Claude 3 Opus | 63.3 | 59.2 | 64.0 | 45.7 | 54.9 | 1586.8 | 37.8 | 70.6 | 694 |
| GLM-4V-9B | 81.1 | 79.4 | 76.8 | 58.7 | 47.2 | 2163.8 | 46.6 | 81.1 | 786 |
GLM-4-9B的安装和使用
1、GLM-4-9B的安装
硬件配置和系统要求,请查看这里
设备和依赖检查
相关推理测试数据
本文档的数据均在以下硬件环境测试,实际运行环境需求和运行占用的显存略有不同,请以实际运行环境为准。
测试硬件信息:
- OS: Ubuntu 22.04
- Memory: 512GB
- Python: 3.10.12 (推荐) / 3.12.3 均已测试
- CUDA Version: 12.3
- GPU Driver: 535.104.05
- GPU: NVIDIA A100-SXM4-80GB * 8
相关推理的压力测试数据如下:
所有测试均在单张GPU上进行测试,所有显存消耗都按照峰值左右进行测算
GLM-4-9B-Chat
| 精度 | 显存占用 | Prefilling | Decode Speed | Remarks |
|---|---|---|---|---|
| BF16 | 19 GB | 0.2s | 27.8 tokens/s | 输入长度为 1000 |
| BF16 | 21 GB | 0.8s | 31.8 tokens/s | 输入长度为 8000 |
| BF16 | 28 GB | 4.3s | 14.4 tokens/s | 输入长度为 32000 |
| BF16 | 58 GB | 38.1s | 3.4 tokens/s | 输入长度为 128000 |
| 精度 | 显存占用 | Prefilling | Decode Speed | Remarks |
|---|---|---|---|---|
| INT4 | 8 GB | 0.2s | 23.3 tokens/s | 输入长度为 1000 |
| INT4 | 10 GB | 0.8s | 23.4 tokens/s | 输入长度为 8000 |
| INT4 | 17 GB | 4.3s | 14.6 tokens/s | 输入长度为 32000 |
GLM-4-9B-Chat-1M
| 精度 | 显存占用 | Prefilling | Decode Speed | Remarks |
|---|---|---|---|---|
| BF16 | 75 GB | 98.4s | 2.3 tokens/s | 输入长度为 200000 |
如果您的输入超过200K,我们建议您使用vLLM后端进行多卡推理,以获得更好的性能。
GLM-4V-9B
| 精度 | 显存占用 | Prefilling | Decode Speed | Remarks |
|---|---|---|---|---|
| BF16 | 28 GB | 0.1s | 33.4 tokens/s | 输入长度为 1000 |
| BF16 | 33 GB | 0.7s | 39.2 tokens/s | 输入长度为 8000 |
| 精度 | 显存占用 | Prefilling | Decode Speed | Remarks |
|---|---|---|---|---|
| INT4 | 10 GB | 0.1s | 28.7 tokens/s | 输入长度为 1000 |
| INT4 | 15 GB | 0.8s | 24.2 tokens/s | 输入长度为 8000 |
最低硬件要求:内存不少于 32 GB、支持 BF16 推理的 GPU 设备
如果您希望运行官方提供的最基础代码 (transformers 后端) 您需要:
- Python >= 3.10
- 内存不少于 32 GB
如果您希望运行官方提供的本文件夹的所有代码,您还需要:
- Linux 操作系统 (Debian 系列最佳)。
Debian是一个基于Linux内核的完整操作系统,它是由社区组织维护的自由软件项目。Debian以其稳定性和安全性而闻名,并且是许多其他流行的Linux发行版(如Ubuntu和Linux Mint)的基础。Debian提供了广泛的软件包,并且使用dpkg包管理系统以及apt(高级包装工具)来安装和更新软件。 - 大于 8GB 显存的,支持 CUDA 或者 ROCM 并且支持
BF16推理的 GPU 设备。(FP16精度无法训练,推理有小概率出现问题)
安装依赖
pip install -r requirements.txt2、快速调用
使用以下方法快速调用 GLM-4-9B-Chat 语言模型
T1、使用 transformers 后端进行推理:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda"
tokenizer = AutoTokenizer.from_pretrained("THUDM/glm-4-9b-chat", trust_remote_code=True)
query = "你好"
inputs = tokenizer.apply_chat_template([{"role": "user", "content": query}],
add_generation_prompt=True,
tokenize=True,
return_tensors="pt",
return_dict=True
)
inputs = inputs.to(device)
model = AutoModelForCausalLM.from_pretrained(
"THUDM/glm-4-9b-chat",
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
trust_remote_code=True
).to(device).eval()
gen_kwargs = {"max_length": 2500, "do_sample": True, "top_k": 1}
with torch.no_grad():
outputs = model.generate(**inputs, **gen_kwargs)
outputs = outputs[:, inputs['input_ids'].shape[1]:]
print(tokenizer.decode(outputs[0], skip_special_tokens=True))T2、使用 vLLM 后端进行推理
from transformers import AutoTokenizer
from vllm import LLM, SamplingParams
# GLM-4-9B-Chat-1M
# max_model_len, tp_size = 1048576, 4
# 如果遇见 OOM 现象,建议减少max_model_len,或者增加tp_size
max_model_len, tp_size = 131072, 1
model_name = "THUDM/glm-4-9b-chat"
prompt = [{"role": "user", "content": "你好"}]
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
llm = LLM(
model=model_name,
tensor_parallel_size=tp_size,
max_model_len=max_model_len,
trust_remote_code=True,
enforce_eager=True,
# GLM-4-9B-Chat-1M 如果遇见 OOM 现象,建议开启下述参数
# enable_chunked_prefill=True,
# max_num_batched_tokens=8192
)
stop_token_ids = [151329, 151336, 151338]
sampling_params = SamplingParams(temperature=0.95, max_tokens=1024, stop_token_ids=stop_token_ids)
inputs = tokenizer.apply_chat_template(prompt, tokenize=False, add_generation_prompt=True)
outputs = llm.generate(prompts=inputs, sampling_params=sampling_params)
print(outputs[0].outputs[0].text)使用以下方法快速调用 GLM-4V-9B 多模态模型
T1、使用 transformers 后端进行推理
使用 transformers 后端进行推理:
import torch
from PIL import Image
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda"
tokenizer = AutoTokenizer.from_pretrained("THUDM/glm-4v-9b", trust_remote_code=True)
query = '描述这张图片'
image = Image.open("your image").convert('RGB')
inputs = tokenizer.apply_chat_template([{"role": "user", "image": image, "content": query}],
add_generation_prompt=True, tokenize=True, return_tensors="pt",
return_dict=True) # chat mode
inputs = inputs.to(device)
model = AutoModelForCausalLM.from_pretrained(
"THUDM/glm-4v-9b",
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
trust_remote_code=True
).to(device).eval()
gen_kwargs = {"max_length": 2500, "do_sample": True, "top_k": 1}
with torch.no_grad():
outputs = model.generate(**inputs, **gen_kwargs)
outputs = outputs[:, inputs['input_ids'].shape[1]:]
print(tokenizer.decode(outputs[0]))
注意: GLM-4V-9B 暂不支持使用 vLLM 方式调用。3、基础功能调用:使用 GLM-4-9B 开源模型进行基本的任务
-
basic_demo: 在这里包含了
- 使用 transformers 和 vLLM 后端的交互代码
- OpenAI API 后端交互代码
- Batch 推理代码
除非特殊说明,本文件夹所有 demo 并不支持 Function Call 和 All Tools 等进阶用法
使用 transformers 后端代码
- 使用命令行与 GLM-4-9B 模型进行对话。
python trans_cli_demo.py # GLM-4-9B-Chat
python trans_cli_vision_demo.py # GLM-4V-9B- 使用 Gradio 网页端与 GLM-4-9B-Chat 模型进行对话。
python trans_web_demo.py- 使用 Batch 推理。
python cli_batch_request_demo.py使用 vLLM 后端代码
- 使用命令行与 GLM-4-9B-Chat 模型进行对话。
python vllm_cli_demo.py- 自行构建服务端,并使用
OpenAI API的请求格式与 GLM-4-9B-Chat 模型进行对话。本 demo 支持 Function Call 和 All Tools功能。
启动服务端:
python openai_api_server.py客户端请求:
python openai_api_request.py压力测试
用户可以在自己的设备上使用本代码测试模型在 transformers后端的生成速度:
python trans_stress_test.py4、完整功能演示:GLM-4-9B的All Tools 能力、长文档解读和多模态能力的展示
-
composite_demo: 在这里包含了
- GLM-4-9B-Chat 以及 GLM-4V-9B 开源模型的完整功能演示代码,包含了 All Tools 能力、长文档解读和多模态能力的展示。
安装
我们建议通过 Conda 进行环境管理。 执行以下命令新建一个 conda 环境并安装所需依赖:
conda create -n glm-4-demo python=3.12
conda activate glm-4-demo
pip install -r requirements.txt请注意,本项目需要 Python 3.10 或更高版本。 此外,使用 Code Interpreter 还需要安装 Jupyter 内核:
ipython kernel install --name glm-4-demo --user您可以修改 ~/.local/share/jupyter/kernels/glm-4-demo/kernel.json 来改变 Jupyter 内核的配置,包括内核的启动参数等。例如,若您希望在使用 All Tools 的 Python 代码执行能力时使用 Matplotlib 画图,可以在 argv 数组中添加 "--matplotlib=inline"。
若要使用浏览器和搜索功能,还需要启动浏览器后端。首先,根据 Node.js 官网的指示安装 Node.js,然后安装包管理器 PNPM 之后安装浏览器服务的依赖:
cd browser
npm install -g pnpm
pnpm install运行
-
修改
browser/src/config.ts中的BING_SEARCH_API_KEY配置浏览器服务需要使用的 Bing 搜索 API Key:export default { BROWSER_TIMEOUT: 10000, BING_SEARCH_API_URL: 'https://api.bing.microsoft.com/v7.0', BING_SEARCH_API_KEY: '<PUT_YOUR_BING_SEARCH_KEY_HERE>', HOST: 'localhost', PORT: 3000, }; -
文生图功能需要调用 CogView API。修改
src/tools/config.py,提供文生图功能需要使用的 智谱 AI 开放平台 API Key:BROWSER_SERVER_URL = 'http://localhost:3000' IPYKERNEL = 'glm-4-demo' ZHIPU_AI_KEY = '<PUT_YOUR_ZHIPU_AI_KEY_HERE>' COGVIEW_MODEL = 'cogview-3' -
启动浏览器后端,在单独的 shell 中:
cd browser pnpm start -
运行以下命令在本地加载模型并启动 demo:
streamlit run src/main.py
之后即可从命令行中看到 demo 的地址,点击即可访问。初次访问需要下载并加载模型,可能需要花费一定时间。
如果已经在本地下载了模型,可以通过 export *_MODEL_PATH=/path/to/model 来指定从本地加载模型。可以指定的模型包括:
CHAT_MODEL_PATH: 用于 All Tools 模式与文档解读模式,默认为THUDM/glm-4-9b-chat。VLM_MODEL_PATH: 用于 VLM 模式,默认为THUDM/glm-4v-9b。
Chat 模型支持使用 vLLM 推理。若要使用,请安装 vLLM 并设置环境变量 USE_VLLM=1。
如果需要自定义 Jupyter 内核,可以通过 export IPYKERNEL=<kernel_name> 来指定。
使用
GLM-4 Demo 拥有三种模式:
- All Tools: 具有完整工具调用能力的对话模式,原生支持网页浏览、代码执行、图片生成,并支持自定义工具。
- 文档解读: 支持上传文档进行文档解读与对话。
- 多模态: 支持上传图像进行图像理解与对话。
(1)、All Tools:模型自主决定进行工具调用、连续调用多个工具、先调用工具后绘图
本模式兼容 ChatGLM3-6B 的工具注册流程。
- 代码能力,绘图能力,联网能力已经自动集成,用户只需按照要求配置对应的Key。
- 本模式下不支持系统提示词,模型会自动构建提示词。
对话模式下,用户可以直接在侧边栏修改 top_p, temperature 等参数来调整模型的行为。
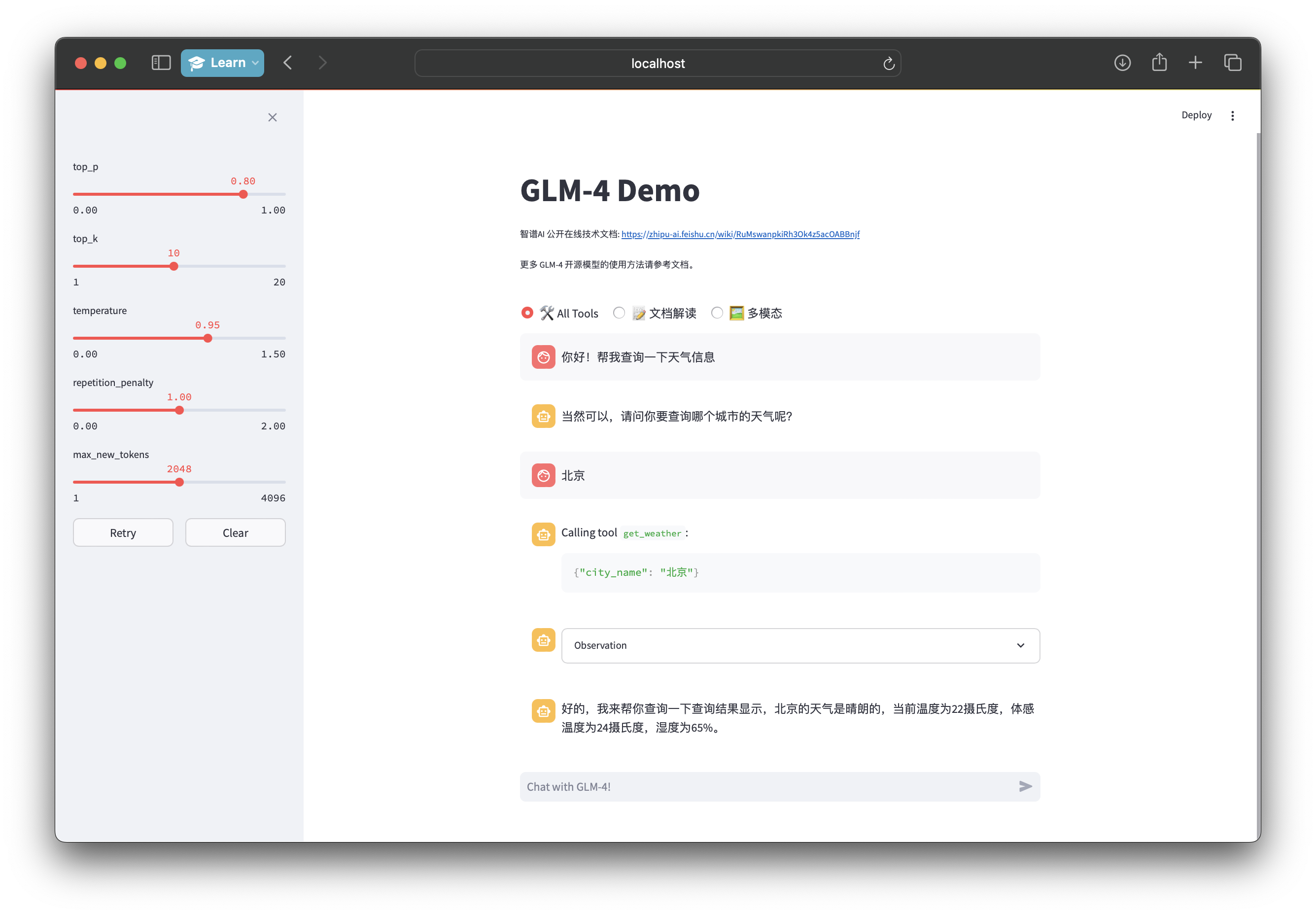
- 与模型对话时,模型将会自主决定进行工具调用。
- 由于原始结果可能较长,默认情况下工具调用结果被隐藏,可以通过展开折叠框查看原始的工具调用结果。
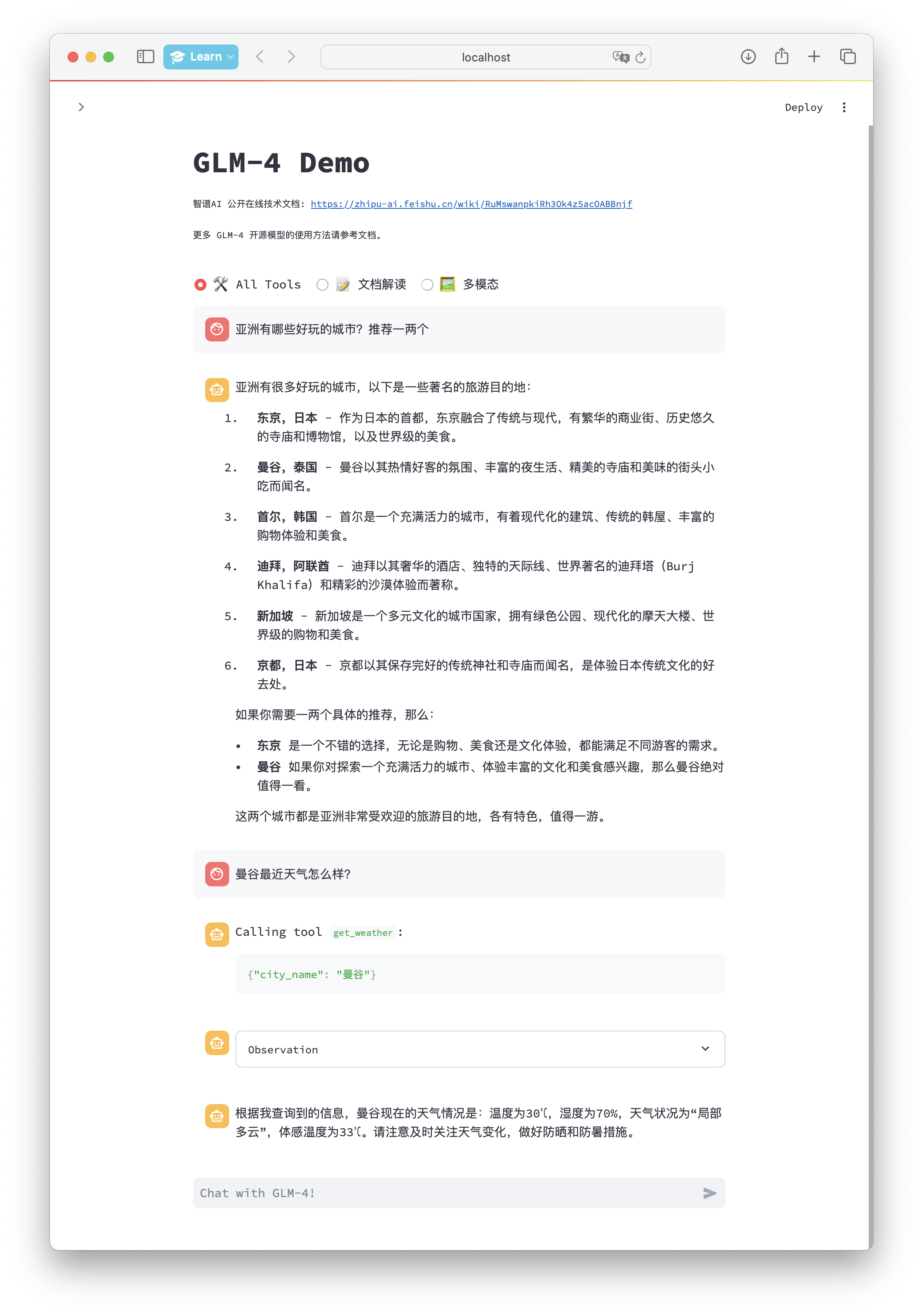
- 模型拥有进行网页搜索和 Python 代码执行的能力。同时,模型也可以连续调用多个工具。例如:
- 此时模型通过调用浏览器工具进行搜索获取到了需要的数据,之后将会调用 Python 工具执行代码,利用 Matplotlib 绘图:
- 如果提供了智谱开放平台 API Key,模型也可以调用 CogView 进行图像生成:
模型拥有进行网页搜索和 Python 代码执行的能力。同时,模型也可以连续调用多个工具。例如:

此时模型通过调用浏览器工具进行搜索获取到了需要的数据,之后将会调用 Python 工具执行代码,利用 Matplotlib 绘图:

如果提供了智谱开放平台 API Key,模型也可以调用 CogView 进行图像生成:

自定义工具
可以通过在 tool_registry.py 中注册新的工具来增强模型的能力。只需要使用 @register_tool 装饰函数即可完成注册。对于工具声明,函数名称即为工具的名称,函数 docstring 即为工具的说明;对于工具的参数,使用 Annotated[typ: type, description: str, required: bool] 标注参数的类型、描述和是否必须。
例如,get_weather 工具的注册如下:
@register_tool
def get_weather(
city_name: Annotated[str, 'The name of the city to be queried', True],
) -> str:
"""
Get the weather for `city_name` in the following week
"""
...
(2)、文档解读:暂不支持不支持工具调用和系统提示词
用户可以上传文档,使用 GLM-4-9B的长文本能力,对文本进行理解。可以解析 pptx,docx,pdf等文件。
- 本模式下不支持工具调用和系统提示词。
- 如果文本很长,可能导致模型需要的显存较高,请确认你的硬件配置。

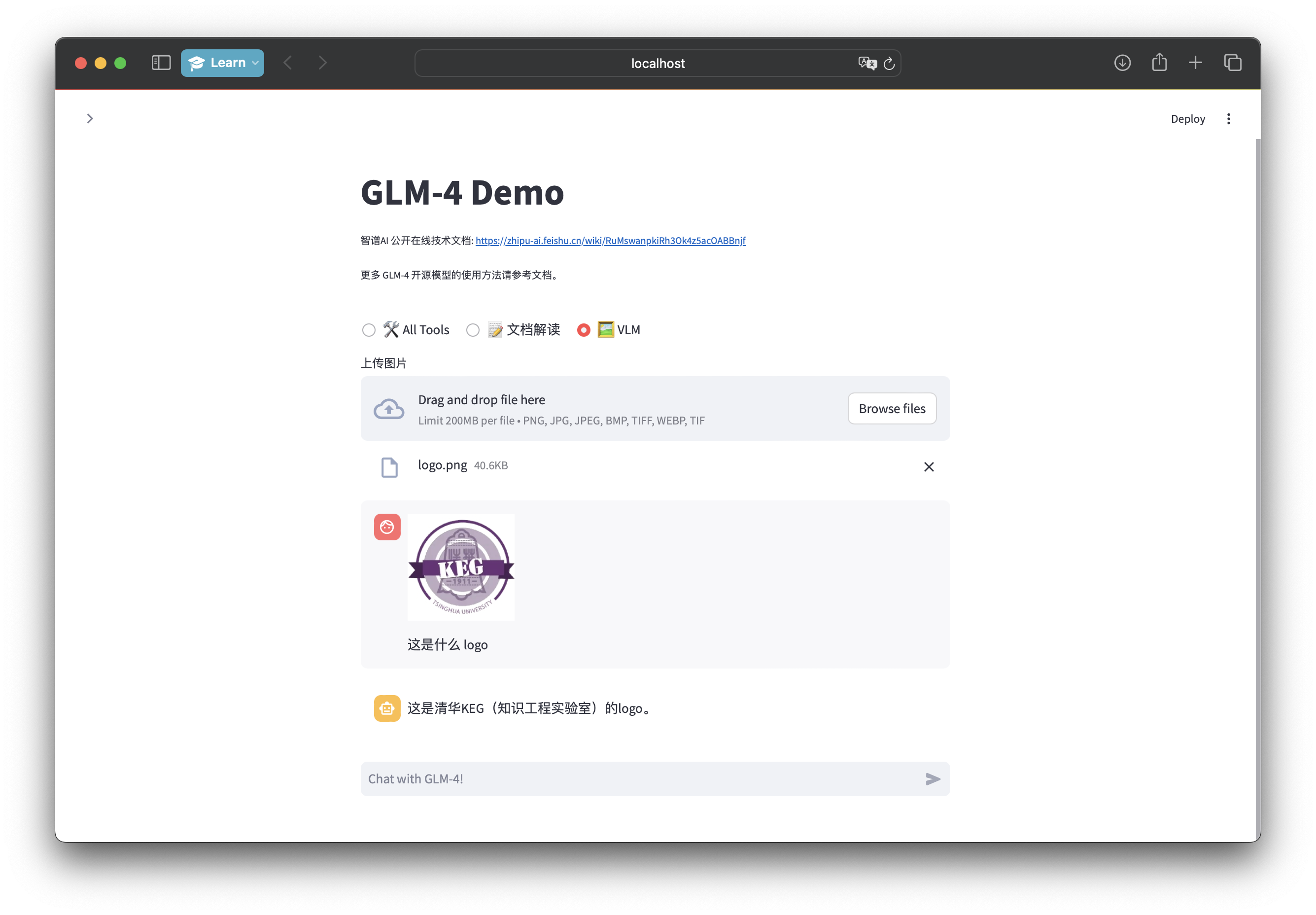
(3)、多模态:不支持工具调用和系统提示词
多模态模式下,用户可以利用 GLM-4V 的多模态理解能力,上传图像并与 GLM-4V 进行多轮对话:
用户可以上传图片,使用 GLM-4-9B的图像理解能力,对图片进行理解。
- 本模式必须使用 glm-4v-9b 模型。
- 本模式下不支持工具调用和系统提示词。
- 模型仅能对一张图片进行理解和联系对话,如需更换图片,需要开启一个新的对话。
- 图像支持的分辨率为 1120 x 1120。
5、GLM-4-9B Chat 对话模型微调:支持lora、p-tuning v2、SFT
本 demo 中,你将体验到如何微调 GLM-4-9B-Chat 对话开源模型(不支持视觉理解模型)。 请严格按照文档的步骤进行操作,以避免不必要的错误。
硬件检查:Ubuntu 22.04、CUDA 12.3
本文档的数据均在以下硬件环境测试,实际运行环境需求和运行占用的显存略有不同,请以实际运行环境为准。 测试硬件信息:
- OS: Ubuntu 22.04
- Memory: 512GB
- Python: 3.10.12 / 3.12.3 (如果您使用 Python 3.12.3 目前需要使用 git 源码安装 nltk)
- CUDA Version: 12.3
- GPU Driver: 535.104.05
- GPU: NVIDIA A100-SXM4-80GB * 8
| 微调方案 | 显存占用 | 权重保存点大小 |
|---|---|---|
| lora (PEFT) | 21531MiB | 17M |
| p-tuning v2 (PEFT) | 21381MiB | 121M |
| SFT (Zero3 method) | 80935MiB (Each GPU,需要使用8张GPU) | 20G |
在开始微调之前,请你先安装basic_demo中的依赖,同时您需要安装本目录下的依赖项:
NOTE: NLTK 3.8.1 部分代码可能尚未对 python 3.12 进行适配,该情况下的适配方法可参考issues #38
pip install -r requirements.txt~~~~多轮对话格式微调~~~~
多轮对话微调示例采用 GLM-4 对话格式约定,对不同角色添加不同 loss_mask 从而在一遍计算中为多轮回复计算 loss。
源地址:GLM-4/finetune_demo at main · THUDM/GLM-4 · GitHub
第一步,微调数据格式:对于数据文件,样例采用如下格式
仅希望微调模型的对话能力而非工具能力:{system-user-assistant-observation-assistant}
如果您仅希望微调模型的对话能力,而非工具能力,您应该按照以下格式整理数据。
[
{
"messages": [
{
"role": "system",
"content": "<system prompt text>",
"tools": [
{
"name": "<tool name>",
"args": {
"<arg name>": "<arg value>"
}
}
// Add more tools if needed
]
},
{
"role": "user",
"content": "<user prompt text>"
},
{
"role": "assistant",
"content": "<assistant response text>"
},
// If Tool Using
{
"role": "user",
"content": "<user prompt text>"
},
{
"role": "assistant",
"content": "<assistant response text>"
},
{
"role": "observation",
"content": "<observation prompt text>"
},
{
"role": "assistant",
"content": "<assistant response observation>"
},
// Multi_turns
{
"role": "user",
"content": "<user prompt text>"
},
{
"role": "assistant",
"content": "<assistant response text>"
}
]
}
]不带有工具的例子:{user-assistant}
这里是一个不带有工具的例子:
{"messages": [
{"role": "user", "content": "类型#裤*材质#牛仔布*风格#性感"},
{"role": "assistant", "content": "3x1的这款牛仔裤采用浅白的牛仔面料为裤身材质,其柔然的手感和细腻的质地,在穿着舒适的同时,透露着清纯甜美的个性气质。除此之外,流畅的裤身剪裁将性感的腿部曲线彰显的淋漓尽致,不失为一款随性出街的必备单品。"}
]
}带有工具调用的例子:{tools→system-user-assistant-observation-assistant}
这是一个带有工具调用的例子:
{"messages":
[
{"role": "system", "content": "", "tools":
[
{"type": "function", "function":
{"name": "get_recommended_books", "description": "Get recommended books based on user's interests",
"parameters":
{"type": "object", "properties":
{"interests":
{"type": "array", "items":
{"type": "string"},
"description": "The interests to recommend books for"}
}, "required": ["interests"]
}
}
}
]
},
{"role": "user", "content": "Hi, I am looking for some book recommendations. I am interested in history and science fiction."},
{"role": "assistant", "content": "{\"name\": \"get_recommended_books\", \"arguments\": {\"interests\": [\"history\", \"science fiction\"]}}"},
{"role": "observation", "content": "{\"books\": [\"Sapiens: A Brief History of Humankind by Yuval Noah Harari\", \"A Brief History of Time by Stephen Hawking\", \"Dune by Frank Herbert\", \"The Martian by Andy Weir\"]}"},
{"role": "assistant", "content": "Based on your interests in history and science fiction, I would recommend the following books: \"Sapiens: A Brief History of Humankind\" by Yuval Noah Harari, \"A Brief History of Time\" by Stephen Hawking, \"Dune\" by Frank Herbert, and \"The Martian\" by Andy Weir."}
]
}
system角色为可选角色,但若存在system角色,其必须出现在user角色之前,且一个完整的对话数据(无论单轮或者多轮对话)只能出现一次system角色。tools字段为可选字段,若存在tools字段,其必须出现在system角色之后,且一个完整的对话数据(无论单轮或者多轮对话)只能出现一次tools字段。当tools字段存在时,system角色必须存在并且content字段为空。
第二步,配置文件
微调配置文件位于 config 目录下,包括以下文件:
deepspeed 配置文件:ds_zereo_2 / ds_zereo_3.json:
{
"train_micro_batch_size_per_gpu": "auto", // 自动设置每个GPU的微批次训练大小
"zero_allow_untested_optimizer": true, // 允许使用未测试的优化器
"bf16": {
"enabled": "auto" // 自动启用或禁用 bfloat16 精度训练
},
"optimizer": {
"type": "AdamW", // 使用 AdamW 优化器
"params": {
"lr": "auto", // 自动设置学习率
"betas": "auto", // 自动设置 beta 参数
"eps": "auto", // 自动设置 epsilon 参数
"weight_decay": "auto" // 自动设置权重衰减参数
}
},
"zero_optimization": {
"stage": 3, // 启用 ZeRO 优化器的第 3 阶段
"allgather_partitions": true, // 启用 all-gather 分区
"allgather_bucket_size": 5e8, // 设置 all-gather 的桶大小
"reduce_scatter": true, // 启用 reduce-scatter 操作
"contiguous_gradients": true, // 使用连续的梯度内存
"overlap_comm": true, // 启用通信重叠
"sub_group_size": 1e9, // 设置子组大小
"reduce_bucket_size": "auto", // 自动设置 reduce 桶大小
"stage3_prefetch_bucket_size": "auto", // 自动设置第 3 阶段预取桶大小
"stage3_param_persistence_threshold": "auto", // 自动设置第 3 阶段参数持久性阈值
"stage3_max_live_parameters": 1e9, // 设置第 3 阶段最大活动参数数
"stage3_max_reuse_distance": 1e9, // 设置第 3 阶段最大重用距离
"stage3_gather_16bit_weights_on_model_save": true // 保存模型时收集 16 位权重
}
}
PEFT配置文件:`lora.yaml / ptuning_v2
.yaml / sft.yaml`: 模型不同方式的配置文件,包括模型参数、优化器参数、训练参数等。 部分重要参数解释如下:
- data_config 部分
- train_file: 训练数据集的文件路径。
- val_file: 验证数据集的文件路径。
- test_file: 测试数据集的文件路径。
- num_proc: 在加载数据时使用的进程数量。
- max_input_length: 输入序列的最大长度。
- max_output_length: 输出序列的最大长度。
- training_args 部分
- output_dir: 用于保存模型和其他输出的目录。
- max_steps: 训练的最大步数。
- per_device_train_batch_size: 每个设备(如 GPU)的训练批次大小。
- dataloader_num_workers: 加载数据时使用的工作线程数量。
- remove_unused_columns: 是否移除数据中未使用的列。
- save_strategy: 模型保存策略(例如,每隔多少步保存一次)。
- save_steps: 每隔多少步保存一次模型。
- log_level: 日志级别(如 info)。
- logging_strategy: 日志记录策略。
- logging_steps: 每隔多少步记录一次日志。
- per_device_eval_batch_size: 每个设备的评估批次大小。
- evaluation_strategy: 评估策略(例如,每隔多少步进行一次评估)。
- eval_steps: 每隔多少步进行一次评估。
- predict_with_generate: 是否使用生成模式进行预测。
- generation_config 部分
- max_new_tokens: 生成的最大新 token 数量。
- peft_config 部分
- peft_type: 使用的参数有效调整类型 (支持 LORA 和 PREFIX_TUNING)。
- task_type: 任务类型,这里是因果语言模型 (不要改动)。
- Lora 参数:
- r: LoRA 的秩。
- lora_alpha: LoRA 的缩放因子。
- lora_dropout: 在 LoRA 层使用的 dropout 概率。
- P-TuningV2 参数:
- num_virtual_tokens: 虚拟 token 的数量。
- num_attention_heads: 2: P-TuningV2 的注意力头数(不要改动)。
- token_dim: 256: P-TuningV2 的 token 维度(不要改动)。
参数对比:ptuning_v2参数配置、lora参数配置
| ptuning_v2参数配置 | lora参数配置 | |
| 数据配置 | data_config: train_file: train.jsonl val_file: dev.jsonl test_file: dev.jsonl num_proc: 1 max_input_length: 128 max_output_length: 128 | data_config: train_file: train.jsonl val_file: dev.jsonl test_file: dev.jsonl num_proc: 1 max_input_length: 512 max_output_length: 512 |
| 训练参数 | training_args: # see `transformers.Seq2SeqTrainingArguments` output_dir: ./output max_steps: 3000 # needed to be fit for the dataset learning_rate: 5e-4 # settings for data loading per_device_train_batch_size: 4 dataloader_num_workers: 16 remove_unused_columns: false # settings for saving checkpoints save_strategy: steps save_steps: 500 # settings for logging log_level: info logging_strategy: steps logging_steps: 500 # settings for evaluation per_device_eval_batch_size: 16 evaluation_strategy: steps eval_steps: 500 # settings for optimizer # adam_epsilon: 1e-6 # uncomment the following line to detect nan or inf values # debug: underflow_overflow predict_with_generate: true # see `transformers.GenerationConfig` generation_config: max_new_tokens: 512 # set your absolute deepspeed path here #deepspeed: ds_zero_3.json | training_args: # see `transformers.Seq2SeqTrainingArguments` output_dir: ./output max_steps: 3000 # needed to be fit for the dataset learning_rate: 5e-4 # settings for data loading per_device_train_batch_size: 1 dataloader_num_workers: 16 remove_unused_columns: false # settings for saving checkpoints save_strategy: steps save_steps: 500 # settings for logging log_level: info logging_strategy: steps logging_steps: 10 # settings for evaluation per_device_eval_batch_size: 4 evaluation_strategy: steps eval_steps: 500 # settings for optimizer # adam_epsilon: 1e-6 # uncomment the following line to detect nan or inf values # debug: underflow_overflow predict_with_generate: true # see `transformers.GenerationConfig` generation_config: max_new_tokens: 512 # set your absolute deepspeed path here #deepspeed: ds_zero_2.json |
| PEFT配置 | peft_config: peft_type: PREFIX_TUNING task_type: CAUSAL_LM num_virtual_tokens: 512 num_attention_heads: 2 token_dim: 256 | peft_config: peft_type: LORA task_type: CAUSAL_LM r: 8 lora_alpha: 32 lora_dropout: 0.1 |
| 总结对比 | >> 输入/输出长度:ptuning_v2的最大输入/输出长度为128,而lora为512。LORA处理更长的序列。 >> 训练批量大小:ptuning_v2的每设备训练批量大小为4,而lora为1。这意味着在相同的GPU内存限制下,lora处理的样本数量较少。 >> 日志记录频率:ptuning_v2每500步记录一次日志,而lora每10步记录一次日志。lora提供更频繁的日志记录,有助于更细粒度地监控训练过程。 >> 评估批量大小:ptuning_v2的每设备评估批量大小为16,而lora为4。ptuning_v2在评估时处理的样本更多。 >> PEFT配置: ptuning_v2使用前缀调优(PREFIX_TUNING),配置了512个虚拟token、2个注意力头和256维的token维度。 lora使用低秩适应(LORA),配置了r参数为8,lora_alpha为32,lora_dropout为0.1。LORA主要通过调整权重矩阵的低秩分解来实现参数高效微调。 通过以上对比可以看出,ptuning_v2和lora各有优缺点,适用于不同的应用场景。ptuning_v2适合较小的输入输出长度,具有较大的评估批量和虚拟token配置。lora则适合处理更长的输入输出序列,并提供了更频繁的日志记录和独特的低秩适应技术。 | |
第三步,开始微调:基于deepspeed 加速,单机多卡/多机多卡
通过以下代码执行 单机多卡/多机多卡 运行,这是使用 deepspeed 作为加速方案的,您需要安装 deepspeed。
OMP_NUM_THREADS=1 torchrun --standalone --nnodes=1 --nproc_per_node=8 finetune_hf.py data/AdvertiseGen/ THUDM/glm-4-9b configs/lora.yaml通过以下代码执行 单机单卡 运行。
python finetune.py data/AdvertiseGen/ THUDM/glm-4-9b-chat configs/lora.yaml从保存点进行微调
如果按照上述方式进行训练,每次微调都会从头开始,如果你想从训练一半的模型开始微调,你可以加入第四个参数,这个参数有两种传入方式:
yes, 自动从最后一个保存的 Checkpoint开始训练XX, 断点号数字 例600则从序号600 Checkpoint开始训练
例如,这就是一个从最后一个保存点继续微调的示例代码
python finetune.py data/AdvertiseGen/ THUDM/glm-4-9b-chat configs/lora.yaml yesMLM之GLM-4:GLM-4-9B源码解读(finetune.py)模型微调与评估的完整实现——定义命令行参数→加载微调配置/模型/分词器/数据管理器→定义数据集(训练集/验证集/测试集)→模型训练(梯度检查点/支持从检查点恢复训练)→模型评估(存在测试数据集/基于ROUGE和BLEU分数)
第四步,使用微调后的模型
在 inference.py 中验证微调后的模型
您可以在 finetune_demo/inference.py 中使用我们的微调后的模型,仅需要一行代码就能简单的进行测试。
python inference.py your_finetune_path这样,得到的回答就微调后的回答了。
MLM之GLM-4:GLM-4-9B源码解读(inference.py)加载预训练的因果语言模型基于用户提问实现对话生成——定义对话消息模板{system+tools+user}→加载模型和分词器→利用apply_chat_template函数应用对话模板(将消息转换为模型输入格式)→定义生成参数并生成输出→解码输出并打印响应
在本仓库的其他 demo 或者外部仓库使用微调后的模型
您可以在任何一个 demo 内使用我们的 LORA 和 全参微调的模型。这需要你自己按照以下教程进行修改代码。
- 使用
finetune_demo/inference.py中读入模型的方式替换 demo 中读入模型的方式。
请注意,对于 LORA 和 P-TuningV2 我们没有合并训练后的模型,而是在
adapter_config.json中记录了微调型的路径,如果你的原始模型位置发生更改,则你应该修改adapter_config.json中base_model_name_or_path的路径。
def load_model_and_tokenizer(
model_dir: Union[str, Path], trust_remote_code: bool = True
) -> tuple[ModelType, TokenizerType]:
model_dir = _resolve_path(model_dir)
if (model_dir / 'adapter_config.json').exists():
model = AutoPeftModelForCausalLM.from_pretrained(
model_dir, trust_remote_code=trust_remote_code, device_map='auto'
)
tokenizer_dir = model.peft_config['default'].base_model_name_or_path
else:
model = AutoModelForCausalLM.from_pretrained(
model_dir, trust_remote_code=trust_remote_code, device_map='auto'
)
tokenizer_dir = model_dir
tokenizer = AutoTokenizer.from_pretrained(
tokenizer_dir, trust_remote_code=trust_remote_code
)
return model, tokenizer- 读取微调的模型,请注意,你应该使用微调模型的位置,例如,若你的模型位置为
/path/to/finetune_adapter_model,原始模型地址为path/to/base_model,则你应该使用/path/to/finetune_adapter_model作为model_dir。 - 完成上述操作后,就能正常使用微调的模型了,其他的调用方式没有变化。
GLM-4-9B的案例应用
持续更新中……



















 1556
1556

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言












{kind=link}
{kind=link}