







LLMs之RAG:RAGFlow(基于深度文档理解的开源 RAG 引擎)的简介、安装和使用方法、案例应用之详细攻略
目录
RAGFlow的简介
RAGFlow 是一个基于深度文档理解的开源检索增强生成 (RAG) 引擎。它提供了一个简化的 RAG 工作流程,适用于任何规模的企业,结合大型语言模型 (LLM) 提供可靠的问答能力,并从各种复杂格式的数据中提供有根据的引用。 RAGFlow 支持多种数据源,例如 Word、幻灯片、Excel、文本、图像、扫描件、结构化数据、网页等,并支持多种大型语言模型和嵌入模型。
0、最新更新日志
2025 年 2 月 5 日 更新了“SILICONFLOW”的模型列表,并增加了对 Deepseek-R1/DeepSeek-V3 的支持。
2025 年 1 月 26 日 优化了知识图谱的提取和应用,提供了多种配置选项。
2024 年 12 月 18 日 升级了 Deepdoc 中的文档布局分析模型。
2024 年 12 月 4 日 在知识库中增加了对 PageRank 分数的支持。
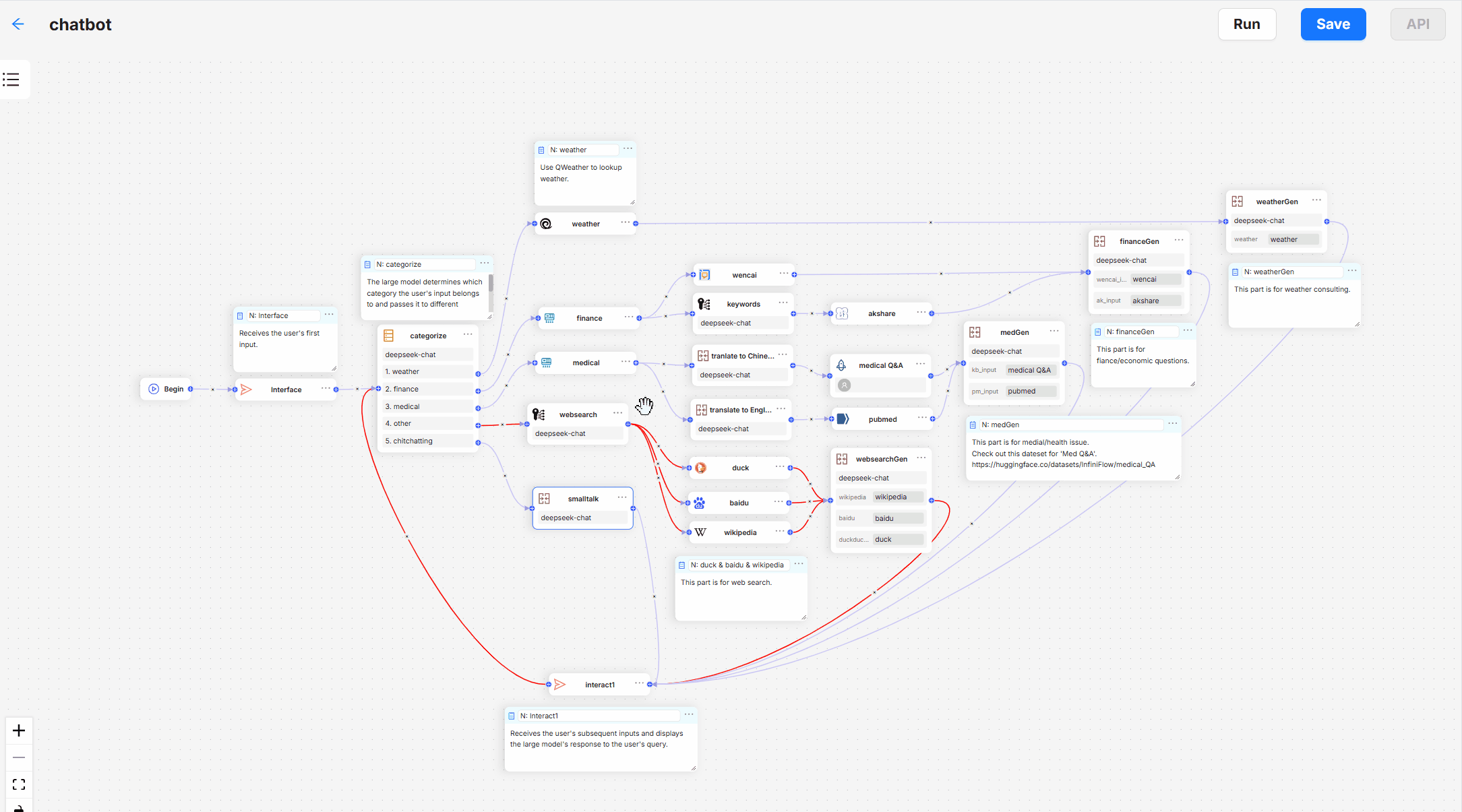
2024 年 11 月 22 日 向 Agent 增加了更多变量。
2024 年 11 月 1 日 在解析的片段中增加了关键词提取和相关问题生成,以提高检索的准确性。
2024 年 8 月 22 日 通过 RAG 支持文本到 SQL 语句的转换。
1、特点
>> 深度文档理解:基于深度文档理解技术,能够从复杂格式的非结构化数据中提取知识。 可以处理海量文本数据,找到“大海捞针”式的特定信息。
>> 模板化分块:使用模板化分块方法,提高效率并增强可解释性。 提供多种模板选项。
>> 可靠的引用和减少幻觉:通过可视化文本分块,允许人工干预。 提供关键参考和可追溯的引用,支持可靠的答案,减少模型幻觉。
>> 兼容异构数据源:支持多种数据源,包括 Word、幻灯片、Excel、文本、图像、扫描件、结构化数据、网页等。
>> 自动化和简化的 RAG 工作流程:简化了 RAG 的编排过程,适用于个人和大型企业。 支持配置 LLM 和嵌入模型,支持多种召回方法和融合重排序。 提供直观的 API,方便与业务系统集成。
>> 支持 Text-to-SQL:支持通过 RAG 将文本转换为 SQL 语句。
>> 知识图谱支持:支持知识图谱的提取和应用,并提供多种配置选项,包括pagerank评分。
2、系统架构
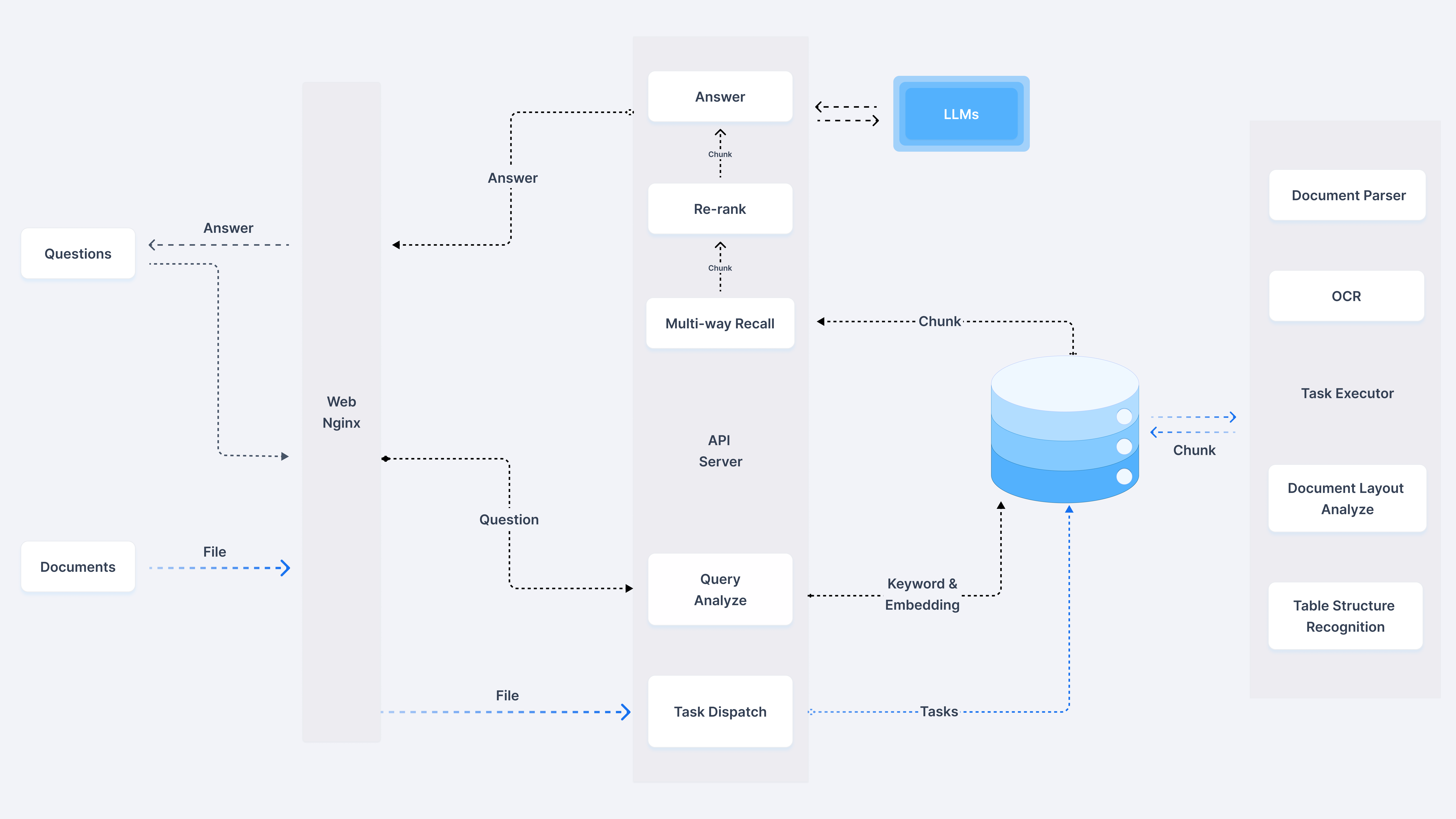
这张图片展示了一个智能文档处理和问题回答系统的流程图。系统的整体架构可以分为几个主要模块:
-
用户输入(问题与文档):用户可以输入问题或上传文档文件,文件被传输到系统中进行处理。
-
Web Nginx:此模块作为前端,负责接收用户的请求并将其转发到后端API服务进行进一步处理。
-
API服务器:这个模块是系统的核心,包含多个子模块:
- 多重召回(Multi-way Recall):根据用户问题从数据库中召回相关的文档或内容。
- 查询分析(Query Analyze):对用户输入的查询进行分析和处理。
- 任务调度(Task Dispatch):将分析的结果分发给不同的任务执行模块。
-
LLMs(大语言模型):对输入问题进行深度处理,并返回相应的答案。
-
文档处理模块:在系统的另一部分,文档通过文档解析器(Document Parser)、**OCR(光学字符识别)和任务执行器(Task Executor)**等模块进行解析和理解,完成对文件内容的提取和处理。
-
数据库与数据存储:文档数据和生成的“块(Chunk)”被存储在数据库中,并为后续查询提供支持。
通过这种架构,系统能够高效地处理用户问题,自动识别和解析文档中的内容,结合大语言模型生成精确答案。
RAGFlow的安装和使用方法:
1、安装
(1)、配置环境
CPU:4 核以上
RAM:16 GB 以上
磁盘空间:50 GB 以上
Docker:24.0.0 以上版本
Docker Compose:v2.26.1 以上版本
系统设置
检查并设置 vm.max_map_count 的值至少为 262144。 如果需要永久生效,请修改 /etc/sysctl.conf 文件。
克隆仓库
(2)、使用方法
T1、启动服务器 (使用预构建的 Docker 镜像)
进入 ragflow/docker 目录,使用 docker compose -f docker-compose.yml up -d 命令启动服务器。 可以选择不同的镜像版本(例如 v0.16.0 或 v0.16.0-slim),v0.16.0-slim 版本大小约为 2GB,不包含嵌入模型;v0.16.0 版本大小约为 9GB,包含嵌入模型。 nightly 版本为不稳定版本。
检查服务器状态:使用 docker logs -f ragflow-server 命令检查服务器状态。 成功启动后,将会显示启动信息。
配置
需要配置 .env 和 service_conf.yaml.template 文件。 .env 文件包含基本系统设置;service_conf.yaml.template 文件配置后端服务,启动 Docker 容器时会自动填充环境变量。 可以通过修改 docker-compose.yml 文件来更改默认的 HTTP 服务端口 (80)。 修改配置后需要重启容器。
切换文档引擎 (可选):默认使用 Elasticsearch 作为文档存储引擎,可以通过修改 .env 文件中的 DOC_ENGINE 变量为 infinity 来切换到 Infinity 引擎。 切换后需要删除 Docker 容器卷并重启容器。
T2、从源码启动服务 (开发环境)
安装 uv:pipx install uv
克隆代码并安装 Python 依赖项:uv sync --python 3.10 --all-extras
使用 Docker Compose 启动依赖服务 (MinIO, Elasticsearch, Redis, MySQL):docker compose -f docker/docker-compose-base.yml up -d
修改 /etc/hosts 文件,将 docker/.env 文件中指定的 host 解析到 127.0.0.1。
设置 HF_ENDPOINT 环境变量 (可选,用于访问 HuggingFace 镜像站点)。
启动后端服务:source .venv/bin/activate && export PYTHONPATH=$(pwd) && bash docker/launch_backend_service.sh
安装前端依赖项并启动前端服务。
2、使用方法
演示地址,用户可以在该地址体验 RAGFlow 的功能。
地址:RAGFlow
RAGFlow的案例应用
RAGFlow 可以应用于各种需要从大量文档中提取信息并进行问答的场景,例如:企业内部知识库构建、客户支持、文档检索、学术研究。
持续更新中……



















 1556
1556

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











