







介绍
行为决策理论是一个多学科交叉的研究领域。其主要内容是以决策者的决策行为作为出发点,研究决策者的认知过程,揭示决策者的判断和选择的原理解释,而非对决策对错的评价。从认知原理学的角度,研究决策者作决策过程中的信息处理机制及其所受的内外部环境影响。行为决策理论是探讨“人们实际是怎样进行决策”以及“为什么会这么决策”的理论。自20世纪70年代以来涌现了许多移动机器人的行为决策方法,包括多准则行为决策方法、马尔科夫决策方法、贝叶斯网络决策方法、模糊决策方法以及产生式规则决策方法等。从机器人学科了来看,自动驾驶车辆可以看到一种移动轮式机器人,因此移动机器人的行为决策方法也可以应用在自动驾驶中。为了实现在各种交通场景下的正常驾驶,自动驾驶车辆的行为决策子系统需要具备以下特性:
1. 合理性。
2. 实时性。
自动驾驶行为决策系统
行为决策子系统的目标是对可能出现的驾驶道路环境都给出一个合理的行为策略。行为决策系统在自动驾驶过程中要求的实时性非常高,如何快速给出决策结果是行为决策子系统必修要考虑的问题。行为决策系统根据环境的运动变化规律分场景的决策,不仅可以提高实时性,还能保证合理性。行为决策系统首先会分析道路结构环境,明确自身所处的驾驶场景。接着以此为基础,针对特定的驾驶场景,基于交通规则或驾驶经验所组成的驾驶先验知识,在多个可选行为中基于驾驶任务需求等要素条件,选择该场景下的最优驾驶行为。
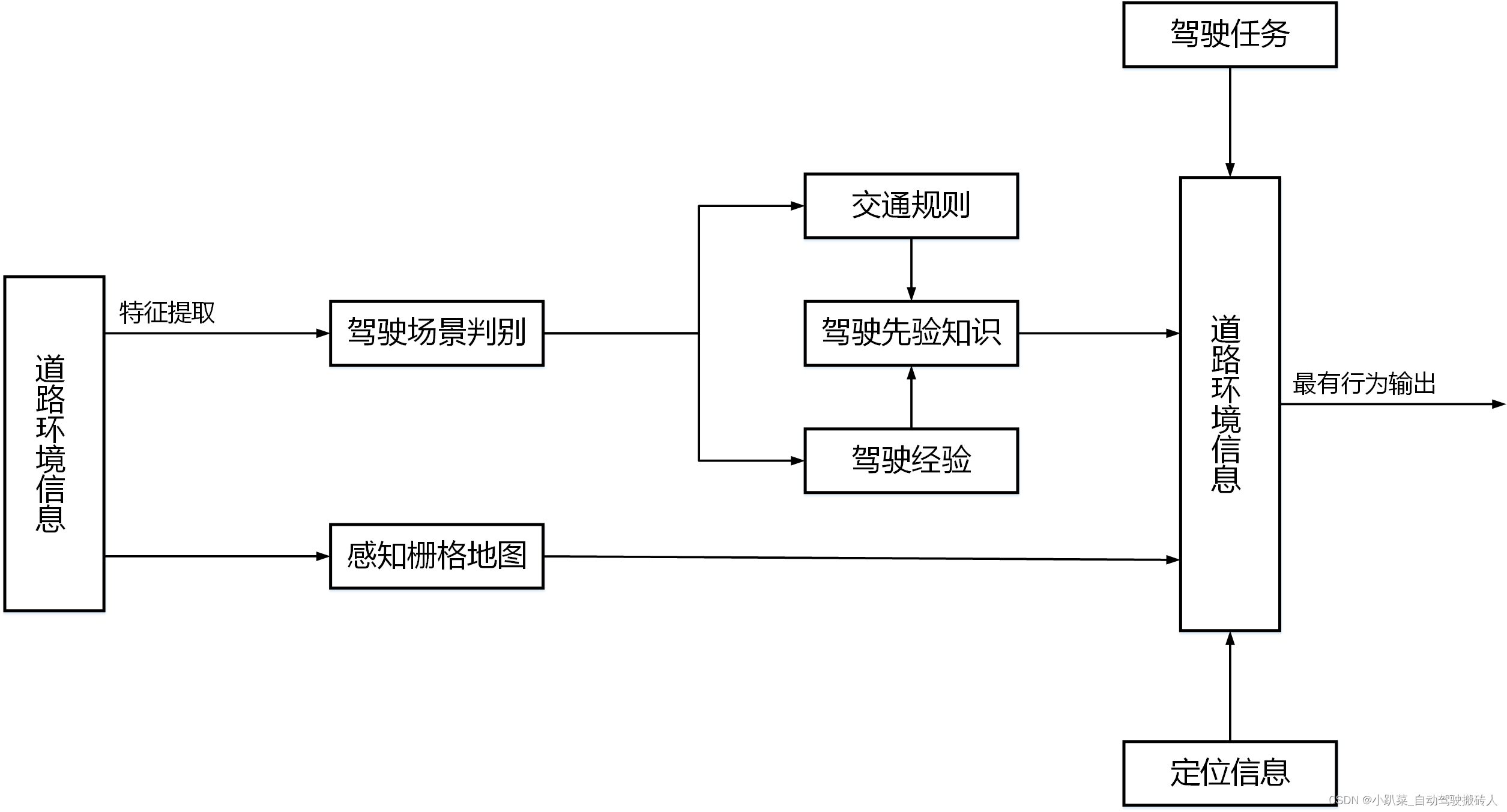
基于规则的行为决策
基于规则的行为决策的核心思想是利用分治的原则将自动驾驶车辆周边的场景进行划分。在每个场景中,独立运用对应的规则来计算自动驾驶车辆对每个场景中元素的决策行为,再将所有划分的场景的决策进行综合,得出一个最后综合的总体行为决定。我们首先需要先引入几个概念:综合决策(Synthetic Decision)、个体决策(Individual Decision)已经场景(Scenario)。
综合决策
综合决策代表自动驾驶车辆行为决策层的整体最高层的决策。作为最高层面的综合决策,其所决策的指令状态空间定义需要和下游的运动规划(Motion Planning)模块保持一致,这样计算得出的综合决策指令是下游可以直接用来执行从而规划出路线轨迹(Trajectory)的。为了便于下游直接执行,综合决策的指令集往往带有具体的指令参数数据。如下表。
| 综合决策指令集定义及其可能的参数 | |
|---|---|
| 综合决策的指令集定义 | 参数 |
| 行驶 | 当前车道 目标车速 |
| 跟车 | 当前车道 跟车对象 目标车速 跟车距离 |
| 转弯 | 当前车道 目标车道 转弯属性 转弯速度 |
| 变道 | 当前车道 变道车道 加速并道 减速并道 |
| 停车 | 当前车道 停车对象 停车位置 |
上表中列举了一些综合决策指令集定义及其可能的参数数据。例如,当综合决策是在当前车道跟车行驶,传给下游运动规划的不仅是跟车这一宏观指令,还包含如下参数数据:
1. 前方需要跟车的汽车ID(一般从感知输出获得);
2. 跟车需要保持的车速(当前车道限速和前车车速之间较小值);
3. 和前车保持的距离(例如前车尾部向后3m等)。
下游的运动规划模块基于宏观综合决定及其伴随指令传来的参数数据,结合地图信息(如车道形状)等,就可以直接规划出安全无碰撞的行驶路线。
个体决策
个体决策指的是对所有重要的行为决策层面的输入个体,都产生一个决策。这里的个体,可以是感知输出的车辆和行人,也可以是结合了地图元素的抽象个体(如红绿灯、人行横道对应的停止线等)。在场景划分的基础上产生每个场景下的个体决策,在综合考虑归纳这些个体决策,得到最终的综合决策。个体决策不仅是产生最后的综合决策的元素,也和综合决策一起被传递给下游运动规划模块。个体决策有利于下游路径规划模块的求解,还能帮助进行决策模块的调试。个体决策和综合决策相似的地方除了其指令集本身之外,个体决策同样带有参数数据。
场景
个体决策的产生依赖于场景的构建。这里可以将场景理解为一些列具有相对独立意义的车辆周边环境的划分。利用这种思想,可以将自动驾驶车辆行为决策层面汇集的周边不同类别的信息元素,聚类到不同的富有实际意义的场景实体中。在每个场景实体中,基于交通规则并结合车主的意图,可以计算出对于每个信息元素的个体决策,再通过一系列准则和必要的运算把这些个体决策最终综合输出给下游。场景定义是分层次的。每个层次中间的场景是互相独立构建的。其中,主车可以认为是最基本的底层场景,其他所有场景的构建都需要先以自动驾驶主车在哪里这一个基本场景为基础。

综上所述,每个场景模块李庸自身的业务逻辑来计算其不同元素个体的决策。通过场景的符合,以及最后对所有个体的综合决策考虑,自动驾驶车辆得到最终行为决策需要是最安全的决策。这里会产生一个问题 —— 会不会出现不同场景对同一物体通过各自独立的规则计算出矛盾的决策?从场景的划分来看,这本身来讲就避免了同一物体出现在不同的场景里。倘若出现了这个问题,上述的系统框架的中间层也会对所有的个体决策进行汇总和安全无碰撞的验证。
马尔可夫决策过程
一个马尔可夫决策过程,有下面的五元组定义:(S,A,T,R,γ)
1. S —— 代表了自动驾驶车辆所处的有限的状态空间。状态空间的划分可以结合自动驾驶车辆当前位置机器在地图上的场景进行设计。
2. A —— 代表了自动驾驶车辆的行为决策空间,即自动驾驶车辆在任何状态下的所有行为空间的集合。
3. T —— 状态转移函数。 T ( s , s ′ ) = P ( s ′ ∣ s , a ) T(s,s')=P(s' | s,a) T(s,s′)=P(s′∣s,a) 是一个条件概率,代表了自动驾驶车辆在状态s和动作a下,到达下一个状态s’ 的概率。
4. R —— 激励函数。 R a ( s , s ′ ) R_a(s,s') Ra(s,s′) 代表了自动驾驶车辆在动作a下,从状态s到状态s’所得到的激励。该激励函数可以考虑安全性、舒适性、可通行性、到达目的地能力,以及下游运动规划执行难度等因素综合设计。
5. γ —— γ ∈ ( 0 , 1 ) \gamma \in (0, 1) γ∈(0,1) 是激励的衰减因子,下一个时刻的激励便按照这个因子进行衰减,在任何一个时间,当前的激励系数为1,下一个时刻的激励系数为γ1,下两个时刻的激励系数为γ2,以此类推。其含义是当前的激励总是比未来的激励重要。
自动驾驶行为决策层面需要解决的问题可以正式描述为在马尔可夫决策过程(MDP)定义下的寻找一个最优解。在任意给定的状态s下,策略会决定产生一个对应的行为。当策略确定后,整个MDP的行为可以看成是一个马尔可夫链。行为决策的策略的选取目标是优化从当前时间点开始到未来的累积激励(如果激励是随机变量,则优化累积激励的期望):
∑ t = 0 ∞ γ t R a t (
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1299
1299

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











