








一、混淆矩阵
对于二分类的模型,预测结果与实际结果分别可以取0和1。我们用N和P代替0和1,T和F表示预测正确和错误。将他们两两组合,就形成了下图所示的混淆矩阵(注意:组合结果都是针对预测结果而言的)。
由于1和0是数字,阅读性不好,所以我们分别用P和N表示1和0两种结果。变换之后为PP,PN,NP,NN,阅读性也很差,我并不能轻易地看出来预测的正确性与否。因此,为了能够更清楚地分辨各种预测情况是否正确,我们将其中一个符号修改为T和F,以便于分辨出结果。

- P(Positive):代表 1
- N(Negative):代表 0
- T(True):代表预测正确
- F(False):代表预测错误
二、准确率、精确率、召回率、F1-Measure
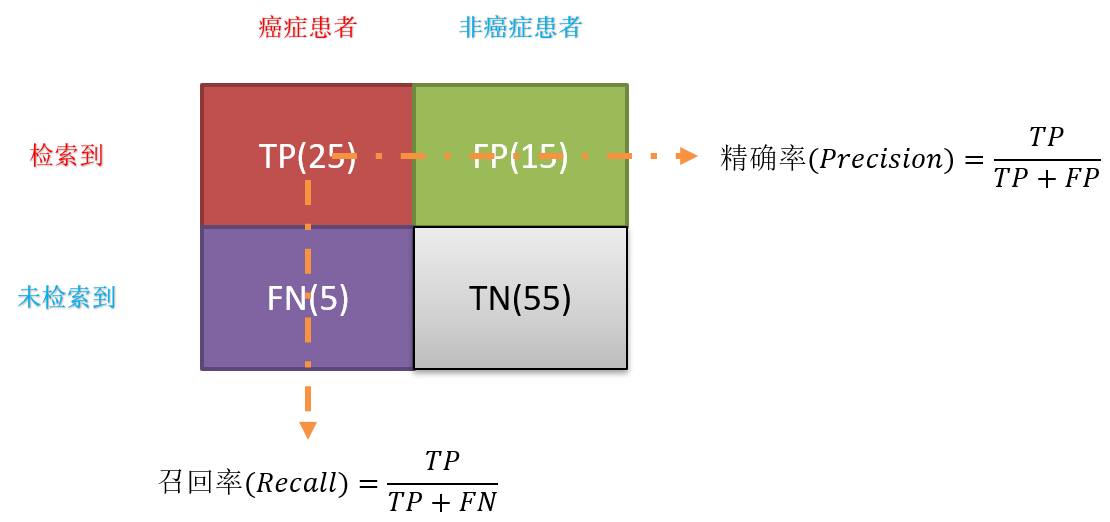
- 准确率(Accuracy):对于给定的测试数据集,分类器正确分类的样本数与总样本数之比。
A c c u r a c y = T P + T N T P + T N + F P + F N = T P + T N 总 样 本 数 量 Accuracy=\cfrac{TP+TN}{TP+TN+FP+FN}=\cfrac{TP+TN}{总样本数量} Accuracy=TP+TN+FP+FNTP+TN=总样本数量TP+TN - 精确率(Precision)**:精指分类正确的正样本个数(TP)占分类器判定为正样本的样本个数(TP+FP)的比例。
P r e c i s i o n = T P T P + F P = 分 类 正 确 的 正 样 本 个 数 判 定 为 正 样 本 的 样 本 个 数 Precision=\cfrac{TP}{TP+FP}=\cfrac{分类正确的正样本个数}{判定为正样本的样本个数} Precision=TP+FPTP=判定为正样本的样本个数分类正确的正样本个数 - 召回率(Recall):召回率是指分类正确的正样本个数(TP)占真正的正样本个数(TP+FN)的比例。
R e c a l l = T P T P + F N = 分 类 正 确 的 正 样 本 个 数 全 部 真 正 的 正 样 本 个 数 Recall=\cfrac{TP}{TP+FN}=\cfrac{分类正确的正样本个数}{全部真正的正样本个数} Recall=TP+FNTP=全部真正的正样本个数分类正确的正样本个数 - F1-Measure值:就是精确率和召回率的调和平均值。
F 1 − M e a s u r e = 2 1 P r e c i s i o n + 1 R e c a l l = 2 × P r e c i s i o n × R e c a l l P r e c i s i o n + R e c a l l \begin{aligned}F1-Measure=\cfrac{2}{\cfrac{1}{Precision}+\cfrac{1}{Recall}}=\cfrac{2×Precision×Recall}{Precision+Recall}\end{aligned} F1−Measure=Precision1+Recall12=Precision+Recall2×Precision×Recall
每个评估指标都有其价值,但如果只从单一的评估指标出发去评估模型,往往会得出片面甚至错误的结论;只有通过一组互补的指标去评估模型,才能更好地发现并解决模型存在的问题,从而更好地解决实际业务场景中遇到的问题。
参考资料:
二分类问题常见的评价指标














 928
928











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









