







 FCN网络作为深度学习图像分割的开创者,实现了图像语义分割的端到端预测。其核心在于将全连接层替换为卷积层,引入上采样层恢复图像尺寸,以及创新的跳跃结构提升分割精度。
FCN网络作为深度学习图像分割的开创者,实现了图像语义分割的端到端预测。其核心在于将全连接层替换为卷积层,引入上采样层恢复图像尺寸,以及创新的跳跃结构提升分割精度。
FCN网络是深度学习图像分割领域的奠基之作,有着极大的意义.今天就来简单介绍一下FCN全卷积网络。
这篇论文的标题为"Fully Convolutional Networks for Semantic Segmentation",也就是全卷积网络应用于语义分割.传统的分类卷积神经网络,如AlexNet,VGG等都是输入一幅图像,输出图像所属类别的概率,因此为对整幅图像的类别的预测.而本文中的FCN全卷积网络则适用于图像语义分割,即输入一幅图像,输出仍然为一幅图像,只是分割出原图像中需要的类别.这样就不能再使用传统的分类模型了.下面将具体介绍一下FCN全卷积网络.
1.语义分割和密集预测
密集预测是一种基于密集像素的图像处理任务,具体的有语义分割,边界预测,图像复原,图像定位等任务.这些任务与图像分类任务最明显的区别就在于,他们需要对整幅图像中的每一个像素点进行操作,因此是一种密集预测.
FCN模型要解决的问题是图像语义分割.它是一种端到端,像素到像素的预测任务,要求输入原始图像,输出图像中对应类别的分割图.
2.FCN模型介绍
FCN网络沿用了VGG分类网络的前几层,并将最后的三层全连接层替换为相应的卷积层,并在网络的最后添加了上采样层(upsampling layer),将图像复原到原先的尺寸.网络的简单结构示意图如图所示:
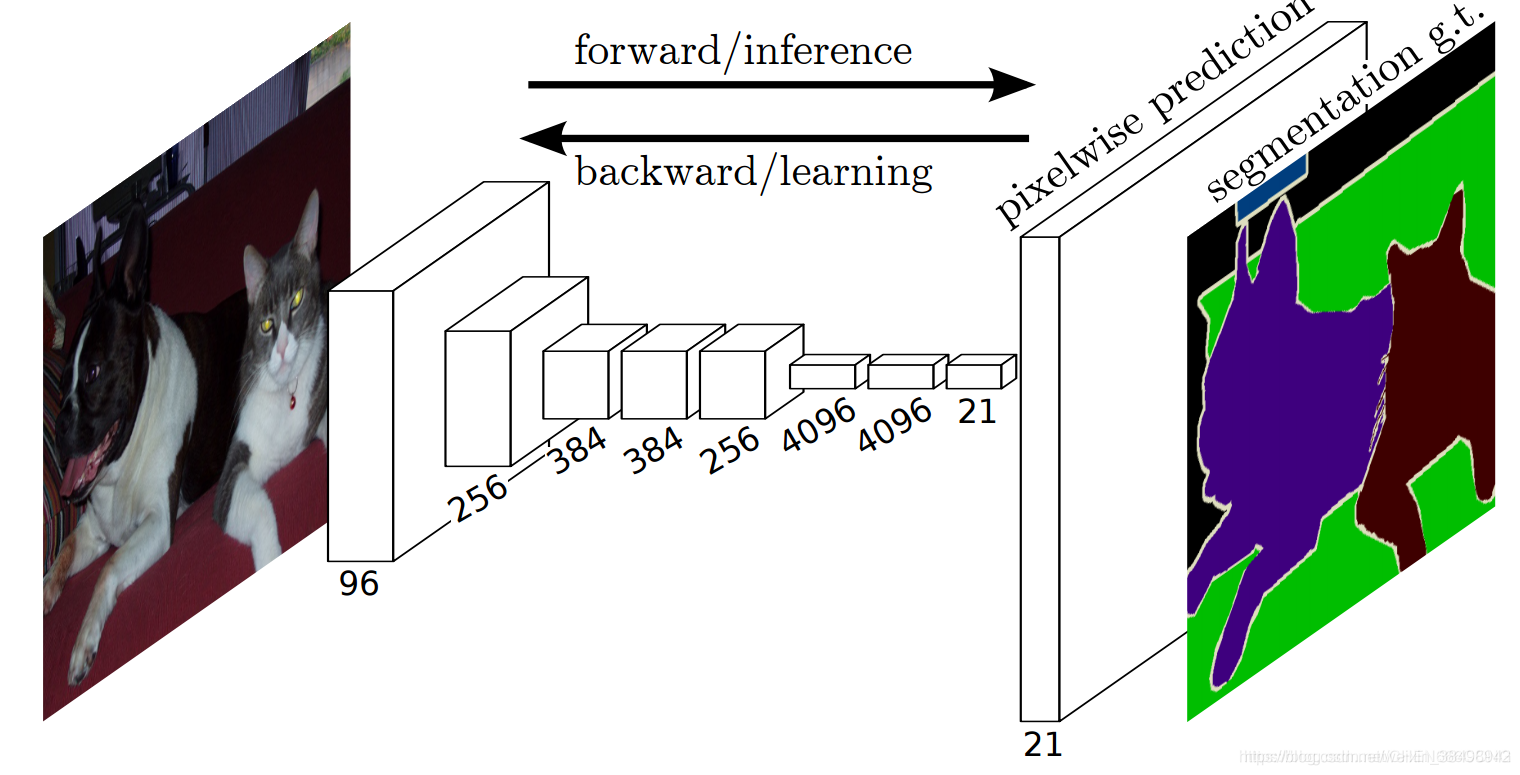
上图仅仅是FCN-32s的示意图,另外的FCN-16s和FCN-8s中包含有跳跃结构,后面将具体解释.
全卷积网络:
正如这篇论文标题所说的,FCN模型的最大的特点就在于使用了全卷积网络.在传统的分类任务中,无论网络前段使用什么样的结构,最后都会接着两层或者三层全连接层,即将卷积得到的三维特征图拉直为一维向量,通过全连接层进行概率预测.在FCN模型中,完全抛弃了全连接层,并且全部用卷积层替代,从头到尾的进行卷积操作.最后将会得到一个三维的特征图,这个特征图的每一个channel的特征图代表一个类别的分数,以此进行预测.具体结构如下:
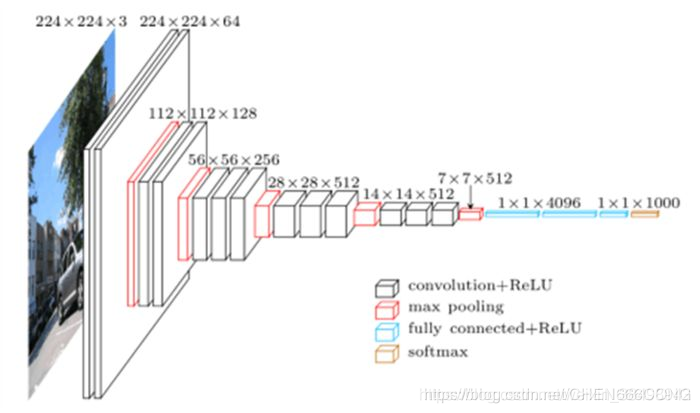
全卷积神经网络的主要优点在于可以输入任意大小的图像。
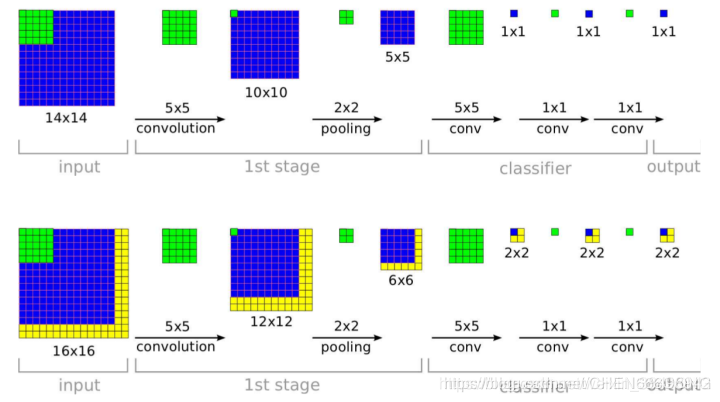
在一个卷积神经网络中,可以很明显的看到卷积层是与输入图像的大小没有关系的,即无论图像多大,都可以进行卷积操作,只是卷积层输出的特征图大小不同.在卷积神经网络中,真正限制输入图像大小的是最后的全连接层神经元数,因为全连接层单元数必须与最后一层卷积的输出特征图相匹配(否则会造成全连接层权值参数个数不一致).使用全卷积网络使用卷积层替换全连接层,这样就没有全连接层单元数的限制,因此可以输入任意大小的图像(至少要大于224X224).
当输入不同大小的图像时全卷积网络将会产生不同大小的输出特征图,例如输入224X224的图像,则输出特征图为1X1X1000,输入512X512的图像,则输出特征图为16X16X1000.
另外,全卷积网络输出三维特征图,保留了原始图像中的坐标信息,这是全连接层所不具备的.
上采样方法
论文中提出了上采样方法,即整个FCN网络模型的最后一层上采样层(FCN-32s).在通过整个全卷积网络之后,原始图像被提炼为m∗n∗1000mn1000m∗n∗1000的特征图,里面包含着整幅图像的高级特征,并且能够预测图像类别.最后还需要添加一个上采样层,将提炼得到的特征图反卷积为原始图像大小,并显示分割图像.
上采样可以看做是卷积和池化的逆操作.因子为fff的上采样可以看做是对原始图像的步长为1/f1/f1/f的卷积,当fff为整数的时候,也可以看做是对输出图像的步长为fff反卷积操作.
反卷积(deconvolution)有很多种方法,插值法,转置卷积法等都是经典的反卷积方法,本文中采用的是双线性插值.双线性插值的基本思想就是根据与像素点相邻的四个像素点进行x,y两个方向的线性插值,从而得到该像素点的预测值.
跳跃结构
该论文中的另一个创新点在于使用了跳跃结构.如下图所示:
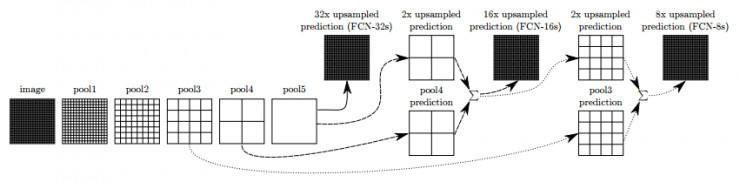
未使用跳跃结构的模型为FCN-32s,它直接将最后一层池化的特征图进行反卷积得到分割图像.原始图像经过FCN模型中的5次池化,图像大小压缩为原来的1/321/321/32,因此FCN-32s模型中的最后一层直接对它进行了因子fff为32的上采样操作,由于上采样倍数过大,输出图像完全无法体现出原始图像的细节,是的结果非常差.在FCN-16s和FCN-8s中使用了跳跃结构如上图所示,FCN-16s模型将第四次池化后的特征图与第五次池化后的特征图结合,既保留了图像的高阶特征,又不会损失过多的图像细节,得到的分割结果明显好于FCN-32s.FCN-8s模型与FCN-16s模型类似.
以FCN-16s模型为例,具体的融合过程为:首先对最后一个池化后的特征图进行因子为2的上采样操作,转化为2X2的图像,然后再与第四次池化后的2X2的特征图相叠加,最后对叠加后的结果进行因子为16的上采样操作.
shift and stitch
要从粗糙的原始图像上采样得到密集预测,文中提出了shift and stitch方法,但是最后的FCN模型中似乎没有使用该方法。shift and stitch的主要思想是对原始图像进行多层次平移池化,即原始图像产生多套池化特征图,最后上采样的时候可以根据多个池化特征图精准的复原图像。具体操作是,设降采样因子为f,把输入图像向右平移x个像素,向下平移y个像素,x,y分别从0~f,产生f2f^2f 2 个版本的池化特征图,理论上这些特征图的总和包含原始图像的全部信息,没有因为池化而损失信息。把这f2f^2f 2 个版本的特征图连接起来(stitch),就是上采样过程。
我认为作者在最终的模型中并没有使用该方法,可能是由于每次池化都需要将原图像分裂为f2f^2f 2 池化特征图,经过多次池化过程,实际上神经网络会变得非常大,计算效率不高。经过实验可以学习的跨层融合的上采样过程效果更好效率都更加高效。
patchwise training
实际上我也完全没看懂patchwise training是什么意思,可能在以前的语义分割中用的较多,具体的一个patch训练与一张图片训练有什么区别,我还有待研究。。。
3.训练过程
和其他分割网络模型相同,FCN模型损失函数为像素级的交叉熵损失函数也采用了动量的随机梯度下降优化算法。FCN的前半部分网络是基于VGG的卷积层,因此直接引用VGG网络的权值参数作为FCN的预训练参数。然后再进行微调。

















 2732
2732

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









