






ORT - QNN EP
本节演示了如何使用ONNX Runtime (ORT) 和QNN作为执行提供者(EP)来加速在专门设计用于处理神经网络的Hexagon Tensor Processor (HTP)上的工作负载。QNN EP还提供了一个CPU后端,可用于在高通 Oryon™ CPU上以FP32精度运行AI工作负载。
安装
以管理员模式打开PowerShell,并运行以下命令以安装依赖项。此设置是教程所需,约需2-5分钟。有关设置的更多详细信息,请参见ort_setup.ps1。
-
运行以下命令以下载设置脚本。如果您已经下载过,可以跳过到第2步。
Invoke-WebRequest -O ort_setup.ps1 https://raw.githubusercontent.com/quic/wos-ai/refs/heads/main/Scripts/ort_setup.ps1 -
运行以下命令以安装QNN EP的依赖项。
设置$DIR_PATH(默认为C:\WoS_AI),用户可以更改为所需路径。
$DIR_PATH = "C:\WoS_AI"ORT-QNN安装:
powershell -command "&{. .\ort_setup.ps1; ORT_QNN_Setup -rootDirPath $DIR_PATH}"以下依赖项将被下载和安装:
- Python amd64版本 3.12.6
- 模型工件包括mobilenet_v2.onnx模型和用于预处理/后处理的io_utils.py。
- Visual Studio Redistributable版本 14.40.33816
- 创建一个虚拟环境(SDX_ORT_QNN_ENV),其中包含QNN EP所需的库。
- onnxruntime-qnn版本 1.20.0
-
设置完成后,$DIR_PATH中的文件夹结构如下所示:

- Downloads: 此文件夹存储完成设置所需的所有文件,例如Python安装程序、设置脚本等。
- Python_Env: 此目录包含为EP创建的虚拟环境。
- Debug_Logs: 此目录包含与设置相关的日志。
- Models: 此目录保存模型子目录及其相应的工件(例如:Mobilenet_v2)。
ORT QNN教程
本教程描述了如何使用ORT QNN EP在HTP/CPU后端运行分类模型(Mobilenet_v2)。
-
打开PowerShell并运行以下命令以设置DIR_PATH并激活Python虚拟环境。确保DIR_PATH与安装期间使用的路径相同。
${DIR_PATH} = "C:\WoS_AI"powershell -NoExit -command "&{cd $DIR_PATH; . .\Downloads\Setup_Scripts\ort_setup.ps1; Activate_ORT_QNN_VENV -rootDirPath $DIR_PATH}" -
运行以下命令在工作目录中创建ort_htp.py文件。
notepad.exe ort_htp.py -
将以下代码复制到ort_htp.py文件中并保存。此示例适用于Mobilenet模型。如果您需要尝试同样的示例,但使用不同的模型,请使用现有的Python虚拟环境(SDX_ORT_QNN_ENV)并通过提供绝对路径来处理依赖项。
# File_name : ort_htp.py import onnxruntime as ort import numpy as np # Qualcomm utility for pre-/postprocessing of input/outputs in model inference import io_utils # Step1: Runtime and model initialization # Set QNN Execution Provider options. execution_provider_option = { "backend_path": r"QnnHtp.dll", "enable_htp_fp16_precision": "1", "htp_performance_mode": "high_performance" } # Create ONNX Runtime session. onnx_model_path = "./mobilenet_v2.onnx" session = ort.InferenceSession(onnx_model_path, providers=["QNNExecutionProvider"], provider_options=[execution_provider_option]) # Step2: Input/Output handling, Generate raw input # github repo for below artifact: https://github.com/quic/wos-ai/tree/main/Artifacts img_path = "https://raw.githubusercontent.com/quic/wos-ai/refs/heads/main/Artifacts/kitten.jpg" raw_img = io_utils.preprocess(img_path) # Model input and output names outputs = session.get_outputs()[0].name inputs = session.get_inputs()[0].name # Step3: Model inferencing using preprocessed input. prediction = session.run([outputs], {inputs: raw_img}) # Step4: Output postprocessing io_utils.postprocess(prediction)注意:
若要在CPU后端运行ONNX模型,请将上述步骤中的execution_provider_option更改为 CPU,如下所示:
execution_provider_option = {"backend_path": "${DIR_PATH}\QnnCpu.dll"} -
从工作目录执行ort_htp.py Python脚本。
python .\ort_htp.py此脚本使用Python实用程序根据模型的要求预处理指定的.jpg图像,并将其发送到QNN EP进行推理。然后处理来自QNN EP推理的结果,以显示识别对象的类别和概率,如下例所示。
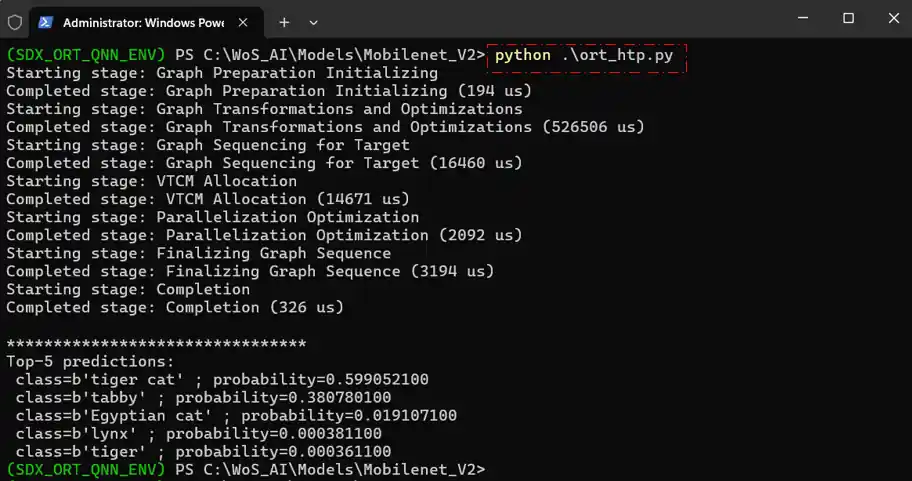
根据上图中的推理结果,模型识别出输入图像中的“虎猫”,概率分数约为59%。
后续步骤
现在您已经知道如何使用QNN EP运行模型,请返回ONNX Runtime,或继续下一部分尝试使用HuggingFace Optimum + ONNX RT进行模型推理。
更多详细信息
常见问题解答
-
支持哪个Python版本?
- ONNX Runtime QNN EP需要Python amd64版本3.8.10到3.12.x。
- 我们已经使用python-3.12.6-amd64验证了教程示例。
- ONNX Runtime QNN EP需要Python arm64版本3.11.x到3.12.x。
- 要在arm64上使用ORT QNN EP,建议创建两个Python环境:一个使用Python
amd64用于预处理和后处理,另一个使用Python ARM进行执行。 - 请注意,Python arm64在一些依赖项(如Torch、ONNX和其他Python包)方面有一些限制。
- 要在arm64上使用ORT QNN EP,建议创建两个Python环境:一个使用Python
- ONNX Runtime QNN EP需要Python amd64版本3.8.10到3.12.x。
-
如何使用C/C++运行推理?
- 使用此示例通过C/C++运行推理。
-
如何使用ORT-QNN EP运行其他模型?
以下是示例代码:python import onnxruntime as ort import numpy as np # Step1: Runtime and model initialization # Enter path to the model in the below onnx_model_path = "path/to/model" # Set QNN Execution Provider options. execution_provider_option = { "backend_path": r"QnnHtp.dll", "enable_htp_fp16_precision": "1", "htp_performance_mode": "high_performance" } # Step2: Input/Output handling, Generate raw input input_shape = session.get_inputs()[0].shape input_data = np.random.random(input_shape).astype(np.float32) # Model input name input_name = session.get_inputs()[0].name # Step3: Model inferencing using preprocessed input. result = session.run(None, {input_name: input_data})

















 1120
1120

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









