






高通 AI Engine Direct SDK(也称为 QNN SDK)提供底层 API,旨在实现高通 平台上 AI 工作负载的最佳性能。QNN SDK 支持 PyTorch、TensorFlow 和 Onnx 等框架的模型。QNN SDK 提供离线工具,用于在高通 硬件上加速转换、量化、优化和部署模型。
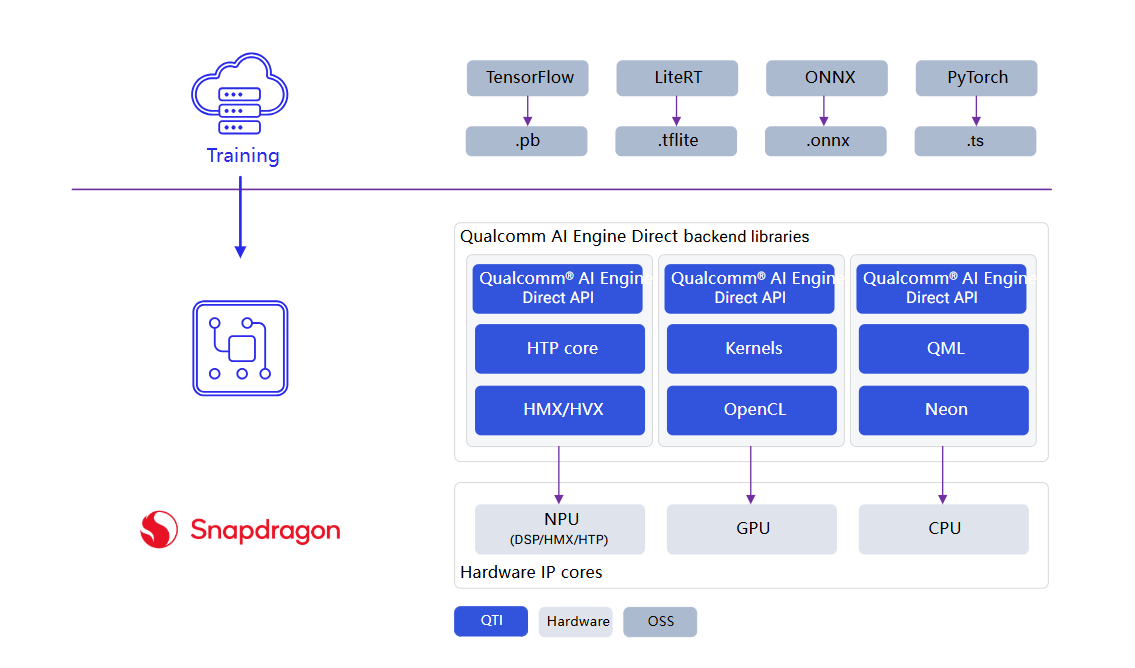
高通 AI Engine Direct SDK 需要 Ubuntu 22.04 主机。
高通 AI Engine Direct SDK 工作流已在运行 Ubuntu 22.04 的情况下进行了验证 在裸机上或虚拟机内,采用以下配置。
| 下载方法 | 先决条件 | 可用版本 |
|---|---|---|
| 直接下载 | 下载无先决条件。 | 2.26.2 版(SDK 每季度更新一次) |
| 高通封装 管理器 | 需要有效的 高通 ID。 高通 Package Manager 工具。 | SDK 每月更新一次。 |
直接下载
AI Engine Direct SDK 可在此处直接下载。下载后,解压缩 包。
unzip v2.26.2.240911.zip
cd qairt/2.26.2.240911/
export SNPE_ROOT=`pwd`高通 Package Manager
AI Engine Direct SDK 可通过 高通 Package Manager (QPM) 下载。 本节演示如何使用 QPM 下载 AI Engine Direct SDK。
- 转到 高通 并使用您的 高通 ID。
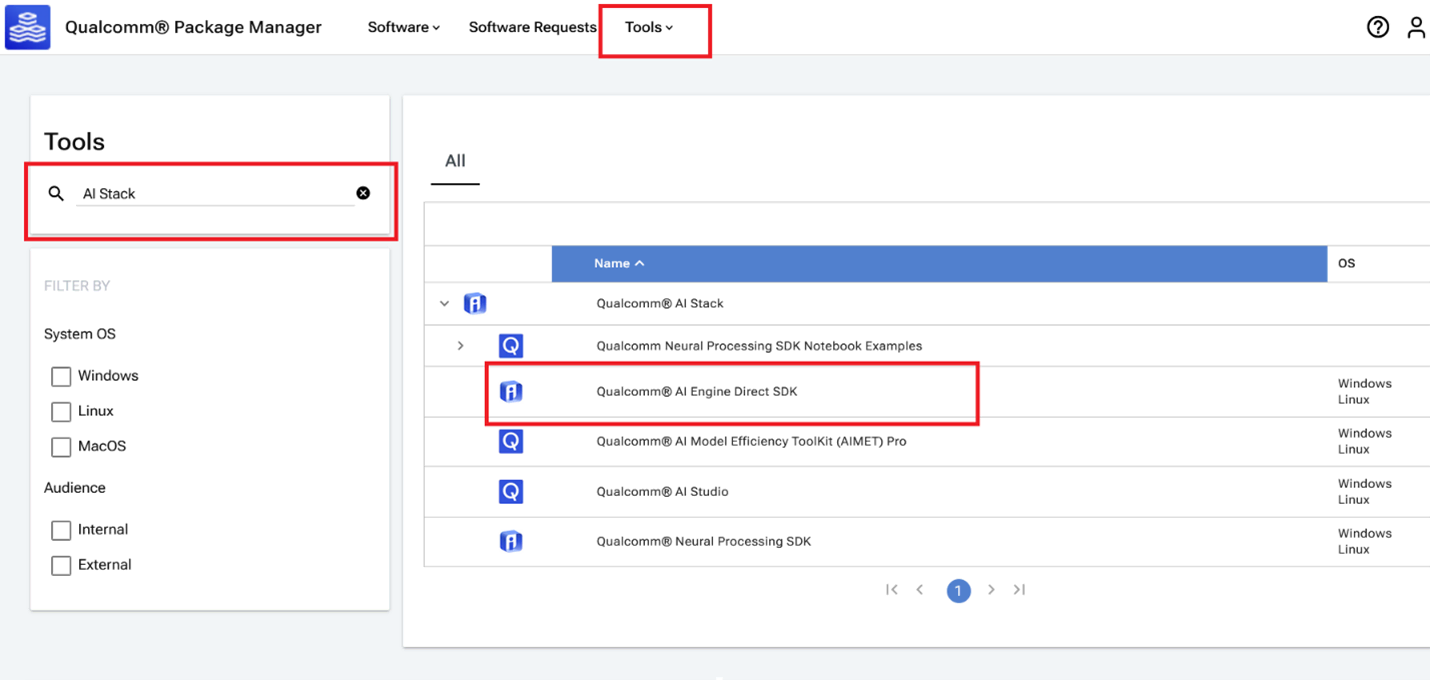
-
单击 AI Engine Direct SDK 导航到下一页。从下拉列表中选择 Linux 和版本 2.26.2.240911 ,然后单击 下载 以下载 AI Engine Direct SDK 安装。
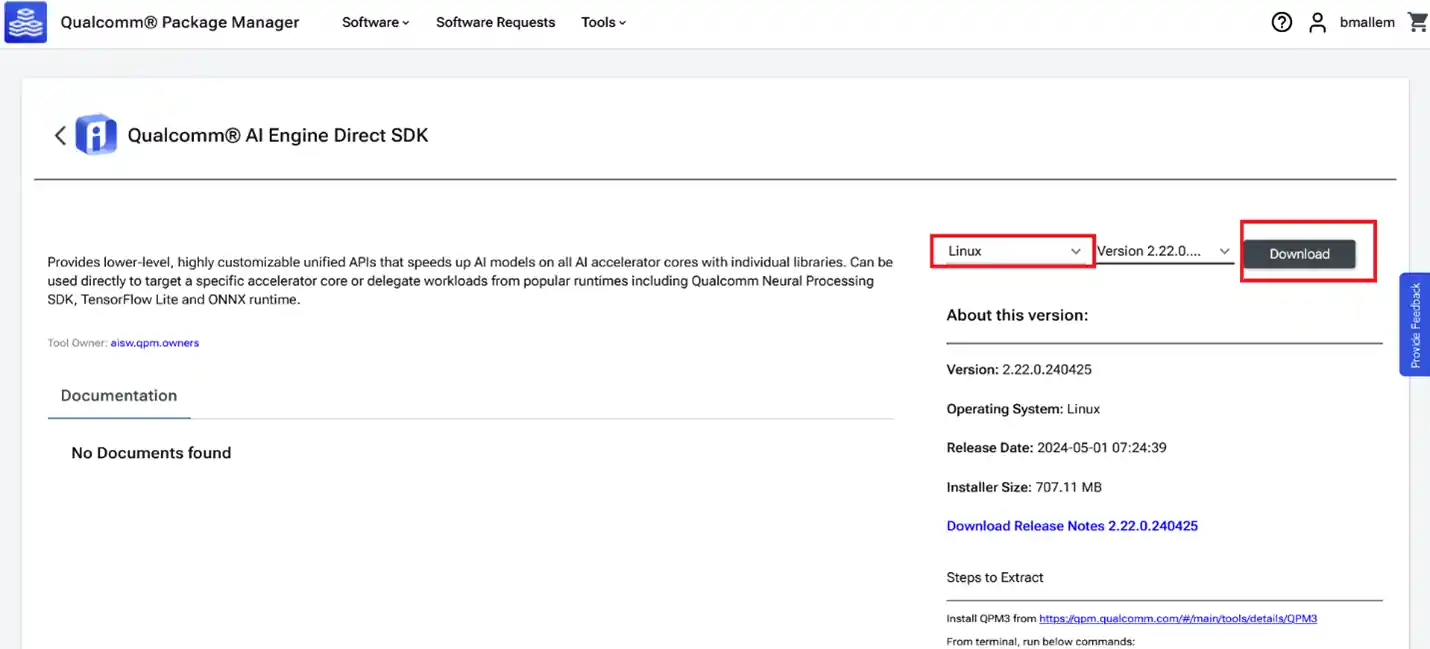 注意
注意- 这些屏幕截图使用版本 2.22.6.240515 作为示例,但用户应下载 版本 2.26.2.240911。
- 如果使用 高通 Package Manager 桌面工具,则会显示 Extract 按钮而不是 download。这 自动安装 QNN SDK。
- 使用 QPM CLI 工具安装下载的安装程序 (.qik)。
- 使用 QPM CLI 登录。
qpm-cli --login <username>
- 激活您的 SDK 许可证。
qpm-cli --license-activate qualcomm_ai_engine_direct
- 提取并安装 SDK。
qpm-cli --extract <path to downloaded .qik file>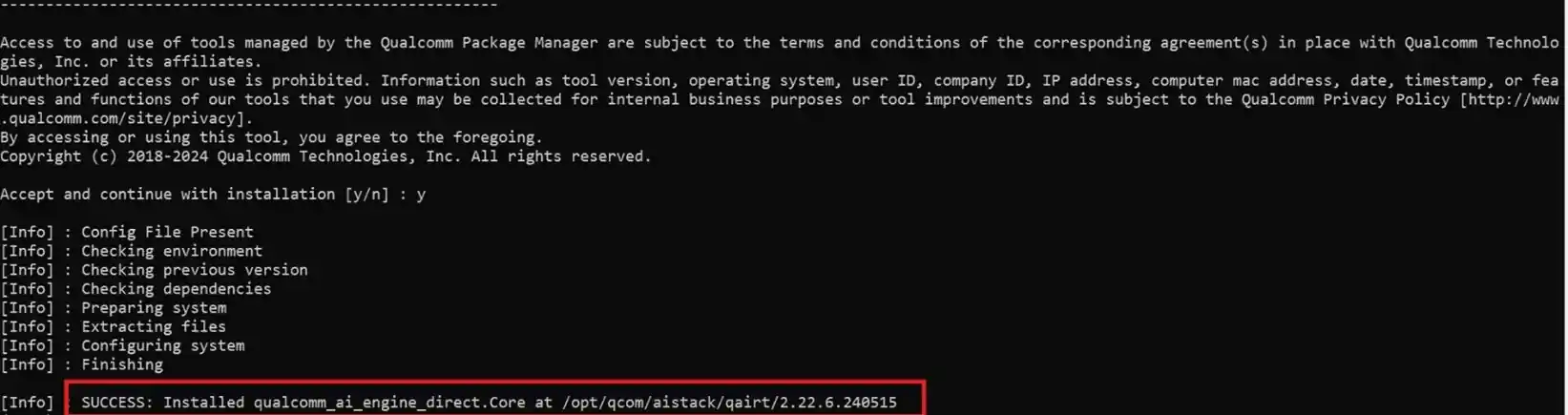
- 使用 QPM CLI 登录。
设置 SDK
要使用 AI Engine Direct SDK,以下 Ubuntu OS 和 Python 版本是 必填:
- Ubuntu 22.04 版本
- Python 3.10 版
有关详细设置,请参阅 AI Engine Direct SDK 设置 指示。
${QNN_SDK_ROOT}指已安装的 AI Engine Direct SDK 根 路径。
- 如果通过直接下载方式下载,请设置为已下载并解压的 SDK 根目录 目录。
${QNN_SDK_ROOT} - 如果通过 QPM 安装,则根目录路径为 /opt/qcom/aistack/qairt/<version>。这 示例使用版本 2.26.2.240911,因此路径为:/opt/qcom/aistack/qairt/2.26.2.240911。
SDK 设置步骤如下:
- 安装 Linux 平台依赖项
- 使用 安装 Python 依赖项
${QNN_SDK_ROOT}/bin/check-python-dependency - 安装 Ubuntu 软件包
sudo bash ${QNN_SDK_ROOT}/bin/check-linux-dependency.sh - 安装模型所需的 ML 框架(PyTorch、TensorFlow、ONNX)。 有关支持的版本,请参阅框架。
框架 版本 TensorFlow 2.10.1 版 TFLite 2.3.0 版 PyTorch 插件 1.13.1 版 ONNX 1.12.0 版 # Install tensorflow pip install tensorflow==2.10.1 # Install tflite pip install tflite==2.3.0 # Install PyTorch pip install torch==1.13.1+cpu torchvision==0.14.1+cpu torchaudio==0.13.1 --extra-index-url https://download.pytorch.org/whl/cpu # Install Onnx pip install onnx==1.12.0 onnxruntime==1.17.1 onnxsim==0.4.36
设置环境
获取 QNN SDK 提供的环境设置脚本,以确保使用所有必要的工具 和 库 可用于工作流。$PATH
source ${QNN_SDK_ROOT}/bin/envsetup.shModel conversion 和 量化
来自 PyTorch、Onnx、TensorFlow 或 LiteRT 是 QNN 转换器工具的输入,用于转换为 QNN 图 以高级可读 C++ 图形的形式表示。qnn-<framework>-converter
要启用量化以及 conversion 中,使用 static 的选项 量化。 --input_list INPUT_LIST
有关更多信息,请参阅量化支持文档。
以下示例使用 ONNX 模型 (inception_v3_opset16.onnx) 从 ONNX Model Zoo 下载。下载模型作为您的工作区。在此示例中,我们 将模型下载到 目录。inception_v3.onnx ~/models
仅模型转换(适用于 CPU 后端)
Model conversion 和 量化(用于 HTP 后端)
要将模型转换为在 x86/Arm CPU 上运行,请运行 以下命令生成 inception_v3.cpp 和 inception_v3.bin
python ${QNN_SDK_ROOT}/bin/x86_64-linux-clang/qnn-onnx-converter --input_network ~/models/inception_v3.onnx --output_path ~/models/inception_v3.cpp --input_dim 'x' 1,3,299,299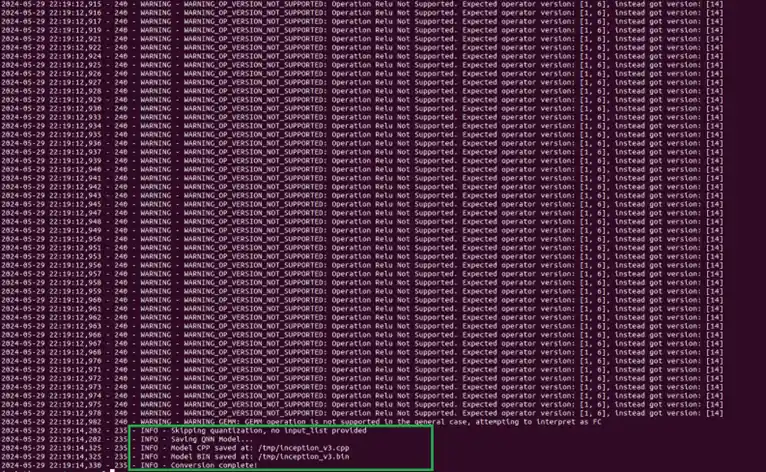
inception_v3.cpp 文件 包含已转换模型的高级图形表示。这 inception_v3.bin 文件包含来自模型的权重/偏差。
模型转换和量化(适用于 HTP 后端)
要在 HTP,则需要量化步骤。对于 AI Engine Direct (QNN) 中的量化 SDK 是来自训练数据集的 50 到 200 张图像的代表性数据集 作为校准数据集提供给 QNN 转换器。“中 校准数据集经过预处理(调整大小、标准化等)并保存为 NumPy 数组.raw。这些 Input .raw 文件的大小必须与 Input Size 匹配 的模型。
出于演示目的,我们 可以使用随机输入文件评估量化过程。输入文件可以 使用下面显示的 Python 脚本为模型生成。将脚本另存为 ~并使用 .inception_v3.onnx generate_random_input.py /models python ~/models/generate_random_input.py
以下 Python 代码 创建一个包含校准数据集的input_list,该数据集用于量化 型。
import os
import numpy as np
input_path_list =[]
BASE_PATH = "/tmp/RandomInputsForInceptionV3"
if not os.path.exists(BASE_PATH):
os.mkdir(BASE_PATH)
# generate 10 random inputs and save as raw
NUM_IMAGES = 10
#binary files
for img in range(NUM_IMAGES):
filename = "input_{}.raw".format(img)
randomTensor = np.random.random((1, 299, 299, 3)).astype(np.float32)
filename = os.path.join(BASE_PATH, filename)
randomTensor.tofile(filename)
input_path_list.append(filename)
#for saving as input_list text
with open("~/models/input_list.txt", "w") as f:
for path in input_path_list:
f.write(path)
f.write("\n")我们现在可以运行以下命令来转换 和 quantize 进行量化。默认情况下,模型针对 INT8 位宽进行量化。您可以指定和/或 for using INT16 量化。[--act_bw 16][--weight_bw 16]
${QNN_SDK_ROOT}/bin/x86_64-linux-clang/qnn-onnx-converter --input_network ~/models/inception_v3.onnx --output_path ~/models/inception_v3_quantized.cpp --input_list ~/models/input_list.txt --input_dim "x" 1,3,299,299这 在目录中生成 and 文件。inception_v3_quantized.cpp inception_v3_quantized.bin ~/models
请参阅 qnn-<framework>-converter 文档或运行以查看所有可用的 量化的自定义,包括量化模式、优化、 等。qnn-<framework>-converter --help
型 汇编
转换/量化步骤完成后,用于编译生成的 C++ graph 转换为共享对象 (.so),使模型能够由 应用程序执行推理。qnn-model-lib-generator
对于 x86,编译器工具链用于编译 C++ graph 转换为 .so 库。对于 RB3Gen2 等 Linux Embedded 设备, 适当的编译器工具链 () 必须为 使用。Clangaarch64-ubuntu-gcc9.4
编译模型以在 x86 上运行
生成共享的 对象模型,以在基于 x86 的 Linux 计算机上运行。这 使用 Clang-14 编译器工具链生成 inception_v3.so 来编译 C++ 图 转换为与 x86 主机兼容的 QNN 型号 .so。${QNN_SDK_ROOT}/bin/x86_64-linux-clang/qnn-model-lib-generator -c ~/models/inception_v3.cpp -b ~/models/inception_v3.bin -o ~/models/libs/ -t x86_64-linux-clang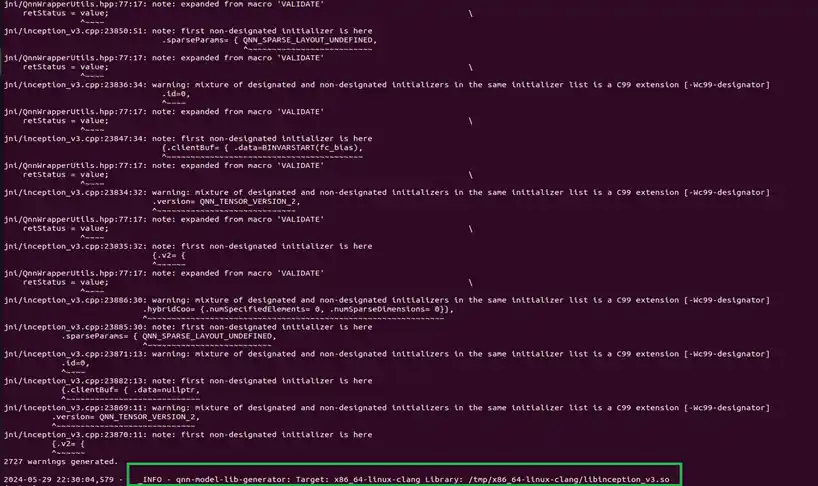
编译模型以在 Arm 架构上运行
以下步骤安装 将 Model .cpp 文件编译为 .so 所需的交叉编译器工具链 图书馆。
sudo apt install g++-aarch64-linux-gnuexport QNN_AARCH64_UBUNTU_GCC_94=/一次 交叉编译器设置好了,使用以下命令在 ~/model/libs/aarch64-ubuntu-gcc9.4.. 中生成 libinception_v3.so。
提供此 location 添加到工具中 论点。qnn-model-lib-generator
${QNN_SDK_ROOT}/bin/x86_64-linux-clang/qnn-model-lib-generator -c ~/models/inception_v3.cpp -b ~/models/inception_v3.bin -o ~/models/libs/ -t aarch64-ubuntu-gcc9.4编译 在 Hexagon Tensor Processor 上运行的模型
以下命令 在 中生成。libinception_v3_quantized.so~/models/libs/aarch64-ubuntu-gcc9.4
${QNN_SDK_ROOT}/bin/x86_64-linux-clang/qnn-model-lib-generator -c ~/models/inception_v3_quantized.cpp -b ~/models/inception_v3_quantized.bin -o ~/models/libs/ -t aarch64-ubuntu-gcc9.4
















 8056
8056

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









