






部署模型
模型 .so(量化或非量化)可以通过支持 QNN 的应用程序(一个 使用 QNN C/C++ API 编写的应用程序)。QNN 提供 API 来加载模型 .so 动态运行模型,并在具有所选后端的硬件上运行模型。
QNN 提供了一个预构建的工具 (qnn-net-run),可以动态加载此 model .so 并使用提供的输入在选定的后端上执行推理。
对于 CPU、GPU 或 HTP 执行,需要三个 参数: qnn-net-run
- 模型文件 –
由 qnn-model-lib-generator生成的 .so 文件 - Backend file (后端文件) – 目标后端的 .so 文件
libQnnCpu.so用于 CPU 后端。libQnnGpu.so用于 GPU 后端。libQnnHtp.so对于 HTP 后端。
- 输入列表 - 文本文件,如使用的文件 在量化过程中,此列表中的 Input Raw 文件除外用于推理。为 简单性在此示例中,我们使用用于量化的相同输入列表 推理。
input_list.txt
在 x86 后端运行 QNN 模型
要在 x86 CPU 上运行模型,需要模型 .so, backend library .so 和 input list 来运行推理以生成输出。qnn-net-run
例如,以下命令加载 libinception_v3.so 模型并运行 model 在 x86 CPU 上。执行完成后,该工具会将输出文件写入 。qnn-net-run~/models/output_x86
${QNN_SDK_ROOT}/bin/x86_64-linux-clang/qnn-net-run --model ~/models/libs/x86_64-linux-clang/libinception_v3.so --backend ${QNN_SDK_ROOT}/lib/x86_64-linux-clang/libQnnCpu.so --input_list input_list.txt --output_dir ~/models/output_qnn_x86准备 QNN 模型以在设备上运行
在目标上运行之前,请确保将 QNN 二进制文件和库复制到 target 以及模型和输入文件。
对于 RB3Gen2,请使用 和${QNN_SDK_ROOT}/bin/aarch64-ubuntu-gcc9.4${QNN_SDK_ROOT}/lib/aarch64-ubuntu-gcc9.4
| 文件 | 源位置 |
|---|---|
qnn-net-run | ${QNN_SDK_ROOT}/bin/aarch64-ubuntu-gcc9.4 |
libQnnHtp.so | ${QNN_SDK_ROOT}/lib/aarch64-ubuntu-gcc9.4/libQnnHtp.so |
libQnnCpu.so | ${QNN_SDK_ROOT}/lib/aarch64-ubuntu-gcc9.4/libQnnCpu.so |
libQnnGpu.so | ${QNN_SDK_ROOT}/lib/aarch64-ubuntu-gcc9.4/libQnnGpu.so |
libQnnHtpPrepare.so | ${QNN_SDK_ROOT}/lib/aarch64-ubuntu-gcc9.4 |
libQnnHtpV68Stub.so | ${QNN_SDK_ROOT}/lib/aarch64-ubuntu-gcc9.4 |
libinception_v3_quantized.so | ~/models/libs/aarch64-ubuntu-gcc9.4 |
libinception_v3.so | ~/models/libs/aarch64-ubuntu-gcc9.4 |
libQnnHtpV68Skel.so | ${QNN_SDK_ROOT}/lib/hexagon-v68/unsigned |
libqnnhtpv68.cat | ${QNN_SDK_ROOT}/lib/hexagon-v68/unsigned |
libQnnSaver.so | ${QNN_SDK_ROOT}/lib/hexagon-v68/unsigned |
libQnnSystem.so | ${QNN_SDK_ROOT}/lib/hexagon-v68/unsigned |
ssh ubuntu@[ip-addr]
mkdir qnn_artifacts
exit
scp ${QNN_SDK_ROOT}/bin/aarch64-ubuntu-gcc9.4/qnn-* ubuntu@[ip-addr]:/home/ubuntu/qnn_artifacts/
scp ${QNN_SDK_ROOT}/lib/aarch64-ubuntu-gcc9.4/libQnn*.so ubuntu@[ip-addr]:/home/ubuntu/qnn_artifacts/
scp ${QNN_SDK_ROOT}/lib/hexagon-v68/unsigned/* ubuntu@[ip-addr]:/home/ubuntu/qnn_artifacts/
scp ~/models/libs/aarch64-ubuntu-gcc9.4/* ubuntu@[ip-addr]:/home/ubuntu/qnn_artifacts/
scp ~/models/input_list.txt ubuntu@[ip-addr]:/home/ubuntu/qnn_artifacts/
scp -r /tmp/RandomInputsForInceptionV3 ubuntu@[ip-addr]:/tmp/
ssh ubuntu@[ip-addr]
cd qnn_artifacts在基于 Arm 的 CPU 上运行 QNN 模型
在基于 Arm 的 CPU 上执行模型时, 需要模型 .so(对于 RB3Gen2 目标,必须交叉编译 .so 使用 aarch64-ubuntu-gcc9.4 工具链)、后端 .so 库和输入列表设置为 运行 Inference 以生成输出。qnn-net-run
例如,以下命令将输出文件写入 。/home/ubuntu/qnn_artifacts/output_cpu
export LD_LIBRARY_PATH=/home/ubuntu/qnn_artifacts/:$LD_LIBRARY_PATH
export PATH=/home/ubuntu/qnn_artifacts:$PATH
qnn-net-run --model libinception_v3.so --backend libQnnCpu.so --input_list input_list.txt --output_dir output_cpu在目标上的 GPU 上运行 QNN 模型
在 Adreno GPU 上执行模型时, 需要 模型 .so、后端 .so 库 (libQnnGpu.so) 和用于运行推理的输入列表 以生成输出。qnn-net-run
例如,以下命令将输出文件写入 。/home/ubuntu/qnn_artifacts/output_gpu
export LD_LIBRARY_PATH=/home/ubuntu/qnn_artifacts/:$LD_LIBRARY_PATH
export PATH=/home/ubuntu/qnn_artifacts:$PATH
qnn-net-run --model libinception_v3.so --backend libQnnGpu.so --input_list input_list.txt --output_dir output_gpu在目标上的 HTP 后端上运行 QNN 模型
要在 HTP 后端上运行模型,请使用库和后端库并将输出保存在 output_htp 目录中。libquantized_inception_v3.solibQnnHtp.so
export LD_LIBRARY_PATH=/home/ubuntu/qnn_artifacts/:$LD_LIBRARY_PATH
export PATH=/home/ubuntu/qnn_artifacts:$PATH
export ADSP_LIBRARY_PATH="/home/ubuntu/qnn_artifacts/;/usr/lib/rfsa/adsp;/dsp"
qnn-net-run --model libinception_v3_quantized.so --backend libQnnHtp.so --input_list input_list.txt --output_dir output_htp验证输出 主机
对于馈送到(通过文件)的每个输入原始文件,将生成一个输出文件夹,其中包含 输出 RAW 文件,其大小将与模型的输出图层匹配,如 下图。(Netron,用于可视化模型的工具)qnn-net-runinput_list
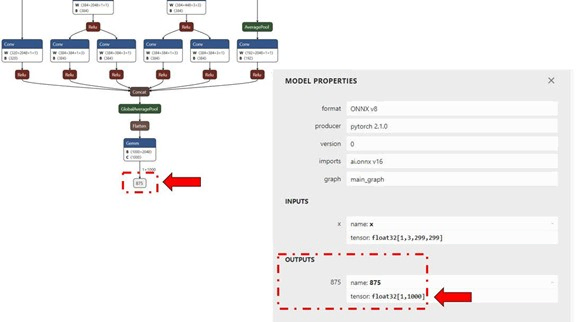
在此示例中,输出 raw 文件是一个二进制文件,该文件 包含 1000 个分类类的概率。inception_v3
我们使用 Python 脚本 要将文件作为 NumPy 数组读取以执行后处理,请验证 输出。下面的示例检查 HTP 预测是否与 CPU 相同 预测。
scp -r ubuntu@[ip-addr]:/home/ubuntu/qnn_artifacts/output_cpu .
scp -r ubuntu@[ip-addr]:/home/ubuntu/qnn_artifacts/output_htp .pwd<path>
将工具的输出从设备复制到主机后 机器上,我们可以创建一个简单的 Python 脚本来加载 CPU 和 HTP 的输出 执行并使用 NumPy 的 NumPy 中。qnn-net-run
#python postprocessing script (compare.py)
import numpy as np
htp_output_file_path = "<path>/output_htp/Result_1/875.raw"
cpu_output_file_path = "<path>/output_cpu/Result_1/875.raw"
htp_output = np.fromfile(htp_output_file_path, dtype=np.float32)
htp_output = htp_output.reshape(1,1000)
cpu_output = np.fromfile(cpu_output_file_path, dtype=np.float32)
cpu_output = cpu_output.reshape(1,1000)
cls_id_htp = np.argmax(htp_output)
cls_id_cpu = np.argmax(cpu_output)
# Let's compare CPU output vs HTP output
print("CPU prediction {} \n HTP prediction {}".format(cls_id_cpu, cls_id_htp))输出

使用 QNN API 部署模型
高通 AI Engine Direct SDK 提供 C/C++ API,以 创建/开发可以加载已编译的 .so 模型并在其上执行它的应用程序 选定的具有加速功能的后端(CPU、GPU 或 HTP)。一个示例应用程序 演示了用于执行模型的 SNPE C/C++ API。
模型部署 使用高通 IM SDK
在构建整个使用时改善开发人员体验 案例管道(来自摄像头的流、预处理图像、执行推理等)、QNN 已作为插件集成到 高通 IM SDK 中。插件 基于 QNN C API 开发,提供动态 加载和执行模型。使用该插件,您可以 将转换和编译的模型库集成到 高通 IM SDK 中 pipeline 来实现您的用例。qtimlqnnqtimlqnn

















 1992
1992

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









