







 本文详细介绍了RadarScenes数据集,包含了四个汽车雷达传感器在德国乌尔姆的测量数据,涉及数据结构、传感器配置、标注过程、数据统计以及相关的工具和应用。该数据集用于机器学习研究,提供了丰富的元信息和示例场景,为自动驾驶和雷达数据分析提供资源。
本文详细介绍了RadarScenes数据集,包含了四个汽车雷达传感器在德国乌尔姆的测量数据,涉及数据结构、传感器配置、标注过程、数据统计以及相关的工具和应用。该数据集用于机器学习研究,提供了丰富的元信息和示例场景,为自动驾驶和雷达数据分析提供资源。
0 引言
RadarScenes数据集包含安装在一辆测量车辆上的四个汽车雷达传感器的数据。该数据集记录于2016年至2018年在德国乌尔姆。该数据集官方网址为RadarScenes - RadarScenes,详细的信息可以从该网址获取。
机器学习领域的一些出版物使用了该数据集。雷达场景论文的预印本可以在[2104.02493] RadarScenes: A Real-World Radar Point Cloud Data Set for Automotive Applications (arxiv.org)获得。
笔者在CSDN上传了第一组序列的数据,可以访问RadarScenes数据集第一组数据资源-CSDN文库获得。
免责声明
该数据集是“按原样”提供的,没有明示或暗示的保证和/或任何超出强制性法定义务的责任。这尤其适用于与数据集有关的任何注意或赔偿义务。这些注释仅为我们的研究目的而创建,没有对任何类型产品的使用进行质量评估。因此,我们不能保证所提供数据集的正确性、完整性或可靠性。
1 数据集结构
1.1 概述
该数据集由158个单独的序列组成。对于每个序列,从雷达和里程计传感器记录的数据存储在一个hdf5文件中。每个这些文件都伴随着一个名为“scenes.json”的json文件,其中存储元信息。在子文件夹中,相机图像以jpg文件的形式存储。
另外两个json文件提供了进一步的元信息:在“sensors.json”文件中,定义了传感器的安装位置和旋转角度。在“sequences.json”文件中,所有记录的序列都列出了附加信息,例如记录持续时间。
1.2 文件
在下面的小节中,给出了关于每种文件类型内容的信息。
1.2.1 sensors.json
这个文件描述了四个雷达传感器的位置和方向。每个传感器都有一个整数id。安装位置相对于车辆后轴的中心给出。这样可以更容易地计算传感器位置上的自车运动。仅给出x和y位置,因为传感器不提供俯仰信息。同样,只需要旋转的偏航角。
1.2.2 sequences.json
该文件包含每个记录序列的一个条目。每个条目都是根据以下信息构建的:类别(机器学习算法的训练或验证),序列中单个场景的数量,以秒为单位的持续时间以及在该序列中执行测量的传感器名称。
1.2.3 scenes.json
在这个文件中,存储了特定序列和该序列中的场景的元信息。
序列的名称在顶层字典中列出,该序列的组(训练或验证)以及雷达传感器在该序列中执行测量的第一次和最后一次的时间戳。
一个场景被定义为四个雷达传感器之一的一次测量。对于每个场景,列出了对应雷达传感器的传感器id。每个场景都有一个唯一的时间戳,即雷达传感器执行测量的时间。每个场景给出了不同雷达测量的四个时间戳:同一传感器测量的下一个和上一个时间戳以及任何雷达传感器测量的下一个和上一个时间戳。这允许快速迭代所有传感器的测量或单个传感器的所有测量。对于与里程表信息的关联,给出了最近里程表测量的时间戳,以及hdf5文件中里程表中可以找到该测量值的索引。并给出了时间戳与雷达测量值最接近的相机图像的文件名。最后给出了hdf5数据集“radar_data”中本场景雷达探测的起止指标。第一个索引对应于hdf5数据集中第一次检测到这个场景的行。第二个索引对应于hdf5数据集中开始下一个场景的行。即这一行的检测是第一个不再属于场景的检测。这个约定允许在列表和数组中使用常见的python索引,其中第二个索引是排他的:arr[start:end]。
1.2.4 radar_data.h5
在这个文件中,雷达和里程计数据都被存储。该文件中存在两个数据集:“odometry”和“radar_data”。
“odometry”数据有六列:timestamp、x_seq、y_seq、yaw_seq、vx、yaw_rate。每一行对应一个驾驶状态的测量值。列x_seq, y_seq和yaw_seq描述了自车相对于某个全局原点的位置和方向。因此,在全局(序列)坐标系中定义姿态。列“vx”包含自车在x方向上的速度,yaw_rate列包含汽车当前的横摆角速度。
hdf5数据集“radar_data”由单个检测组成。数据集中的每一行对应一个检测。检测由以下信号定义,每个信号列在一列中:
- timestamp:相对于某个任意原点以微秒为单位
- sensor_id:整数值,记录检测的传感器id
- range_sc:以米为单位,到检测的径向距离,传感器坐标系
- azimuth_sc:以弧度为单位,检测方位角,传感器坐标系
- rcs:以dBsm表示,表示检测的rcs值
- vr:单位为m/s。为该检测测量的径向速度
- vr_compensated in m/s:这个检测的径向速度,但是补偿了自车运动
- x_cc和y_cc: m表示检测在汽车坐标系中的位置(原点在后桥中心)
- x_seq和y_seq:m表示检测在全局序列坐标系中的位置(原点在任意起点)
- uuid:检测的唯一标识。可用于关联预测标签和调试
- track_id:该检测所属的动态对象的id。如果它不属于任何对象则为空
- label_id:该检测所属对象的语义类id。乘用车(0)、大型车辆(如农业或工程车辆)(1)、卡车(2)、公共汽车(3)、火车(4)、自行车(5)、机动两轮车(6)、行人(7)、行人群(8)、动物(9)、驾驶时遇到的所有其他动态物体(10)和静态环境(11)。
1.3 相机图像
记录相机的图像位于每个序列的“camera”子文件夹中。每个图像的文件名对应于记录该图像的时间戳。
该数据集为雷达数据集。相机图像只被包括在内,以便数据集的用户更好地了解记录的场景。然而,由于GDPR的要求,通过语义实例分割网络提出的区域重新绘制和人工校正,从这些图像中删除了个人信息。网络被优化为高召回值,因此假阴性被抑制,代价是有假阳性标记。由于摄像机图像仅用于引导记录的雷达场景,因此这一缺点对实际数据没有负面影响。
2 传感器配置
该数据集使用四个汽车雷达传感器进行记录。此外,还记录了来自纪实摄像机的图像。使用汽车的里程计传感器和DGPS系统记录自车的运动信息。
两个侧面传感器向外倾斜85°,另外两个传感器向外倾斜约25°:
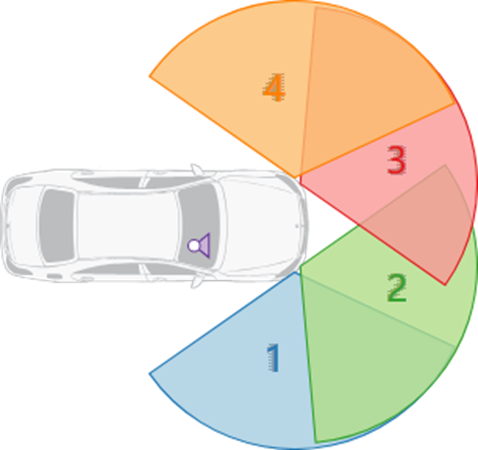
每个传感器的最大探测距离为100米,视野范围约为-60°至+60°。距离和径向速度分辨率分别为0.15m和0.1km/h。两次连续测量之间的平均周期时间为60ms。与任何其他雷达传感器一样,方位角方向的分辨率随着方位角的增大而降低。在视轴方向上,分辨率约为0.5°,在视场外侧分辨率降至2°。
3 标注
3.1 概述
汽车雷达点云的数据标注是一项极其繁琐的工作。它需要具有丰富经验的人类专家准确地识别出与感兴趣的目标对应的所有雷达点。
在这个数据集中,只有移动的物体被标注。也就是说,静态环境(树木、电线杆、路沿石、房屋等)被忽略,潜在的移动物体(停放的汽车、站立的行人)也没有被注释。
为了确保高质量的注释,只使用由人类专家创建的手动标记数据。
3.2 11个目标类别
11种不同的对象类别被标记为:汽车、大型车辆、卡车、公共汽车、火车、自行车、机动两轮车、行人、行人群体、动物和其他。在不能对单个行人进行一定的分隔时,分配行人组标签。另一类由各种其他道路使用者组成,这些道路使用者不太适合这些类别,例如溜冰者或移动的手推车。除了11个对象类之外,还为所有剩余的点分配了一个静态标签。
所有标签的选择都是为了尽量减少不同专家评估之间的分歧,例如,如果没有大型车辆标签,则大型皮卡车可能被定性为汽车或卡车。
3.3 5个简化类别
除了常规的11个类之外,还提供了一个映射函数和数据集工具,它将大多数类投影到一个更粗糙的变体,仅包含:汽车、大型车辆、两轮车、行人和行人组。这种可选的类定义可以用于需要更平衡的标签分布的任务,例如在神经网络的训练期间。对于这个映射,动物和其他类不会被重新分配。相反,它们可能被用于,例如,用于隐藏的类检测任务。
3.4 标注过程
为动态对象的每个单独检测分配两个标签:label id和track id。
label id是一个整数,描述了相应对象所属的语义类。另一方面,track id在整个记录时间内唯一地标识单个真实世界对象。也就是说,对同一对象的所有检测都具有相同的track id。如果一个物体被遮挡超过500毫秒,或者如果运动停止了这段时间(例如,如果一辆汽车停在红灯处),那么一旦再次测量到运动物体,就会分配一个新的track id。
标记者被指示以这样一种方式标记物体,即保持现实和一致的物体比例。由于汽车雷达传感器在方位角方向上的精度相当低,特别是在较远的距离上,物体的轮廓不能准确捕获。例如,方位方向的偏差可能会导致自我飞行器前面的物体看起来比实际宽得多。在这种情况下,报告的非零多普勒速度的探测位置与真实物体的位置相差甚远。然后,这些检测不会添加到对象中。这可以从下图中看到,尽管它们的多普勒速度不为零,但被包围的探测并没有被添加到卡车集群中:

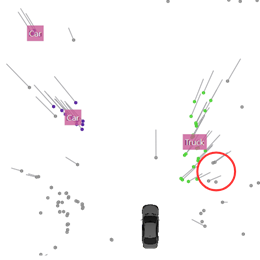
一个物体的真实尺寸是由标注者在整个测量过程中估计出来的。这种方法导致标记结果乍一看似乎是错误的,因为靠近运动物体的非零多普勒检测不被标记为该物体的成员。然而,这种视觉印象在大多数情况下是误导的,并且非常小心地使对象尺寸随时间保持一致。这种选择有很大的好处,即可以通过对象检测算法估计真实的对象范围。
当查看来自多个传感器扫描的检测时,应该小心判断检测是否属于某个对象。由于物体的运动,它的探测分布在地球固定的坐标系中。因此,一个物体的长度与它的速度和所选时间窗口的大小成比例地增加。因此,对于检测是否属于一个物体的问题,应该始终只在观察器中位移一个测量帧。
镜像效应、每个测量维度的模糊性以及大副瓣的假阳性检测会导致不属于任何运动物体的非零多普勒检测。这些检测具有默认的静态标签。因此,简单地对多普勒维度的所有检测进行阈值处理不会产生属于移动道路使用者的检测集。
4 数据统计
4.1 一些数字
- 四个雷达传感器
- 一部纪实摄影机
- >100公里行驶里程
- >4小时记录时间
- 158种不同的序列
- >7500个独立道路使用者
- 11个不同的对象类
- 大约400万个注释检测
4.2 一些图片
请随意从数据集本身复制这些图片!
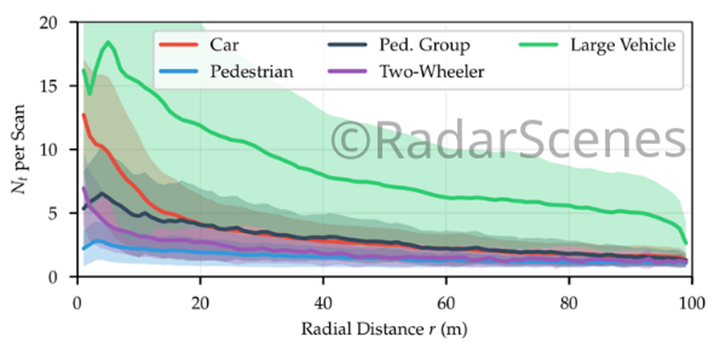
下图为每次扫描中五个映射类(见标签)的检测数量与径向距离的关系。
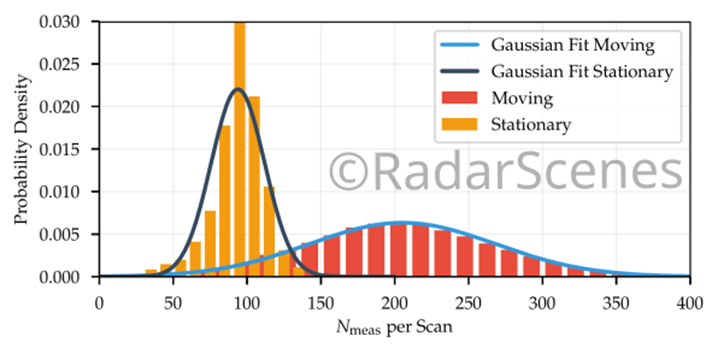
其中一个传感器测量到的检测次数。可以区分两种情况:移动的自车和静止的自车。
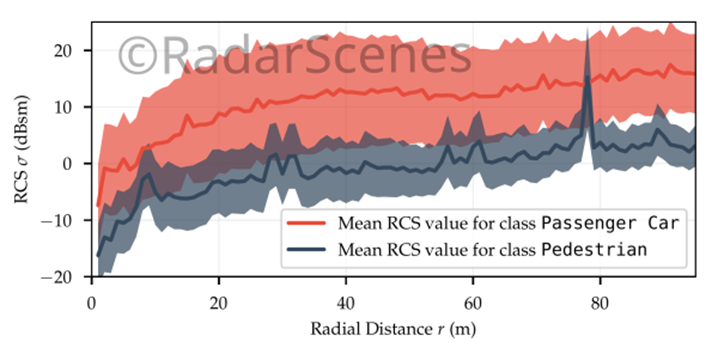
不同径向距离下汽车和行人的RCS值比较。阴影区域是平均值周围的标准偏差(实线)。
5 实例
以下图库包含数据集中的一些示例场景。
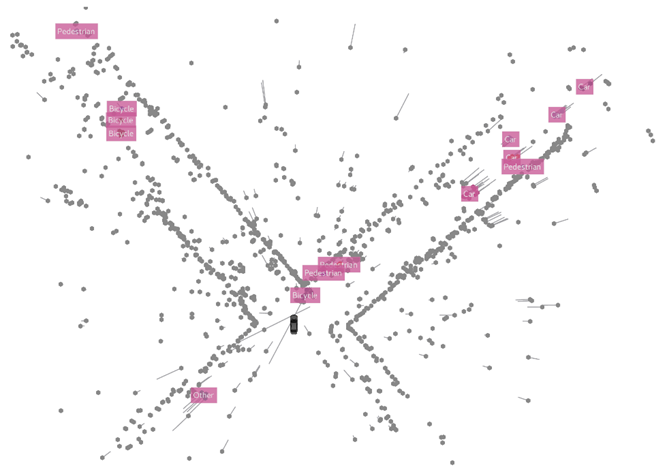

有多个道路使用者的十字路口。
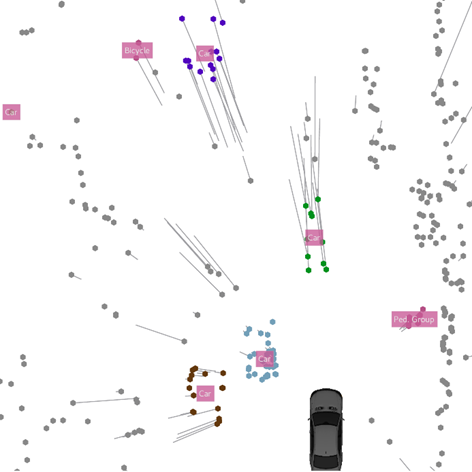

市中心有行人,汽车和自行车。
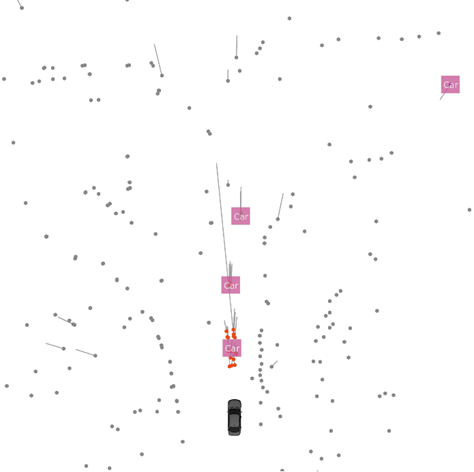

雷达透射效应:即使直接视线被遮挡,也能看到自车前方的车辆。


行人组注释:检测不能与单个行人相关联,因此选择了行人组类标签。


有很多车的丁字路口。
6 工具和应用
使用雷达数据与使用相机或激光雷达数据有很大不同。为了使开始更容易,我们创建了一些工具来帮助您。
6.1 显示
您可以在pypi(radar-scenes · PyPI)和github(oleschum/radar_scenes: Helper tools for the radar scenes data set. (github.com))上找到RadarScenes数据集的显示器。
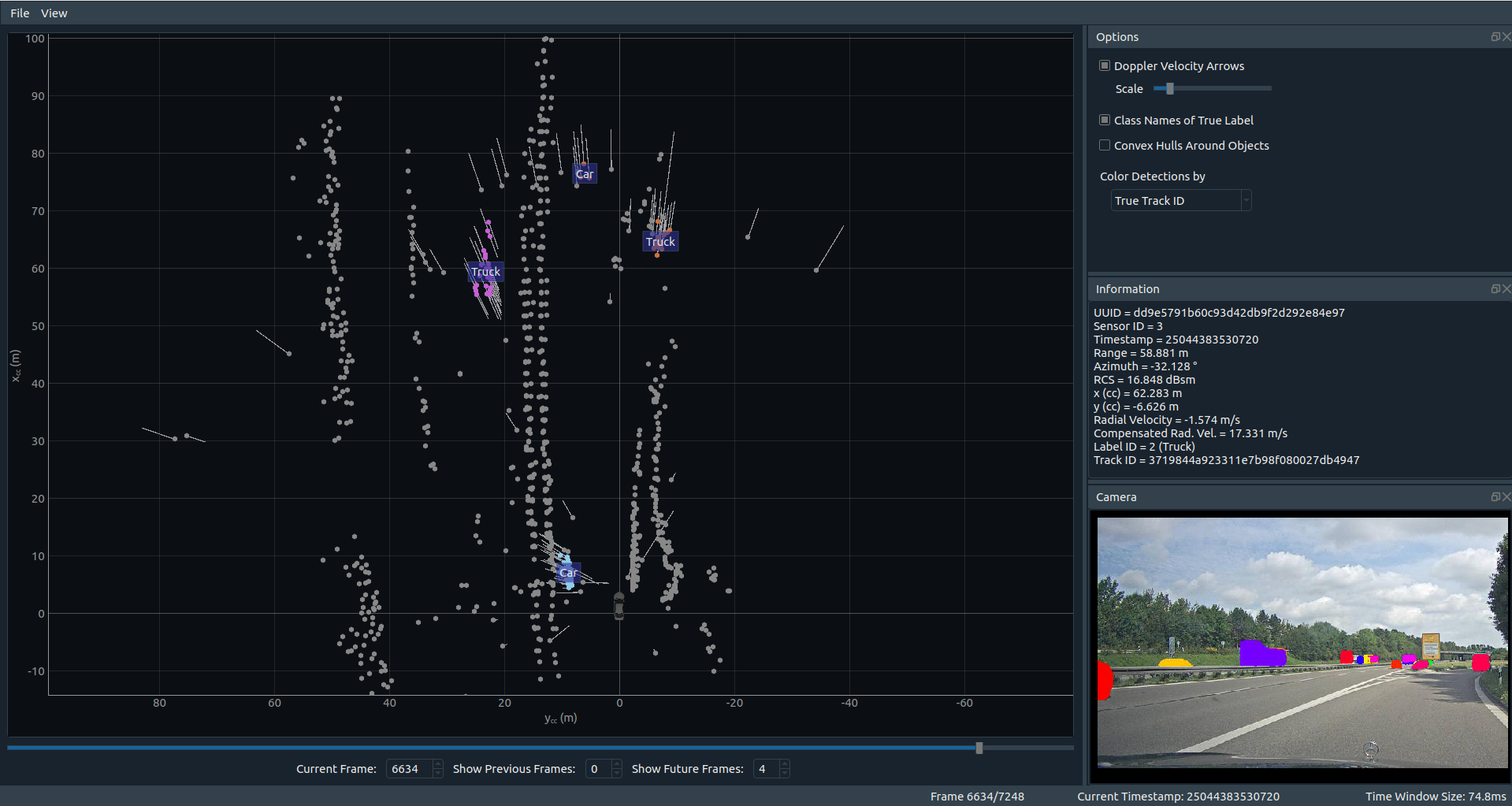
要安装显示器,只需按照链接页面上的说明进行操作。最后,您将得到一个名为radar_scenes的python包,其中包含显示器。
6.2 API
此外,链接的radar_scenes python包还包含一个用于数据集的小API。它允许对数据进行迭代,并包含辅助函数,例如坐标转换。
示例代码可以在radar_scenes包的examples文件夹中找到:Github(radar_scenes/radar_scenes/examples at master · oleschum/radar_scenes (github.com))。
未来,将整合不同机器学习方法的分数计算辅助函数。
请随意通过拉请求贡献!
6.3 标签数据
下面是一个关于如何访问数据的示例:让我们来看看在一个序列中包含多少个不同的标记检测。
首先,让我们导入必要的包,定义数据集的路径并选择一个序列:
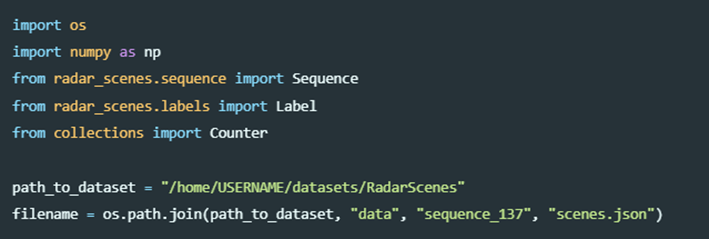
然后,我们为选定的序列创建一个Sequence对象:

有了这个序列对象,我们可以很容易地访问雷达数据。例如,我们可以选择包含所有检测的标签id的列:

您可以通过使用适当的显示器直接查看hdf5文件或打印出numpy数组序列的dtype来查找列名。
sequence.radar_data使用python的collections模块中的Counter类,我们可以快速计算所有标签的出现次数:
c = Counter(all_labels)
for label_id, n in c.items():
print("In the whole sequence, class {} occurred {} times".format(Label.label_id_to_name(label_id), n))如果我们对每个场景中唯一对象的数量感兴趣,我们可以得到它们如下。首先,我们定义一个小的辅助函数
def count_unique_objects(sequence: Sequence):
"""
For each scene in the sequence, count how many different objects exist.
Objects labeled as "clutter" are excluded from the counting, as well as the static detections.
:param sequence: A measurement sequence
:return: a list holding the number of unique objects for each scene
"""
objects_per_scene = []
for scene in sequence.scenes():
track_ids = scene.radar_data["track_id"]
label_ids = scene.radar_data["label_id"]
valid_idx = np.where(label_ids != Label.STATIC.value)[0]
unique_tracks = set(track_ids[valid_idx])
objects_per_scene.append(len(unique_tracks))
return objects_per_scene
然后为我们的序列调用它:
print("\nCounting the number of unique dynamic objects in each scene:")
object_counts = count_unique_objects(sequence)
print("The most unique objects appear in scene {} in which {} different objects were labeled.".format(np.argmax(object_counts),
object_counts[np.argmax(object_counts)]))完整的示例(radar_scenes/radar_scenes/examples/label_statistics.py at master · oleschum/radar_scenes (github.com))包含更多关于如何使用数据集的提示。
一定要看看其他的例子(radar_scenes/radar_scenes/examples at master · oleschum/radar_scenes (github.com))!
7 RadarScenes工具
7.1 概述
这个python包为RadarScenes数据集(RadarScenes - RadarScenes (radar-scenes.com))提供了一些帮助脚本。
除此之外,该软件包还包含一个查看器,用于查看来自数据集的雷达数据和相机图像。
7.2 安装
该软件包专为Python版本>=3.6设计,可以使用pip安装。使用pip安装是推荐的方法。
另一种方法是克隆这个存储库,然后使用setup.py手动安装这个包。
7.3 虚拟环境
强烈建议在软件包自己的虚拟环境中安装该软件包。为此,在安装软件包之前创建一个虚拟环境:
python3 -m venv ~/.virtualenvs/radar_scenes这将在主目录下的.virtualenvs文件夹中创建一个名为radar_scenes的python虚拟环境。
这个环境可以通过下面的命令激活
source ~/.virtualenvs/radar_scenes/bin/activate活动的虚拟环境由通常的bash提示符之前的前一行(radar_scenes)表示。
一旦虚拟环境处于活动状态,就可以使用该命令安装包
pip install radar_scenes您不必为安装克隆此存储库。
有很多指南可以提供关于虚拟环境和python包安装的更多信息,例如在python.org上。
7.4 全系统安装
如果不需要虚拟环境(同样,不鼓励这样做!),可以使用全局版本的pip安装包
pip install --user radar_scenes如果需要在系统范围内安装(可能需要root权限),可以省略标志--user。
7.5 Windows安装提示
当获得错误消息“qt.qpa. qpa.”插件:无法加载Qt平台插件“windows”在“”,即使它被找到。这个应用程序启动失败,因为没有Qt平台插件可以初始化。重新安装应用程序可能会解决此问题。
不要放弃。相反,你应该试试这个:

7.6 引用
请参考www.radar-scenes.com获取如何引用数据集的说明。
7.7 雷达数据显示器
在安装过程中,命令rad_viewer可用。如果已将包安装到虚拟环境中,则该命令仅在虚拟环境处于活动状态时可用。
调用rad_viewer将启动雷达数据查看器。作为一个可选的命令行参数,可以提供从RadarScenes数据集到*.json文件的路径。然后,序列将在启动时直接加载。
例子:
(radar_scenes)
$ rad_viewer ~/datasets/radar_scenes/data/sequence_128/scenes.json时间滑块本身或键盘上的箭头键可用于滚动序列。
7.8 许可证
本项目在MIT许可条款下获得许可。
但是请注意,RadarScenes数据集本身带有不同的许可。
















 309
309

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











