







啊啊啊我的妻王氏宝钏
- 1. 一些概念
- 2. 支持的硬件
- 3. 支持的第三方库
- 4. 安装
- 5. 下载测试数据
- 6. tips
- 7.1 如何在应用程序中使用(引用)VISP?
- 7.2 如何copy例程并新建一个VISP应用程序?
- 8. 帮助文档
- 8.1 基本的矩阵向量运算
- 8.2 图像操作
- 8.3 图像处理
- 8.4 相机内参标定
- 8.5 相机外参标定
- 8.6 基于视觉特征(edge、KLT、深度法线、深度密度)的目标跟踪(目标检测 + 位姿估计)
- 8.6.0 一些概念
- 8.6.1 斑点(blob)跟踪
- 8.6.2 关键点(key)、特征点跟踪
- 8.6.3 边缘检测并跟踪
- 8.6.4 RGB相机:基于通用模型的目标检测和跟踪
- 8.6.5 stereo 相机:基于通用模型的目标检测和跟踪
- 8.6.6 RGB-D 相机:基于通用模型的目标检测和跟踪
- 8.6.7 RGB相机 + AprilTag:基于通用模型的目标检测和跟踪
- 8.6.8 在visp中使用JSON
- 8.6.9 如何使用Blender软件创建仿真数据
- 8.6.10 visp + 深度学习算法MegaPose:实现目标跟踪、位姿估计
- 8.6.11 基于NeRF算法利用图像生成3D模型并导出为MegaPose可以使用的格式
- 8.7 图像目标检测(包含边框回归)
- 8.8 基于DNN的目标检测
- 8.9 图像分割
- 8.10 机器视觉
- 8.11 视觉伺服
1. 一些概念
1.1 什么是VISP
VISP 即 Visual servoing platform.
Allows to control a robot equipped with a camera from measures extracted from the images.
- 实现无人机机载端的飞行控制,机器人运动控制。
- 实现实时目标检测。
- 实现实时位姿估计。
1.2 特点
- 集成其他算法很便捷
- 跨平台,源码为C++
- 完备的文档
1.3 模块化的软件架构
下图突出显示了模块依赖项和每个模块可能使用的第三方库。中央模块是核心模块core。所有其他模块都依赖于core。
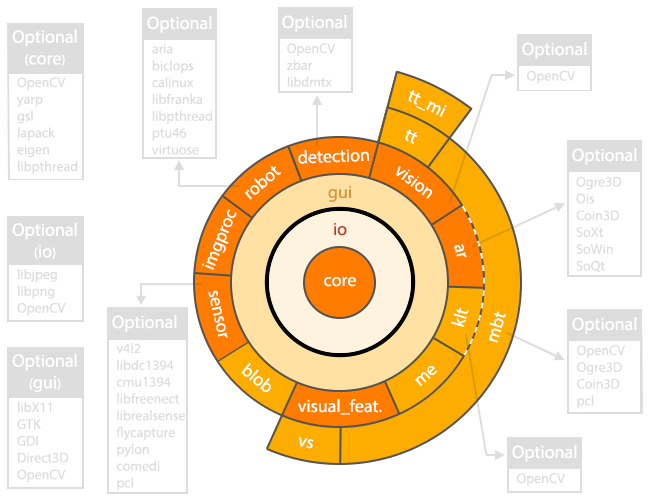
模块 概述:
- core
定义基本数据结构(图像、矩阵、相机)的模块。此模块由所有其他模块使用。为了启用某些功能,此模块可能会使用可选的第三方库。 - io
管理图像或视频的 I/O、命令行解析。 - gui
在屏幕窗口上显示图像,实时绘制变量的演变过程。 - ar
ar 即 augmented reality ,增强现实。 - detection
二维码和人脸检测。
目标检测。 - robot
真实机器人或仿真机器人接口。
真实:Afma4, Afma6, Viper, Pioneer, Panda from Franka Emika
仿真:free flying camera, Afma6, Viper, Pioneer - imgproc
提供图像处理算法。 - sensor
提供摄像头、RGB-D传感器、激光传感器接口。
如:usb相机,Kinect相机,Sick雷达。
需要调用第三方库。 - vision
相机标定、图像特征点检测、特征点匹配、位姿估计等。
基本通过调用opencv实现。 - visual_feat
定义视觉特征,用于视觉伺服。 - vs
实现视觉伺服功能。 - 下面介绍的模块都用于跟踪功能:
- blob
实现blob跟踪功能 - me
moving-edges跟踪 - klt
Kanade-Lucas-Tomasi特征跟踪 - mbt
markerless model-based跟踪 - tt
基于SSD 和 ZNCC 的模版跟踪 - tt_mi
tt模块的扩展
1.4 代码中重要的概念
1.4.1 cMo 坐标转换关系矩阵
cMo 是一个4x4的坐标齐次变换矩阵,详细点说明是物体坐标系O到相机坐标系C的齐次变换矩阵,是两个坐标系位姿关系的一种表示方式,了解什么是齐次变换矩阵请看坐标变换篇。
假如已知一向量p在物体坐标系O中的坐标为
[
x
o
,
y
o
,
z
o
]
T
[x_o, y_o, z_o]^T
[xo,yo,zo]T,那么向量p在相机坐标系中的坐标可以通过下式计算得到:
[
x
c
,
y
c
,
z
c
]
T
=
c
M
o
[
x
o
,
y
o
,
z
o
]
T
[x_c,y_c,z_c]^T= {^cM}_o[x_o, y_o, z_o]^T
[xc,yc,zc]T=cMo[xo,yo,zo]T
其中
c
M
o
^cM_o
cMo中包含了两个坐标系间的旋转关系和平移关系,详细请参考坐标变换篇。
1.4.2 检测对象、检测目标、跟踪目标、跟踪对象 的含义
目标检测:是指整个检测过程。
检测目标:是目标检测这个过程中的实施对象,即被检测的对象、物体、类别。
检测对象:与 “检测目标” 同义,与 “被检测对象” 同义。
目标跟踪:实时目标检测 + 实时边框回归。
跟踪目标:被跟踪的目标,与 “跟踪对象” 同义,与同义 “被跟踪目标” 。
上述概念适用于本篇全部章节!
目标检测、目标识别、目标分类和目标跟踪是计算机视觉领域的几个关键任务,它们之间既相互区别又相互联系。以下是对它们之间关系的详细阐述:
1.4.3 目标分类、目标识别、目标检测、目标跟踪
- 目标分类:即图像分类。在计算机视觉祯中,目标分类通常指的是将图像中的对象归类到预定义的类别中,而不涉及对象的位置信息。
- 目标识别:目标识别是指从图像或视频祯中区分出一个特殊目标与其他目标的过程。它侧重于确定图像中对象的类别,而不关注对象的具体位置。
- 目标检测:目标检测是计算机视觉中的一个核心任务,旨在找出图像或视频祯中的所有感兴趣目标(物体),并确定它们的类别和位置。它融合了图像分类和定位两个子任务,要求算法能够同时解决“是什么”和“在哪里”的问题。
- 目标跟踪:目标跟踪是指在视频序列中持续监测并识别一个或多个特定目标对象的过程。它侧重于随时间推移跟踪特定对象的位置,通常用于视频分析和监控应用中。
总结:
- 目标分类 == 图像分类,
- 目标识别 ≈ 目标分类
只不过目标识别通常是在更复杂的背景下进行,而目标分类则可能是在更简单的场景下进行,目标分类可以作为目标识别的一个预处理步骤。 - 目标检测 == 目标识别 + 边界回归(定位)
- 目标跟踪 == 目标检测 + 目标唯一标识 + 持续唯一标识的位置信息
目标跟踪 与 目标检测的区别,以视频帧中有两辆车为例,一辆比亚迪,一辆宝马;
目标检测的结果:只能得到两辆车的边界框,并且这两个目标的类别都是【车】;
目标跟踪的结果:也能得到两个边界框,但还可以知道其中一个框是宝马,另一个框是比亚迪。
即可以得到识别目标的唯一标识,并且持续更新这个唯一标识的位置移动信息。
使用目标检测算法来确定初始帧中目标的位置和类别,然后在后续帧中持续跟踪这些目标的位置变化。
在目标检测的基础上,目标跟踪算法会跟踪目标物体的移动轨迹。
这需要对目标物体的特征进行描述和匹配,以实现不同目标物体之间的区分。
2. 支持的硬件
机器人、相机、雷达、力传感器、触觉传感器、动作捕捉器、mavlink系统 …
参考:Supported Hardware
3. 支持的第三方库
如OpenCV、PCL、MavSDK/MavLink …
参考:Supported Third-Party Libraries
4. 安装
参考:Installation
环境:Ubuntu-20.04
在jetson开发板上安装请参考下面两篇文献:
【1】Tutorial: Installation from source on a Jetson TX2 equipped with a Quasar Carrier board
【2】Tutorial: Installation from source on a Jetson TX2 equipped with an Orbitty Carrier board
Quasar 载板和 Orbitty 载板的区别请参考:https://cloud.tencent.com/developer/article/1080248
4.1 快速安装VISP
以编译源码的方式安装visp;
仅安装部分必要的第三方库,可选的第三方库可在后续使用过程中再安装;
- 0)前提条件
sudo apt-get install build-essential cmake-curses-gui git wget
- 1)创建工作目录
echo "export VISP_WS=$HOME/visp-ws" >> ~/.bashrc source ~/.bashrc mkdir -p $VISP_WS - 2)安装部分必要的第三方库
openCV 和 mavsdk 对于ardupilot无人机来说是必须的,注意mavsdk要安装v1.4的版本,否则VISP编译会报错。
安装mavsdk,请参考 MAVSDK篇 或 pixhawk_prereq_software。
安装openCV ,命令如下:# Ubuntu 20.04 : sudo apt-get install libopencv-dev libx11-dev liblapack-dev libeigen3-dev libv4l-dev libzbar-dev libpthread-stubs0-dev libdc1394-dev nlohmann-json3-dev # older Ubuntu distros : sudo apt-get install libopencv-dev libx11-dev liblapack-dev libeigen3-dev libv4l-dev libzbar-dev libpthread-stubs0-dev libdc1394-22-dev - 3)获取VISP源码
cd ~/visp-ws git clone https://github.com/lagadic/visp.git - 4)编译
mkdir -p ~/visp-ws/visp-build cd ~/visp-ws/visp-build cmake ../visp make -j$(nproc) - 5)设置环境变量 VISP_DIR,即设置一个visp安装路径的环境变量
echo "export VISP_DIR=$VISP_WS/visp-build" >> ~/.bashrc source ~/.bashrc
4.2 第三方库的(可选)安装
如果发现缺少第三方库,安装它,然后重新配置VISP并重新编译。
-
1)安装第三方库
参考1:Supported Third-Party Libraries
参考2:Advanced ViSP installation
参考3:pixhawk_prereq_software -
2)重新配置VISP
cd ~/visp-ws/visp-build cmake ../visp查看新添加的第三方库是否被配置进~/visp-ws/ViSP-third-party.txt中:请参考此处
-
3)重新编译
cd ~/visp-ws/visp-build make -j$(nproc)nproc是操作系统级别对每个用户创建的进程数的限制。
5. 下载测试数据
文档:Install ViSP data set
一些ViSP示例和测试需要一个数据集,包括图像、视频和模型。
- 下载途径:
- 通过下载压缩包visp-images-3.6.0.zip的方式下载数据集
Download visp-images-3.6.0.zip from https://visp.inria.fr/download and uncompress it in your workspace - 通过Git下载数据集
cd $VISP_WS git clone https://github.com/lagadic/visp-images.git - 设置环境变量VISP_INPUT_IMAGE_PATH以便运行example:
echo "export VISP_INPUT_IMAGE_PATH=$VISP_WS/visp-images" >> ~/.bashrc source ~/.bashrc - 测试
点击图片结束测试cd $VISP_WS/visp-build ./example/device/display/displayX
6. tips
包括:
- 如何卸载ViSP ?
cd $VISP_WS/visp-build sudo make uninstall - 如何安装VISP ?
- How to take into account a newly installed 3rd party ?
- Which are the targets that could be run with make ?
make help | grep visp - How to build a ViSP specific module ?
- Which are the 3rd party libraries that are used in ViSP ?
7.1 如何在应用程序中使用(引用)VISP?
windows应用程序、cmake、eclipse ide:请参考文档
类 unix 系统包括OSX、Fedora、Ubuntu、Debian …
以 Ubuntu 为例:
- 在项目中使用ViSP的最简单方法是使用CMake。如果不熟悉CMake,可以查看cmake篇或cmake文档。
- 本教程中描述的所有材料(源代码和图像)都是ViSP源代码的一部分,可以使用以下命令下载:$ svn export https://github.com/lagadic/visp.git/trunk/tutorial/image
- 1)编译示例程序
cd $VISP_WS/visp-build # 编译全部 cmake ../visp make -j$(nproc) # 仅编译某个示例程序tutorial-viewer cmake ../visp make tutorial-viewer - 2)执行示例程序
可执行程序在:~/visp-ws/visp-build/tutorial/image/tutorial/image/tutorial-viewer
示例程序源代码在:~/visp-ws/visp/tutorial/image/tutorial-viewer.cppcd $VISP_WS/visp-build/tutorial/image ./tutorial-viewer monkey.pgm - 参考:https://visp-doc.inria.fr/doxygen/visp-daily/tutorial-getting-started.html
7.2 如何copy例程并新建一个VISP应用程序?
- (1)复制 tutorial-grabber-opencv-threaded.cpp 命名为 copy tutorial-grabber-opencv-threaded.cpp-hyl.cpp
- (2)在tutorial-grabber-opencv-threaded.cpp所在目录的CMakeFileLists.txt中新增代码:
set(tutorial_cpp
tutorial-grabber-1394.cpp
...
tutorial-grabber-opencv-threaded-hyl.cpp
) - (3)重新构建、编译
cd ~/visp-ws/visp-build rm -rf * cmake ../visp make tutorial-grabber-opencv-threaded-hyl
8. 帮助文档
源码中的文档也很赞:
visp-ws/visp/doc
8.1 基本的矩阵向量运算
- 本教程的重点是基本的线性代数运算,如向量和矩阵乘法。
- 参考文献:Tutorial: Basic linear algebra operations
- 实现在 vpMatrix 类中
- 矩阵、向量运算函数
- 矩阵相乘
vpMatrix::mult2Matrices(const vpMatrix &, const vpMatrix &, vpMatrix &)
vpMatrix::operator*(const vpMatrix &) const - 矩阵乘以向量
vpMatrix::multMatrixVector(const vpMatrix &, const vpColVector &, vpColVector &)
vpMatrix::mult2Matrices(const vpMatrix &, const vpColVector &, vpColVector &)
vpMatrix::operator*(const vpColVector &) const - 矩阵本身与转置相乘A * AT、AT * A
vpMatrix::AtA()
vpMatrix::AtA(vpMatrix &) const
vpMatrix::AAt()
vpMatrix::AAt(vpMatrix &) const
- 矩阵相乘
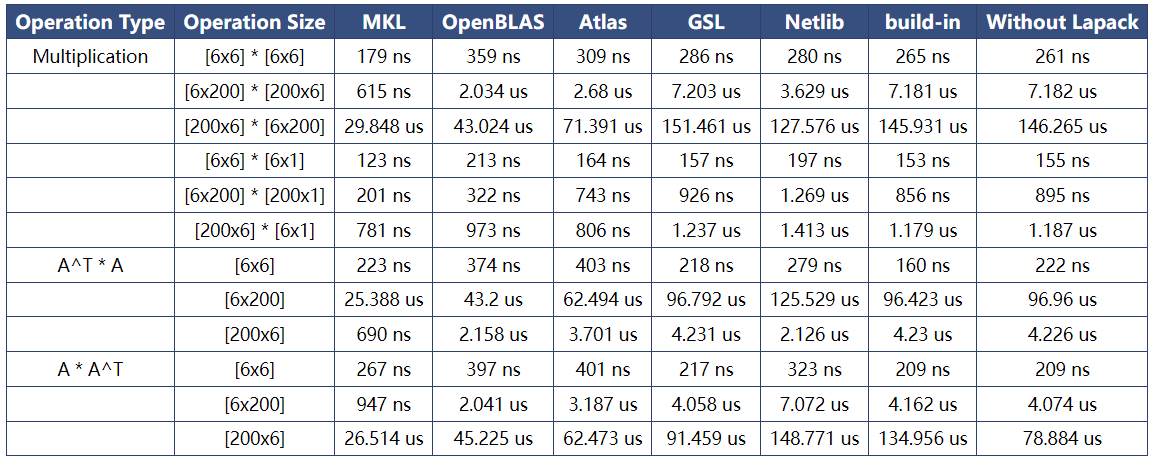
- 矩阵、向量运算需要调用的第三方库,如 MKL、OpenBLAS、 Atlas、 GSL、Netlib 等,最好安装,可以提升计算性能。如果没有安装这些第三方,ViSP将提供一个未经优化的内置在 visp 中的 Lapack-build-in 版本,矩阵运算性能远不如前者。
- 众所周知,MKL、OpenBLAS、 Atlas、 GSL、Netlib 软件包都是用于加速或优化矩阵运算的软件包吗,是互斥的不能再visp中同时使用,那么如何在编译visp时指定使用哪个包呢?
指定方法1:cmake ../visp -DUSE_BLAS/LAPACK=[ MKL | OpenBLAS | Atlas | GSL | Netlib | OFF ]
其中cmake ../visp -DUSE_BLAS/LAPACK=OFF即使用 Lapack-build-in 。
指定方法2:或者使用可视化编译工具ccmake来指定:ccmake ../visp
cmake结束后会有提示,visp使用了哪个包:
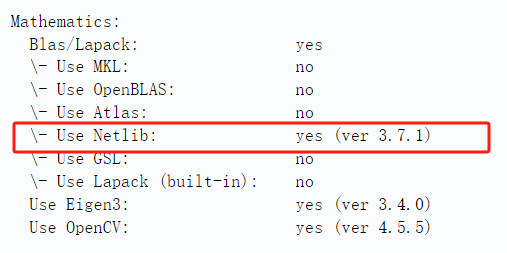
- 尽管计算性能取决于操作系统和矩阵的维度,但推荐使用 MKL 包。
- 性能比较
8.2 图像操作
包括:读取、滤波、渲染…
参考:Image manipulation
8.2.1 在图像显示窗口绘制图像
- visp gui模块提供图形用户界面功能,允许在窗口中显示vpImage。为此,您可以使用几个可选的第三方库,它们是:X11、GDI、OpenCV、GTK、Direct3D。我们建议在类unix系统上使用X11,即使用vpDisplayX类,在Windows上使用GDI,即使用类vpDisplayGDI。如果这些类都不可用,则可以使用vpDisplayOpenCV。
- 以tutorial-image-display.cpp为例,
它显示了如何创建一个3840x2160的灰度图像,将所有像素值(灰度值)设置为128,并在图像中间显示一个半径为200像素的红色圆圈://! \example tutorial-image-display.cpp #include <visp3/gui/vpDisplayGDI.h> #include <visp3/gui/vpDisplayX.h> int main() { vpImage<unsigned char> I(2160, 3840, 128); try { #if defined(VISP_HAVE_X11) vpDisplayX d(I); #elif defined(VISP_HAVE_GDI) vpDisplayGDI d(I); #endif vpDisplay::setTitle(I, "My image"); vpDisplay::display(I); vpDisplay::displayCircle(I, I.getHeight() / 2, I.getWidth() / 2, 200, vpColor::red, true); vpDisplay::flush(I); std::cout << "A click to quit..." << std::endl; vpDisplay::getClick(I); } catch (const vpException &e) { std::cout << "Catch an exception: " << e.getMessage() << std::endl; } } - vpImage只能与一个显示窗口关联。在前面的例子中,图像I与显示d相关联。
- 图像显示的缩放
应用于显示大于屏幕分辨率的图像
修改代码:
5倍缩放:
自动缩放:#if defined(VISP_HAVE_X11) vpDisplayX d(I, vpDisplay::SCALE_5); #elif defined(VISP_HAVE_GDI) vpDisplayGDI d(I, vpDisplay::SCALE_5); #endif
或:#if defined(VISP_HAVE_X11) vpDisplayX d(I, vpDisplay::SCALE_AUTO); #elif defined(VISP_HAVE_GDI) vpDisplayGDI d(I, vpDisplay::SCALE_AUTO); #endif#if defined(VISP_HAVE_X11) vpDisplayX d; #elif defined(VISP_HAVE_GDI) vpDisplayGDI d; #endif d.setDownScalingFactor(vpDisplay::SCALE_AUTO); d.init(I); }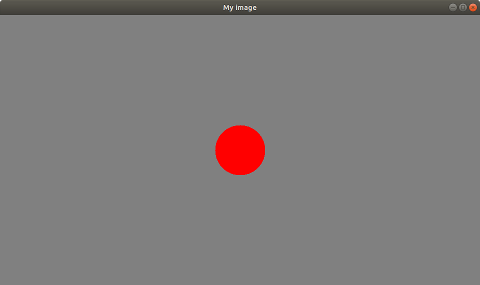
8.2.2 在图像显示窗口加载、显示、绘制图像
参考:Tutorial: How to display an image and basic drawings in a window
涉及到的第三方库:X11、GDI、OpenCV、GTK、Direct3D。至少使用其中之一。
- 显示本地路径的图片
- 显示基本图形
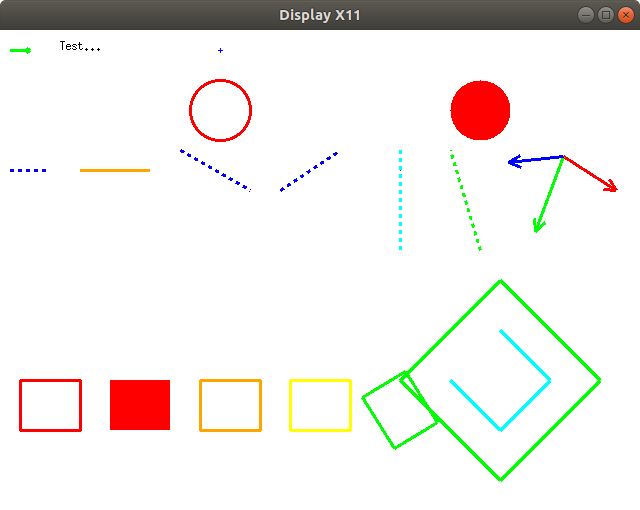
- 在图像上绘制一个点(覆盖式绘制)
- 绘制两个点之间的直线(覆盖式绘制)
- 绘制矩形、圆形、十字、文字(覆盖式绘制)
- 导出并保存绘制的内容
- 处理窗口中的键盘事件
8.2.2 无显示窗口的情况下在图像上添加基本图形
参考:Tutorial: How to modify an image to insert basic drawings
在不需要图像显示窗口的情况下通过添加基本图形来修改图像的内容。
无需使用第三方库:X11、GDI、OpenCV、GTK、Direct3D。
vpImageDraw类允许通过插入点、圆、线、矩形、多边形、框架等基本图形来修改图像。还有vpFont类,它允许修改图像以插入文本。这些类在testImageDraw.cpp中使用。
8.2.3 从视频流或相机中获取图像祯
工业相机数据(电气)接口分类:
- FireWire(IEEE 1394)
- GigE (网口)
- USB
- Camera Link
- CoaXPress
- 参考:工业数字相机接口概述
参考:Tutorial: Image frame grabbing
只有安装了相应的第三方库,才能从相机、视频流中获取图像。需要根据相机型号、数据接口、品牌、视频流来源来安装对应的第三方库。
-
FlyCapture SDK
例子:tutorial-grabber-flycapture.cpp
FlyCapture SDK适配以下相机类型:- Flea3 USB 3.0 cameras (FL3-U3-32S2M-CS, FL3-U3-13E4C-C)
菲力尔品牌的usb相机 - Flea2 firewire camera (FL2-03S2C)
- Dragonfly2 firewire camera (DR2-COL)
- GigE PGR cameras
- Flea3 USB 3.0 cameras (FL3-U3-32S2M-CS, FL3-U3-13E4C-C)
-
libdc1394 SDK
firewire or USB3 camera under Unix
tutorial-grabber-1394.cpp -
libv4l2 SDK
usb camera under Unix
tutorial-grabber-v4l2.cpp -
Pylon SDK
Basler cameras
tutorial-grabber-basler-pylon.cpp -
Realsense SDK
Realsense RGB-D cameras
tutorial-grabber-realsense.cpp
tutorial-grabber-multiple-realsense.cpp
参考:Frame grabbing using Realsense SDK -
Occipital Structure SDK
Occipital公司的Structure Core RGB-D camera,如第二代Structure Sensor:Mark II
tutorial-grabber-structure-core.cpp -
对比 RealSense D435 相机 和 Structure Core 相机得到的RGB和深度图像
tutorial-grabber-rgbd-D435-structurecore.cpp
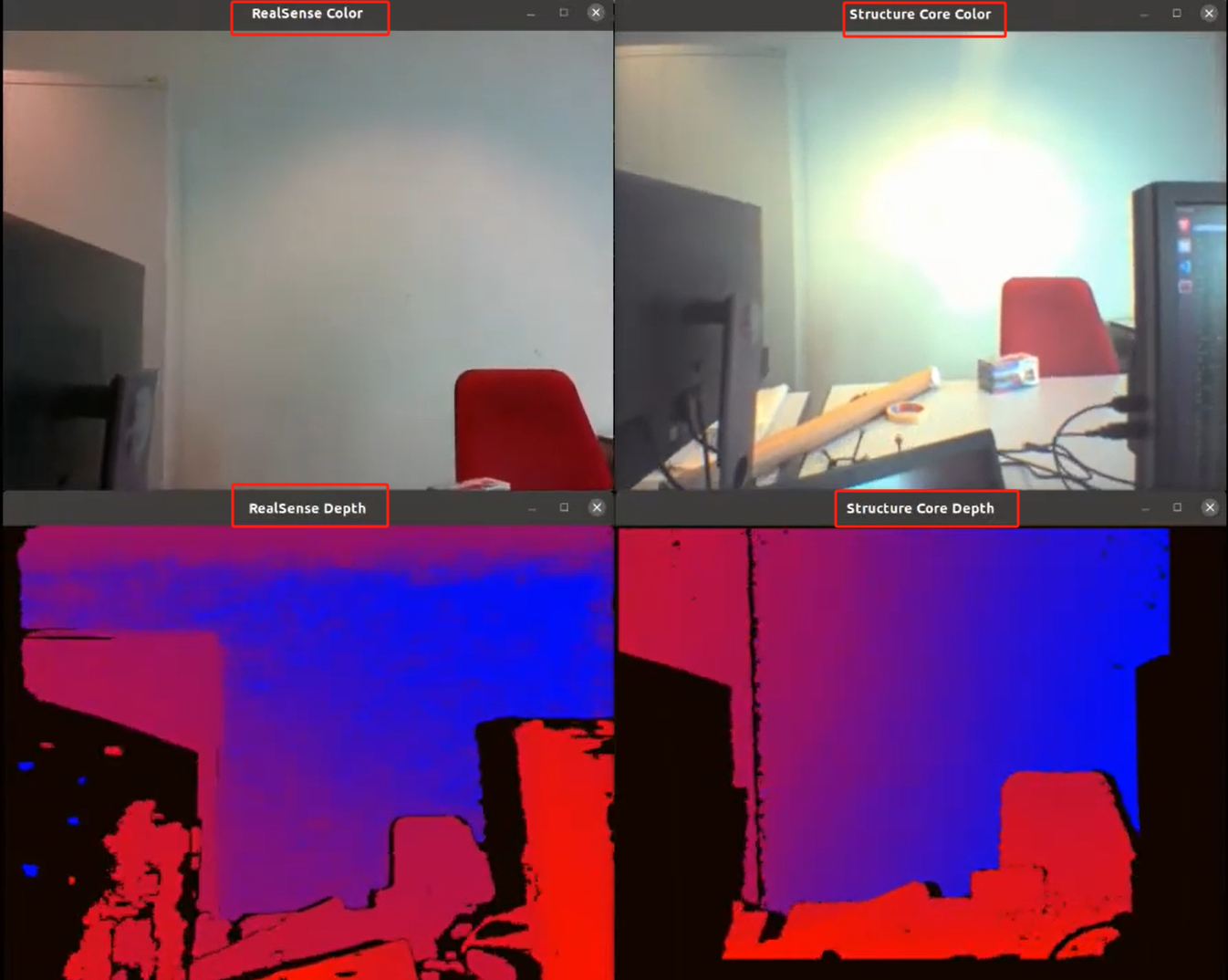
-
从OpenCV获取图像祯
参考:Frame grabbing using OpenCV
例子:tutorial-grabber-opencv.cpp
如何通过openCV获取https、rtsp视频流??- (1) 找到调用opencv的地方,可知_cap是opencv类的对象:
cv::VideoCapture _cap; - (2) 由 this->_cap.open(this->_camera_id, cv::CAP_V4L2); 可知打开视频的函数是open
- (3) F12 进入 cv::VideoCapture 找到 open 函数的定义:
CV_WRAP virtual bool open(const String& filename, int apiPreference = CAP_ANY); - (4) F12 进入 CAP_ANY 可知openCV函数支持以下视频源输入:
综上可知,枚举中的 CAP_GSTREAMER 类型就可以打开https、rtsp类型的视频源(前提是必须安装gstreamer第三方库),或者干脆设置为 CAP_ANY 类型可实现自动检测!!enum VideoCaptureAPIs { CAP_ANY = 0, //!< Auto detect == 0 CAP_VFW = 200, //!< Video For Windows (obsolete, removed) CAP_V4L = 200, //!< V4L/V4L2 capturing support CAP_V4L2 = CAP_V4L, //!< Same as CAP_V4L CAP_FIREWIRE = 300, //!< IEEE 1394 drivers CAP_FIREWARE = CAP_FIREWIRE, //!< Same value as CAP_FIREWIRE CAP_IEEE1394 = CAP_FIREWIRE, //!< Same value as CAP_FIREWIRE CAP_DC1394 = CAP_FIREWIRE, //!< Same value as CAP_FIREWIRE CAP_CMU1394 = CAP_FIREWIRE, //!< Same value as CAP_FIREWIRE CAP_QT = 500, //!< QuickTime (obsolete, removed) CAP_UNICAP = 600, //!< Unicap drivers (obsolete, removed) CAP_DSHOW = 700, //!< DirectShow (via videoInput) CAP_PVAPI = 800, //!< PvAPI, Prosilica GigE SDK CAP_OPENNI = 900, //!< OpenNI (for Kinect) CAP_OPENNI_ASUS = 910, //!< OpenNI (for Asus Xtion) CAP_ANDROID = 1000, //!< Android - not used CAP_XIAPI = 1100, //!< XIMEA Camera API CAP_AVFOUNDATION = 1200, //!< AVFoundation framework for iOS (OS X Lion will have the same API) CAP_GIGANETIX = 1300, //!< Smartek Giganetix GigEVisionSDK CAP_MSMF = 1400, //!< Microsoft Media Foundation (via videoInput) CAP_WINRT = 1410, //!< Microsoft Windows Runtime using Media Foundation CAP_INTELPERC = 1500, //!< RealSense (former Intel Perceptual Computing SDK) CAP_REALSENSE = 1500, //!< Synonym for CAP_INTELPERC CAP_OPENNI2 = 1600, //!< OpenNI2 (for Kinect) CAP_OPENNI2_ASUS = 1610, //!< OpenNI2 (for Asus Xtion and Occipital Structure sensors) CAP_GPHOTO2 = 1700, //!< gPhoto2 connection CAP_GSTREAMER = 1800, //!< GStreamer CAP_FFMPEG = 1900, //!< Open and record video file or stream using the FFMPEG library CAP_IMAGES = 2000, //!< OpenCV Image Sequence (e.g. img_%02d.jpg) CAP_ARAVIS = 2100, //!< Aravis SDK CAP_OPENCV_MJPEG = 2200, //!< Built-in OpenCV MotionJPEG codec CAP_INTEL_MFX = 2300, //!< Intel MediaSDK CAP_XINE = 2400, //!< XINE engine (Linux) };
- (1) 找到调用opencv的地方,可知_cap是opencv类的对象:
-
CMU1394 SDK
a firewire camera under Windows
tutorial-grabber-CMU1394.cpp -
Parrot Bebop 2 drone
tutorial-grabber-bebop2.cpp -
从视频流获取图像祯
只支持本地视频流,不支持https、rtsp等网络视频流,网络视频流请移步OpenCV;
支持*.avi, *.mp4, *.mov, *.ogv, *.flv 等格式;
不支持保存为图像帧,即不支持--record选项
要求安装第三方库OpenCV;
例子:tutorial-video-reader.cpp
参考:Images from a video stream
8.2.4 图像滤波
参考:Tutorial: Image filtering
例程:tutorial-image-filter.cpp
- 原图:

- 高斯模糊 处理

- 沿x, y轴计算梯度(空间导数)
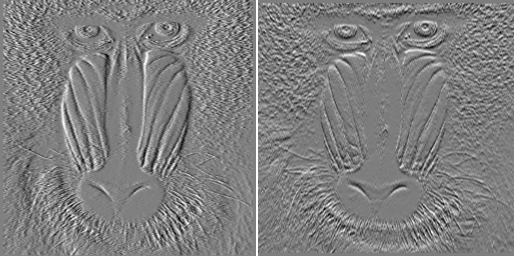
- Canny边缘检测器

- 图像卷积
例如,对于卷积核:
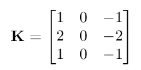
有:

根据卷积核可知结果应该与梯度计算的结果类似。 - Gaussian image pyramid
8.2.5 图像的投影
参考:Tutorial: Planar image projection
例程:tutorial-image-simulator.cpp
使用场景:将平面场景中的某个图像投影到相机位置所在的图像坐标系上,即:在相机视角看到的空间图像。
例子解析:
- 原始图像:20x20cm的正方形,如下

- 目标:将图像投影到给定的相机位置(相机坐标系),以及获得结果图像。

8.2.6 将 视频、图片序列 制作成 深度学习数据集
使用场景:
(1)将视频流抽取祯并保存为图像序列,通过鼠标点击的形式选择祯;
(2))将图像序列进行 重命名、转换格式、部分选择 操作来构成用于深度学习的图像数据集。
参考:Tutorial: How to manipulate a video or a sequence of images
例程:tutorial-image-manipulation.cpp
功能:
- 生成图像序列
ls -1 /tmp/myseq/png
I0001.png
I0002.png
I0003.png
I0004.png
I0005.png
...
- 图像 重命名、格式转换
ls -1 /tmp/myseq/jpeg/
image-0001.jpeg
image-0002.jpeg
image-0003.jpeg
image-0004.jpeg
image-0005.jpeg
...
- 改变起始祯
ls -1 /tmp/myseq/jpeg
image-0100.jpeg
image-0101.jpeg
image-0102.jpeg
image-0103.jpeg
image-0104.jpeg
image-0105.jpeg
...
- 保存为灰度图像 序列
- 从视频中提取图像帧 并生成图像序列
image-0001.jpeg
image-0002.jpeg
image-0003.jpeg
image-0004.jpeg
image-0005.jpeg
...
- 鼠标点击视频帧以选择保存(生成)哪些图像祯序列
8.2.6 键盘事件
参考:Handle keyboard events in a window
例程:tutorial-event-keyboard.cpp
8.2.7 visp opencv 代码解析
tutorial-grabber-opencv-hyl.cpp
--device
相机类型
cv::VideoCapture cap(opt_device)--filename
cv::VideoCapture cap(opt_filename,opt_device);--record
将视频流、相机数据流保存为图像祯。
--record=1鼠标左键点击一次则保存一张。
--record=0鼠标左键点击一次这开始将视频流保存为图像序列,直到视频结束或相机流终止。
保存路径:与可执行程序同路径,或保存在/tmp中--seqname
与--record一起使用,规定了保存的图像帧的名称格式
如:--seqname I%04d.pgm --record 0
保存的结果为:
保存路径:与可执行程序同路径,或保存在/tmp中- opencv读取相机
cv::VideoCapture cap(“https”,opt_device);
cv::Mat frame;
cap.read(frame) - visp图像定义
vpImage<vpRGBa> I; // To acquire color images vpImage<unsigned char> I; // To acquire gray images - 将opencv读取的图像帧转化为vpImage
vpImageConvert::convert(frame, I); --no-display
显示vpImage图像vpDisplayOpenCV *d = nullptr; if (opt_display) d = new vpDisplayOpenCV(I); cap >> frame; // get a new frame from camera // Convert the image in ViSP format and display it vpImageConvert::convert(frame, I); vpDisplay::display(I);//显示 std::stringstream ss; ss << "Acquisition time: " << std::setprecision(3) << vpTime::measureTimeMs() - t << " ms"; vpDisplay::displayText(I, I.getHeight() - 20, 10, ss.str(), vpColor::red); vpDisplay::flush(I);//渲染- 保存图像帧
解析:vpImageQueue<vpRGBa> image_queue(opt_seqname, opt_record_mode); vpImageStorageWorker<vpRGBa> image_storage_worker(std::ref(image_queue)); std::thread image_storage_thread(&vpImageStorageWorker<vpRGBa>::run, &image_storage_worker); while(!quit ) { quit = image_queue.record(I); } image_queue.cancel(); image_storage_thread.join();
image_queue.record(I)函数根据鼠标事件将视频流中要保存的帧号记录到image_queue中;
while循环结束后,启动线程以保存这些祯;
while结束的条件:视频流终止。 - 等待鼠标事件以退出显示窗口
若点击则返回true// Wait for a click in the display window std::cout << "A click to quit..." << std::endl; vpDisplay::getClick(I);
8.3 图像处理
8.3.1 基本图像处理:亮度、对比度、直方图、滤波、伽马校正
参考:Tutorial: Brightness and contrast adjustment
例程:tutorial-brightness-adjustment.cpp
功能:
- 亮度、对比度调整

- 伽马校正

- 直方图均衡化

- 同态滤波

8.3.2 图像锐化
参考:Tutorial: Contrast and image sharpening techniques
例程:utorial-contrast-sharpening.cpp

8.3.3 图像二值化、自动阈值
参考:Tutorial: Automatic thresholding
例程:tutorial-autothreshold.cpp
自动阈值算法包括:
- Huang
- Intermodes
- Isodata
- Mean
- Otsu
- Triangle
不同算法的效果对比:

8.3.4 二值图像:轮廓提取
参考:Contours extraction from a binary image
例程:tutorial-contour.cpp
效果:



8.3.5 二值图像:标记所有的连通形状(区域)
参考:Tutorial: Connected-components labeling
例程:tutorial-connected-components.cpp
例如,用颜色来标记不同的连通区域:
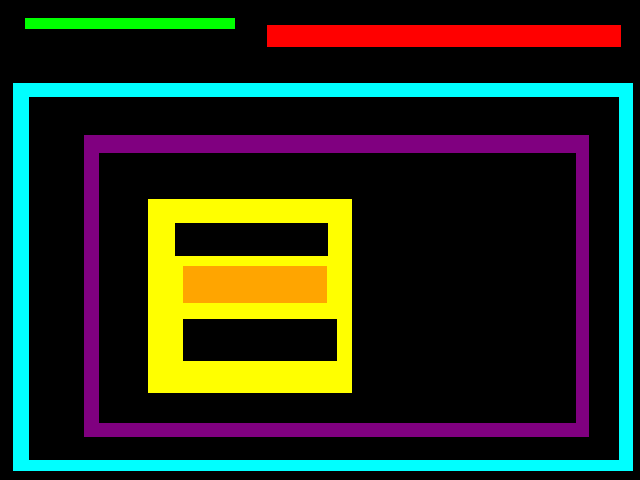
8.3.6 二值图像:区域填充(膨胀)
参考:Tutorial: Flood fill algorithm
例程:tutorial-flood-fill.cpp
效果:
8.3.7 应用实例:计算图像中的硬币数量
参考:Practical example: count the number of coins in an image
例程:tutorial-count-coins.cpp
技术路线:
- 自动阈值
- 区域填充、膨胀
- 轮廓提取
- 图像形态学运算
- 图像矩(image moments) ??
测试图像2张:
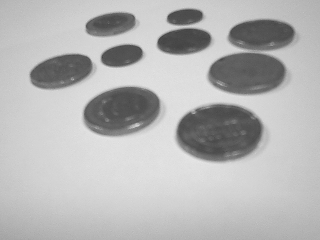

二值化处理:


二值化后发现连通区域并不完美,存在孔洞。
进行孔洞填充。
形态学运算。
结果:

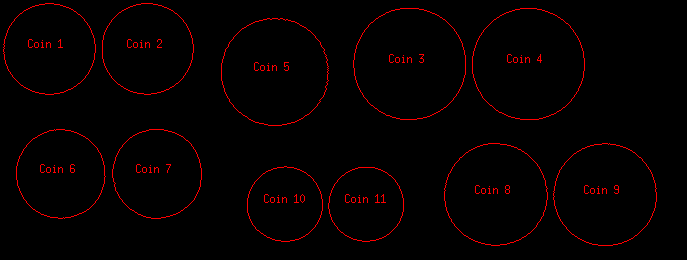
8.3.8 应用实例:圆霍夫变换—检测图像中的圆形
参考:Tutorial: Gradient-based Circle Hough Transform
例程:
8.4 相机内参标定
只针对RGB相机、灰度相机。
8.4.1 过程
例程:calibrate-camera.cpp
原理:相机参数标定原理 篇
参考:Tutorial: Camera intrinsic calibration
标定图案下载:a black and white chessboard [OpenCV_Chessboard.pdf]
为了提高精准度,做到以下几点:
- 标定图案打印后贴在硬板上;
- 聚焦、亮度正常;
- 不要垂直拍摄,倾斜拍摄;
- 尽量让整个图案填满整张图像;
- 获取5到15张图像。不需要获取大量图像,而是需要良好的姿势和质量;
步骤:
-
(1)获取5~15张不同角度拍摄标定板的图像;
如果使用其他相机、SDK,请参考:Tutorial: Image frame grabbing.
下面以利用opencv读取本地视频文件为例(源码请看附录篇):./tutorial-grabber-opencv-hyl --filename './cv-bd.mp4' --seqname chessboard-%02d.jpg --record 1
注意:标定程序仅支持.pgm, .ppm, .jpg, .png类型的图像输入。 -
(2)编写标定程序配置文件
default-chessboard.cfg

以上面给出的chessboard标定图案为例,配置文件default-chessboard.cfg的写法如下:# Number of inner corners per a item row and column. (square, circle) BoardSize_Width: 9 BoardSize_Height: 6 # The size of a square in meters Square_Size: 0.025 # The type of pattern used for camera calibration. # One of: CHESSBOARD or CIRCLES_GRID Calibrate_Pattern: CHESSBOARD # The input image sequence to use for calibration Input: chessboard-%02d.jpg # Tempo in seconds between two images. If > 10 wait a click to continue Tempo: 1其中BoardSize_Width、BoardSize_Height表示下图中的横、纵 交叉点个数:

-
(3)启动标定程序
注意:(1)中的图像文件和(2)中的.cfg文件要与可执行程序calibrate-camera在同一路径下,尤其是前者!
./calibrate-camera default-chessboard.cfg
标定结果保存在与可执行程序相同路径下的camera.xml中。 -
(4)标定结果解析
标定的目的主要是计算得到px,py,u0,v0的值,这些值可在camera.xml中查看,如:
图像不失真时的标定结果:<model> <!--Projection model type--> <type>perspectiveProjWithoutDistortion</type> <!--Pixel ratio--> <px>1125.1827706954514</px> <py>1130.4632882820727</py> <!--Principal point--> <u0>383.10649912934025</u0> <v0>654.02478654420372</v0> </model>图像失真时候的标定结果:
<model> <!--Projection model type--> <type>perspectiveProjWithDistortion</type> <!--Pixel ratio--> <px>1097.9128785325488</px> <py>1100.555719915495</py> <!--Principal point--> <u0>362.8856025467764</u0> <v0>639.48219097397157</v0> <!--Undistorted to distorted distortion parameter--> <kud>0.073370178752183005</kud> <!--Distorted to undistorted distortion parameter--> <kdu>-0.071746763433310504</kdu> </model>px、py、u0 、v0的含义:
u0 , v0:相机光心在像素坐标系中的坐标。
px , py:像素焦距,即xy方向单位长度焦距对应的像素个数。相机的姿态(跟踪对象机体系到相机坐标系的转换关系矩阵)cMo:
相机与目标之间的距离(跟踪对象机体系原点在相机坐标系中的位置向量)cMo_dist:<camera_poses> <cMo>0.05066118176 -0.1270684814 0.3616890349 -0.193814684 -0.1427615872 1.5898817</cMo> <cMo>0.02184416016 -0.1560152882 0.5529943829 -0.4688730587 0.1518388512 1.540308857</cMo> <cMo>-5.363762892e-05 -0.1868981484 0.6604669304 -0.5604800864 0.1691326205 1.515790215</cMo> <cMo>0.03544513901 -0.1089358276 0.4843374973 0.2014046797 -0.5057590613 1.583342629</cMo> <cMo>0.05159861868 -0.06258943526 0.4451049761 0.3258355889 -0.5863235901 1.593701297</cMo> <cMo>0.05320266394 -0.1400458385 0.6397415347 -0.4379457567 -0.5395737076 1.511685668</cMo> <cMo>0.03751171637 -0.1403759676 0.5769463545 -0.4584539793 -0.578216169 1.528464394</cMo> <cMo_dist>0.05705328533 -0.1224893331 0.3550852042 -0.1948613355 -0.123781045 1.592045068</cMo_dist> <cMo_dist>0.03173028524 -0.1491886829 0.5419514477 -0.4643943343 0.1703767271 1.544958702</cMo_dist> <cMo_dist>0.01180301052 -0.1787670398 0.6475276512 -0.5556073987 0.1890253068 1.521273617</cMo_dist> <cMo_dist>0.04411063099 -0.1028753688 0.4731396975 0.2021577067 -0.4788303372 1.583675872</cMo_dist> <cMo_dist>0.05953714734 -0.05695565923 0.4339260526 0.3282994939 -0.5608298789 1.592460787</cMo_dist> <cMo_dist>0.06458495308 -0.131855115 0.6251995305 -0.4361927534 -0.5177167094 1.517989606</cMo_dist> <cMo_dist>0.04781083371 -0.1330054252 0.5643172805 -0.455853917 -0.5559317605 1.535047012</cMo_dist> </camera_poses>
ViSP 3.3.1版本以后提供了一系列的分析工具:
- Grid patterns
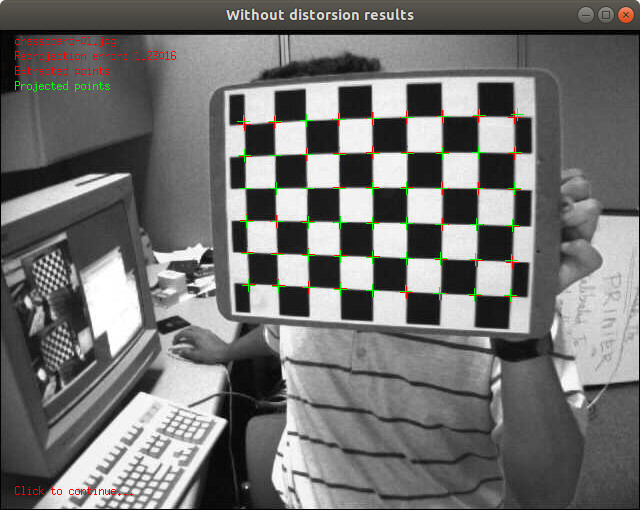
略… - 重投影误差(Reprojection error)
提取点(extracted points):图中红色“十字”点
投影点(projected points):图中绿色“十字”点
重投影误差:提取点和投影点的误差。
过程:经过两个投影阶段,无失真投影,失真投影。
结论:当提取的点和重投影的点彼此非常接近并且当全局重投影误差小于1.0时,可以获得良好的校准。重投影误差越小,标定效果越好!!
- 直线拟合
略… - 绘制标定时相机的姿态
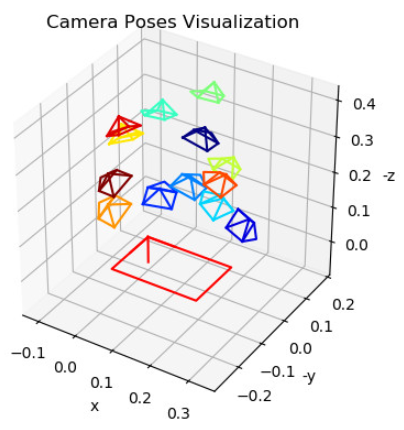
sudo apt install python-pip pip install scipy python camera_calibration_show_extrinsics.py --calibration camera.xml --scale_focal 20
8.4.2 问题解决
8.5 相机外参标定
外参标定:相机坐标系和世界坐标系的转换关系。
参考:Tutorial: Camera eye-to-hand extrinsic calibration
8.6 基于视觉特征(edge、KLT、深度法线、深度密度)的目标跟踪(目标检测 + 位姿估计)
8.6.0 一些概念
- 参考:Tracking
- 功能:
目标跟踪的结果提供:
(1)目标的3D位置(相机坐标系下的坐标值);
(2)目标的姿态(pose,相机系与目标机体系的旋转关系); - 适用对象:
对象的CAD模型已知,并且格式为vrml(.wrl)或.cao;
对象的结构由直线、圆、球体、圆柱体混合组成;
对象事先没有做过标注(markerless); - 技术原理:
- vpMbGenericTracker类;
- step1,vpMbGenericTracker类调用OpenCV得到当前帧的视觉特征:
(1)边缘 特征;
(2)KLT关键点 特征;
(3)组合特征; - step2,根据视觉特征(边缘、KLT关键点)可以得到目标的关键区域(大致边界);
- step3,位姿估计:大致边界结合3D模型、初始位姿,得到当前帧目标的精确边界、当前位姿;
- 边缘特征适用于无纹理对象;
- KLT关键点特征适用于有纹理对象;
8.6.1 斑点(blob)跟踪
跟踪目标:斑点
blob:斑点可以是黑色背景上的白色,也可以是白色背景上的黑色。
类:vpDot或vpDot2
技术栈:目标检测+目标跟踪


分析:上图中,红色线条包裹的是blob的轮廓,“十字”符号表示blob的集合中心。
8.6.1.1 鼠标手动点选斑点(blob)像素以开启跟踪
- 例程: tutorial-blob-tracker-live-firewire.cpp
- 代码解析
- 定义
vpDot2 blob; blob.setGraphics(true); //将目标轮廓叠加到图像上显示 blob.setGraphicsThickness(2); //轮廓像素厚度 - 初始化
vpImagePoint germ; //属于blob的像素点 vpDisplay::getClick(I, germ, false); //等待鼠标事件 blob.initTracking(I, germ); //初始化 - 跟踪
blob.track(I); - blob信息获取
在类vpDot2中查看,如获取获取blob所有轮廓点:getEdges
- 定义
8.6.1.2 自动检测斑点(blob)并跟踪
例程:tutorial-blob-auto-tracker.cpp
参考:Tracking
8.6.2 关键点(key)、特征点跟踪
关键点:KLT keypoints
参考:Tutorial: Keypoint tracking
技术栈:OpenCV KLT tracker
例程:tutorial-klt-tracker.cpp
类:vpKltOpencv

分析:
- 自动检测关键点
./tutorial-klt-tracker - 鼠标左键选择关键点,右键取消
./tutorial-klt-tracker --init-by-click - KLT tracker with re-initialisation
Tutorial: Keypoint tracking
8.6.3 边缘检测并跟踪
参考:Tutorial: Moving-edges tracking
参考:tutorial-me-line-tracker.cpp
类:vpMeLine
原理:ViSP移动边缘跟踪器提供了垂直于物体轮廓的点的实时跟踪功能。这样的跟踪器允许使用基于模型的法线来跟踪直线、椭圆或更复杂的对象。

8.6.4 RGB相机:基于通用模型的目标检测和跟踪
参考:https://visp-doc.inria.fr/doxygen/visp-daily/tutorial-tracking-mb-generic.html
8.6.4.1 概述
- 跟踪对象:
- 事先没有做过标注的对象(markerless)
- 由直线、圆、球体、圆柱体混合组成的对象
- 已知对象的CAD模型,并且格式为
vrml(.wrl)或.cao,使用vrml需要安装Coin 3rd 库
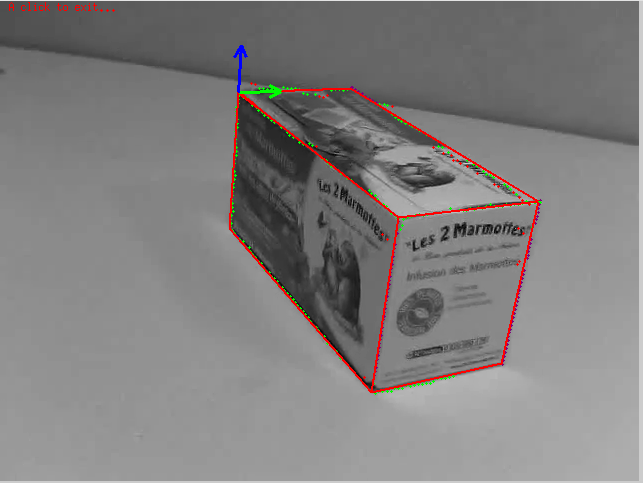
- 本教程跟踪对象以茶盒为例。

- 功能:
- 目标检测、跟踪
- 提供基于相机坐标系下的3D位置信息
- 类:vpMbGenericTracker
- 原理概述:
- 利用边缘检测:沿着CAD模型中定义的可见边缘(线、面、圆柱体和圆基元)跟踪的图像点。该功能适用于跟踪无纹理对象。
- 利用关键点检测:使用KLT跟踪器(面和圆柱体基本体)在可见对象面上跟踪关键点。此功能适用于纹理对象。
- 第三方库:openCV、Coin
- 文件:
-
tutorial-mb-generic-tracker.cpp源码 -
tutorial-mb-generic-tracker-full.cpp
提出了对先前入门示例的扩展,其中实现了高级功能,如从XML文件读取跟踪器设置或可见性计算。 -
teabox.mpg视频文件 -
teabox.cao3D模型 -
teabox.init
用于计算初始姿势的一些点的3D坐标,该初始姿势用于初始化跟踪器。用户必须在图像中点击相应的2D点以生成该文件。 -
.ppm .png .jpg .jpeg .pgm
用于提示使用者在初始化跟踪器时应该点选那几个点,如:

-
myobject.xml
跟踪器的预设参数,包括相机的标定参数等。
-
8.6.4.2 3D 模型
- 标题中的通用模型指的是3D模型 ??
- 在visp中,物体的CAD模型仅支持cao(.cao)和 vrml(.wrl)格式。
- cao格式是ViSP特有的。
- 只有在安装了Coin第三方的情况下,才支持vrml格式。
- 加载模型
vpMbGenericTracker tracker; tracker.loadModel("teabox.cao"); // 或者: tracker.loadModel("teabox.wrl"); - 如何建立跟踪对象的 vrml 模型 ?
需要第三方库Coin的支持。 - 如何建立跟踪对象的 cao 模型 ?
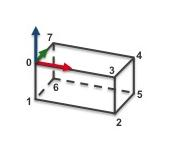
仅支持在visp中使用该种格式,利用点、线、面 来定义物体的3D模型,如:teabox.cao
以上代码定义的3D模型如下:V1 # 3D Points 8 # Number of points 0 0 0 # Point 0: X Y Z 0 0 -0.08 0.165 0 -0.08 0.165 0 0 0.165 0.068 0 0.165 0.068 -0.08 0 0.068 -0.08 0 0.068 0 # Point 7 # 3D Lines 0 # Number of lines # Faces from 3D lines 0 # Number of faces # Faces from 3D points 6 # Number of faces 4 0 1 2 3 # Face 0: [number of points] [index of the 3D points]... 4 1 6 5 2 4 4 5 6 7 4 0 3 4 7 4 5 4 3 2 4 0 7 6 1 # Face 5 # 3D cylinders 0 # Number of cylinders # 3D circles 0 # Number of circles
8.6.4.3 代码解析
-
输入
vpImage<vpRGBa> I_color; vpImage<unsigned char> I; vpImageConvert::convert(I_color, I); -
输出
跟踪器的输出是一个4x4的矩阵,是一个坐标转换矩阵,含义是:被检测对象的机体坐标系到相机坐标系的变换矩阵,包括:旋转 + 位移
例如:
(1)vpHomogeneousMatrix cMo;初始化为4x4的单位矩阵;
(2)vpHomogeneousMatrix cMo(0, 0, 0.75, 0, 0, 0);初始化为4x4的矩阵:根据构造函数vpHomogeneousMatrix(double tx, double ty, double tz, double tux, double tuy, double tuz);可知,前3个参数是3个轴的位移量,后三个参数是3个轴的旋转量。 -
相机的标定参数输入
(1)如果使用的是tutorial-mb-generic-tracker.cpp则修改:
cam.initPersProjWithoutDistortion(839, 839, 325, 243);
(2)如果使用的是tutorial-mb-generic-tracker-full.cpp,则可在myobject.xml文件中设定。 -
加载3D模型
- .cao
tracker.loadModel(objectname + ".cao"); - CAD模型
tracker->loadModel(objectname + ".wrl");
- .cao
-
获取跟踪对象的3D位置信息(基于相机坐标系)
tracker.getPose(cMo); -
初始化跟踪器
- 目的
根据teabox.init中定义的3D坐标点和用户交互获得的2D坐标点,计算物体姿势,然后用于初始化跟踪器。 - 提示
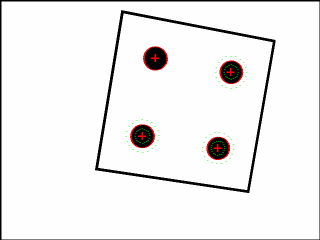
当teabox.png(或.ppm .png .jpg .jpeg .pgm)存在,并且tracker.initClick(I, objectname + ".init", true);中最后一个参数设置为true时,在初始化跟踪器时窗口将显示图片teabox.png以提示使用者需要点选被跟踪目标物体的哪几个点,作为跟踪器的初始化输入。 - 两种方法
-
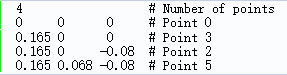
(一)人机交互。通过鼠标点选跟踪对象的几个点(4个以上);
这几个点必须提前指定好,并且以CAD 3维坐标点的形式定义在teabox.init文件中,实质上是从teabox.cao或teabox.wrl中将几个合适的点复制到teabox.init中,例如:
初始化选点的提示图片可查看teabox.png(或.ppm .png .jpg .jpeg .pgm),如:

选哪些点?如何选?才能具有更好的性能效果?
(1)选择的3D点在图像中的投影的空间分布应在图像中尽可能宽(即,它们不应分布在图像中非常小的部分上),当对象是非平面时,它们不应该对齐且不位于同一平面中。
(2)点在图像中的投影必须可见。
(3)通常,我们从.cao文件中复制/粘贴三维点的坐标。 -
(二)从外部提供跟踪目标的初始姿态。
由外部算法(代码)提供物体的初始姿势cMo,用法:tracker.initFromPose(I, cMo);
如何获得物体的初始姿态?:
(1)在线检测,请参考:Tutorial: Markerless generic model-based tracking using AprilTag for.
(2)通过关键点特征点,请参看:Tutorial: Object detection and localization.
(3)通过深度学习…
-
- 目的
8.6.4.4 跟踪器的预设参数、myobject.xml 的用法
例程 tutorial-mb-generic-tracker-full.cpp 可以实现从XML文件中设置跟踪器参数,而不是从源代码中设置跟踪器参数。
-
读取配置文件
xxx.xml:#if defined(VISP_HAVE_PUGIXML) if (vpIoTools::checkFilename(objectname + ".xml")) { std::cout << "Tracker config file : " << objectname + ".xml" << std::endl; tracker.loadConfigFile(objectname + ".xml"); usexml = true; } #endif -
<ecm>标签:边缘检测参数
移动边缘(moving-edge)检测算法的参数设置。这些设置影响检测边缘的性能。<conf> ... <ecm> <mask> <size>5</size> <nb_mask>180</nb_mask> </mask> <range> <tracking>8</tracking> </range> <contrast> <edge_threshold_type>1</edge_threshold_type> <edge_threshold>20</edge_threshold> <mu1>0.5</mu1> <mu2>0.5</mu2> </contrast> <sample> <step>4</step> </sample> </ecm> ... </conf>对应于.cpp中的:
vpMe me; me.setMaskSize(5); me.setMaskNumber(180); me.setRange(8); me.setLikelihoodThresholdType(vpMe::NORMALIZED_THRESHOLD); me.setThreshold(20); me.setMu1(0.5); me.setMu2(0.5); me.setSampleStep(4); tracker.setMovingEdge(me);-
MaskSize
用于检测边缘的卷积核的大小,取值 3、5、7,建议5。 -
MaskNumber
卷积核的数量,影响物体边缘的法线计算精度。建议取值180。 -
Range
设置被跟踪物体的移动边缘的法线的两侧的范围。如果被跟踪对象在两个连续图像祯中的位移很大,则必须增加此参数。 -
LikelihoodThresholdType
估计阈值的类型,这个阈值用于决定检测到的边缘是否判定为有效。
类型的取值范围:
0 即 vpMe::OLD_THRESHOLD,使用旧版本阈值算法(默认)。
1 即vpMe::NORMALIZED_THRESHOLD ,使用新版本的标准化阈值算法(推荐)。 -
Threshold
被检测物体的边缘的估计阈值,这个估计阈值用于决定检测到的边缘是否判定为有效。
取值范围:
当 LikelihoodThresholdType = vpMe::NORMALIZED_THRESHOLD 时取值范围0~255。
如何取值:
当图像中的对比度很小时,应该使用一个较小的值,如5或10。当对比度较大时,例如对应于从黑色到白色的过渡,反之亦然,可以将该值增加到60或100。
当 LikelihoodThresholdType = vpMe::OLD_THRESHOLD时,
旧版本的阈值类型怎么样转换成新版?参看:文档。 -
Mu1
设置检测轮廓所允许的最小图像对比度。我们建议将此值保持为0.5。 -
Mu2
设置检测轮廓所允许的最大图像对比度。我们建议将此值保持为0.5。 -
SampleStep
设置两条邻近边缘之间的最小像素距离。若要增加检测到的边缘的数量,必须减少此参数。 -
SampleStep 和 Range 是两个最重要的参数 !!
-
-
<klt>标签:关键点(特征点)检测参数
用于检测和跟踪关键点的klt跟踪器参数设置。- MaskBorder
为零意味着可以在物体边缘位置上检测到关键点。 - MaxFeatures
要跟踪的关键点的最大特征数量。 - WindowSize
用于优化物体角点(corners)位置的窗口大小。 - Quality
表征图像角点(corners)的最低可接受质量值。质量值小于此参数的拐角将被滤除。这意味着,如果希望检测到更多的关键点,则必须减少此参数。 - MinDistance
检测到的角点(corners)之间的最小欧几里得距离,用于初始化关键点位置。 - HarrisFreeParameter
harris检测器的自由参数。 - BlockSize
用于计算关键点特征的block块的平均大小。 - PyramidLevels
设置最大金字塔级别。如果水平为零,则不计算光流的棱锥。 - 最重要的两个参数是 MinDistance 和 Quality !!
- MaskBorder
-
<camera>标签:相机的标定参数(内参)
相机的标定参数(内参)设置。而且必须是不失真的相机,失真相机(如广角相机)则要经过不失真处理。<conf> ... <camera> <u0>325.66776</u0> <v0>243.69727</v0> <px>839.21470</px> <py>839.44555</py> </camera> ... </conf>对应于
.cpp中:vpCameraParameters cam; cam.initPersProjWithoutDistortion(839.21470, 839.44555, 325.66776, 243.69727); tracker.setCameraParameters(cam); -
<face>标签:可视化配置
由可见性算法使用该配置,该算法用于确定对象的面是否可见。
这里不再细述,详细请参考:Visibility settings -
Clipping settings
略…
8.6.4.5 其他专题:请参考文档
- 故障
- 加载的3D模型是如何被处理的?
- Level of detail (LOD)
The level of detail (LOD) consists in introducing additional constraints to the visibility check to determine if the features of a face have to be tracked or not. Two parameters are used: - CAD model in cao format

- CAD model in wrml format
- How to set a name to a face
- How to save tracking results without vpDisplay
- 如何不考虑特定的多边形
- 如何设置要考虑的自由度
- issues
8.6.4.6 使用案例
- 茶盒teabox

- 立方体卫星

- mmicro model
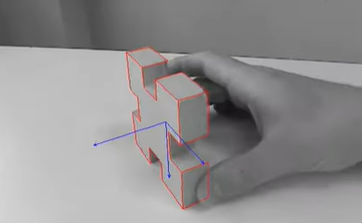
- 乐高模型 with a live camera
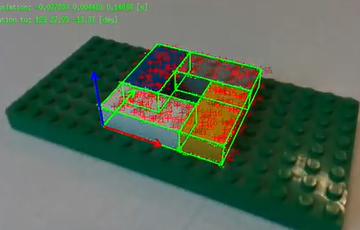
8.6.4.7 例程测试
tutorial-mb-generic-tracker.cpp:读取视频,实现基本的检测;
tutorial-mb-generic-tracker-full.cpp:是前者的拓展,具有更高级的功能如读取xml;
tutorial-mb-generic-tracker-live.cpp:读取相机的视频流,并具有更高级的功能如--learn
tutorial-mb-generic-tracker-save.cpp:??
tutorial-mb-generic-tracker-read.cpp:??
- 帮助:–help
./tutorial-mb-generic-tracker --help - 仅检测物体边缘:
--tracker 0./tutorial-mb-generic-tracker --tracker 0 - 仅检测关键点:
--tracker 1./tutorial-mb-generic-tracker --tracker 1 - 检测边缘、关键点:
--tracker 2./tutorial-mb-generic-tracker --tracker 2 - 指定外部视频文件、物体3D模型文件:
--video --model./tutorial-mb-generic-tracker --video <path1>/myvideo%04.png --model <path2>/myobject.cao - 帮助:
--learn
为例避免后续运行需要再次进行手动初始化,在第一次手动选点初始化跟踪器后,代码会给予当前的1~2祯对被检测物体进行学习,并将学到的信息保存在./tutorial-mb-generic-tracker-live --learnlearning/data-learned.bin文件中,后续的跟踪器初始化不再需要手动进行,如:
./tutorial-mb-generic-tracker-live --model model/lego-square/lego-square.cao --auto_init
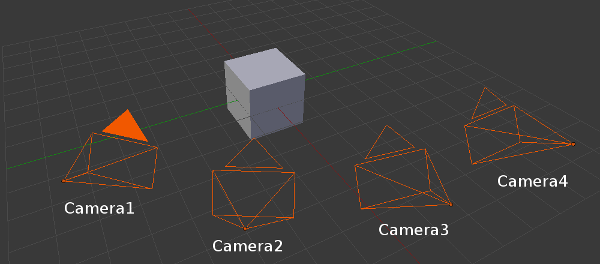
8.6.5 stereo 相机:基于通用模型的目标检测和跟踪
参看:Tutorial: Markerless generic model-based tracking using a stereo camera
多个RGB相机在不同角度拍摄。
其中一个相机作为参考相机,其他相机到参考相机的变换矩阵要已知,如下面的camera1就是参考相机:
8.6.6 RGB-D 相机:基于通用模型的目标检测和跟踪
8.6.6.1 概述
- RGB-D 相机如 Intel RealSense 品牌的 SR300 或 D400 系列。
RGB-D相机在某种意义上是立体相机( stereo 相机)。 - RGB-D 相机可以提供更多的视觉特征:
- 边缘特征:根据RGB信息
- 关键点特征:根据RGB信息
- 深度法线(depth normal):根据深度信息
- 深度密度(depth dense):根据深度信息
- RGB-D相机独有的深度特征:深度法线、深度密度
- 组合视觉特征可以提高目标跟踪的鲁棒性。
例如- 边缘+关键点+深度法线
效果如下:
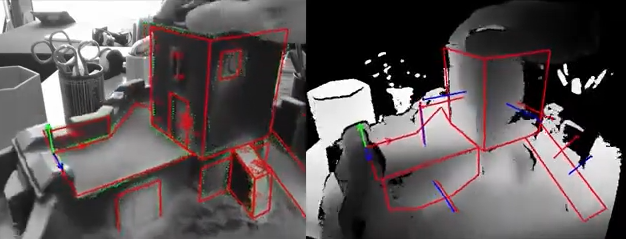
- 边缘+关键点+深度密度(depth dense)
效果如下:
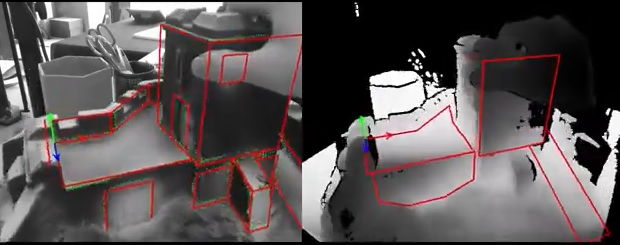
- 边缘+关键点+深度法线
- 需要安装的第三方库
- 安装 Intel Realsense 深度相机的SDK:Depth Camera SDK
- 根据具体情况,安装以下第三方,确保能顺利编译ViSP:
- OpenCV:使用边缘检测、关键点检测、使用KLT跟踪器;以视频流、本地视频文件、图片集等作为视频源的输入。
- PCL:如果RGB-D传感器以点云的形式来提供深度信息,则必须要安装;如果不想将深度信息当做视觉特征,则不需要安装PCL。
- Ogre 3D:允许通过Ogre3D启用高级可视化功能;很难安装。
- Coin 3D:使用 wrml 格式的CAD模型时必须安装Coin 3D;很难安装。
- 建议安装优化版的 BLAS库(例如 OpenBLAS),可以让有关深度密度(dense depth)相关的大矩阵运算能有更好的性能。例如在Ubuntu Xenial上,应该安装libopenblas-dev包。如果需要选择或切换已安装的BLAS库,请参考:Handle different versions of BLAS and LAPACK
- 安装 Intel Realsense 深度相机的SDK:Depth Camera SDK
8.6.6.2 代码解析
-
详细解析请参考文档,这里只做一些必要的讲解。
-
输入
- RGB 信息输入
略… - 深度信息输入
- (1) 传感器的深度信息以点云的形式提供
需要提供一个2D矩阵,其中2D矩阵中的每个元素用于存放与该元素相对应的像素点的深度信息(即相机坐标系下的X、Y、Z坐标值),写法如下:
定义一个容器来实现2D矩阵:
其中640*480为相机分辨率,即像素点的数量。std::vector<vpColVector> pointcloud(640*480);
2D矩阵中的元素用于存放该像素点的坐标信息:vpColVector coordinate(3); coordinate[0] = X; coordinate[1] = Y; coordinate[2] = Z; pointcloud[0] = coordinate; vpColVector coordinate(3); - (2) 传感器的深度信息以深度图的形式提供
深度图:深度图,即一个2D矩阵M,其中每个元素M(u,v)是深度传感器与对象之间的距离 Z(单位m),如:
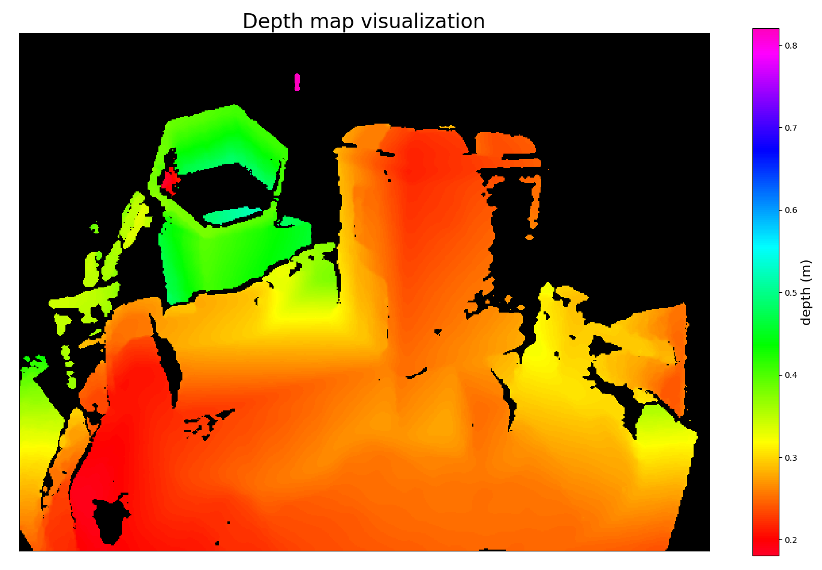
此时需要利用相机的标定参数(内参)来计算每个像素点对应的XYZ坐标信息(相机坐标系下):
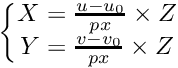
计算得到XYZ后之后的用法与(1)相同。
- (1) 传感器的深度信息以点云的形式提供
- RGB 信息输入
-
定义 跟踪器
- 类型
在visp中跟踪器的全部类型定义在 vpMbGenericTracker::vpTrackerType
中,有以下几类:- EDGE_TRACKER: 仅使用边缘特征的跟踪器
- KLT_TRACKER : 仅使用 KLT 特征
- DEPTH_NORMAL_TRACKER : 仅使用深度法线特征的跟踪器
- DEPTH_DENSE_TRACKER: 仅使用深度密度特征的跟踪器
- 单特征
vpMbGenericTracker tracker(vpMbGenericTracker::EDGE_TRACKER); - 组合特征
vpMbGenericTracker tracker(vpMbGenericTracker::EDGE_TRACKER | vpMbGenericTracker::KLT_TRACKER); - 充分利用RGB-D相机的特性
这将定义一个具有边缘+KLT+深度密度特征的跟踪器。std::vector<int> trackerTypes(2); trackerTypes[0] = vpMbGenericTracker::EDGE_TRACKER | vpMbGenericTracker::KLT_TRACKER; trackerTypes[1] = vpMbGenericTracker::DEPTH_DENSE_TRACKER; vpMbGenericTracker tracker(trackerTypes);
- 类型
待续…
8.6.6.3 应用案例
-
Tracking a 4.2 cm cube

-
Tracking a teabox
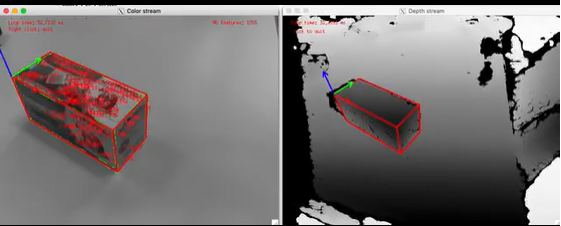
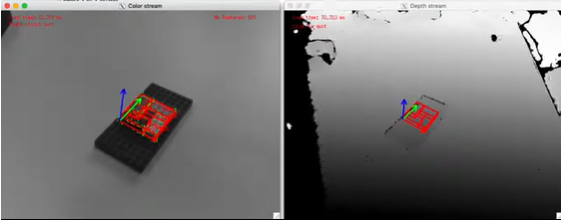
-
Tracking a lego square
8.6.7 RGB相机 + AprilTag:基于通用模型的目标检测和跟踪
- AprilTag是什么?用途?
用途:例如,确定相机的位姿(相对于AprilTag Marker)
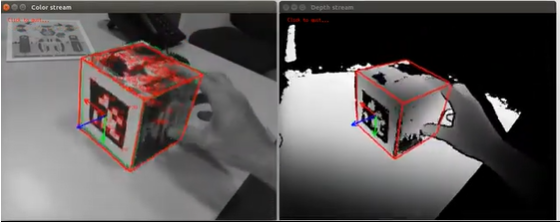
- 优缺点
优点:初始化跟踪器时不需要手动选点!!
缺点:需要将AprilTag贴在被检测的物体上!
8.6.8 在visp中使用JSON
参考:Tutorial: Loading a model-based generic tracker from JSON
功能:
- 以JSON格式存储和加载各种ViSP数据类型。
- 将某个配置好的跟踪器以JSON的形式保存、加载。
- Initializing a tracker from a JSON file
8.6.9 如何使用Blender软件创建仿真数据
Blender:一个免费开源的3D模型创建套件。在Linux, Windows and Mac 中均可使用。
参考文献:Tutorial: How to use Blender to generate simulated data for model-based tracking experiments
功能介绍:
制作一个3D场景,场景中的元素包括:物体的3D模型、以某个姿态拍摄着物体的虚拟RGB-D相机。例如:
- 可以制作物体的3D模型,如茶盒;

- 可以创建一个rgb相机,以获取rgb图
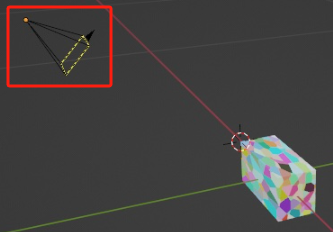
- 可以创建深度传感器,获取深度图
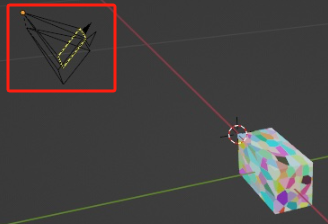
- 让RGB-D相机连续拍摄物体,生成动画,以获取一系列的rgb图像和深度图像,作为仿真数据用来代替真实相机的数据输入!!!


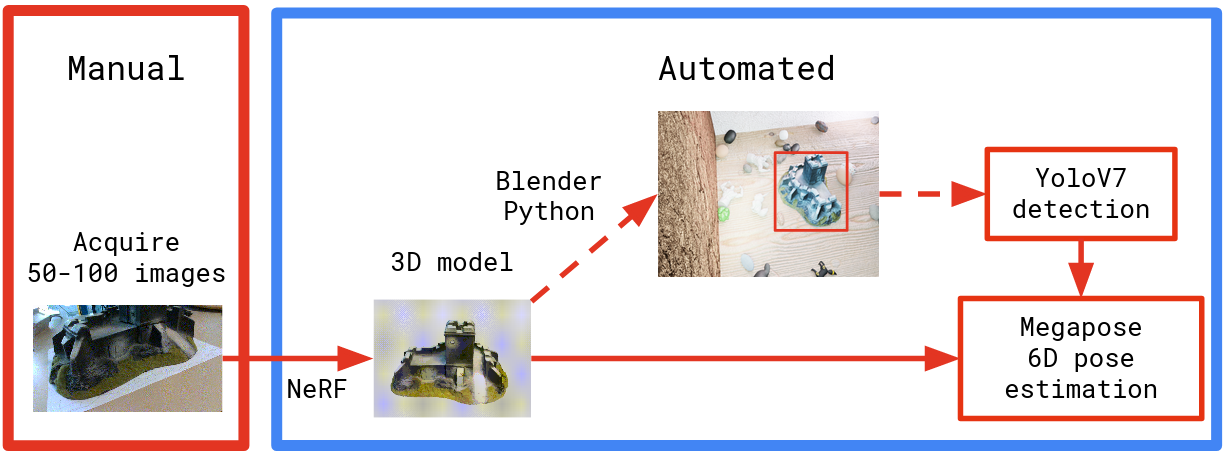
8.6.10 visp + 深度学习算法MegaPose:实现目标跟踪、位姿估计
参考:Tutorial: Tracking with MegaPose

不仅可以进行目标跟踪,还可以进行物体的位姿估计!!!
MegaPose官网:MegaPose
MegaPose:一种针对6自dof物体的位姿估计的深度学习算法。
在visp中MegaPose以client-server的模式运行:
- client:向server发送位姿估计请求,C++语言编写基于visp,运行在没有GPU的PC上也可以与server运行在同一个PC。
- server:将结果发给client,Python语言编写基于MegaPose,运行server的CPU需要GPU。
前提条件:
- RGB或RGB-D相机的内参已知;
- 目标物体所在图像区域的粗略边框(如用YOLOv7实现边框回归);
- 被检测目标物体的3D模型已知;
目的:
- 检测并跟踪目标
- 被检测目标物的3D位姿估计(相机坐标系下的位姿信息)
优点:
- 存在遮挡、光线变化场景、无纹理物体的情况下进行稳健位姿估计;
- 可以使用对象的粗略3D模型;
- 不需要对新对象进行重新训练;
缺点:
- 需要GPU
- vis运行客户端,服务器运行服务端,客户端访问服务器获得计算结果;
- 当目标进入相机视野,需要拿第一张图像祯进行目标检测并初始化跟踪器,这将耗时2~3s.
- 运行速度比较慢,对于 640 x 480 的照片,RTX6000的服务器,初始化需要2s,每一帧的位姿估计需要60~70ms.
- MegaPose算法需要使用某一种目标检测算法(如神经网络、YOLOv7)以进行目标边界回归来进行跟踪器初始化,然后基于此回归边界进行位姿估计。即MegaPose的两个输入包括目标边框(如用YOLOv7实现)和3D模型,如下图
准备工作有哪些: - 被跟踪目标的3D模型制作:Tutorial: Exporting a 3D model to MegaPose after reconstruction with NeRF
- 训练一个用在MegaPose中的目标跟踪网络:Tutorial: Deep learning object detection
- 利用blenderproc软件制作用于训练目标检测神经网络的数据集:Tutorial: Generating synthetic data for deep learning with Blenderproc
- 标定好用于获得视频流的相机的内参。
根据自己的应用案例来准备数据:
参考:Adapting this tutorial for your use case
- 相机内参标定
本篇的 8.4 相机内参标定 小节 - 搭建供MegaPose使用的3D模型
Tutorial: Exporting a 3D model to MegaPose after reconstruction with NeRF - 搭建 目标检测网络(实现目标边框回归,供MegaPose调用)
Tutorial: Deep learning object detection - 用Blender生成仿真数据用来训练目标检测网络
Tutorial: Generating synthetic data for deep learning with Blenderproc.
8.6.11 基于NeRF算法利用图像生成3D模型并导出为MegaPose可以使用的格式
参考文献:Tutorial: Exporting a 3D model to MegaPose after reconstruction with NeRF
用Blender 创建物体的3D模型,并导出成为MegaPose算法可以识别、使用的格式。
本章节重点不在如何创建3D模型,而在如何导出3D模型。
如何利用NeRFs算法实现:根据目标物体的一系列RGB图像来生成目标物体的3D模型。
NeRFs:Neural Radiance Fields(神经辐射场),该算法可以解决的问题:从图像中得到三维模型。算法介绍:NeRF(Neural Radiance Fields)基础知识点。
8.7 图像目标检测(包含边框回归)
8.7.1 关键点(特征点)匹配
参考:Tutorial: Keypoints matching
第三方库:OpenCV
例程:tutorial-matching-keypoint.cpp
功能:
将某祯图像作为参考图像(例如视频流的第一祯),进行关键点检测;
在视频流的下一祯图像中,检测出与参考图像中相同的关键点并显示。

8.7.2 二维码检测
参考:Tutorial: Bar code detection
例程:
tutorial-barcode-detector.cpp
tutorial-barcode-detector-live.cpp
二维码的编码规则有两种:QR Code和Data Matrix。如:

二维码检测结果:
QR码检测:

Data Matrix 码检测:

8.7.3 人脸检测
参考:Tutorial: Face detection
例程:tutorial-face-detector.cpp
原理:OpenCV Haar cascade

8.7.4 目标检测和位姿估计
参考:Tutorial: Object detection and localization
8.7.4 AprilTag marker 检测
参考:Tutorial: AprilTag marker detection
8.8 基于DNN的目标检测
8.8.1 基于DNN的目标检测
参考:Tutorial: Deep learning object detection
类:vpDetectorDNNOpenCV
例程:tutorial-dnn-object-detection-live.cpp
技术栈:OpenCV DNN module.
vpDetectorDNNOpenCV支持的功能:图像分类、边界框回归、类别概率值。其他高级功能请直接使用OpenCV DNN API.
vpDetectorDNNOpenCV支持使用以下分类网络(框架、卷积网络):
- Faster-RCNN
- SSD-MobileNet
- ResNet 10,
- Yolo v3
- Yolo v4,
- Yolo v5,
- Yolo v7
- Yolo v8
- 自定义的神经网络
可以用 JSON 文件 来对vpDetectorDNNOpenCV检测器进行初始化。
依赖:openCV、GPU.
8.8.1 基于DNN的目标检测(使用NVIDIA GPU with TensorRT)
参考:Tutorial: Deep learning object detection on NVIDIA GPU with TensorRT
8.9 图像分割
参考:Segmentation
根据 HSV color scale 来分割
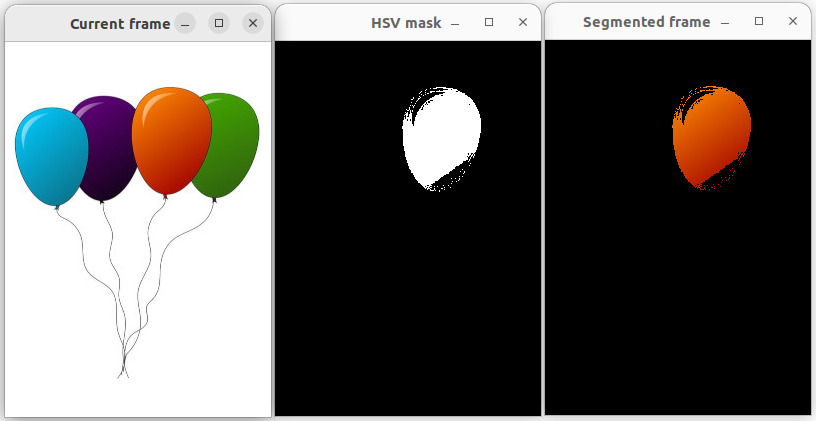

8.10 机器视觉
参考:Computer vision
功能:
- 现实增强中的位姿估计
- 基于平面点、非平面点的位置估计
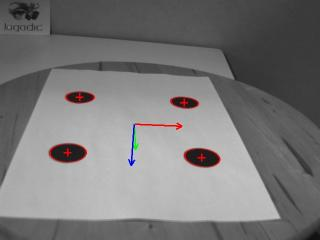
- 基于QRcode二维码的的位姿估计

- 基于 RGB-D 相机的位姿估计

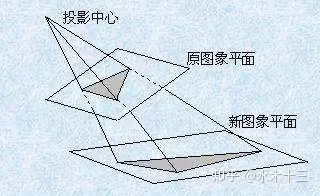
- 单应性矩阵 (Homography) 估计
什么是 Homography ?参考。
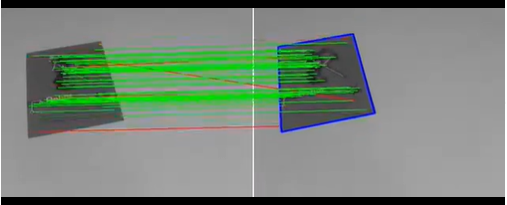
单应矩阵 描述:同一平面下的点,从一个图像到另一个图像的投影映射。

结果:
8.11 视觉伺服
请参考 高阶篇。


















 3574
3574

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









