








堆栈自编码器 Stacked AutoEncoder_浮生了大白的博客-CSDN博客_堆栈自编码器
Based on blog which links were give above.
code explanation for SDAE//That's a nice try
自编码(AutoEncoder)模型及几种扩展之三——SDAE - 知乎
All those materials give a relatively complete infomation about DAE\SDAE\SAE,and in terms the training process of sdae,it's a little bit fuzzy and confusing,here comes my humble understanding.
Training:I'm gonna use a table to interpret this.
SDAE training process
Stacked-DAE Input Hidden_layer Output Loss DAE1 X h1=W1*X X' L(X,X') DAE2 h1 h2=W2*h1 X'' L(h1,X'') DAE3 h2 h3=W3*h2 X''' L(h2,X''') DAE4 h3 h4=W4*h3 X'''' L(h3,X'''')Downstream-finetuing:SDAE training process
| Input x |
| Hidden_layer:h1 |
| Hidden_layer:h2 |
| Hidden_layer:h3 |
| Hidden_layer:h4 |
| Fine-tuning:Downstream_task:softmax,Dense,... |

When you done with training DAE1,you discard output_layer X',you use Hidden_layer h1 as input for DAE2,and the same when you done with training DAE2,you discard the output_layer X'',and you use Hidden_layer h2 as input ...,Alright,that's the process when you train the sub_module for SDAE,and when you done with all the DAEx(x=1,2,3,4),it's time to stack those hidden layer together to inference.
Inference:I'm gonna use a table to interpret this
| Input x |
| Hidden_layer:h1 |
| Hidden_layer:h2 |
| Hidden_layer:h3 |
| Hidden_layer:h4 |
| Fine-tuning:Downstream_task:softmax,Dense,... |
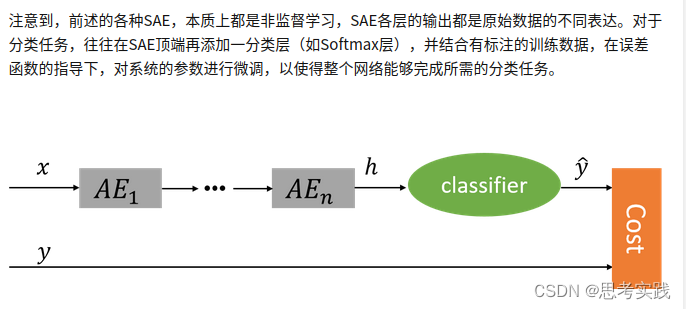
When you done with finetuing on some down-stream task,then you start inference just like any other DNN.
Reference
[自编码器:理论+代码]:自编码器、栈式自编码器、欠完备自编码器、稀疏自编码器、去噪自编码器、卷积自编码器_nana-li的博客-CSDN博客_卷积自编码器原理 //Content is relatively overall,Stacked auto-encoder training-part explanation is little clear.
堆叠式降噪自动编码器(SDA)_Mr_Researcher的博客-CSDN博客_堆叠去噪自动编码器//Explanation is clear
降噪自动编码机(Denoising Autoencoder)_冰涛的博客-CSDN博客_降噪自编码器
自编码(AutoEncoder)模型及几种扩展之三——SDAE - 知乎














 1500
1500











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









