










挑战:目前视觉感知技术的局限性,如有限的分辨率、天气影响和盲点。
协同感知使网联无人车(CAV)、路边设施在通信范围内使用车辆通信(VC)系统共享感知信息,包括GPS和各种传感器数据(雷达,相机和激光雷达数据)。CAV可以接收并汇总来自其他CAV的信息和自己的本地感知数据,以实现协同感知提高自动驾驶系统的安全性和稳定性。
3 Proposed Framework
提出的基于特征融合的协同感知网络结构是从PointPillars扩展而来,以点云为输入,每个点都有属性(x、y、z)坐标和强度。
特征编码 & 特征提取:

1)特征编码–点云数据被划分为多个pillars,每个pillar中的点还包含与pillar中所有点的算术平均值的偏移量和与pillar中心的偏移量的信息,用柱状特征网络(PFN)将点云转换为伪图像;
2)中间特征提取–用特征金字塔网络 (FPN)从伪图像中提取多尺度特征; FPN 包含三个用于多分辨率特征提取的下采样块。然后将从三个下采样块获得的三个特征图进行上采样和拼接起来,从而获得多尺度特征图。
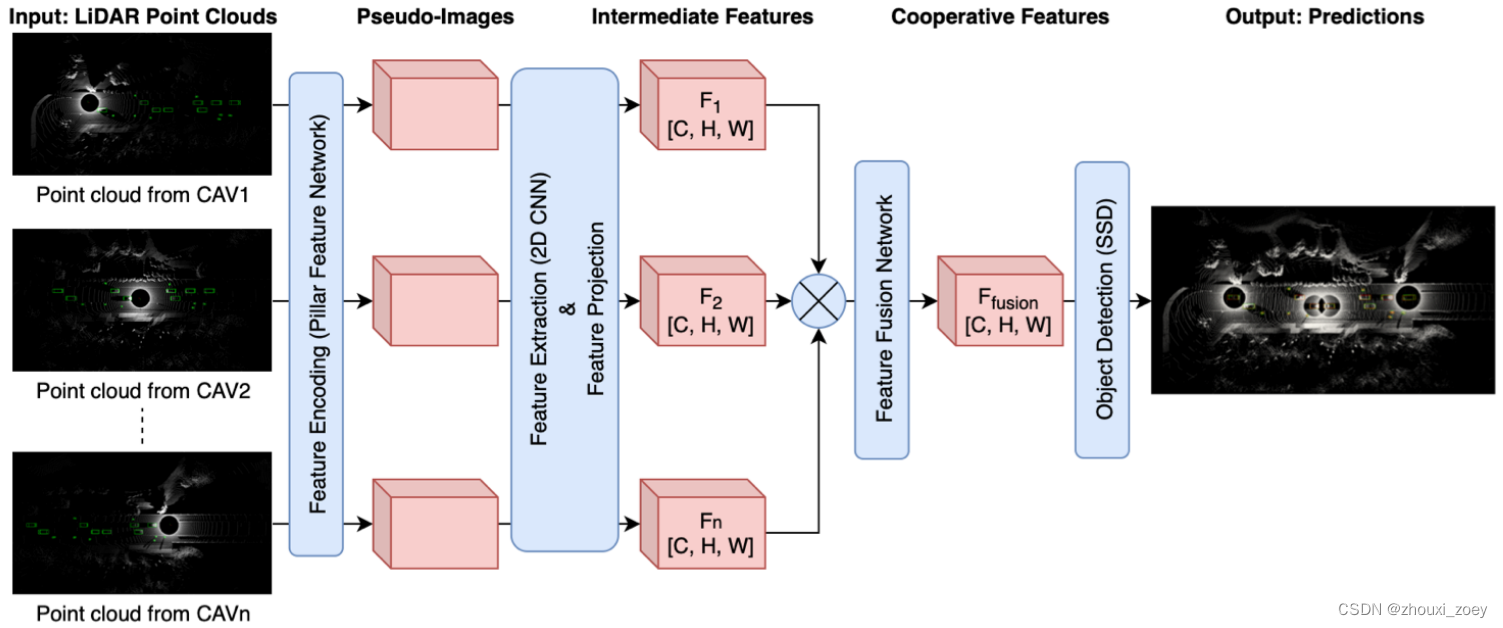
3)特征投影–用LiDAR pose信息将CAV的中间特征图投影到自车坐标上;
4)中间特征融合–用特征融合网络生成组合特征图;
5)3D目标检测–融合特征被输入SSD以预测3D边界框 和 检测到的物体类别的置信度分数。
4 提出的自适应特征融合模型
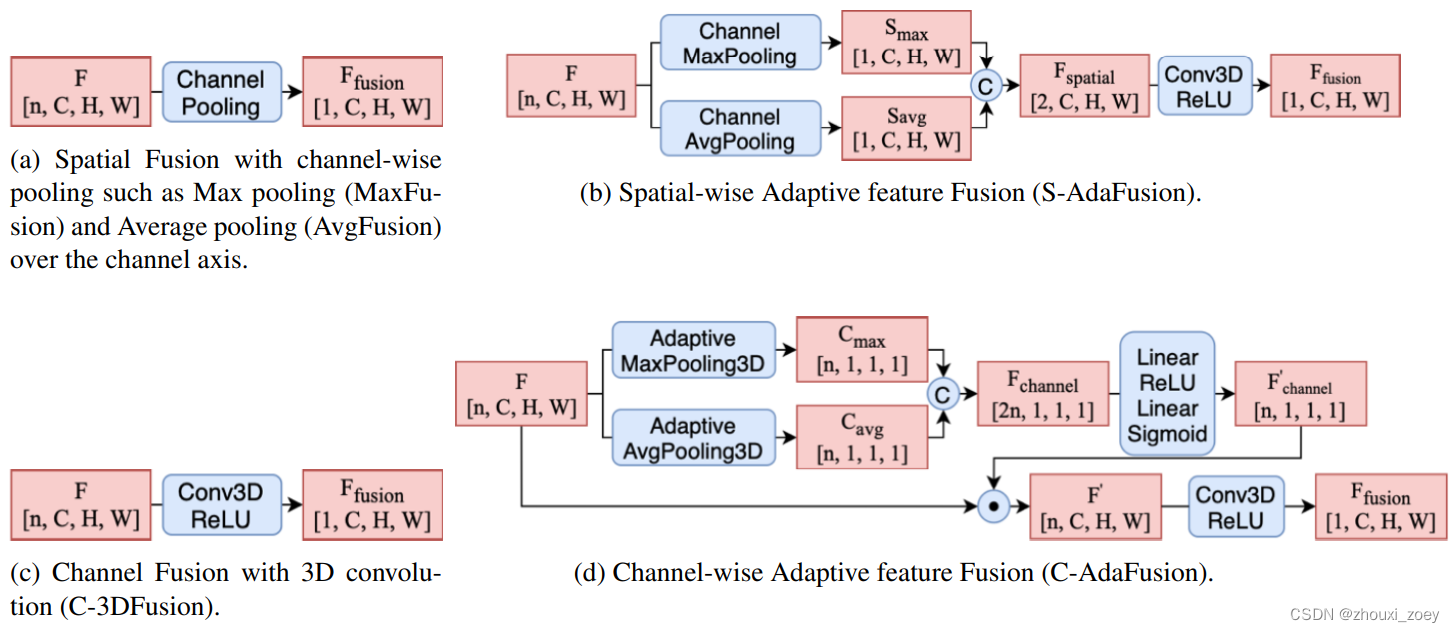
为了优化特征融合模块以实现更好的性能和更高的 3D 目标检测精度,提出了空间上的和通道上的特征融合模型。
4.1 空间特征融合
4.1.1 MaxFusion 和 AvgFusion
为了融合特征图,将一个简单的 reduction operator(例如 max 或 mean)应用于重叠特征,这两种融合方法称为 MaxFusion 和 AvgFusion,它们分别在通道轴上计算最大池化和平均池化,得到融合特征图 Ffusion ∈ R1×C×H×W。

4.1.2 SAdaFusion
提出了 Spatial-wise Adaptive feature Fusion(SAdaFusion),其自适应地利用最大池化和平均池化生成的空间特征。
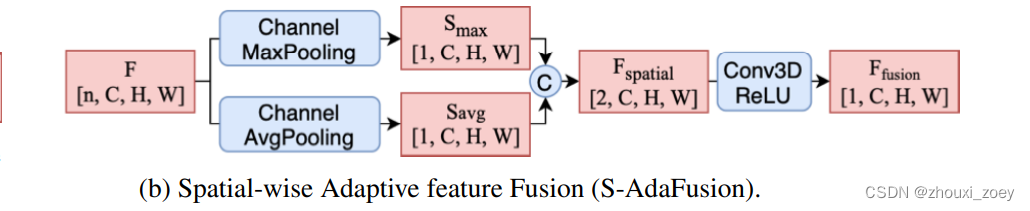
首先,通过沿着第一通道轴计算最大池化和平均池化,将输入特征图 F ∈ Rn×C×H×W分解为 Smax ∈ R1×C×H×W 和 Savg ∈ R1×C×H×W。将两个特征图拼接在一起,得到一个 4D 张量 Fspatial ∈ R2×C×H×W,其中包含来自原始聚合的中间特征图F的两种空间信息。然后,使用带有 ReLU 激活函数的 3D 卷积进行进一步的特征选择和降维。
4.2 通道特征融合
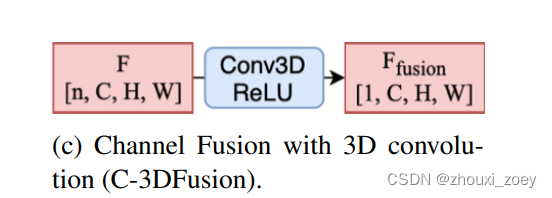
4.2.1 C-3DFusion
对于输入的 4D 张量 F ∈ Rn×C×H×W,可以使用 3D CNN 来提取通道特征并减少输入特征通道的数量。 3D CNN 的输入通道数等于 CAV 的最大数量,而输出通道将等于 1,代表一个组合特征集。
4.2.2 CAdaFusion
受通道注意模块 SENet 的启发,提出了一个 Channel-wise Adaptive feature Fusion (CAdaFusion) 模块,该模块可以通过使用通道信息来选择和融合中间特征图。

全局池化用于在通道描述符channel-wise descriptor中压缩全局信息。利用 3D 自适应最大池化和平均池化来提取两个channel-wise descriptor Cmax ∈ Rn×1×1×1 和 Cavg ∈ Rn×1×1×1。然后,将两个向量拼接在一起,通过具有 ReLU 和 Sigmoid 激活函数的线性层得到通道权重 F’channel ∈ Rn×1×1×1。输入特征图 F ∈ Rn×C×H×W 在通道维度上乘以可学习的通道权重 F’channel ∈ Rn×1×1×1 生成新的特征表示 F’∈ Rn×C×H×W。最终,通过 3D CNN 进行通道缩减后获得融合特征图 Ffusion ∈ R1×C×H×W 。
数据集
CODD数据集中一个有四辆CAV的十字路口的场景样例: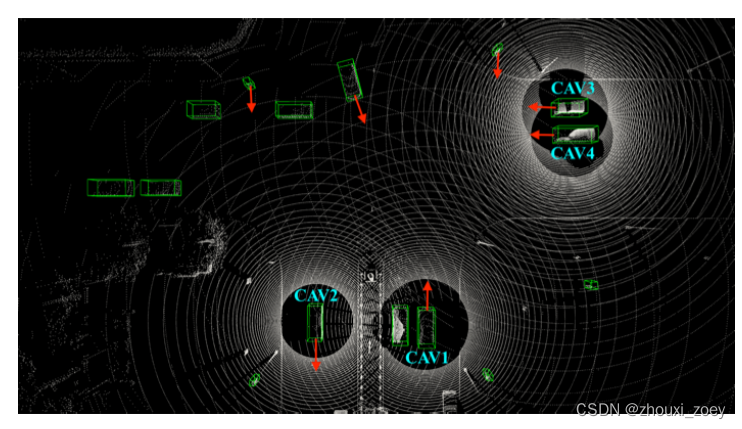
假设CAV1为ego车辆:
1)四个CAVs处理他们的LiDAR点云,并在它们的本地系统中提取中间特征图;2)其他三个CAVs将他们提取的特征图与LiDAR pose信息一起传送给CAV1;
3)CAV1接收到这些信息后,将这三个特征图投影到它自己的坐标系中,并将这些信息与它自己的感知信息聚合在一起,进行3D目标检测。
总结
- 提出了一个基于中间融合的轻量级协同感知框架,包括三个用于协同感知的可训练的特征融合模型,可以从多个CAV中自适应地选择特征。所提出的Spatial-wise Adaptive feature Fusion(S-AdaFusion)模型在OPV2V数据集的两个子集上(默认的CARLA Towns用于车辆检测,Culver City用于领域自适应Domain Adaptation)的表现优于其他最先进的模型。
- 使用两个公共基准数据集对所提出的模型进行验证,包括车辆检测,行人检测和域适应(在OPV2V数据集上进行了车辆检测和域适应的实验,在CODD数据集上进行了车辆和行人的检测)。















 1001
1001











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









