






 本文介绍了一种使用Seurat进行10X单细胞转录组和10X单细胞ATAC-seq数据的联合分析方法,包括数据预处理、锚点识别、细胞注释转移以及共嵌入可视化。通过Signac工具包,作者展示了如何整合这两种异源数据以增强对细胞特性和功能的理解。
本文介绍了一种使用Seurat进行10X单细胞转录组和10X单细胞ATAC-seq数据的联合分析方法,包括数据预处理、锚点识别、细胞注释转移以及共嵌入可视化。通过Signac工具包,作者展示了如何整合这两种异源数据以增强对细胞特性和功能的理解。
hello,大家好,这是第一次和大家分享有关10X单细胞和10XATAC的联合分析,我们这一次来深入看一下10X单细胞和10XATAC的联合分析方法(Seurat)。
Integrating scRNA-seq and scATAC-seq data(最新的内容是3月18日完成的)。
单细胞转录组学已经改变了我们表征细胞状态的能力,但是对生物学的深入了解不仅需要分类学的分类列表(也就是对细胞类型的研究)。随着测量不同细胞形态的新方法的出现,一个关键的分析挑战是整合这些数据集以更好地理解细胞的特性和功能。 例如,我们可以在同一生物系统上执行scRNA-seq和scATAC-seq实验,并用相同的细胞类型一致地注释两个数据集。 由于scATAC-seq数据集难以注释,原因在于单细胞分辨率下收集的基因组数据稀疏,并且scRNA-seq数据中缺乏可解释的基因标记,因此该分析尤其具有挑战性。
在Stuart, Butler et al, 2019中,2019年,我们介绍了整合从同一生物系统收集的scRNA-seq和scATAC-seq数据集的方法,并在此示例中演示了这些方法。 特别是,我们演示了以下分析:
- 如何使用带注释的scRNA-seq数据集标记来自scATAC-seq实验的细胞
- 如何从scRNA-seq和scATAC-seq共同可视化(共嵌入)细胞
- 如何将scATAC-seq细胞投射到源自scRNA-seq实验的UMAP坐标上
下面的示例使用了Signac软件包,该软件包最近开发用于分析以单细胞分辨率(包括scATAC-seq)收集的染色质数据集。 大家可以参考signac,多多学习。
我们使用来自10x Genomics的约12,000个人PBMC“multiome”数据集演示了这些方法。 在此数据集中,scRNA-seq和scATAC-seq图谱同时收集于相同细胞。
出于本注释的目的,将数据集视为源自两个不同的实验,并将其集成在一起。 由于它们最初是在同一同一细胞中测量的,因此提供了一个基本事实,我们可以用来评估积分的准确性。 我们强调,此处我们将多基因组数据集用于演示和评估目的,并且可以将这些方法应用于分别收集的scRNA-seq和scATAC-seq数据集(这也就是说即使一个样本分成两部分分别进行10X单细胞转录组和10X单细胞ATAC,也可以用这个方法)。 我们提供了一个单独的加权最近邻小插图(WNN)(这个在Seurat最新的方法中),它描述了多组单细胞数据的分析策略。
Load in data and process each modality individually(首先单独处理)
PBMC多组学数据集可从10x基因组学获得。 为了方便加载和浏览(当然,本身软件就有提供)。 我们分别加载RNA和ATAC数据,并假设这些配置文件是在单独的实验中测量的。 我们在WNN注释中对这些单元进行了注释,并且注释也包含在SeuratData中。
加载包~~~
library(SeuratData)
# install the dataset and load requirements
InstallData("pbmcMultiome")
library(Seurat)
library(Signac)
library(EnsDb.Hsapiens.v86)
library(ggplot2)
library(cowplot)
载入数据和分开处理
# load both modalities
pbmc.rna <- LoadData("pbmcMultiome", "pbmc.rna")
pbmc.atac <- LoadData("pbmcMultiome", "pbmc.atac")
# repeat QC steps performed in the WNN vignette
pbmc.rna <- subset(pbmc.rna, seurat_annotations != "filtered")
pbmc.atac <- subset(pbmc.atac, seurat_annotations != "filtered")
# Perform standard analysis of each modality independently RNA analysis
pbmc.rna <- NormalizeData(pbmc.rna)
pbmc.rna <- FindVariableFeatures(pbmc.rna)
pbmc.rna <- ScaleData(pbmc.rna)
pbmc.rna <- RunPCA(pbmc.rna)
pbmc.rna <- RunUMAP(pbmc.rna, dims = 1:30)
# ATAC analysis add gene annotation information
annotations <- GetGRangesFromEnsDb(ensdb = EnsDb.Hsapiens.v86)
seqlevelsStyle(annotations) <- "UCSC"
genome(annotations) <- "hg38"
Annotation(pbmc.atac) <- annotations
# We exclude the first dimension as this is typically correlated with sequencing depth
pbmc.atac <- RunTFIDF(pbmc.atac)
pbmc.atac <- FindTopFeatures(pbmc.atac, min.cutoff = "q0")
pbmc.atac <- RunSVD(pbmc.atac)
pbmc.atac <- RunUMAP(pbmc.atac, reduction = "lsi", dims = 2:30, reduction.name = "umap.atac", reduction.key = "atacUMAP_")
这个地方我们注意一下,10X单细胞数据和10XATAC数据先是分别进行分析的。
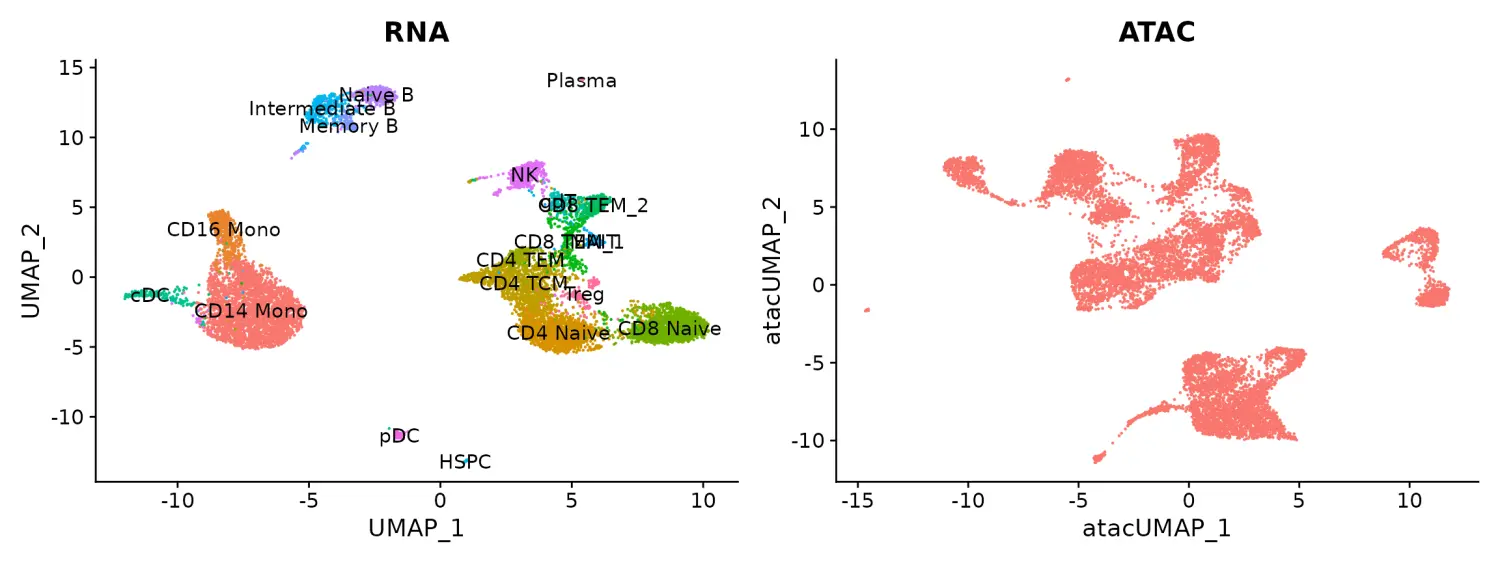
现在,我们绘制两种模态的结果。 先前已根据转录组状态对细胞进行了注释。 我们将预测scATAC-seq单元的注释。
p1 <- DimPlot(pbmc.rna, group.by = "seurat_annotations", label = TRUE) + NoLegend() + ggtitle("RNA")
p2 <- DimPlot(pbmc.atac, group.by = "orig.ident", label = FALSE) + NoLegend() + ggtitle("ATAC")
p1 + p2
Identifying anchors between scRNA-seq and scATAC-seq datasets(看来整合的方法和单细胞整合实一样的)。
为了识别scRNA-seq和scATAC-seq实验之间的“anchor”,我们首先通过使用GeneActivity量化上游2 kb区域和基因体中的ATAC-seq计数,来生成每个基因的转录活性的粗略估计GeneActivity() 函数在Signac程序包中。 然后将来自scATAC-seq数据的随后的基因活性得分与来自scRNA-seq的基因表达定量一起用作规范相关分析的输入。 我们对从scRNA-seq数据集确定为高度可变的所有基因进行此量化。
# quantify gene activity
gene.activities <- GeneActivity(pbmc.atac, features = VariableFeatures(pbmc.rna))
# add gene activities as a new assay
pbmc.atac[["ACTIVITY"]] <- CreateAssayObject(counts = gene.activities)
# normalize gene activities
DefaultAssay(pbmc.atac) <- "ACTIVITY"
pbmc.atac <- NormalizeData(pbmc.atac)
pbmc.atac <- ScaleData(pbmc.atac, features = rownames(pbmc.atac))
然后识别anchor
# Identify anchors
transfer.anchors <- FindTransferAnchors(reference = pbmc.rna, query = pbmc.atac, features = VariableFeatures(object = pbmc.rna),
reference.assay = "RNA", query.assay = "ACTIVITY", reduction = "cca")
Annotate scATAC-seq cells via label transfer(利用单细胞数据对ATAC进行注释)
识别anchor后,我们可以将注释从scRNA-seq数据集转移到scATAC-seq细胞上。 注释存储在seurat_annotations字段中,并作为refdata参数的输入提供。 输出将包含一个矩阵,其中包含每个ATAC序列信元的预测和置信度分数。
celltype.predictions <- TransferData(anchorset = transfer.anchors, refdata = pbmc.rna$seurat_annotations,
weight.reduction = pbmc.atac[["lsi"]], dims = 2:30)
pbmc.atac <- AddMetaData(pbmc.atac, metadata = celltype.predictions)
这里大家不要大意,看一看上面的dims参数,差异最大的维度1没有选择,那为什么要为减少和权重选择不同的(非默认)值?
在FindTransferAnchors()中,当在scRNA-seq数据集之间传输时,我们通常将PCA结构从参考集投影到新的数据集上。 但是,当进行多组学的数据分析时,我们发现CCA更好地捕获了共享特征相关结构,因此在此处设置了reduce ='cca'。 此外,默认情况下,在TransferData()中,我们使用相同的投影PCA结构来计算会影响每个单元格预测的锚点本地邻域的权重。 在从scRNA-seq到scATAC-seq传输的情况下,我们使用通过在ATAC-seq数据上计算LSI获悉的低维空间来计算这些权重,因为这样可以更好地捕获ATAC-seq数据的内部结构。
执行命令后,ATAC-seq单元具有预测的注释(从scRNA-seq数据集转移)存储在预测的ID字段中。 由于这些细胞是用多基因组试剂盒测量的,因此我们还有一个可以用于评估的真实注释。 您可以看到预测的注释和实际的注释非常相似。
pbmc.atac$annotation_correct <- pbmc.atac$predicted.id == pbmc.atac$seurat_annotations
p1 <- DimPlot(pbmc.atac, group.by = "predicted.id", label = TRUE) + NoLegend() + ggtitle("Predicted annotation")
p2 <- DimPlot(pbmc.atac, group.by = "seurat_annotations", label = TRUE) + NoLegend() + ggtitle("Ground-truth annotation")
p1 | p2
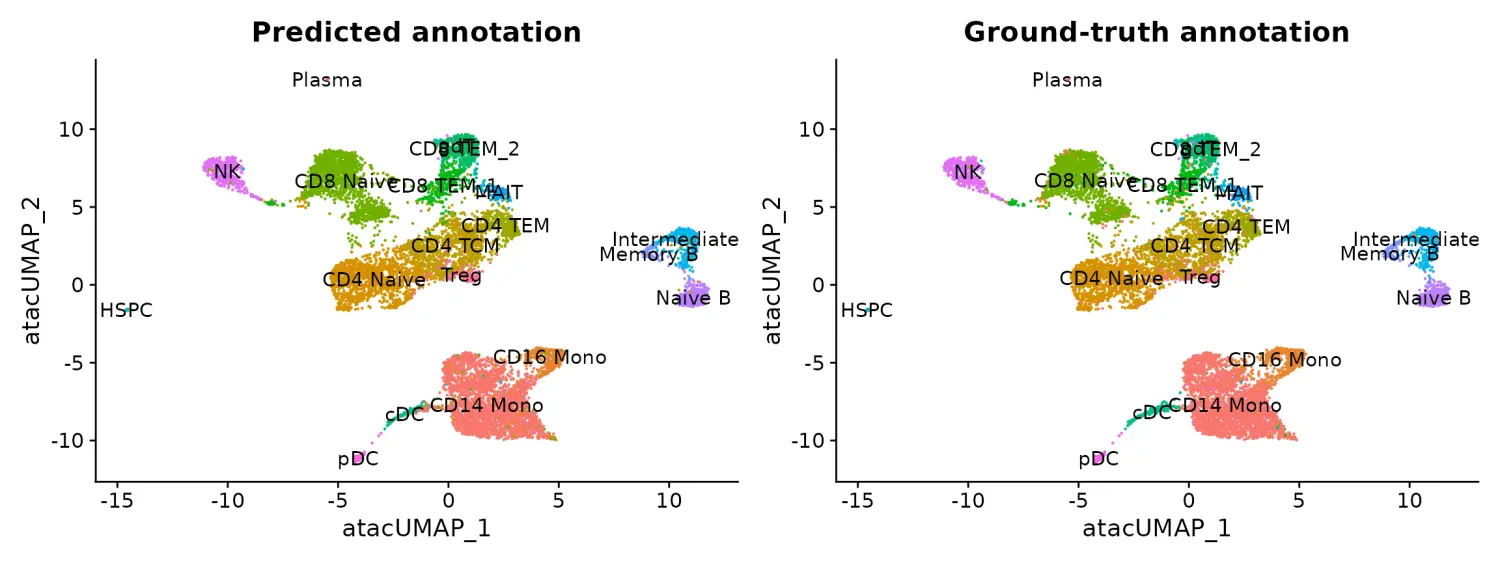
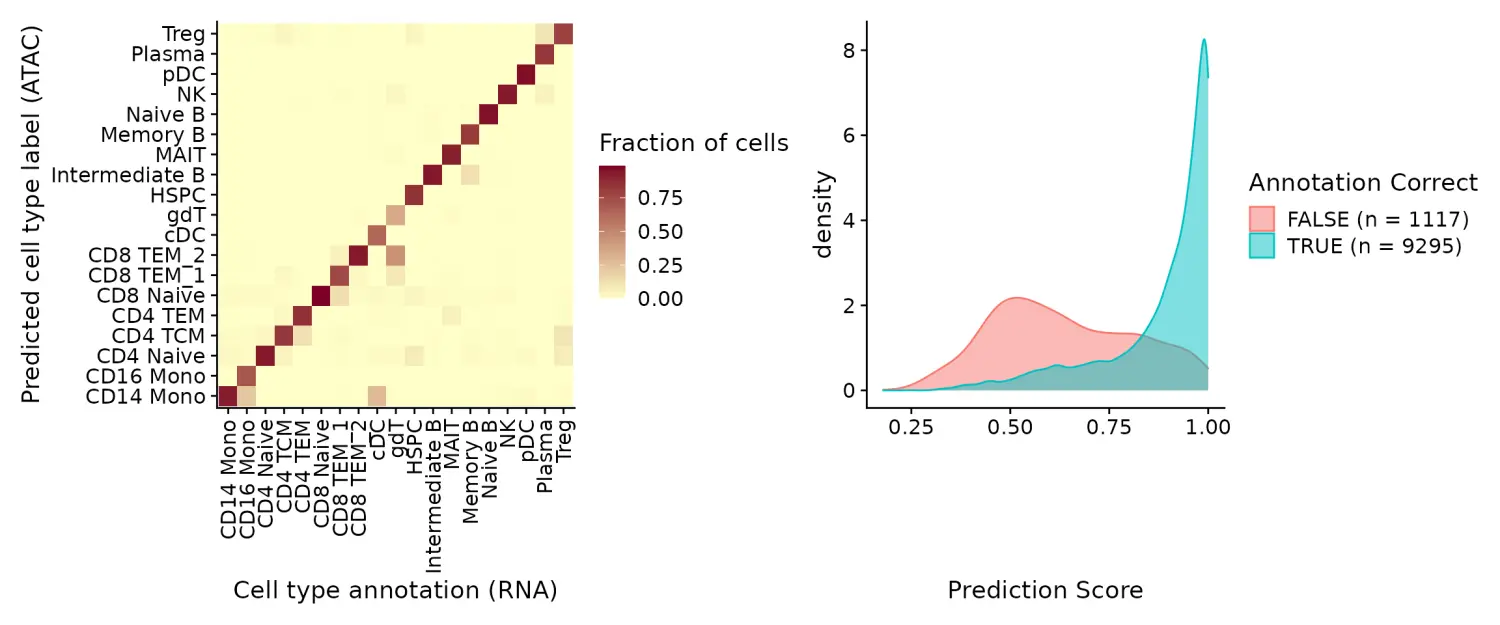
在此示例中,可通过scRNA-seq整合〜90%正确预测scATAC-seq谱图的注释。 此外,predict.score.max字段可量化与我们预测的注释相关的不确定性。 我们可以看到正确注释的单元格通常与较高的预测分数(> 90%)相关联,而错误注释的单元格与较低的预测分数(<50%)相关联。 错误的分配也往往会反映出密切相关的细胞类型(即 Intermediate vs. Naive B cells)。
predictions <- table(pbmc.atac$seurat_annotations, pbmc.atac$predicted.id)
predictions <- predictions/rowSums(predictions) # normalize for number of cells in each cell type
predictions <- as.data.frame(predictions)
p1 <- ggplot(predictions, aes(Var1, Var2, fill = Freq)) + geom_tile() + scale_fill_gradient(name = "Fraction of cells",
low = "#ffffc8", high = "#7d0025") + xlab("Cell type annotation (RNA)") + ylab("Predicted cell type label (ATAC)") +
theme_cowplot() + theme(axis.text.x = element_text(angle = 90, vjust = 0.5, hjust = 1))
correct <- length(which(pbmc.atac$seurat_annotations == pbmc.atac$predicted.id))
incorrect <- length(which(pbmc.atac$seurat_annotations != pbmc.atac$predicted.id))
data <- FetchData(pbmc.atac, vars = c("prediction.score.max", "annotation_correct"))
p2 <- ggplot(data, aes(prediction.score.max, fill = annotation_correct, colour = annotation_correct)) +
geom_density(alpha = 0.5) + theme_cowplot() + scale_fill_discrete(name = "Annotation Correct",
labels = c(paste0("FALSE (n = ", incorrect, ")"), paste0("TRUE (n = ", correct, ")"))) + scale_color_discrete(name = "Annotation Correct",
labels = c(paste0("FALSE (n = ", incorrect, ")"), paste0("TRUE (n = ", correct, ")"))) + xlab("Prediction Score")
p1 + p2
Co-embedding scRNA-seq and scATAC-seq datasets(联合)
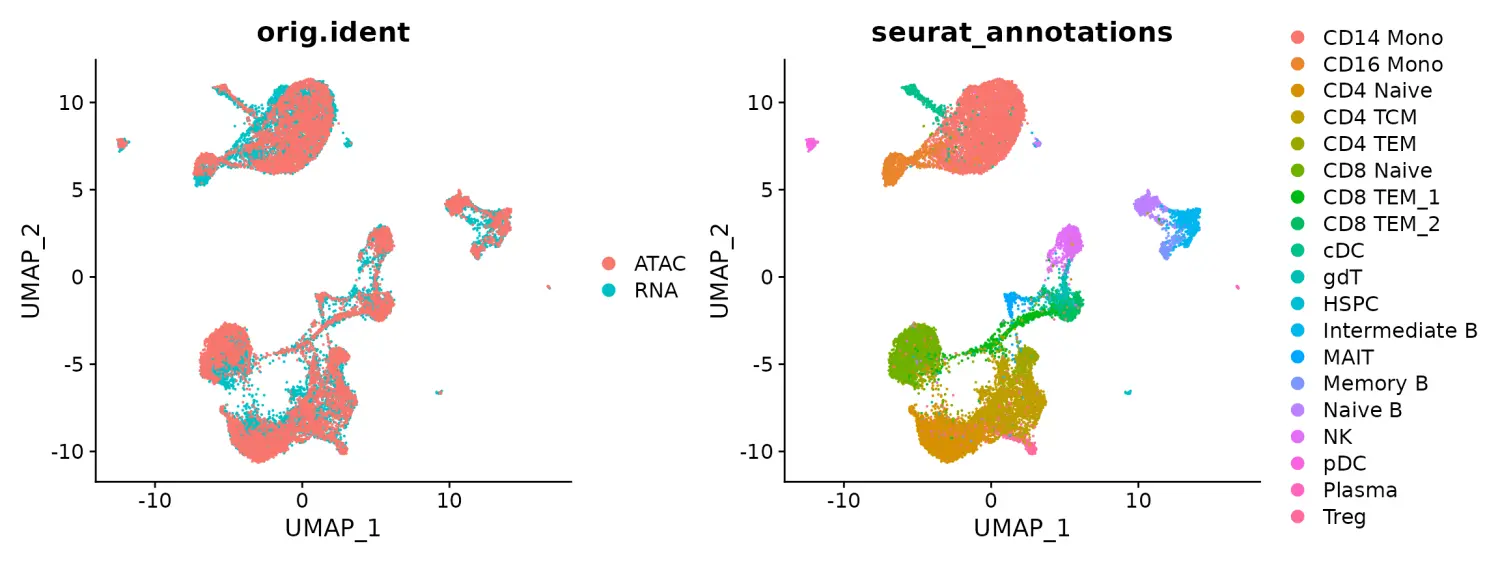
除了跨模式转移标记外,还可以在同一图中可视化scRNA-seq和scATAC-seq细胞。 注意此步骤主要用于可视化,并且是可选步骤。 通常,当我们在scRNA-seq和scATAC-seq数据集之间进行整合分析时,我们主要集中在如上所述的标签转移上。 我们在下面展示了用于共嵌入的工作流程,并再次强调了这是出于演示目的,尤其是在这种特殊情况下,实际上在同一单元中测量了scRNA-seq图谱和scATAC-seq图谱。
为了执行共嵌入,我们首先根据先前计算的锚点将RNA表达“估算”到scATAC-seq细胞中,然后合并数据集
# note that we restrict the imputation to variable genes from scRNA-seq, but could impute the
# full transcriptome if we wanted to
genes.use <- VariableFeatures(pbmc.rna)
refdata <- GetAssayData(pbmc.rna, assay = "RNA", slot = "data")[genes.use, ]
# refdata (input) contains a scRNA-seq expression matrix for the scRNA-seq cells. imputation
# (output) will contain an imputed scRNA-seq matrix for each of the ATAC cells
imputation <- TransferData(anchorset = transfer.anchors, refdata = refdata, weight.reduction = pbmc.atac[["lsi"]],
dims = 2:30)
pbmc.atac[["RNA"]] <- imputation
coembed <- merge(x = pbmc.rna, y = pbmc.atac)
# Finally, we run PCA and UMAP on this combined object, to visualize the co-embedding of both
# datasets
coembed <- ScaleData(coembed, features = genes.use, do.scale = FALSE)
coembed <- RunPCA(coembed, features = genes.use, verbose = FALSE)
coembed <- RunUMAP(coembed, dims = 1:30)
DimPlot(coembed, group.by = c("orig.ident", "seurat_annotations"))
Seurat目前还是很权威的,希望我们多多关注Seurat推出的方法。
生活很好,有你更好

















 1471
1471

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









