







Ultra Fast Structure-aware Deep Lane Detection
目前车道线检测算法的难点
1、计算成本高,需要更低的计算成本处理每个摄像头的输入。
2、no-visual-clue(无视觉线索),有严重遮挡和极端光照条件。车道线检测迫切需要更高层次的车道语义信息。基于深度学习的图像分割方法比传统的图像处理方法具有更强的语义表示能力。
SCNN针对这一问题,提出了相邻像素之间的消息传递机制。这显著提高了深度分割方法的性能,但是由于像素间密集的通信,这种消息传递需要更多的计算成本。
车道表示为分割的二进制特征,而不是直线或曲线。尽管深度分割方法在车道检测领域占主导地位,但这种表示方式难以明确的利用先验信息,如车道的平整度。
作者提出了一种以极快速度和无视觉线索为目标的新型车道检测方法。基于提出的公式,设计了一种结构损失,以明确利用车道线的先验信息。具体而言,公式是使用全局特征来选择图像在预定义行上的车道线位置,而不是根据局部感受野分割车道线的每个像素,这大大降低了计算的成本,位置选择示意图如图二所示。

左右车道的选择示意图。在右边部分,详细展示了行的选择。行anchor是预定义的行位置,本文的公式是在每个行anchor上进行水平选择。在图像的右侧,引入了一个背景gridding cell(网格单元)来表示该行没有车道。
对于no-visual-clue问题,因为本文的公式是基于全局特征进行行选择的过程,在全局特征的帮助下,方法得到了整个图像的感受野。与基于有限的感受野的分割方法相比,来自不同位置的视觉线索和消息可以被学习和利用。
车道检测的新公式
本文的方法可以同时解决速度和无视觉线索问题。基于这个公式,车道表示为不同行的选择位置,而不是分割图。通过优化选定位置的关系,即结构损失,直接利用车道的特性,如刚性和平滑度。
使用全局特征在每个预定义行上选择车道的正确位置。在本文中,车道被描述为预定义行(即行anchor)处水平位置的变化。为了表示位置,第一步是网格化。在每行anchor点上,该位置分为许多单元。这样,车道的检测可以描述为在预定义的行anchor上选择某些单元。假设最大车道数为C,行锚数为h,网格单元数为w。假设X是全局图像特征,并且是用于选择第i车道第j行锚点上车道位置的分类器。那么车道线的预测可以写成: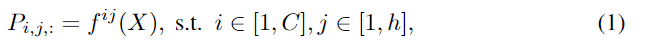
其中Pij:向量表示为第i车道第j行锚点选择(w + 1)个网格单元的概率。假设Tij :是正确位置的选择。则公式的损失函数可以写成:
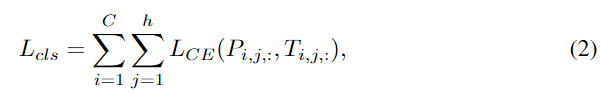
其中LCE是交叉熵损失。公式之所以由(w + 1)维分类而不是w维分类组成,是因为使用了一个维度来表示不存在车道。本文的方法基于全局特征预测了每行anchor点上所有位置的概率分布,然后可以根据概率分布选择正确的位置。

在分割任务上,最终的特征图的大小是 HxWxC 。分类是要沿着 C方向的,C方向的向量代表一个像素位置的特征向量属于哪一个类别;在本方法中,最终的特征图的大小是 hx(w+1)xC 。h是要在垂直方向上采样的行的数量(row anchor),h<H;w是行方向上车道线候选点的位置(grid cell)的数量,w<W。C是车道线的数量。分类是沿着w方向的,即对每个车道线,在其预设的垂直方向h上,计算其出现在水平位置上每个grid cell中的概率。
从感受野的角度来看,本文的公式具有整个图像的感受野,远大于分割方法。来自图像其他位置的上下文信息和消息可用于解决无视觉提示问题。从学习的角度来看,还可以根据公式使用结构损失来学习诸如车道的形状和方向之类的先验信息。局部感受野小导致的复杂车道线检测困难问题。由于本文的方法不是分割的全卷积形式,是一般的基于全连接层的分类,它所使用的特征是全局特征。这样就直接解决了感受野的问题,对于本文的方法,在检测某一行的车道线位置时,感受野就是全图大小。因此也不需要复杂的信息传递机制就可以实现很好的效果。
另一个好处是,这种公式化以基于行的方式对车道位置进行建模,这使我们有机会明确地建立不同行之间的关系。由于分割方法得到的为车道线的二值分割图,其结构是逐像素建模,因此几乎无法实现对上述高层语义(平滑、刚性)层级的约束,可以缓解由low-level像素级建模和车道的high-level 长结构引起的原始语义鸿沟。

车道结构损失
除了分类损失外,还提出了两个损失函数,旨在模拟车道线中点的位置关系。这样,有利于学习结构信息。
第一个损失函数是从车道是连续的事实得出的,也就是说,相邻行锚中的车道点应彼此靠近。在公式中,车道的位置由分类矢量表示。因此,通过限制分类向量在相邻行锚上的分布来实现平滑性。这样,相似度损失函数可以定义为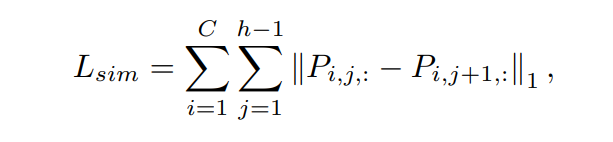
Pij:表示了对j行anchor的预测,这里使用L1范式来进行距离的约束。
另一个结构损失函数着眼于车道线的形状。一般来说,大多数车道线是直的。即使对于弯道,经过透视变换,大部分弯道仍然可以看作是直的。将相邻行间的二阶差分定义为车道线的形状。由于车道线大多是直线,因此其二阶差分为0。所以本文利用二阶差分方程约束车道线的形状,在直线情况下为0。
为了考虑形状,需要计算每一行anchor的位置,直观的想法是通过找到最大响应峰值从分类预测中找到位置,对于任何车道线索引i和行anchor索引j,其位置Loc i,j可以表示为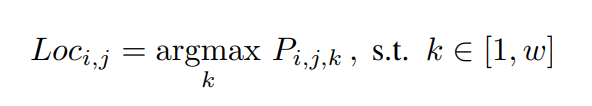
其中,k是一个整数,表示位置索引。需要注意的是,我们没有在背景网格单元中计数,并且位置索引k只在1到w之间,而不是w+1。
然而argmax函数是不可微的,不能再进一步的约束下使用。在分类表述中,类没有明显的顺序,并且很难在不同的行锚之间建立关系。为了解决这个问题,使用预测的期望值作为位置的近似值。而预测的期望值由softmax函数得到。用softmax得到不同位置的概率。
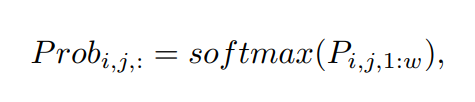
P i,j,1:w是一个w维向量,Prob i,j:表示每一个位置的概率,不包含背景单元,计算范围为1到w,位置的期望可以写成
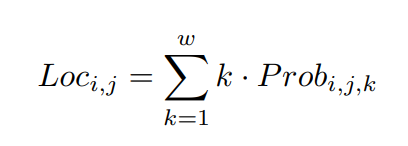
Prob i,j,k:第i个车道,第j个行anchor,第k个位置的概率。这种定位方法有两方面的好处,第一个是期望函数是可微的,第二个是利用离散随机变量恢复连续位置。
二介差分约束可以写成:

其中Loci,j是第i个车道上的位置,即第j行anchor。之所以使用二阶差分而不是一阶差分,是因为一阶差分在大多数情况下并不为零。所以网络需要额外的参数来学习车道位置的一阶差分的分布。此外,二阶差分的约束相对比一阶差分的约束要弱,因此导致车道不直时影响较小。最后,整体结构损失为:
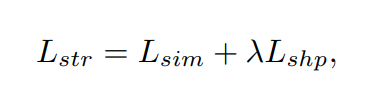
特征聚合
上节中的损失设计主要集中在车道的内部关系上。在本节中,提出一种特征聚合方法,该方法着重于全局上下文和局部特征。提出了一种利用多尺度特征的辅助分割任务来对局部特征进行建模。并使用交叉熵作为辅助分割损失。这样,本文方法的整体损失可以写成:
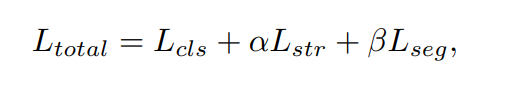
Lseg 是分割损失,α 和 β是损失系数。需要注意的是,我们的方法只在训练阶段使用辅助分割任务,在测试阶段将其删除,这样即使我们增加了额外的分割任务,也不会影响方法的运行速度,它和没有辅助分割任务的网络是一样的。
模型
下图展示了整个模型的结构,基本可以分为三个部分:Backbone、 Auxiliary部分和用于车道线候选点选择的Group Classification部分。可以看出,由于整个pipeline中参与最终inference的部分只进行了下采样而不像分割模型还进行了多轮的上采样,因此模型整体的计算量是相当低的,根据论文给出的结果可以达到300FPS。
Backbone部分采用了较小的ResNet18或者ResNet34,下采样到4X的部分作为最终的特征,这里其实是较为浅层的特征,一般分割模型要下采样到16x或者32x。论文里也提到了使用较大的感受野就可以达到不错的检测效果,这样就可以极大的提高模型的推理速度。
Auxiliary部分对三层浅层特征进行了concat和上采样,用来进行实例分割。其目的是在训练过程中增强视觉特征,不参与推理。

https://blog.csdn.net/sinat_17456165/article/details/107218741
https://github.com/SeokjuLee/VPGNet/blob/master/vpgnet-labels.txt
https://www.jianshu.com/p/2d483a7ca7b2
https://blog.csdn.net/mangguoyouyizhi/article/details/110542485















 471
471











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









