









23年9月来自北京交通大学和纽约大学的论文“An In-depth Survey of Large Language Model-based Artificial Intelligence Agents“。
由于大语言模型(LLM)所展示的强大功能,最近将其与AI智体集成以提高其性能的努力激增。本文探讨基于LLM的AI智体与传统AI智体的核心区别和特点。具体而言,首先比较这两种类型智体的基本特征,阐明了基于LLM的智体在处理自然语言、知识存储和推理能力方面的显著优势。随后,对AI智体的关键组成部分进行了深入分析,包括规划、记忆和工具使用。特别是对于记忆的关键组成部分,本文引入了一种分类方案,不仅偏离了传统的分类方法,而且为AI智体的记忆系统设计提供了一个新的视角。最后,为该领域的进一步研究提供了方向性的建议,希望能给该领域的学者和研究人员提供有价值的见解。
传统AI是专门为解决某些问题而设计的。它们主要依赖于预先确定的算法或规则集,在为其构建的任务中表现出色。然而,当面对最初范围之外的任务时,他们往往难以进行泛化和推理。大语言模型(LLM)的引入给人工智能智体的设计带来了重大变化。这些智体在广泛的语料库上训练,不仅精通自然语言的理解和生成,而且表现出较强的泛化能力。这种功能使它们能够轻松地与各种工具集成,增强了它们的多功能性。另一方面,大语言模型的涌现能力(Wei 2022a)表明LLM也善于推理,这可以帮助他们从错误行为中学习。
以游戏探索为例,特别是在Minecraft环境中,基于LLM的智体(如VOYAGER(Wang 2023a))与传统RL智体之间的差异是显而易见的。LLM智体凭借其丰富的预训练知识,即使没有特定任务的训练,在决策策略方面也具有优势。另一方面,传统的RL智体往往需要在新的环境中从头开始,严重依赖交互来学习。在这个场景中,VOYAGER展示了更好的泛化能力和数据效率。
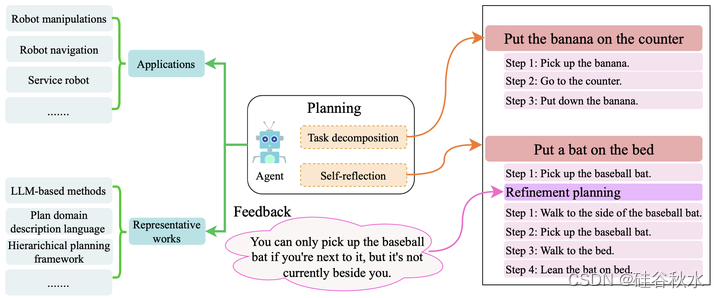
如图是人工智能智体的规划组件概述。左:介绍了规划的一些应用和有代表性的方法。右:提供了一个示例,说明了具有任务分解和自我反思的人工智能智体的工作机制。
规划
规划的目标是设计一系列行动,以促进状态转换并最终实现所需任务。如上图左侧所示,该组件作为一个单独的模块,已集成在各种应用中,如机器人操作(Chen 2021)、机器人导航(Lo 2018)和服务机器人(Li&Ding,2023)。现有的工作,如使用规划域描述语言(PDDL)的方法(Aeronautiques 1998;Fox&Long2003;Jiang2019)和分层规划框架(Erol1994;Suárez-Herńandez2018;Guo2023),极大地推动了规划系统的发展。最近,随着LLM在各种领域取得的重大成功,许多研究都在探索利用LLM来增强人工智能智体的规划和执行能力。得益于LLM强大的推理能力,基于LLM的人工智能智体可以有效地将复杂的任务或指令分解为一系列子任务或更简单的指令(即规划)。例如,如上图右上角所示,基于LLM的智体将复杂的指令“把香蕉放在柜台上”分解为一系列更简单的指令,这些指令对智体来说更容易完成。此外,在不考虑外部环境反馈的情况下,仅根据智体制定的初始规划采取行动可能会限制智体的性能。例如,如上图右下角所示,一个智体为指令“把球棒放在床上”创建了一个规划,而初始规划的第一步是“拿起棒球棒”,当附近没有“球棒”时,该规划可能无法执行。然而,如果智体能够根据反馈进行自我反思,它可以将第一步细化为“走到棒球棒的一边”,然后逐步朝着实现目标的方向努力。因此,在执行过程中,反思和分析过去的行为和反馈,以及随后调整规划,对于人工智能智体成功执行任务同样至关重要。
任务方法分解
任务分解旨在将复杂的任务或指令分解为一系列更简单的子目标或子指令,用于执行任务。例如,如上图的右上角所示,给定任务指令“将香蕉放在柜台上”,智体会将其分为三个步骤:1。捡起香蕉。2.去柜台。3.把香蕉放下。现有工作主要通过思维链CoT或思维树ToT(Wei2022b;Kojima2022;Yao2021)和带LLM的PDDL(Liu2020)进行任务分解。思维链可以利用几个例子或简单的指令来逐步指导LLM推理,以便将复杂的任务分解为一系列更简单的任务(Wei 2022b;Zhang2022;Huang2022a;Wang2023b)。Zhang(Zhang 2022)提出一种思维链样本的自动生成方法。首先对问题进行聚类,然后为每个聚类选择具有代表性的问题,以零样本的方式生成思维链样本。Huang(Huang 2022a)利用与给定任务相关的高级任务及其分解的规划步骤作为示例,并将这些示例与输入信息相结合来构建提示。然后,用LLM来预测规划的下一步,并将生成的步骤添加到原始提示中,继续预测,直到整个任务完成。Wang(Wang 2023b)提出,首先引导LLM来构建一系列规划,然后逐步执行解决方案,可以有效缓解中间规划在推理过程中消失的问题。与线性思维不同,思维树(Long2023,Yao2023a)在每一步都会产生多个思维分支,创建树状结构。随后,用广度优先搜索(BFS)或深度优先搜索(DFS)等方法对该思维树进行搜索。为了评估每个状态,可以使用“价值提示”来促进推理,或者可以通过投票机制生成评估结果。此外,一些研究工作考虑将LLM与PDDL相结合,规划目标问题(Xie2023;Liu2023a;Guan2023)。例如,Liu(Liu 2023a)首先将自然语言形式的任务描述传达给LLM,通过上下文学习ICL将其转换为PDDL格式,然后他们使用经典规划器生成规划,并通过LLM将其再次转换为自然语言格式。
自反思
在与环境互动的过程中,人工智能智体可以接收反馈来反思过去的动作,从而增强其规划能力。有许多工作试图将基于LLM的智体与自我反思相结合(Yao2022;Huang2022b;Shinn2023;Liu2023b;Sun2023;Singh2023;Yao2023b;Chen&Chang2023)。例如,Yao(Yao 2022)将动作与思维链相结合,利用思维制定指导智体执行动作的规划。同时,在环境中交互执行动作进一步增强了智体的规划能力。Shinn(Shinn2023)引入了一个名为Reflexion的框架,在该框架中,该方法首先通过Actor模块生成动作并对其进行评估。然后利用自我反思模块生成反馈并将其存储在记忆中。当出现错误时,该方法可以推断导致错误的动作并进行更正,从而不断增强智体的能力。Liu(Liu2023b)首先基于人类反馈对模型的各种输出进行评级,然后用提示模板将这些评级构建成自然语言形式,并将其与输出相结合,对模型进行微调,从而使其能够学习自反思。Singh(Singh2023)利用Python程序和注释来生成规划,其中assertion函数用于从环境中获得反馈。当assertion为false时,可以执行错误恢复。Sun(Sun2023)提出了一个名为AdaPlanner的模型,该模型利用两个细化器来优化和细化规划。细化器之一在执行动作之后从环境收集信息,然后将该信息用于后续动作。另一种是在执行的行动未能达到预期结果时,根据从外部环境获得的反馈调整现有规划。同样,Yao(Yao2023b)。首先将一个小语言模型作为回顾模型进行微调,生成对过去失败的反馈,然后将此反馈附加到actor提示中,作为大LLM的输入,防止类似错误的再次发生并预测下一步动作。
记忆
如图记忆的映射结构:左边描绘了人类记忆中的记忆类别,右边描绘了人工智能智体中的记忆分类,这些记忆分类根据LLM的特征重新定义。
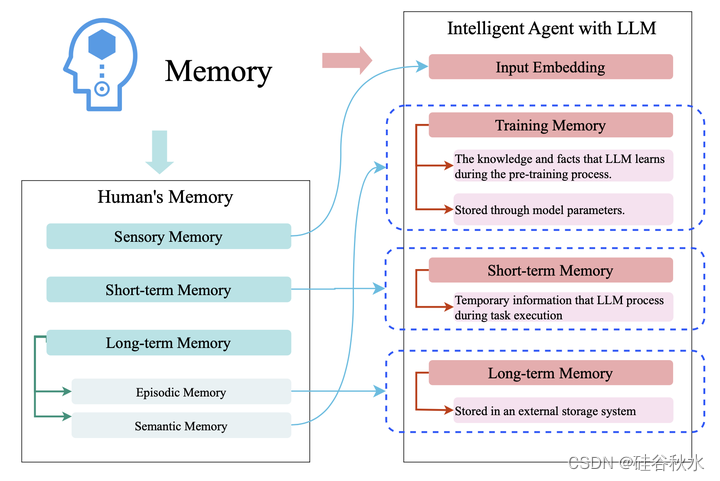
记忆可以帮助个人将过去学到的知识和经历与当前状态相结合,从而帮助做出更合适的决定。一般来说,人类记忆可分为三种主要类型:感觉记忆、短期记忆和长期记忆(Camina&Guëell,2017)。感官记忆是通过触觉、听觉、视觉和其他感官收集信息,其寿命极其短暂(Wan2020;Jung2019)。短期记忆是指在短时间内处理信息的过程,通常通过工作记忆来实现(Hunter1957;Baddeley,1983,1997)。相反,长期记忆是指可以长时间存储的记忆,包括情景记忆和语义记忆。情节记忆是指个人对亲身经历的事件的记忆能力,通常能够将这些事件与上下文信息紧密联系起来(Tulving 1972;Tulving,1983)。语义记忆是指个体所知道的事实知识,这种记忆与特定事件和个人经历无关(Tulving 1972)。同样,记忆作为人工智能智体的关键组成部分,可以帮助从过去的信息中学习有价值的知识,从而帮助智体更有效地执行任务。为了充分利用记忆中存储的信息,一些研究试图将人工智能智体与短期记忆相结合(Kang2023;Peng 2023)、长期记忆(Vere&Bickmore,1990;Kazemifard等人,2014),以及两者的结合(Nuxoll&Laird,2007;Kim2023,Yao2023b;Shinn2023)。此外,由于感觉记忆可以被视为文本和图像等输入的嵌入表示,类似于感知缓存,感知记忆不看成是人工智能智体记忆模块的一部分。随着大语言模型(LLM)的出现,一些工作致力于使用LLM来驱动人工智能智体的开发。考虑到LLM的特点,进一步重定义人工智能智体的记忆类型概念,并将其分为训练记忆、短期记忆和长期记忆。
训练记忆是指模型在预训练过程中学习的知识和事实,这些信息通过模型参数存储。现有研究表明,模型可以在预训练阶段学习世界知识(Rogers 2021)、关系知识(Petroni 2019;Safavi&Koutra2021),常识知识(Davison2017;Da2020;Bian2023),语义知识(Tang2023)和句法知识(Chiang2020)。因此,使用LLM进行推理,人工智能智体可以隐含地回忆这些知识,提高模型的性能。
短期记忆是指AI智体在任务执行过程中处理的临时信息,如上下文内学习过程中涉及的示例信息和LLM推理过程中产生的中间结果。在推理过程中,LLM临时存储和处理上下文信息或中间结果,利用它们来提高模型的能力。这类似于人类的工作记忆,短期暂存和处理信息,支持复杂的认知任务(Gong2023)。一些工作利用上下文学习来提高LLM的性能。首先将一些例子与输入信息相结合来构建提示,然后将该提示发送给LLM,利用短期记忆(Li2023b;Logeswaran2022;Omidvar&An2023)。例如,Li(Li 2023b)指出,当提供与任务相关的上下文时,重要的是要确保其工作记忆受上下文控制。否则,该模型应依赖于在预训练阶段获得的世界知识。Logeswaran(Logeswara2022)首先将一些示例与输入指令相结合作为提示,然后用LLM生成多个候选子目标规划。随后,采用重排序模型从这些候选人中选择最合适的规划。一些工作促使LLM以思维链的形式输出其思维过程和结果,或者将LLM推理的中间结果输入LLM进行进一步推理(Huang 2022a;Akyurek 2021;Chen 2020,Zhang 2022,Chen2023c)。例如,Zhang(Zhang 2023a)首先引导模型通过基于给定上下文的多回合对话来生成思维链。随后,他们将上下文与生成的思维链相结合,形成样本,然后用于帮助模型在新的上下文情况下进行推理和预测。Akyurek(Akyurek2023)提出了一种包括两个LLM多智体协作系统。一个LLM负责基于输入内容生成答案,而另一个LLM基于第一个LLM的输入和输出生成文本评论,帮助纠错。
长期记忆是指存储在外部存储系统中的信息,当人工智能智体使用该记忆时,可以从外部存储中检索与当前上下文相关的信息。长期记忆的利用可以分为三个步骤:信息存储、信息检索和信息更新。信息存储旨在存储来自智体与其环境之间的交互的基本信息。例如,Shuster(Shuster2022)首先生成最后一次交互的摘要。如果生成的摘要是“no persona”,则不存储;否则,将摘要信息存储在长期记忆中。Zhang(Zhang 2023b)利用表格格式以K-V对的形式存储记忆。在这种格式中,观测值和状态作为K,动作及其相应的Q值被存储为V。Liang(Liang2023a)存储了智体与环境之间相互作用的相关信息。上次交互的信息存储在闪存(flash)中,以便快速检索。其余信息作为长期记忆存储在动作记忆中。信息检索旨在从长期记忆中检索与当前上下文相关的信息,以帮助智体执行任务。例如,Lee(Lee2023)首先澄清了输入信息,然后用密集passage retrievers从长期记忆中选择相关信息。然后,将选择的信息与输入信息相结合,并使用思维链或少样本学习等方法来选择与任务执行最相关的信息。Zhang(Zhang 2023b)首先计算接收到的信息与长期记忆中存储K之间的相似度,然后选择相似度最高的top-k个记录来辅助LLM的决策。信息更新旨在更新存储的长期记忆。例如,Zhong(Zhong 2023)设计了一种基于Ebbinghaus遗忘曲线的遗忘机制,模拟人类长期记忆的更新过程。
工具使用
最近LLM在涉及最新信息、计算推理等的某些场景中仍然无法实现令人满意的性能。例如,当用户问:“《奥本海默》的全球首映在哪里?”,ChatGPT无法回答这个问题,因为电影《奥本海默》是最新的信息,不包括在LLM的训练语料库中。
为了弥补这些差距,许多努力都致力于将LLM与外部工具集成,以扩展其功能。一些工作旨在将LLM与特定工具集成,如网络搜索(Nakano2021)、翻译(Thoppilan 2022)、计算器(Cobbe 2020)和ChatGPT2的一些插件。其他一些工作考虑教LLM选择合适的工具或组合各种工具来完成任务。例如,Karpas(Karpas2022)实现了一个名为MRKL的系统,该系统主要由语言模型、适配器和多个专家(例如,模型或工具)组成,其中适配器用于选择适当的专家来帮助语言模型处理输入请求。Parisi(Parisi 2022)设计了一种迭代self-play算法,帮助LM学习如何通过微调LM来利用外部API。在self-play中,首先用几个样本对LM进行微调,然后利用它生成工具输入,用于调用工具API生成结果,然后使用LM推断答案。如果参考答案与特别答案相似,则将任务输入和预测结果(即工具输入、工具结果和预测答案)附加到语料库集,以便在下一轮中进一步微调和迭代。Patil(Patil2023)首先构建了一个具有指令-API对格式的数据集,然后基于该数据集对LLM进行微调,帮助LLM使用具有零样本和检索器-觉察的工具。类似地,Schick(Schick2023)在包含API调用的数据集上微调LLM,帮助LLM学习调用API的能力。Paranjape(Paranjape2023)首先以输入任务为提示检索相关实例,然后利用LLM实现链式推理(chain reasoning)的推断。在这个过程中,如果眼前步骤需要工具,则暂停推理过程以执行工具,并将工具的输出插入推理过程。Li(Li 2023c)提出了API库来评估LLM利用工具的能力,并设计了一种工具增强的LLM范式来缓解上下文长度的限制。Shen(Shen 2023)提出了一种将LLM与HuggingFace相结合的方法,提高LLM的性能。具体来说,该方法首先采用LLM将复杂任务分解为一系列子任务,然后从HuggingFace中依次选择合适的模型来执行这些子任务。Lu(Lu 2023)设计了一种即插即用的组合推理方法,首先规划输入任务的时间表,然后组合多个工具来执行子任务,实现原始任务。Liang(Liang 2023b)首先应用多模型的基础模型来理解和规划从API平台中选择合适API的给定指令,然后用动作执行器生成结果。此外,用人类反馈来优化LLM的API规划和选择能力,以及API平台中的API文档。与上述方法不同的是,Cai(Cai 2023)首先用LLM生成输入任务的工具,然后基于生成的工具使用LLM执行任务。具体来说,对于刚来的任务,如果任务所需的工具已经生成,则会直接调用该工具,否则LLM将首先生成工具使用。
下表是基于LLM智体的应用:


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









