






2025深度学习发论文&模型涨点之——交叉注意力+特征融合
交叉注意力机制的核心在于通过查询(Query)、键(Key)和值(Value)的交互,动态地关注不同模态之间的相关性。特征融合则利用交叉注意力的输出,将不同模态的特征进行加权融合,权重由交叉注意力机制动态确定,以反映不同特征的重要性。
-
增强特征表达能力:交叉注意力能够动态捕捉不同模态之间的关联,特征融合则将这些信息整合,提升特征的判别能力。
-
提升模型性能:在多个任务中,交叉注意力与特征融合的结合显著提高了模型的准确率和鲁棒性。
-
通用性:这种组合可以集成到不同的模型架构中,适用于多种多模态任务。
小编整理了一些交叉注意力+特征融合【论文】合集,以下放出部分,全部论文PDF版皆可领取。
需要的同学
回复“111”即可全部领取
论文精选
论文1:
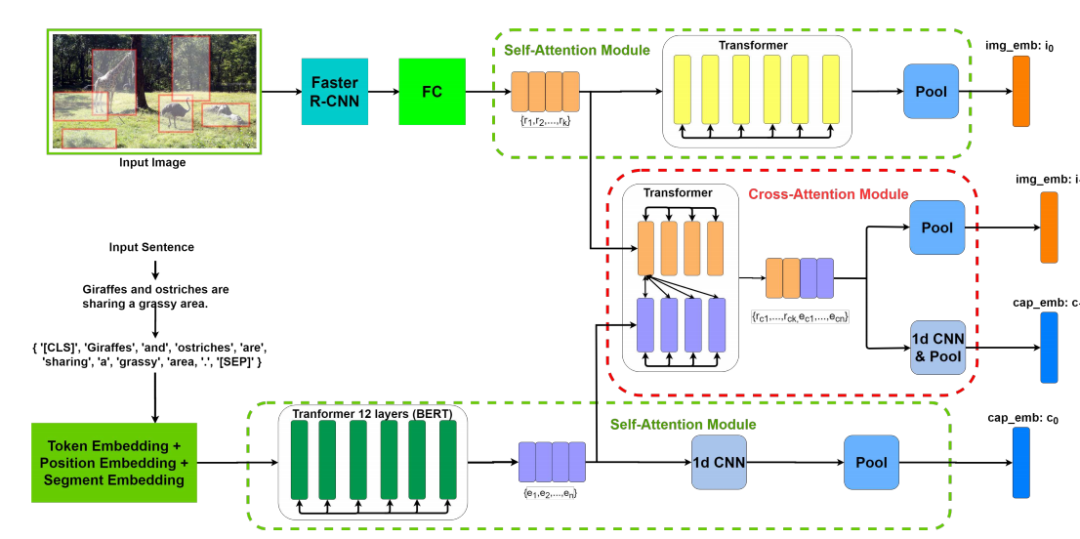
Multi-Modality Cross Attention Network for Image and Sentence Matching
多模态交叉注意力网络用于图像和句子匹配
方法
-
多模态交叉注意力网络(MMCA):提出了一种新的网络架构,通过联合建模图像区域和句子单词的内模态(intra-modality)和跨模态(inter-modality)关系,实现图像和句子的匹配。
-
自注意力模块:利用Transformer和BERT分别提取图像区域和句子单词的特征,建模内模态关系。
-
交叉注意力模块:通过堆叠图像区域和句子单词的表示,并通过Transformer单元和1D-CNN融合跨模态和内模态信息。
创新点
-
联合建模内模态和跨模态关系:首次在统一的深度模型中同时建模图像区域和句子单词的内模态和跨模态关系,提升了匹配性能。
-
性能提升:在Flickr30K数据集上,图像到句子检索的R@1指标达到74.2%,比之前最佳方法提升了5.3%;在MS-COCO数据集上,R@1指标达到74.8%,比之前最佳方法提升了3.6%。
-
跨模态注意力机制:提出了一种新的交叉注意力机制,能够同时利用内模态和跨模态信息,增强了图像和句子匹配的特征表示。
论文2:
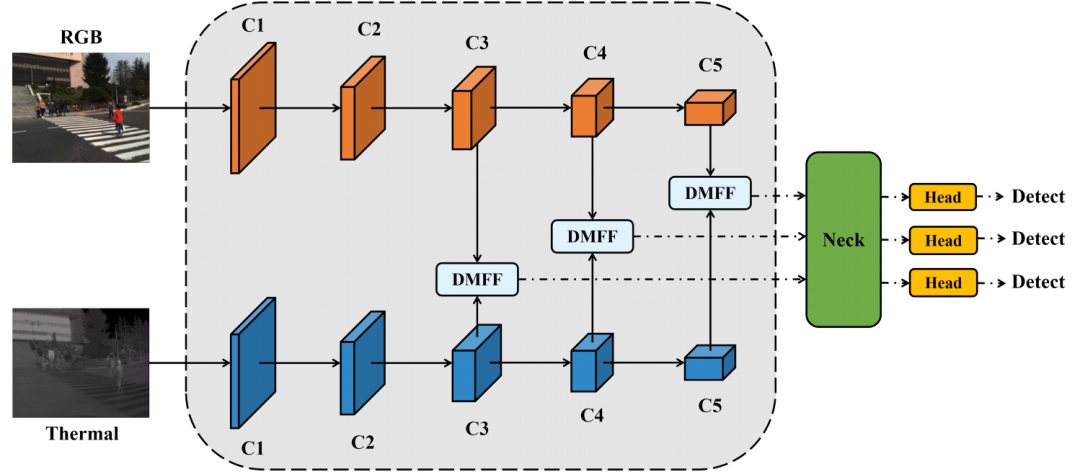
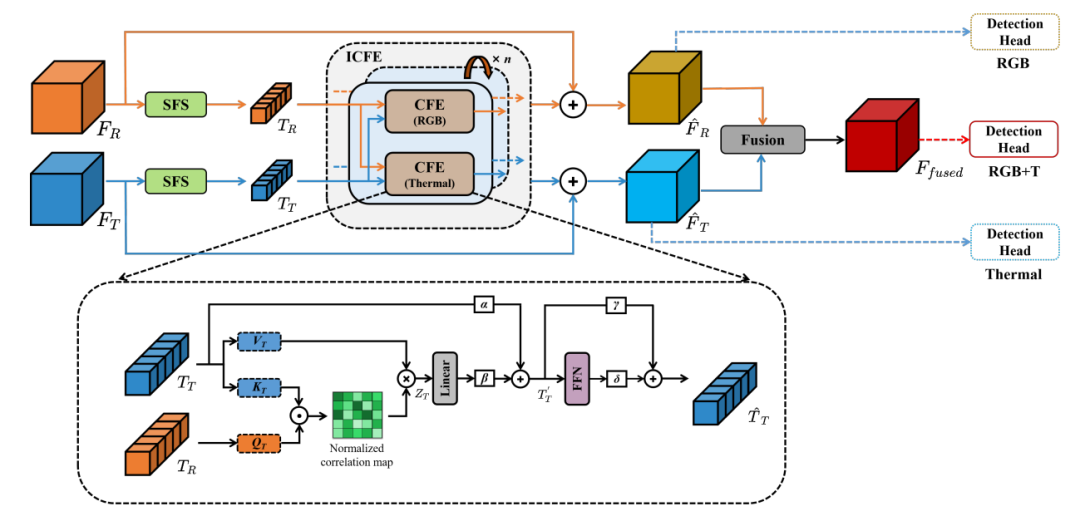
ICAFusion: Iterative Cross-Attention Guided Feature Fusion for Multispectral Object Detection
ICAFusion:迭代交叉注意力引导的多光谱目标检测特征融合
方法
-
双交叉注意力Transformer:提出了一种新的特征融合框架,通过查询引导的交叉注意力机制,同时建模全局特征交互和跨模态的互补信息。
-
迭代交互机制:受人类复习知识过程的启发,提出了一种迭代交互机制,通过参数共享减少模型复杂度和计算成本。
-
空间特征压缩(SFS):在交叉注意力模块之前应用空间特征压缩,降低特征图的维度,减少计算复杂度。
创新点
-
双交叉注意力特征融合:通过查询引导的交叉注意力机制,能够有效提取跨模态的互补信息,提升目标检测的性能。
-
性能提升:在KAIST数据集上,log-average miss rate降低到7.17%,比之前最佳方法降低了0.46个百分点;在FLIR数据集上,mAP50指标达到79.2%,比之前最佳方法提升了0.6%。
-
迭代学习策略:通过迭代交互机制,能够在不增加额外参数的情况下,进一步优化跨模态特征的融合。
论文3:
Predicting Pedestrian Crossing Intention with Feature Fusion and Spatio-Temporal Attention
基于特征融合和时空注意力的行人穿越意图预测
方法
-
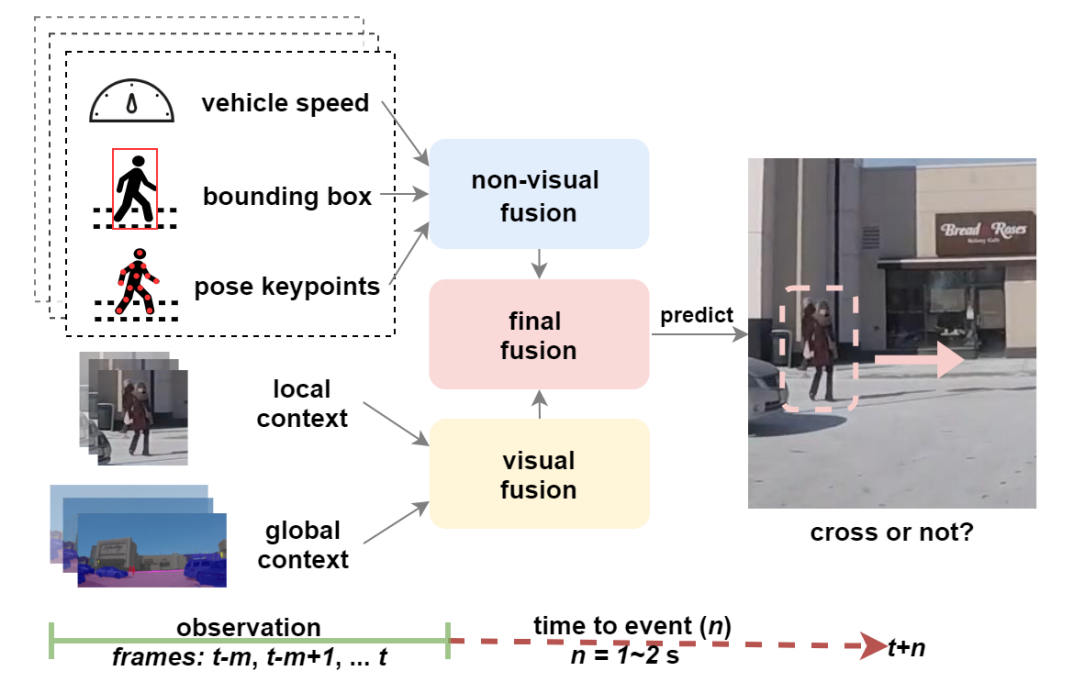
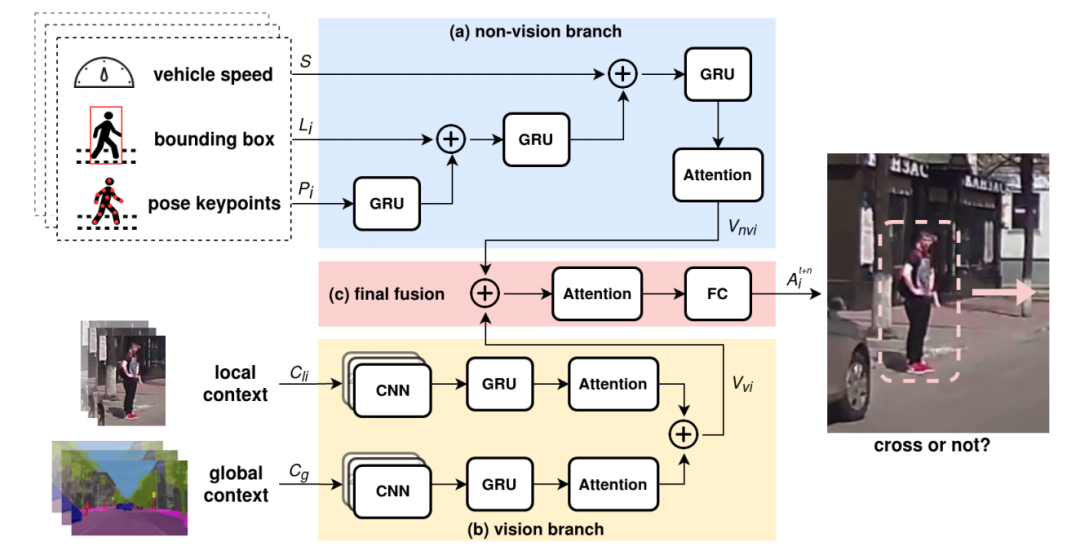
时空特征融合:提出了一种新的神经网络架构,融合RGB图像序列、语义分割掩码和车辆速度等不同时空特征。
-
注意力机制和RNN堆叠:利用注意力机制和循环神经网络(RNN)堆叠,优化特征融合策略。
-
混合融合策略:采用混合融合策略,将非视觉特征(如行人边界框、姿态关键点和车辆速度)和视觉特征(如局部上下文和全局上下文)进行融合。
创新点
-
全局时空上下文利用:通过语义分割掩码引入全局上下文信息,显著提升了行人穿越意图预测的准确性。
-
性能提升:在JAAD数据集的行为子集上,F1分数达到0.74,比之前最佳方法PCPA提升了0.15;在JAAD全数据集上,F1分数达到0.63,提升了0.08。
-
混合融合策略:通过比较不同的融合策略(早期、晚期、层次化和混合融合),证明了混合融合策略在行人意图预测中的有效性。
论文4:
Rethinking Cross-Attention for Infrared and Visible Image Fusion
重新思考用于红外和可见光图像融合的交叉注意力
方法
-
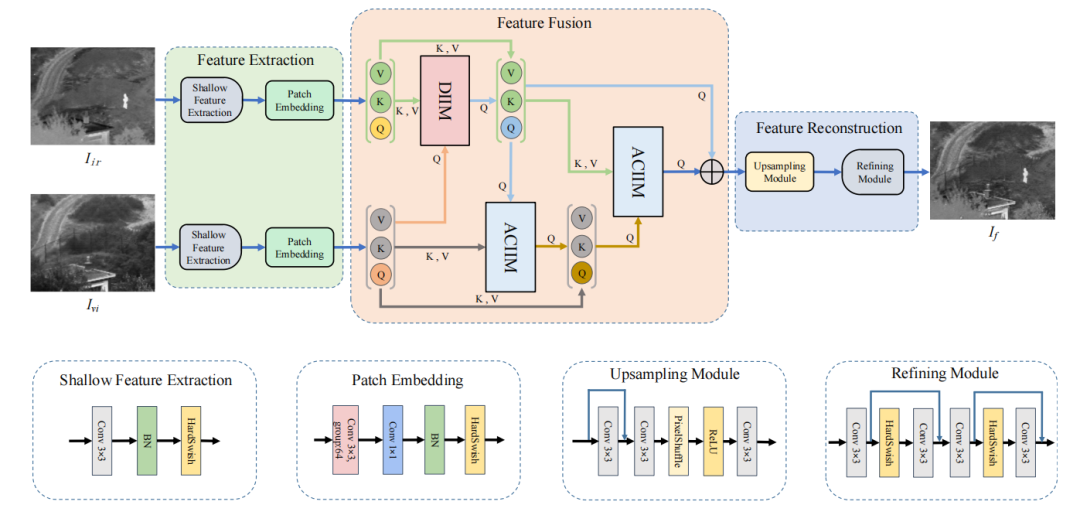
交替Transformer融合网络(ATFuse):提出了一种新的融合网络,包含差异信息注入模块(DIIM)和交替公共信息注入模块(ACIIM)。
-
差异信息提取:通过修改交叉注意力机制,设计了DIIM模块,专注于提取源图像之间的差异信息。
-
公共信息提取:通过交替使用交叉注意力机制,设计了ACIIM模块,用于充分挖掘公共信息并整合长距离依赖关系。
创新点
-
差异信息提取:DIIM模块能够有效提取源图像之间的差异信息,提升了融合图像的显著性。
-
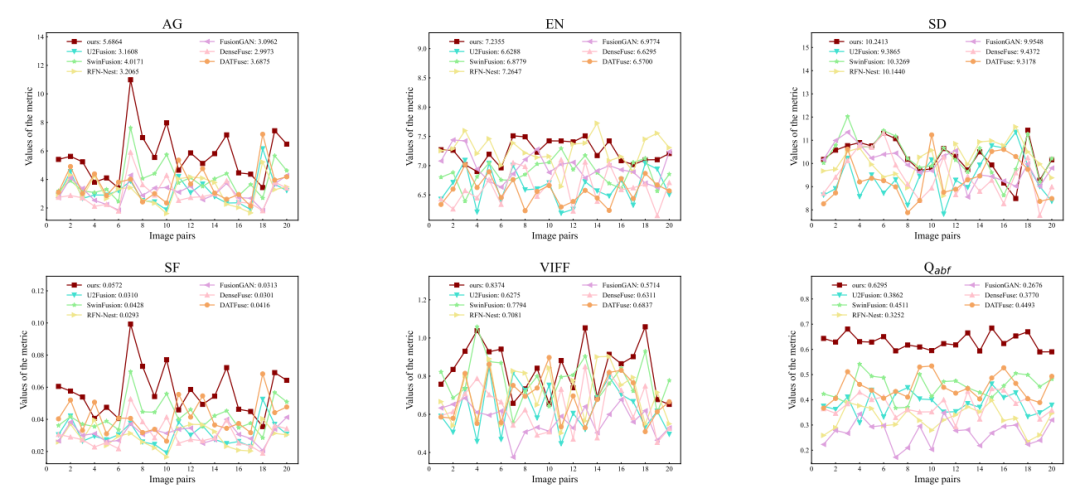
性能提升:在RoadScene数据集上,平均梯度(AG)达到5.6864,比其他方法提升了1.5-2.5个单位;在MSRS数据集上,AG指标达到4.6872,提升了0.5个单位。
-
分段像素损失函数:通过分段像素损失函数,实现了纹理细节和显著信息保留之间的良好平衡,提升了融合图像的质量。
小编整理了交叉注意力+特征融合论文代码合集
需要的同学
回复“111”即可全部领取

















 7369
7369

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









