











1.摘要
本文提出了一种新型的四重参数适应性增长优化算法(QAGO),该算法通过整合分布、对抗和平衡特性来提升其数值优化性能。QAGO的核心设计包括一个四重参数适应机制,利用特定概率分布的参数采样动态调整算法的超参数。此外,算法还引入了基于对立关系的三重参数自适应机制来调整操作符的参数。在平衡机制方面,QAGO利用信息理论中的詹森-香农散度来调和“矛”与“盾”的关系,进一步通过优化操作符的拓扑结构并精细化处理,有效地利用进化信息以提高解决方案的质量。这种综合的参数调整与平衡策略,使得QAGO在复杂的数值优化任务中表现出色。
2.增强优化算法GO原理
增长优化算法:用于解决连续和离散的全局优化问题的元启发式算法
3.改进策略
基于对抗与平衡的三参数自适应
在增长优化算法GO中,尽管学习阶段的操作算子通过积累差距来近似个体的搜索方向,但它未能利用普通个体的信息,这可能导致重要的问题空间信息的丢失。为了克服这一缺陷,QAGO对差距的计算方法进行了改进。在QAGO中,每个个体都有机会参与计算过程,这确保了全局最优区域周围的关键信息得到保留。此外,QAGO的学习操作算子利用了五个差距,并通过涉及不同层次的个体进行操作,从而为种群提供了丰富的进化信息。对于最后两个差距,QAGO采取了非常规策略,引入了不确定的扰动,以增强算法的适应能力和效果:
{
G
a
p
1
=
X
b
e
s
t
−
X
b
e
t
t
e
r
G
a
p
2
=
X
b
e
t
t
e
r
−
X
n
o
r
m
a
l
G
a
p
3
=
X
n
o
r
m
a
l
−
X
w
o
r
s
e
G
a
p
4
=
X
L
1
−
X
L
2
G
a
p
5
=
X
L
3
−
X
L
4
\begin{cases}&Gap_1=X_{best}-X_{better}\\&Gap_2=X_{better}-X_{normal}\\&Gap_3=X_{normal}-X_{worse}\\&Gap_4=X_{L1}-X_{L2}\\&Gap_5=X_{L3}-X_{L4}\end{cases}
⎩
⎨
⎧Gap1=Xbest−XbetterGap2=Xbetter−XnormalGap3=Xnormal−XworseGap4=XL1−XL2Gap5=XL3−XL4
基于一维向量映射的参数自适应

一维映射能够将高维向量简化并映射到一维空间,这样做可以有效降低算法的计算复杂性和内存使用,从而提高其效率:
D
G
a
p
1
=
⟨
X
b
e
s
t
,
X
b
e
t
t
e
r
⟩
D
G
a
p
2
=
⟨
X
b
e
t
t
e
r
,
X
n
o
r
m
a
l
⟩
D
G
a
p
3
=
⟨
X
n
o
r
m
a
l
,
X
w
o
r
s
e
⟩
D
G
a
p
4
=
⟨
X
L
1
,
X
L
2
⟩
D
G
a
p
5
=
⟨
X
L
3
,
X
L
4
⟩
\begin{aligned}&DGap_{1}=\langle X_{best},X_{better}\rangle\\&DGap_{2}=\langle X_{better},X_{normal}\rangle\\&DGap_{3}=\langle X_{normal},X_{worse}\rangle\\&DGap_{4}=\langle X_{L1},X_{L2}\rangle\\&DGap_{5}=\langle X_{L3},X_{L4}\rangle\end{aligned}
DGap1=⟨Xbest,Xbetter⟩DGap2=⟨Xbetter,Xnormal⟩DGap3=⟨Xnormal,Xworse⟩DGap4=⟨XL1,XL2⟩DGap5=⟨XL3,XL4⟩
为了防止映射过程中生成的负值在后续计算中产生复数,我们将所有映射值转换为非负实数域:
L
F
k
=
D
G
a
p
k
+
2
∣
min
(
D
G
a
p
)
∣
∑
n
=
1
5
(
D
G
a
p
n
+
2
∣
min
(
D
G
a
p
)
∣
)
LF_k=\frac{DGap_k+2\left|\min\left(DGap\right)\right|}{\sum_{n=1}^5\left(DGap_n+2\left|\min\left(DGap\right)\right|\right)}
LFk=∑n=15(DGapn+2∣min(DGap)∣)DGapk+2∣min(DGap)∣
基于适应度差的参数自适应
本文介绍了一种新的缩放因子
S
F
SF
SF自适应方法,用于改善增长优化算法GO在处理不同差距
𝐺
𝑎
𝑝
𝑘
𝐺𝑎𝑝𝑘
Gapk时的适应性。通过分析
𝐺
𝑎
𝑝
𝑘
𝐺𝑎𝑝𝑘
Gapk内向量间的适应度差异,此方法能够根据差异大小自适应调整
𝑆
𝐹
𝑖
𝑆𝐹_𝑖
SFi,以促进个体在全局和局部层面的优化探索:
{
F
G
a
p
1
=
∣
f
(
X
b
e
s
t
)
−
f
(
X
b
e
t
t
e
r
)
∣
F
G
a
p
2
=
∣
f
(
X
b
e
t
t
e
r
)
−
f
(
X
n
o
r
m
a
l
)
∣
F
G
a
p
3
=
∣
f
(
X
n
o
r
m
a
l
)
−
f
(
X
w
o
r
s
e
)
∣
F
G
a
p
4
=
∣
f
(
X
L
1
)
−
f
(
X
L
2
)
∣
F
G
a
p
5
=
∣
f
(
X
L
3
)
−
f
(
X
L
4
)
∣
\left\{\begin{array}{l}FGap_1=\left|f(X_{best})-f(X_{better})\right|\\FGap_2=\left|f(X_{better})-f(X_{normal})\right|\\FGap_3=\left|f(X_{normal})-f(X_{worse})\right|\\FGap_4=\left|f(X_{L1})-f(X_{L2})\right|\\FGap_5=\left|f(X_{L3})-f(X_{L4})\right|\end{array}\right.
⎩
⎨
⎧FGap1=∣f(Xbest)−f(Xbetter)∣FGap2=∣f(Xbetter)−f(Xnormal)∣FGap3=∣f(Xnormal)−f(Xworse)∣FGap4=∣f(XL1)−f(XL2)∣FGap5=∣f(XL3)−f(XL4)∣
基于Jensen-Shannon散度的参数自适应
在QAGO中,
𝐿
𝐹
𝐿𝐹
LF和
𝑆
𝐹
𝑆𝐹
SF的设计呈现出“矛与盾”的相互依存和制约关系,为了更精确地调控这两个系统之间的平衡,本研究引入了詹森-香农散度。通过这种方式,我们能够观察并估计
𝐿
𝐹
𝐿𝐹
LF和
𝑆
𝐹
𝑆𝐹
SF两个系统之间的距离,进而优化学习操作符的自适应过程:
d
J
S
(
L
F
,
S
F
)
=
D
J
S
(
L
F
,
S
F
)
d_{JS}\left(LF,SF\right)=\sqrt{D_{JS}\left(LF,SF\right)}
dJS(LF,SF)=DJS(LF,SF)
其中,詹森-香农散度
D
J
S
(
L
F
,
S
F
)
=
1
2
K
L
(
L
F
,
L
F
+
S
F
2
)
+
1
2
K
L
(
S
F
,
L
F
+
S
F
2
)
\begin{aligned}D_{JS}\left(LF,SF\right)&=\frac{1}{2}KL\left(LF,\frac{LF+SF}{2}\right)\\&+\frac{1}{2}KL\left(SF,\frac{LF+SF}{2}\right)\end{aligned}
DJS(LF,SF)=21KL(LF,2LF+SF)+21KL(SF,2LF+SF)
KL散度
K L ( L F , S F ) = ∑ k = 1 5 L F k ln ( L F k S F k ) KL\left(LF,SF\right)=\sum_{k=1}^{5}LF_{k}\ln\left(\frac{LF_{k}}{SF_{k}}\right) KL(LF,SF)=k=1∑5LFkln(SFkLFk)
流程图
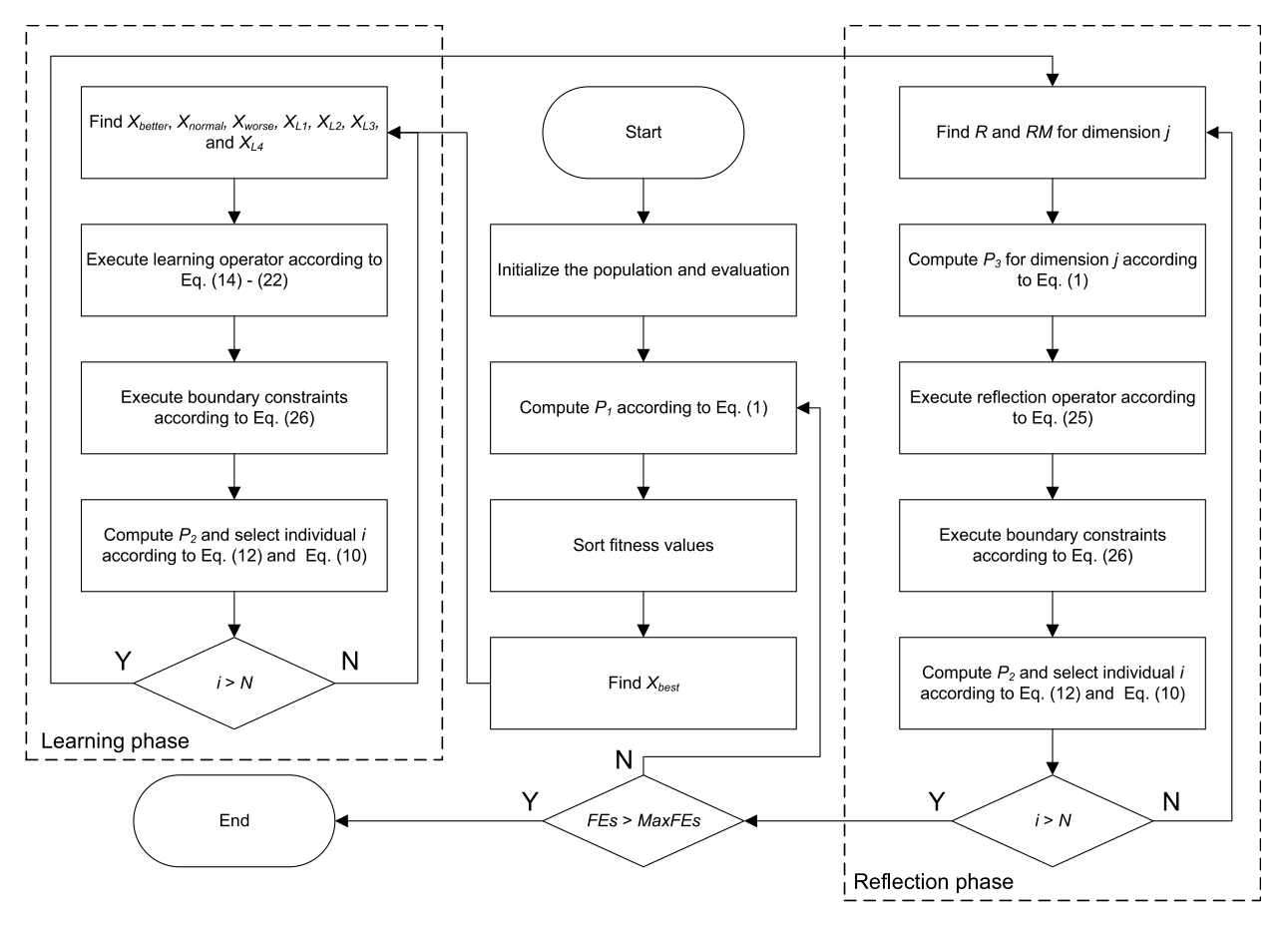
伪代码

4.结果展示
CEC2017






5.参考文献
[1] Gao H, Zhang Q, Bu X, et al. Quadruple parameter adaptation growth optimizer with integrated distribution, confrontation, and balance features for optimization[J]. Expert Systems with Applications, 2024, 235: 121218.



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











