











1.摘要
灰狼优化算法(GWO)是一种新型自然启发式算法,具备较强的局部搜索能力,但在处理大规模问题时全局搜索能力较弱。本文提出了改进灰狼算法(RSMGWO),RSMGWO算法结合了随机对立学习、增强灰狼层级结构和修改进化种群动态(EPD)。
2.灰狼算法GWO原理
3.改进策略
基于增强灰狼层级结构
受粒子群优化算法(PSO)启发,本文提出了基于增强狼群层级结构的灰狼优化算法(GWOSH)。作为经典的群体智能算法,PSO通过学习个体和群体中最佳位置来有效地在复杂空间中搜索全局最优解。在GWOSH中,每只狼有两种更新模式:一种是基于随机维度的全局最优搜索方式,增强狼群的层级结构;另一种是采用传统GWO的更新方式。每只灰狼根据其社会层级选择适合的更新模式,从而提高搜索效率和优化性能。
S
i
(
t
)
S_i(t)
Si(t)来记录每个个体的层级,从
α
,
β
,
δ
,
ω
\alpha,\beta,\delta,\omega
α,β,δ,ω分别为1-4,引入决策因子
D
F
i
(
t
)
DF_i(t)
DFi(t)使每只灰狼决定选择哪种更新模式来更新它们的位置:
D
F
i
(
t
)
=
(
L
−
S
i
(
t
)
)
/
(
L
−
1
)
DF_i(t)=(L-S_i(t))/(L-1)
DFi(t)=(L−Si(t))/(L−1)
其中,
L
L
L是狼群层级总数,狼群有4个层级
L
=
4
L = 4
L=4。

改进EPD算子
EPD(演化种群动态)机制源自自组织临界性(SOC)理论,该理论指出动态系统最有效的状态是临界状态。在SOC理论中,平衡种群中的微小扰动能够维持平衡而不依赖外部干扰。在生物进化过程中,去除最差个体对种群的整体演化有显著影响。去除最差个体并重新定位其位置的过程称为EPD。EPD能够有效提高种群的中位数,并且在优化基于种群的元启发式算法时具有较高的效率和较低的成本。RSMGWO使用EPD首先去除一些表现较差的个体,然后将它们重新定位到最佳解附近或搜索空间中的随机位置。
(a)领导者周围更新最差候选解的位置:
X
(
t
+
1
)
=
{
X
p
−
r
1
∗
(
X
p
−
l
b
)
,
r
<
=
0.5
X
p
+
r
1
∗
(
u
b
−
X
p
)
,
r
>
0.5
\boldsymbol{X}(t+1)=\left\{ \begin{array} {cc}\boldsymbol{X}_p-r_1*(\boldsymbol{X}_p-\boldsymbol{l}\boldsymbol{b}), & \quad r<=0.5 \\ \boldsymbol{X}_p+r_1*(\boldsymbol{u}\boldsymbol{b}-\boldsymbol{X}_p), & \quad r>0.5 \end{array}\right.
X(t+1)={Xp−r1∗(Xp−lb),Xp+r1∗(ub−Xp),r<=0.5r>0.5
(b)更新最差候选解在搜索空间中随机位置的位置:
X
(
t
+
1
)
=
l
b
+
r
∗
(
u
b
−
l
b
)
\boldsymbol{X}(t+1)=\boldsymbol{lb}+r*(\boldsymbol{ub}-\boldsymbol{lb})
X(t+1)=lb+r∗(ub−lb)
随机对立学习策略
为进一步提高探索能力,本文引入了一种随机对立学习策略,随机选择一只灰狼并使用该策略更新其位置:
X
r
s
=
l
b
+
(
u
b
−
X
α
)
X_{rs}=lb+(ub-X_\alpha)
Xrs=lb+(ub−Xα)
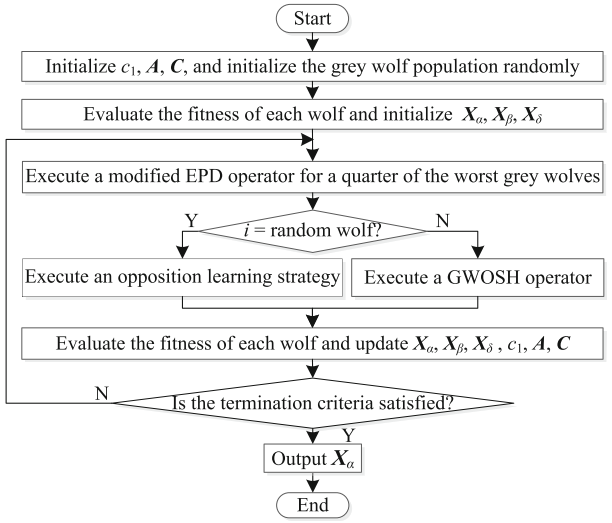
流程图
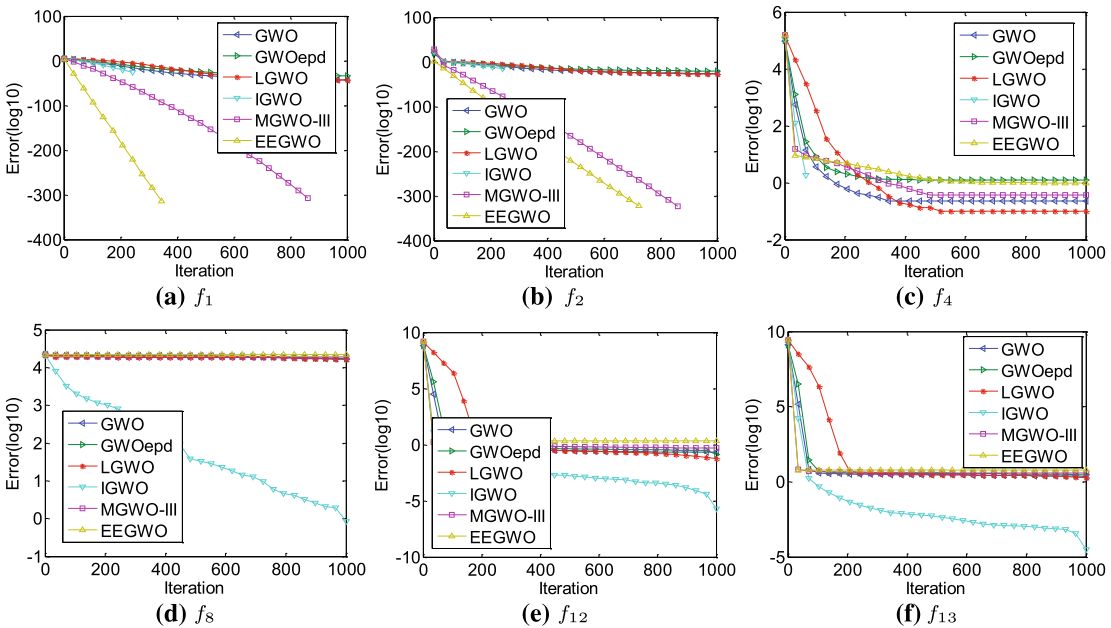
4.结果展示
5.参考文献
[1] Zhang X, Wang X, Chen H, et al. Improved GWO for large-scale function optimization and MLP optimization in cancer identification[J]. Neural computing and applications, 2020, 32: 1305-1325.
6.代码获取
function [Alpha_score,Cbest,Alpha_pos]=RSMGWO(f,lb,ub,d,M,N)
%Improved GWO for large-scale function optimization and MLP optimization in cancer identification(RSMGWO)
%Programmer: Xinming Zhang
%Date:2018-6-26
% initialize alpha, beta, and delta_pos //初始化α、β和δ狼
Alpha_pos=zeros(1,d);
Alpha_score=inf; %change this to -inf for maximization problems
Beta_pos=zeros(1,d);
Beta_score=inf; %change this to -inf for maximization problems
Delta_pos=zeros(1,d);
Delta_score=inf; %change this to -inf for maximization problems
%Initialize the positions of search agents
aa=repmat(lb,N,1);bb=repmat(ub,N,1);
Positions=aa+(bb-aa).*rand(N,d);%fitval=zeros(1,size(Positions,1));
X=Positions;
X(:,d+1)=feval(f, X(:,1:d));
X = PopSort(X);
Positions=X(:,1:d);s1=1;s2=N+1;s3=N+1;
fit=X(:,d+1);
for i=1:N
if fit(i)<Alpha_score
Alpha_score=fit(i); % Update alpha
Alpha_pos=Positions(i,:);s1=i;
end
if fit(i)>Alpha_score && fit(i)<Beta_score
Beta_score=fit(i); % Update beta
Beta_pos=Positions(i,:);s2=i;
end
if fit(i)>Alpha_score && fit(i)>Beta_score && fit(i)<Delta_score
Delta_score=fit(i); % Update delta
Delta_pos=Positions(i,:);s3=i;
end
end
Cbest=zeros(1,M);
Cbest(1)=Alpha_score;
a1=2;
l=0;% Loop counter
% Main loop
while l<M
a=2-l*((2)/M); % a decreases linearly fron 2 to 0
% EPD
[~,index]=sort(fit);
Positions=Positions(index,:);%
Num=round(N/4);
for i=1:Num%采用EPD
pa=rand;
if pa<=0.25
temp=Alpha_pos;
elseif pa<=0.5
temp=Beta_pos;
elseif pa<=0.75
temp=Delta_pos;
else
temp=[];
end
if isempty(temp)
Positions(N-Num+i,1:d)=lb+(ub-lb).*rand(1,d);
else
if rand<0.5
Positions(N-Num+i,1:d)=temp+(ub-temp).*rand(1,d)*ba;
else
Positions(N-Num+i,1:d)=temp-(temp-lb).*rand(1,d)*ba;
end
end
end
Num=ceil(N*rand);while Num==s1||Num==s2||Num==s3,Num=ceil(N*rand);end%随机选择一个灰狼
for i=1:N
if i==Num
Positions(i,:)=lb+(ub-Alpha_pos);%反向学习
elseif i==s1%对于alpha狼
for j=1:d
cnum=ceil(d*rand);
if cnum~=j
Positions(i,j)=Alpha_pos(cnum);
else
rnum=ceil(N*rand);while rnum==i,rnum=ceil(N*rand);end;
rnum1=ceil(N*rand);while rnum1==i || rnum1==rnum,rnum1=ceil(N*rand);end;
if rand<=0.5
Positions(i,j)=Positions(i,j)+3.5*a*rand*(Positions(rnum,j)-Positions(rnum1,j));
else
Positions(i,j)=Beta_pos(j)-a*(2*rand-1)*abs(a1*rand*Beta_pos(j)-Positions(i,j));
end
end
end
elseif i==s2%对于beta狼
cc=rand(1,d)>=0.67;snum=sum(cc);
Positions(i,cc)=Alpha_pos(cc)-a*(2*rand(1,snum)-1).*abs(a1*rand(1,snum).*Alpha_pos(cc)-Positions(i,cc));
snum=d-snum;
cnum=ceil(rand(1,snum)*d);
Positions(i,~cc)=(Alpha_pos(cnum)+Beta_pos(cnum))/2;
elseif i==s3%对于delta狼
cc=rand(1,d)>=0.33;snum=sum(cc);
X1=Alpha_pos(cc)-a*(2*rand(1,snum)-1).*abs(a1*rand(1,snum).*Alpha_pos(cc)-Positions(i,cc));
X2=Beta_pos(cc)-a*(2*rand(1,snum)-1).*abs(a1*rand(1,snum).*Beta_pos(cc)-Positions(i,cc));
Positions(i,cc)=(X1+X2)/2;
snum=d-snum;
cnum=ceil(d*rand(1,snum));
Positions(i,~cc)=(Alpha_pos(cnum)+Beta_pos(cnum)+Delta_pos(cnum))/3;
Else%对于其它狼
X1=Alpha_pos-a*(2*rand(1,d)-1).*abs(a1*rand(1,d).*Alpha_pos-Positions(i,:));
X2=Beta_pos-a*(2*rand(1,d)-1).*abs(a1*rand(1,d).*Beta_pos-Positions(i,:));
X3=Delta_pos-a*(2*rand(1,d)-1).*abs(a1*rand(1,d).*Delta_pos-Positions(i,:));
Positions(i,:)=(X1+X2+X3)/3;
end
end
Positions=ControlBound(Positions,aa,bb);%限定位置
fit=feval(f,Positions);%求适应度值
for i=1:N
% Calculate objective function for each search agent
fitness=fit(i);
% Update Alpha, Beta, and Delta
if fitness<Alpha_score
Alpha_score=fitness; % Update alpha
Alpha_pos=Positions(i,:);s1=i;
end
if fitness>Alpha_score && fitness<Beta_score
Beta_score=fitness; % Update beta
Beta_pos=Positions(i,:);s2=i;
end
if fitness>Alpha_score && fitness>Beta_score && fitness<Delta_score
Delta_score=fitness; % Update delta
Delta_pos=Positions(i,:);s3=i;
end
end
l=l+1;
Cbest(l)=Alpha_score;
end



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











