






环境介绍:
主系统win11,子系统ubuntu22.04,Gazebo11.10,ROS2 humble。

完成后,整体效果如下:
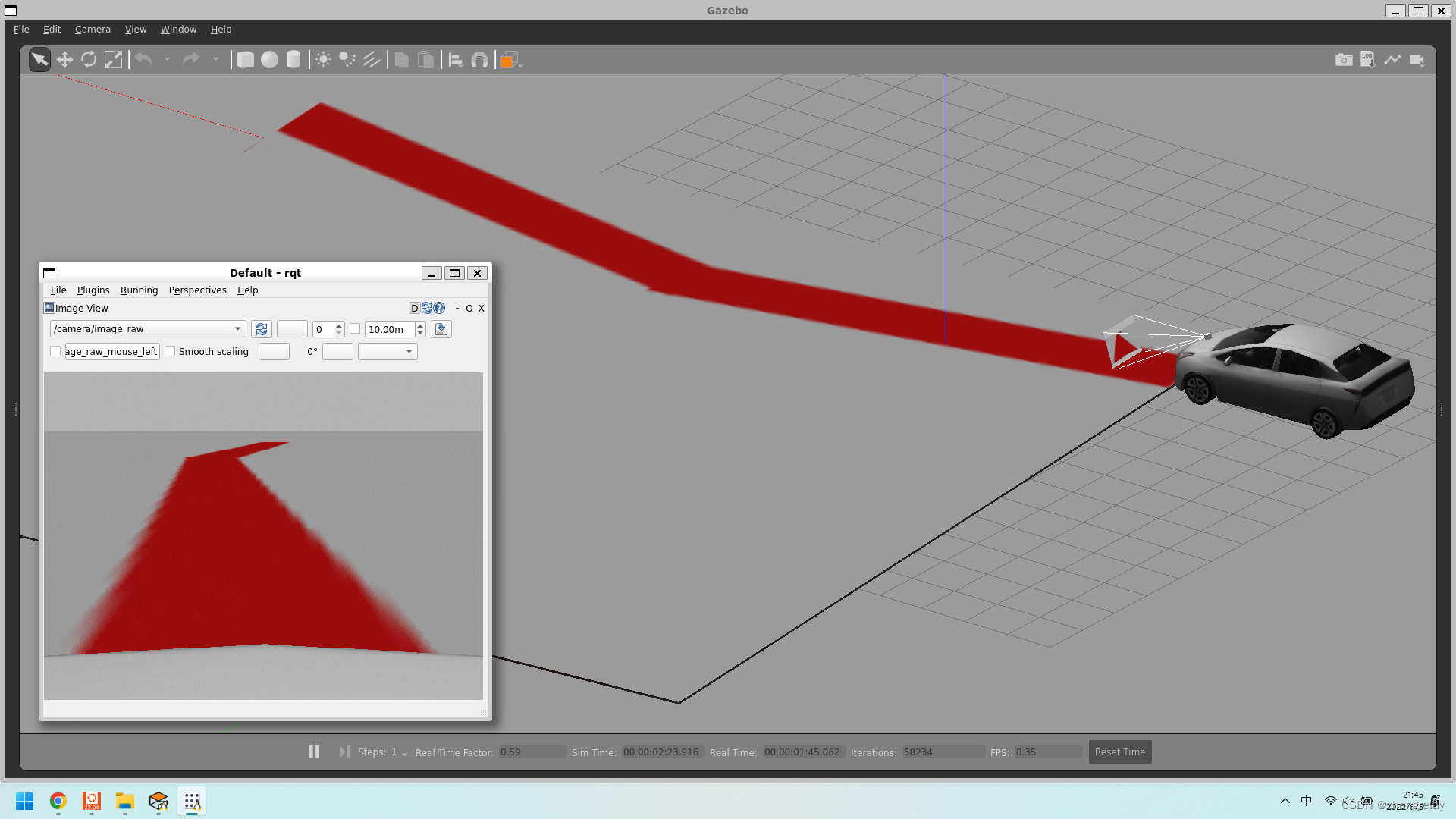
然后,对获取视觉数据进行处理可以实现巡线跑程序,后面一节再叙述。
需要配置摄像头也就是视觉插件:
<sensor name='camera' type='camera'>
<always_on>1</always_on>
<visualize>1</visualize>
<update_rate>30</update_rate>
<camera name='prius_cam'>
<horizontal_fov>1.0856</horizontal_fov>
<image>
<width>640</width>
<height>480</height>
<format>R8G8B8</format>
</image>
<clip>
<near>0.03</near>
<far>100</far>
</clip>
<noise>
<type>gaussian</type>
<mean>0</mean>
<stddev>0.007</stddev>
</noise>
</camera>
<plugin name='camera_driver' filename='libgazebo_ros_camera.so'/>
</sensor>launch文件:
from launch import LaunchDescription
from launch.actions import ExecuteProcess
def generate_launch_description():
return LaunchDescription([
ExecuteProcess(
cmd=['gazebo', '--verbose', '/home/zhangrelay/ros_ws/prius_line_following/src/world/prius_on_track.world'],
output='screen'),
])需要用到的一些指令:
- source install/setup.sh
- ros2 launch prius_line_following car_on_track.launch.py
- ros2 topic list
- rqt
如果需要更改赛道和色彩如下:
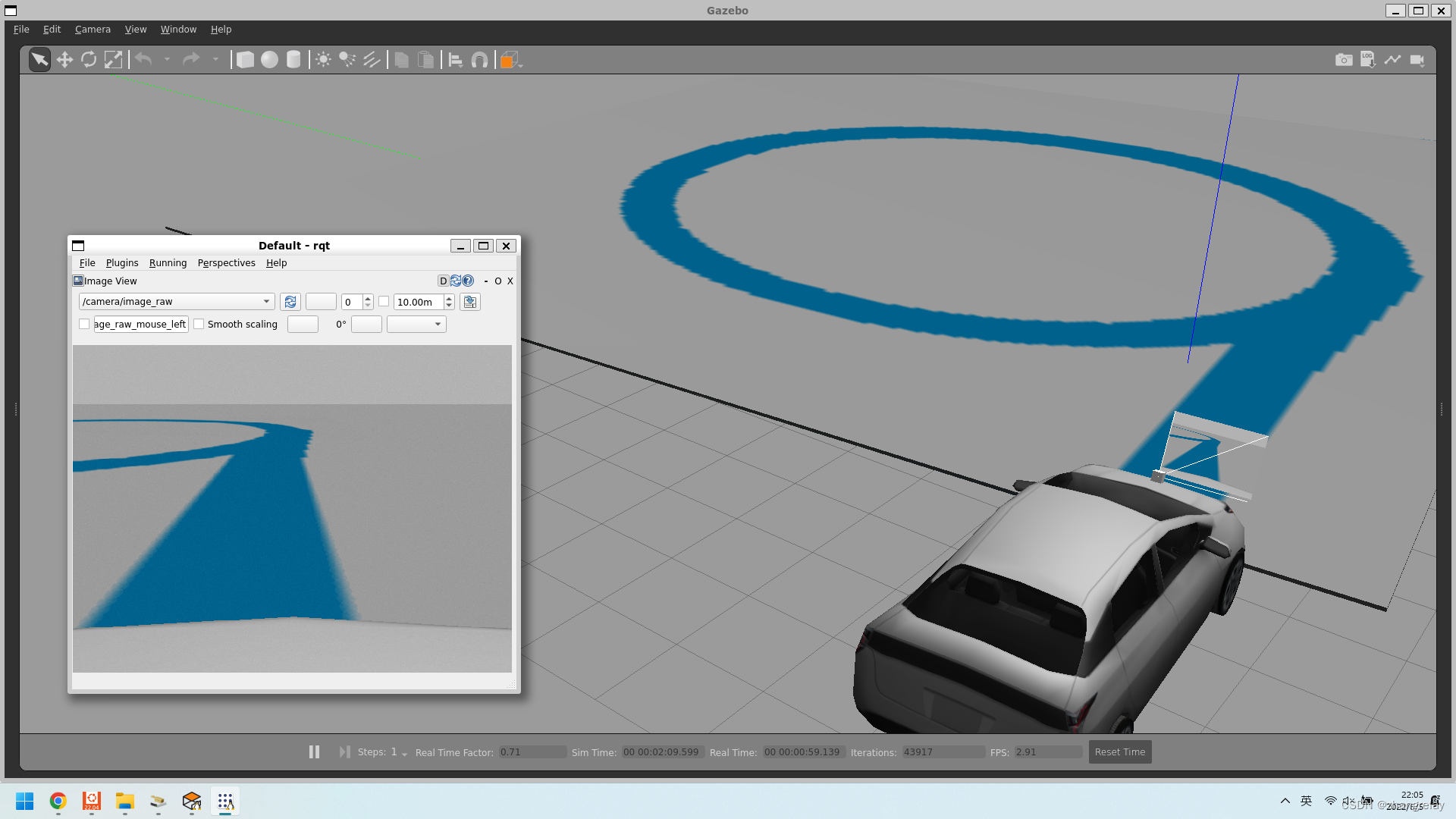
如何实现呢?
当然如果觉得车的颜色也不好看,也可以改:
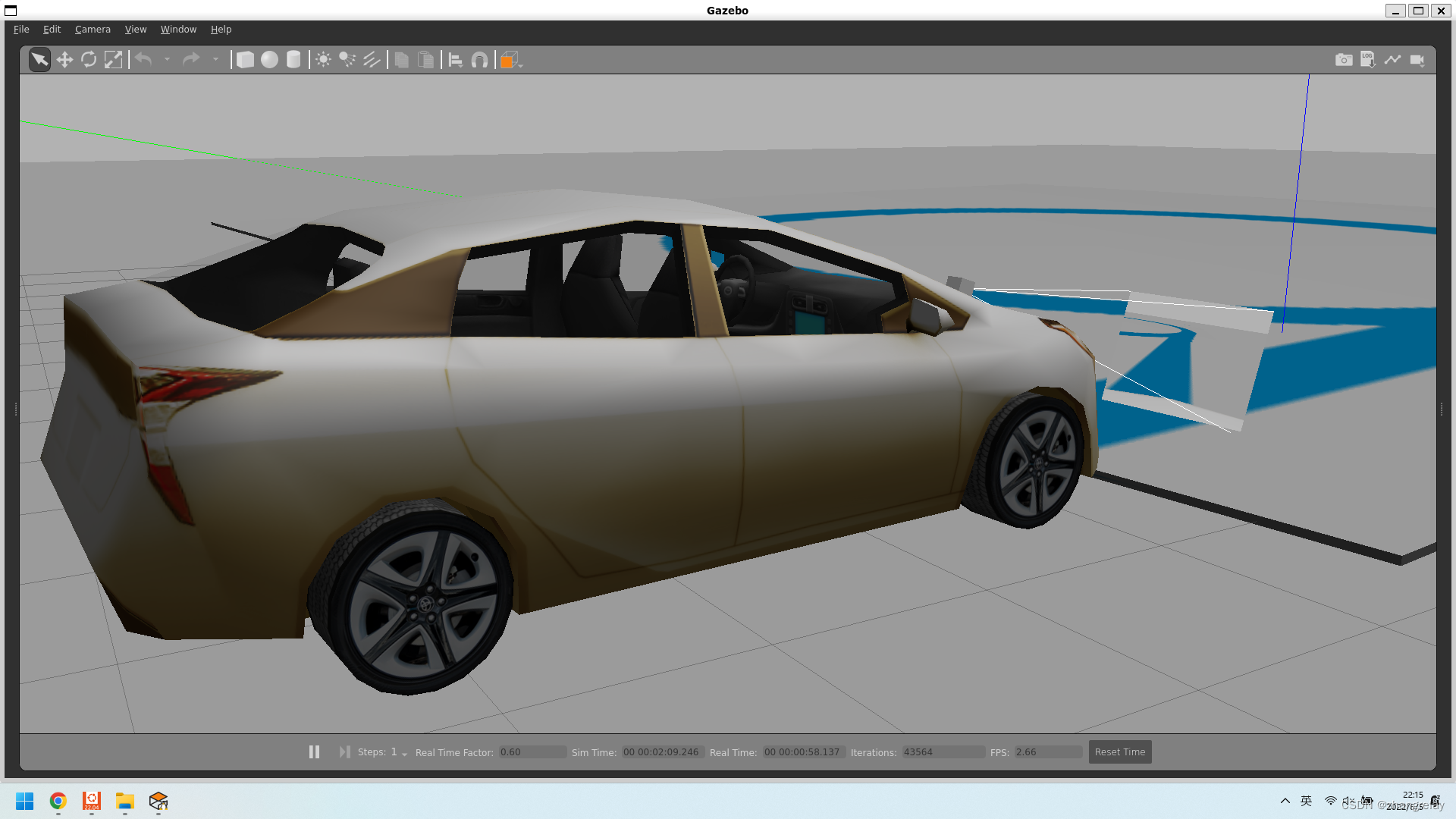
这如何实现?
需要熟练掌握Gazebo11使用,此部分基础ROS1/2差异不大,内容和方法基本通用的。
-^_^-
















 4011
4011











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











