






Trained Trajectory based Automated Parking System using Visual SLAM
使用Visual SLAM的基于训练轨迹的自动停车系统
概述
自动泊车已成为现代车辆的标准配置。
现有的停车系统构建本地地图,以便能够计划朝着检测到的插槽进行机动。
下一代停车系统有一个用例,其中它们建立了汽车经常停车的环境的永久地图,例如家庭停车或办公室停车。
预先构建的地图有助于在下次尝试停放车辆时更好地对其进行重新定位。
这可以通过使用Visual SLAM来实现,该功能称为训练轨迹停车。
augmenting the parking system with a Visual SLAM pipeline and the feature
在本文中,我们讨论了经过训练的轨迹自动泊车系统的用例,设计和实现。为了鼓励进一步的研究,我们发布了一个包含50个视频序列的数据集,其中包含超过100,000张图像,并且具有相关的地面真实性作为我们WoodScape数据集的伴侣[18]。据作者所知,这是训练有轨的停车系统场景的第一个公共数据集。
I. INTRODUCTION
大致而言,自动驾驶(AD)用例根据操作速度分为三种情况:
- 高速公路驾驶
- 中速城市驾驶
- 低速停车动作[5]。
- high speed highway driving,
- medium speed urban driving
- and low speed parking maneuvers [5].
高速用例的定义和结构相对较好,因此,高速公路通行证等功能最成熟,并且已经在市场上部署。
城市驾驶用例与中速相对应,它们是高度结构化且最具挑战性的。停车是一种低速用例,在结构化方面处于中间位置。
相对而言,停车位及其相关道路基础设施(道路标志和交通标志)的驾驶规则定义不清,但由于操作速度较慢,因此相对易于处理。
停车需要near-field sensing近场感测,而不是前置摄像头提供的典型**远场感测far-field sensing[**4]。
通常,这是通过四个fish-eye鱼眼摄像机实现的,它们在汽车近场周围可提供360°的全覆盖范围(图1)。

特别地,在相同的区域反复停放是很普遍的,例如:所有者的住宅区,要么是车库,要么在住宅和办公空间的前面。
准确的区域地图将有助于自动操纵以更有效地停车。 这可以通过可视化SLAM pipeline 来实现,该pipeline 可以构建停车区的地图,以后可以用于重新定位。
通常,这些停车区是私人区域,不能由TomTom,HERE等商业地图绘制公司进行地图绘制。因此,车辆必须具有智能来学习绘制频繁停车区的地图,然后重新定位。
在本文中,我们描述了使用商用汽车级相机和嵌入式系统提供此功能的系统。
视觉同时定位和地图绘制(VSLAM)是机器人技术和自动驾驶中一个经过充分研究的问题。
主要有三种类型的方法,即
(1)基于特征的方法,
(2)直接SLAM方法和
(3)CNN方法。
基于特征的方法利用描述性图像特征进行跟踪和深度估计[8],这会导致地图稀疏。
MonoSLAM [2],并行跟踪和映射(PTAM)[7]和ORBSLAM [10]是这种类型的开创性算法。
直接SLAM方法可在整个图像上工作,而不会使用稀疏特征来帮助构建密集地图。 密集跟踪和映射(DTAM)[11]和大规模半密集SLAM(LSD-SLAM)[3]是基于最小化光度误差的流行直接方法。
基于CNN的方法对于Visual SLAM问题相对不那么成熟,在[9]中对其进行了详细讨论。
本文的其余部分的结构如下。
第二部分概述了经过训练的轨迹停车系统用例。
第三节详细介绍了经过训练的轨迹停车系统及其组件的系统架构。
第四部分详细讨论了Visual SLAM pipeline 及其挑战。
最后,第五节总结了论文并提供了潜在的未来方向。
II. TRAINED TRAJECTORY PARKING SYSTEM
训练有轨的轨道停车分为两个阶段:训练阶段和重播阶段(training phase and replay phase. )
在训练阶段,驾驶员将车辆开到需要的地方(例如车棚,车库等)。 轨迹及其其他周围信息将存储起来,以便以后自动复制。
在重播阶段,将训练的轨迹加载到车辆上,并且该软件能够识别相对于整个路径中的学习轨迹的当前车辆位置。 如图2所示。

图2:经过训练的停车和重新定位的图示:
白色虚线路径是训练的轨迹(周围物体带有红色特征)。
带有箭头的黄色斑点表示当前车辆(具有检测到的特征为蓝色)按照训练的方向沿箭头方向移动。
在训练阶段,里程表和/或超声传感器信息的融合给出了更精确的轨迹回放。
然后,车辆控制计划会使用此计算出的车辆位置来规划返回停车位置的路线,并控制转向和加速,以使车辆自行在此处行驶。
Visual SLAM算法用于训练和重播阶段,以计算和识别训练的轨迹和车辆位置。
如下所述,在不同的用例中使用了经过训练的轨迹停车的这些阶段
Home Parking:驾驶员经常将汽车停在其本地区域,其想法是学习本地区域以自动执行停车操作。
家用停车系统使用计算机视觉技术在已存储的轨迹内定位自我车辆,从而使车辆能够使用存储的轨迹完全自主地驶入家用停车位。
在这样的应用中,系统将地标存储在场景中,传感器在其中工作以检测那些地标。 驾驶员训练系统以定位这些地标,然后系统将其用于定位。
Automated Reverse Parkout自动倒车停车:这有助于驾驶员倒车(例如驶入死胡同,停车)。
通常,不同的训练轨迹会存储在持久性存储器的缓冲区中,然后用户可以根据车辆的当前位置选择首选轨迹,以自动停泊或停泊。 连续记录停放自动回放的轨迹,通常无需任何手动触发。
Valet Parking代客泊车:代客泊车是最先进的泊车形式,需要L4自动化。 该系统必须自主执行导航以找到停车位,选择最佳停车位,然后自行停车。 在未知环境中完成此任务非常具有挑战性。 因此,人们正在努力创建带有人工地标(二维码,类似的标记)的基础设施地图,车辆可以利用这些基础设施来构建有效的局部地图
III. PARKING SYSTEM ARCHITECTURE
我们的系统框图如图3所示,并在本节中进行描述。 停车系统所需的必要计算机视觉模块将在III-B节中讨论。 第四节详细讨论了经过训练的轨迹停车所需的视觉SLAM。
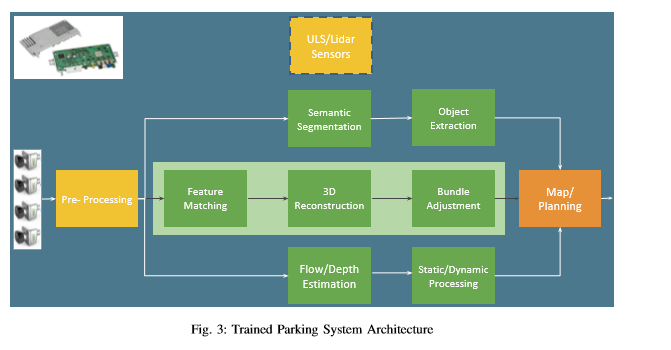
A. Platform Overview
传感器:汽车设置包括商业部署的automotive grade汽车级传感器,如图1所示。
停车系统所需的主要传感器是
- 鱼眼摄像头(用于提供轨迹信息)
- 超声波传感器(用于在停车过程中检测近端障碍物)。
有四个鱼眼相机(图中标记为绿色),分辨率为1兆像素,水平视场(FOV)为190°。四个摄像机一起覆盖了汽车周围的整个360°FOV。这些摄像机旨在提供长达10米的最佳近场感测,并能在25米以内将视线稍微降低。
还有一个12个超声波传感器阵列(图中标记为灰色),覆盖前后区域。它们在汽车周围提供了坚固的安全网,避免了碰撞,这对于坚固的系统是必不可少的。
它通常是具有调制脉冲的单膜传感器,用于在51.2kHz中心频率处进行发送和接收。传感器从压电元件提供原始数据,随后是模拟滤波器组,用于在进行数字转换之前对信号进行条件处理。检测和定位对象的其他处理步骤在ECU上完成。
一些高端系统还具有LiDAR,可用于定位,但不是主要传感器
SOC:
尽管在大型PC上显示了自动驾驶原型,但量产项目是部署低功耗和低成本的嵌入式系统。
尽管汽车嵌入式系统的计算能力迅速增长,但是部署计算机视觉算法仍然是一个很大的挑战[1] [6]。
图3在左上方显示了一个典型的汽车嵌入式系统,称为电子控制单元(ECU)。 汽车的典型SOC供应商包括德州仪器(TI)TDAx,瑞萨电子(Renesas)V3H和Nvidia Xavier平台。
这些SOC多数提供定制的计算机视觉硬件加速器,用于密集的光流,立体视差和深度学习。 典型的SOC系统具有1至10 TOPS的计算能力,并且消耗的功率不到10瓦。
软件体系结构:
在应用于视觉算法之前,典型的预处理算法包括鱼眼失真校正,对比度增强和降噪。
使用计算机视觉算法(在第III-B节中讨论)检测物体。
然后将它们送入地图,以规划汽车的自动泊车操作。
来自四个摄像机的图像坐标中的对象被转换为世界上的集中坐标系统。
深度估计提供通过语义分割检测到的对象(如行人和车辆)的定位。
同样,使用connected component algorithm 算法提取道路对象(如车道和路缘石)并映射到世界坐标。
还可以从其他传感器(如Ultrasonics和Lidar)中提取对象(如果有),然后将其融合到以前使用的地图中。
车辆控制和计划单元使用地图和当前位置来规划返回停车位置的路线,并控制转向和加速,以使车辆自行在此处行驶。
GPS可以用于在轨迹开始时提供车辆的粗略定位。
对于系统级别的软件来说,具有感知能力以检测行驶路径上的障碍物或行人,并据此改变轨迹是很重要的。
该系统应能够利用 自动紧急制动 Auto Emergency Braking functionality 功能,以使车辆能够在一定条件下进行紧急制动。
B. Standard Computer Vision Modules in Parking
除了传统的特征匹配之外,现代的VSLAM系统还使用语义信息来实现重新定位的鲁棒性。
一种现代实践是识别场景中的动态和可移动对象,并对这些实体在场景中所承载的特征赋予零或非常小的权重
语义分割Semantic Segmentation:
感兴趣的主要对象是道路对象。例如自由空间,道路标记,路缘石等,以及动态对象,例如车辆,行人和骑自行车的人。
它们都可以由统一语义分割网络[15]实时检测[16]。
图4在广角鱼眼图像上显示了Enet网络[13]的输出。

通常在自动驾驶中检测这些对象以用于导航和障碍物检测。
特别是对于我们的应用程序,动态对象可能有助于消除地图中的特征点,因为它们在重新定位期间可能不在同一位置。
诸如车道和道路标记之类的静态实体提供了可以在操纵过程中遍历的有效轨迹。
通用障碍物检测:
为了获得鲁棒的系统,必须使用外观以外的其他线索cues提示来检测物体,using alternate cues other than appearance. 。
在实践中,为所有可能的对象训练基于外观的语义分割是非常具有挑战性的,有非常罕见的对象类,例如袋鼠或建筑卡车。
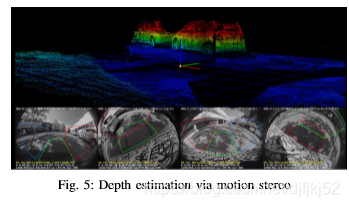
因此:运动和深度就是这种cues提示,在汽车场景中非常有用。通常,深度用于检测静态对象,而运动用于检测动态对象。
如前所述,大多数汽车SOC提供了可以利用的密集的光流和双目硬件加速器dense optical flow and stereo hardware accelerators 。
双目硬件加速器stereo hardware accelerators 可用于单眼相机的运动立体motion stereo of our monocular cameras。
图5说明了通过运动双目算法计算的深度。
在这种情况下,鱼眼畸变流形,是在点云下方可视化的分段平面。 另外,它们也可以使用高效的多任务网络进行计算efficient multi-task network[17]。
IV. VISUAL SLAM FOR PARKING
A. Mapping Overview
mapping是自动驾驶的关键支柱之一。
许多自动驾驶的成功演示(例如,由Google进行的演示)主要依赖于 定位到预先映射的区域localization to pre-mapped areas. 。
图6说明了TomTom RoadDNA提供的用于自动驾驶的商业HD高清地图服务[12]。
它们为大多数欧洲城市提供高度密集的语义3D点云地图和定位服务,典型定位精度为10厘米。
准确定位后,高清地图可以视为主要提示
因为已有强大的先验语义细分
可以通过在线分割算法进行细化[14]。
但是,此服务昂贵,因为它需要对世界各地进行定期维护和升级。由于隐私法和可访问性的原因,这种商业服务不能在许多情况下使用
而且必须在车辆的嵌入式系统中建立a mapping mechanism 机制。
例如,在许多国家(例如德国),不能合法地绘制私人住宅区。图7展示了我们的系统生成的点云。由于车辆中可用的计算能力有限,因此与密集的HD地图相比,它非常稀疏。

B. VSLAM的基本管道
(VSLAM)是一种算法,可构建汽车周围环境的地图,并同时在该环境中显示汽车的当前位置。
安装在汽车上的摄像头可从四个摄像头中的任何一个或组合生成广角图像。
然后遵循绘制车辆周围环境并跟踪地图的过程,该过程构成了图8所示的VSLAM的基本pipeline。
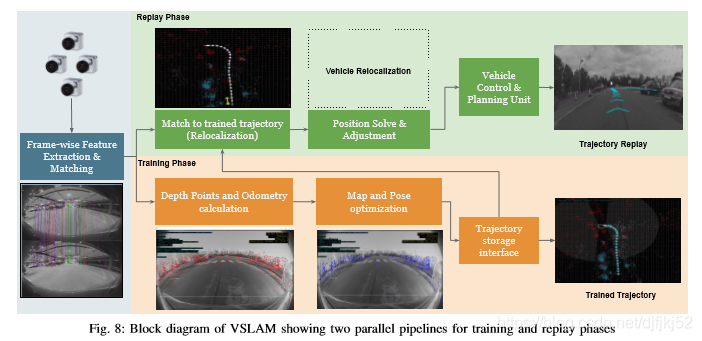
mapping 是生成地图的过程,该地图由训练有素的轨迹和路标组成, 这些在被跟踪的传感器数据之外。
经过训练的轨迹是一组关键姿势,周围围绕着从车辆始发点到目的地位置的地标。
这些地标使用鲁棒的图像特征表示, 在捕获的图像中是唯一的。
在回顾最先进的Visual SLAM pipeline 的优点和缺点时,我们得出结论,基于特征的方法最适合直接方法,因为它需要较少的内存,并且对动态对象和结构更改不那么敏感在现场。
图像中的独特特征可能是像素区域,剧烈变化以特定方式或边缘或拐角位置。
为了估算世界上的地标,我们进行了跟踪,
可以在两个或多个相同功能的视图中进行匹配。
一旦车辆移动了足够的量,VSLAM将拍摄另一张图像并提取特征。重构相应的特征以获得它们在现实世界中的坐标和姿势。
BA优化
Frame-to-frame 3D 逐帧3D重建和视觉测距法可能会出现漂移,需要对其进行全局校正。
这是通过bundle adjustment step 实现的 , 共同优化3D点和相机位置。
这是一个非常消耗计算的步骤,因为3D点的高重投影误差会增加迭代次数以降低成本,因此无法在每个帧中执行。
它通常在N帧中执行一次,称为窗口捆绑调整windowed bundleadjustment.。
在训练结束时,还将执行完整的(全局)束调整 full(global)bundle adjustment ,其中所有关键帧(不是轨迹上的每个帧)都进行了优化,以确保内部VSLAM映射的全局一致性。
最终的优化轨迹以地图的形式保存在永久性存储器中,并被算法用于重新定位车辆姿态以自动进行车辆操纵。
在此期间,将对实时摄像机图像进行搜索以寻找特征,并将其与训练后的地图中的帧进行匹配。
如果将实时图像中的特征与地图进行匹配,则优化模块(bundle adjustment捆绑调整)可以估计相对于轨迹训练期间车辆的当前位置。
数据
我们的验证数据集上的定性结果通过以下链接https://streamable.com/d6b97共享。
视频显示了我们的自动停车解决方案,重播了经过训练的轨迹。 实时图像来自前(右)和后(左)视摄像机。 中间播放的小视频显示了经过训练的轨迹图(车辆姿态显示为白点),周围有稀疏特征。 黄色移动箭头显示了根据VSLAM算法计算出的定位位置,车辆的实时运动。 在大多数情况下,提出的算法能够重新定位训练轨迹,定位方向的公差为2°,位置公差为0.05m。
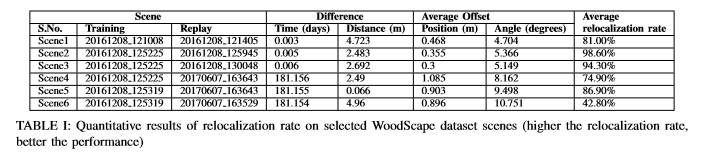
表I列出了WoodScape数据集中少数几个具有挑战性的场景的结果。这些场景在时间/日期和横向/角度偏移上都有变化,从而导致视频序列中的照明和结构变化。重新定位率受训练和重播场景之间变化量的影响。表格中的前三列指的是训练和重放场景,按记录的时间表示(yymmdd hhmmss)。第四和第五列提到捕获训练和重播场景的时间(以天为单位)的差异,以及开始训练和重播场景之间的距离(以米为单位)的差异。接下来的两列提到轨迹长度上位置和角度的平均偏移。最后一列是我们针对相应火车和重播轨迹的组合所获得的平均重新定位百分比。由于光照和横向偏移的变化很大,Scene6具有最具挑战性的场景,因此其重新定位率相对较差。
C. Technical Challenges
We briefly list the practical challenges involved in deploying this system based on our experience.
-
照明或天气条件变化可能会导致场景在视觉上看起来有所不同。例如,如果mapping和定位是在白天/夜晚或夏季/冬季等进行的,则算法会显着降级,因为特征对应将更少。
-
住宅区可能具有相似的结构,因此很难匹配独特的功能。因此,需要通过更专业的功能或更高级别的语义来增强系统。
-
大多数现代汽车无法访问云基础架构,因此必须在汽车的嵌入式系统上进行mapping。因此,在轨迹的末端,驾驶员需要额外的等待时间以允许完成地图的全局包调整global bundle adjustment of the map. 。
•SLAM pipeline需要良好的初始化,以便可以有效地匹配轨迹上的特征。这通常是通过嘈杂的GPS信号来完成的,这可能会导致不可靠的重定位 unreliable relocalization.。
•由于对象的移动,场景中的结构更改非常普遍,因此必须动态更新地图以合并这些新更改。
•汽车摄像头通常具有rolling shutter 快门时间,因此必须对其进行补偿,特别是对于相对较高的速度。
•通过利用多个摄像机之间的距离来解决比例尺的歧义,但是由于估计中的噪声,比例尺仍有可能漂移。
五,结论
在本文中,我们概述了工业训练的轨迹自动泊车系统。 我们讨论了经过训练的轨迹停车用例,并演示了如何使用Visual SLAM管道扩展当前的停车系统。 我们详细描述了Visual SLAM管道,并列出了商业部署中遇到的实际挑战。 为了鼓励进一步的研究,我们计划发布包含100,000张图像的数据集。 在未来的工作中,我们计划探索一个统一的多任务网络来执行视觉SLAM和其他物体检测模块。

















 9253
9253

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









