







作为【Head-DETR系列】的开篇之作,接下来,我将按照 Transformer–>detr–>deforable detr–>ConditionalDetr—>DABDetr 讲解这个系列。
本文致力于通过可变形操作来优化 DETR,DETR模块在处理图像特征图时的局限性,它存在收敛速度慢和特征空间分辨率有限的问题。为了缓解这些问题,我们提出了可变形的DETR,其注意力模块仅关注参考周围的一小部分关键采样点。可变形的DETR可以比DETR (尤其是在小物体上) 获得更好的性能,并且训练时间少10倍。
1 INTRODUCTION
现代对象检测器采用许多手工制作的组件 (Liu等人,2020),例如锚生成、基于规则的训练目标分配、非最大抑制 (NMS) 后处理。它们不是完全端到端的。最近,Carion等人 (2020) 提出了DETR以消除对这种手工制作的组件的需要,并构建了第一个完全端到端的对象检测器,实现了非常有竞争力的性能。DETR通过组合卷积神经网络 (cnn) 和Transformer (Vaswani等人,2017) 编码器-解码器,利用简单的架构。在适当设计的训练信号下,他们利用变压器的多功能和强大的关系建模功能来代替手工制作的规则。
简单回顾一下 DETR 整体结构:

尽管DETR具有有趣的设计和良好的性能,但它有自己的问题 :
( 1) 与现有的物体检测器相比,它需要更长的训练时间来收敛。例如,在COCO (Lin等人,2014) 基准上,DETR需要500个时期来收敛,这比更快的r-cnn (Ren等人,2015) 慢约10到20倍。训练周期长,相比faster rcnn慢10-20倍。收敛速度太慢,这是因为 Transformer 的参数初始化随机,在预测检测框的交叉 Attention 时,一开始注意力值几乎是平均的,完全分散,因此需要较长时间的训练;初始化时,attention model对于特征图上所有像素权重几乎是统一的(即一个query与所有的k相乘的贡献图比较均匀,也即 wq 均匀分布,然而理想结果是q与高度相关且稀疏的k相关性更强),导致需要用长训练周期学习去关注稀疏有意义的位置,即学习attention map前后显著的变化
(2) DETR在检测小物体时提供相对较低的性能。现代物体检测器通常利用多尺度特征,其中从高分辨率特征图中检测到小物体。同时,高分辨率特征图导致DETR无法接受的复杂性。
上述问题主要可以归因于在处理图像特征图时Transformer 组件的缺陷。在初始化时,注意力模块将几乎均匀的注意力权重投射到特征图中的所有像素。长时间的训练时间对于学习注意力权重以将注意力集中在稀疏有意义的位置上是必要的。另一方面,Transformer 编码器中的注意力权重计算是二次计算关于像素数字。因此,处理高分辨率特征图具有很高的计算和存储复杂性 。对小目标不友好。通常用多尺度特征来解小目标,然而高分辨率的特征图大大提高DETR复杂度(计算复杂度呈空间大小的平方倍上升, Nk 变多了) 。在检测小物体时效果不好,因为 Transformer 的复杂度高使得其必须使用分辨率较低的特征图来完成任务,一些细节会因此丢失。处理高分辨率特征存在计算两大,存储复杂的特点。transformer中encoder的注意力权重是关于像素点的平方
在图像域,可变形卷积(Dai et al., 2017)是一种处理稀疏空间位置的强大而高效的机制。它自然回避了上述问题。而元素关系建模机制是DETR成功的关键。
在本文中,我们提出了可变形DETR,它缓解了DETR收敛速度慢和复杂度高的问题。它结合了可变形卷积的稀疏空间采样的优点和变压器的关系建模能力。我们提出了可变形的注意模块,该模块处理一小组采样位置作为所有特征图像素中突出关键元素的预滤波器。该模块可以自然地扩展到聚合多尺度特征,而无需FPN的帮助(Lin et al., 2017a)。在Deformable DETR中,我们利用(多尺度)可变形注意模块来代替Transformer注意模块处理特征图,如图1所示。
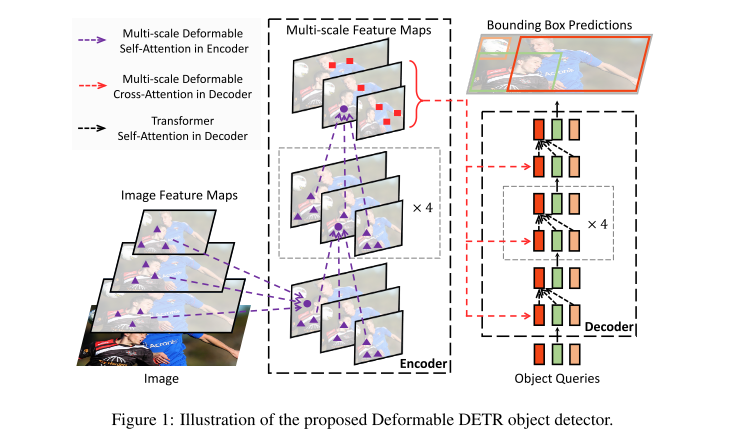
可变形DETR凭借其快速的收敛性以及计算和存储效率,为我们开发端到端对象检测器的变体提供了可能性。我们探索了一种简单有效的迭代边界盒细化机制,以提高检测性能。其中,区域建议也由变形DETR的变体生成,并进一步输入到解码器用于迭代边界框优化
与DETR相比,变形DETR可以获得更好的性能(特别是在小物体上),训练时间少10倍。提出的两级可变形DETR可以进一步提高性能。
创新点
于是本文针对上述的整体两个策略可以概括为:使用编码器输出的一些预测框来初始化解码器中的物体特征;使用多尺度特征和可变形卷积来细化检测框。
1、 让encoder初始化的权重不再是统一分布,即不再与所有key计算相似度,而是与更有意义的key计算相似度
2、 deformable convolution就是一种有效关注稀疏空间定位的方式
3、 随即提出deformable detr,融合deformable conv的稀疏空间采样与transformer相关性建模能力
4、 在整体feature map像素中,模型关注小序列的采样位置作为预滤波,作为key
5. DETR直接使用特征图进行训练,Deformable DETR使用注意力后的特征图进行训练(即每一个query搜索有效位置作为keys)
6. 重点修改了key的提取方式,以及贡献图的生成方式,贡献图直接使用query的特征回归
7. Deformable DETR比DETR训练快10x84. backbone使用resnext101-DCN-trick,在coco达到sota,尤其是小目标, APs=34.4
2 RELATED WORK
Efficient Attention Mechanism.Transformers (Vaswani等人,2017) 涉及自我注意和交叉注意机制。Transformers最著名的问题之一是巨大的关键元素数量下的高时间和内存复杂性,这在许多情况下阻碍了模型的可伸缩性。最近,为了解决这个问题已经做出了许多努力 (Tay等人,2020b),在实践中可以大致分为三类。
第一类是在键上使用预先定义的稀疏注意模式pre-defined sparse attention patterns on keys。最直接的范例是The most straightforward paradigm is restricting the attention pattern to be fixed local windows。尽管将注意力模式限制在本地社区可以降低复杂性,但它会丢失全局信息。 To compensate, attend key elements at fixed intervals to significantly increase the receptive field on keys.例如 允许少数特殊special tokens 访问所有key elements 。例如 还添加一些pre-fixed sparse attention patterns ,直接参加distant key elements。
第二类是学习依赖于数据的稀疏注意力。Kitaev等人 (2020) 提出了一种基于位置敏感哈希 (LSH) 的注意,该注意将查询和关键元素都哈希到不同的bin。Roy等人 (2020) 提出了类似的想法,其中k-means找出最相关的键。Tay等(2020a) 学习块排列以进行块稀疏注意。
第三类是探索自我关注中的低级属性。Wang等人 (2020b) 通过在尺寸尺寸上而不是通道尺寸上的线性投影来减少关键元素的数量。Katharopoulos等人 (2020); Choromanski等人 (2020) 通过内核化近似重写了自我注意的计算。
在图像领域,有效注意机制的设计 (例如,Parmar等人 (2018); Child等人 (2019); Huang等人 (2019); Ho等人 (2019); Wang等人 (2020a); Hu等人 (2019);ramachandran等人 (2019)) 仍然限于第一类。尽管理论上降低了复杂性,Ramachandran等人 (2019); Hu等人 (2019) 承认,由于存储器访问模式的内在限制,这种方法在实现上比具有相同触发器的传统卷积慢得多 (至少慢3倍)。
另一方面,如在Zhu等人 (2019a) 中所讨论的,存在卷积的变体,例如可变形卷积 (Dai等人,2017; Zhu等人,2019b) 和动态卷积 (Wu等人,2019),它们也可以被视为自我注意机制。特别是,可变形卷积在图像识别上比Transformers 自我注意更有效。同时,它缺乏元素关系建模机制。
我们提出的可变形注意力模块受到可变形卷积的启发,属于第二类。它仅关注根据查询元素的特征预测的一小部分固定采样点集。不同于Ramachandran等人 (2019); Hu等人 (2019),在相同的FLOPs.下,可变形的注意力只比传统的卷积稍慢。
Multi-scale Feature Representation for Object Detection.物体检测的主要困难之一是有效地表示不同尺度的物体。现代物体检测器通常利用多尺度特征来适应这一点。作为开创性工作之一,FPN (Lin等人,2017a) 提出了一种自上而下的路径来结合多尺度特征。PANet (Liu等人,2018b) 进一步在FPN的顶部增加了一条自下而上的路径。Kong等人 (2018) 通过全球关注操作结合了所有尺度的特征。Zhao等 (2019) 提出了一种融合多尺度特征的U形模块。最近,提出了NAS-FPN (Ghiasi等人,2019) 和Auto-FPN (Xu等人,2019) 以通过神经架构搜索自动设计跨尺度连接。Tan等人 (2020) 提出了BiFPN,它是PANet的重复简化版本。我们提出的多尺度可变形注意力模块可以通过注意力机制自然地聚合多尺度特征图,而无需这些特征金字塔网络的帮助。
3 REVISITING TRANSFORMERS AND DETR
Multi-Head Attention in Transformers.Transformers(Vaswani等人,2017) 是基于用于机器翻译的注意机制的网络架构。给定一个查询元素query (例如,输出句子中的目标词) 和一组关键元素 keys(例如,输入句子中的源词),多头注意模块根据注意权重自适应地聚合key内容,测量 query-key pairs 的兼容性(匹配情况)。为了使模型专注于来自不同表示子空间和不同位置的内容,将不同注意力头的输出与可学习的权重线性聚合。
Let q ∈ Ω q q ∈ Ω_q q∈Ωq indexes a query element with representation feature z q ∈ R C z_q ∈ R^C zq∈RC,
and k ∈ Ω k k ∈ Ω_k k∈Ωk indexes a key element with representation feature x k ∈ R C x_k ∈ R^C xk∈RC,
where C C C is the feature dimension, Ω q Ω_q Ωq and Ω k Ω_k Ωk specify the set of query and key elements,respectively.
Then the multi-head attention feature is calculated by
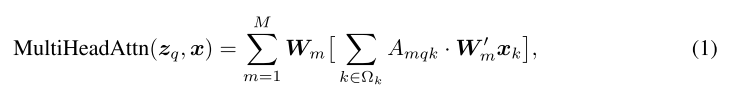
where m indexes the attention head;
W m ∈ R C × C v W_m∈ R^{C×Cv} Wm∈RC×Cv and W m ′ ∈ R C v × C W'_m∈ R^{Cv×C} Wm′∈RCv×C are of learnable weights
C v = C / M Cv = C/M Cv=C/M by default are normalized as
The attention weights 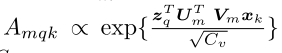 ,in which U m , V m ∈ R C v × C U_m,V_m ∈ R^{Cv×C} Um,Vm∈RCv×C are also learnable weights.
,in which U m , V m ∈ R C v × C U_m,V_m ∈ R^{Cv×C} Um,Vm∈RCv×C are also learnable weights.
A m q k A_{mqk}
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 515
515

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











