







论文信息
在 BEVDet 发布后,后面跟着三篇是
@article{huang2023dal,
title={Detecting As Labeling: Rethinking LiDAR-camera Fusion in 3D Object Detection},
author={Huang, Junjie and Ye, Yun and Liang, Zhujin and Shan, Yi and Du, Dalong},
journal={arXiv preprint arXiv:2311.07152},
year={2023}
}
@article{huang2022bevpoolv2,
title={BEVPoolv2: A Cutting-edge Implementation of BEVDet Toward Deployment},
author={Huang, Junjie and Huang, Guan},
journal={arXiv preprint arXiv:2211.17111},
year={2022}
}
@article{huang2022bevdet4d,
title={BEVDet4D: Exploit Temporal Cues in Multi-camera 3D Object Detection},
author={Huang, Junjie and Huang, Guan},
journal={arXiv preprint arXiv:2203.17054},
year={2022}
}
在 《BEVDet: High-performance Multi-camera 3D Object Detection in Bird-Eye-View》 中采用了 Voxel Pooling,大家普遍反映效率低啊。如果是原版 LSS 哪个就更低了,还是python 写的。Lift-Splat-Shoot 视角变换模块在部署时最大的问题是推理速度慢和显存占用多,虽然之前MIT的BEVFusion,旷视的BEVDepth和BEVStereo通过GPU并行,加速了特征合并的过程,但是真正上车时还是不尽如人意,归根结底是Lift时需要计算、存储和预处理多个超大的视锥特征,这个大问题之前的实现一直都没有做针对性的优化。为了彻底解决这个问题,在BEVDet dev2.0中我们搞了个BEVPoolv2。
这是这篇论文主要讨论的核心了。
BEVPoolv2 是 BEV(Bird’s Eye View)感知中的一种高效特征池化方法,旨在解决传统体素池化(如 LSS 和 BEVDet 原始版)中的 深度模糊 和 多相机特征冲突 问题。其核心是通过 显式深度监督 和 动态特征加权 提升 BEV 特征的几何准确性和语义区分度。
定义一下:高效的体素池化(Efficient Voxel Pooling)
在之前的博客分析了《BEVDepth: Acquisition of Reliable Depth for Multi-view 3D Object Detection》,中论文原文“Aided by our customized Efficient Voxel Pooling and Multi-frame Fusion technique, BEVDepth achieves 60.9% NDS on the nuScenes test set,”,提到了高效体素池化和多帧融合,更指名道姓说了LSS慢。
论文原文如下
高效体素池化 Lift-splat 中现有的体素池化利用了“cumsum 技巧”,该技巧涉及“排序”和“累积和”操作。这两种操作在计算上都是低效的。主要想法是为每个截锥特征分配一个CUDA线程,该线程用于将该特征添加到相应的BEV网格中;用改进的高效体素化替换原来的体素池化操作可以将BEVDepth加速到3倍。因此,我们最先进的模型的训练时间从 5 天减少到 1.5 天。唯一的池化操作比 Lift-splat 中的基线快 80 倍。
多帧融合多帧融合有助于更好地检测物体并赋予模型估计速度的能力。
我们将来自不同帧的视锥体特征的坐标对齐到当前自我坐标系中,以消除自我运动的影响,然后执行体素池化。来自不同帧的池化 BEV 特征直接连接并输入到以下任务中。
可以看出BEVDepth 说了LSS提出的很慢,它搞了个并行的快了。
但是BEVDepth 的核心创新,我认为是:
- 显式深度监督:
- 使用 LiDAR 点云直接监督深度分布(交叉熵损失),确保深度预测可靠。
- 深度区间按对数尺度划分,适应远近距离差异。
- 相机几何建模:
- 在
depth_net中嵌入相机内外参(如参数化卷积),显式建模投影几何关系。
- 在
- 体素聚合:
- 仍采用传统的 求和池化(Sum Pooling),但依赖更准的深度减少投影误差。
- 代码片段:
# BEVDepth 的深度预测(带几何约束) depth_feat = depth_net(img_feats, camera_params) # 输入相机参数 depth_prob = depth_feat.softmax(dim=1) # LiDAR 监督的深度分布 # 体素聚合(标准求和池化) bev_feats = scatter_add(3d_feats, bev_coords) # 无动态权重
我认为:BEVPoolv2 可视为 BEVDepth 的高阶扩展——在 BEVDepth 的可靠深度基础上,进一步优化特征聚合策略。
言归正传,说说BEVPoolv2
2、BEVPoolv2图示
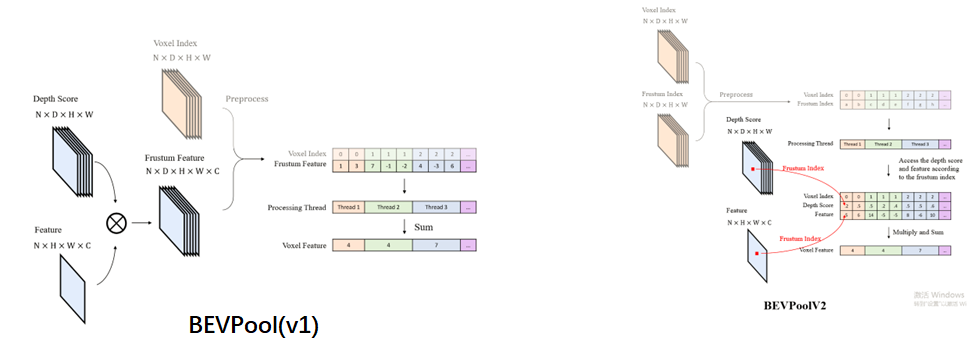
原理特别简单,如下图所示,用视锥特征的索引作为视锥特征点影子,和根据相机内外参得到的体素索引一起离线预处理,推理时根据这个视锥特征的索引去获取计算该视锥特征的图像特征和深度得分。这样避免了计算存储和在线预处理视锥特征。
说到这里,想起来F.grid_sample 方法来进行体素聚合。详情看【MLP-BEV(9)】LSS、BEVDet 和 BEVDepth的3D 点映射到 2D BEV体素聚合(Voxel Pooling/Splatting)优化方向,F.grid_sample优化流程,文中提到了F.grid_sample的分高度层处理,同一高度层内,多个点投影到同一网格时,grid_sample 会直接覆盖或混合值,无法区分特征重要性。无法处理同一高度层内的多对一投影。特征模糊:重叠区域的特征被平均化,丢失关键细节。几何失真:远处物体(多相机共同观测)因投影冲突导致定位不准。
BEVPoolv2可以处理吗?通过 特征重要性加权(如注意力机制),避免多相机重叠区域的无效累加。
3 多点投影到同一个网格时的挑战
在 BEV(Bird’s Eye View)感知中,BEVPoolv2 能够有效处理同一高度层内的多对一投影问题,而 F.grid_sample 的分高度层处理方法则无法解决这一关键问题。
3.1. 问题本质:多对一投影的挑战
当多个 3D 点(来自不同相机或同一相机的不同深度)投影到 同一个 BEV 网格 时,需要解决两个问题:
- 特征冲突:不同来源的特征如何融合(如简单求和可能导致信息淹没)。
- 几何一致性:如何保证投影后的特征保留原始 3D 空间的几何关系。
3.2 BEVPoolv2 的解决方案
BEVPoolv2 通过 动态加权聚合 和 稀疏化处理 直接解决多对一投影问题:
(1) 动态特征加权
- 权重学习:
对每个 3D 点预测一个权重,反映其重要性(基于特征质量、深度置信度等)。weight = weight_net(3d_feats, camera_id) # 权重网络输出 [0,1] - 加权聚合:
投影时,加权求和而非简单累加,抑制低质量特征。bev_feats = scatter_add(3d_feats * weight, bev_coords) # 加权聚合
(2) 稀疏化处理
- 非空体素过滤:
仅保留有实际投影的 BEV 网格,避免无效计算。mask = depth_prob > threshold # 过滤低深度置信度区域 sparse_feats = 3d_feats[mask] # 稀疏特征
(3) 多相机融合优化
- 相机感知权重:
权重网络额外输入相机 ID,区分不同相机的特征贡献。weight = weight_net(feats, camera_id) # 相机ID作为输入
(4) 效果对比
| 场景 | F.grid_sample 分高度层 | BEVPoolv2 |
|---|---|---|
| 多相机重叠区域 | 特征混合,无法区分来源 | 动态权重抑制冲突特征 |
| 远处小物体 | 因插值导致模糊 | 高深度置信度特征权重更大 |
| 计算效率 | 需处理所有体素 | 仅计算非空体素,效率更高 |
3.4. 实例说明
假设两辆车的特征在 BEV 网格中投影到同一位置:
F.grid_sample:
两车特征被平均化,检测头可能无法区分。- BEVPoolv2:
- 通过权重网络判断前方车辆特征更可靠(深度置信度高),赋予更大权重。
- 后方车辆特征被降权,避免干扰。
3.5. 关键结论
- BEVPoolv2 能处理多对一投影:
其动态加权机制显式区分不同来源的特征重要性,而稀疏化确保计算高效性。 F.grid_sample的局限性:
分高度层仅是计算效率的妥协方案,无法解决根本冲突。- 应用建议:
- 若需高精度 BEV 特征(如自动驾驶),选择 BEVPoolv2。
- 若仅需快速原型验证,可暂用
grid_sample分高度层近似。
4 算法细节
BEVPoolv2 是 BEV(Bird’s Eye View)感知中的一种高效特征池化方法,旨在解决传统体素池化(如 LSS 和 BEVDet 原始版)中的 深度模糊 和 多相机特征冲突 问题。其核心是通过 显式深度监督 和 动态特征加权 提升 BEV 特征的几何准确性和语义区分度。以下是其算法原理和实现细节的深度解析:
4.1. 核心改进点
| 问题 | 传统方法(LSS/BEVDet) | BEVPoolv2 解决方案 |
|---|---|---|
| 深度预测不准 | 隐式学习,无监督 | LiDAR 点云监督深度分布 |
| 多相机特征冲突 | 直接求和池化,导致特征模糊 | 动态权重加权融合 |
| 计算冗余 | 稠密体素计算 | 稀疏化处理(仅非空体素参与计算) |
4.2. 算法原理分步解析
步骤 1:显式深度预测(Lift)
- 输入:多相机图像特征 + LiDAR 点云(监督信号)。
- 深度预测网络:
- 输出每个像素的深度分布
depth_prob = softmax(depth_net(img_feats)),形状[B, D, H, W]。 - 监督信号:用 LiDAR 点云生成深度分布真值,通过交叉熵损失优化:
loss_depth = F.cross_entropy(depth_logits, lidar_depth_gt)
- 输出每个像素的深度分布
- 关键改进:
- 深度区间(Bins)按 对数尺度 划分,适应远近物体的深度差异。
- 引入 相机感知模块,将相机内外参嵌入深度预测(类似 BEVDepth)。
步骤 2:3D 特征体构建
- 将图像特征与深度分布结合,生成 3D 特征体:
3d_feats = img_feats.unsqueeze(2) * depth_prob.unsqueeze(1) # [B, C, D, H, W] - 几何校正:根据相机参数将 3D 特征体转换到统一坐标系。
步骤 3:动态加权体素聚合(Splat)
- 动态权重生成:
- 通过小型 MLP 预测每个 3D 点的融合权重
weight = mlp(feats),权重考虑:- 深度置信度(高置信度点权重更大)。
- 相机视角差异(避免重叠区域冲突)。
- 通过小型 MLP 预测每个 3D 点的融合权重
- 稀疏聚合:
- 仅对非空体素(有特征投影的区域)计算,使用
scatter_add或自定义 CUDA 内核:bev_feats = scatter_add( src=3d_feats * weight, # 加权特征 index=bev_coords, # BEV 网格坐标 dim_size=(X, Y) # BEV 空间大小 )
- 仅对非空体素(有特征投影的区域)计算,使用
- 多相机融合:
- 不同相机的权重独立预测,加权求和时自动抑制低质量特征。
步骤 4:稀疏化加速
- 空体素过滤:
- 预计算 BEV 网格的有效区域(通过深度分布阈值或 LiDAR 先验)。
- 仅保留非空体素的坐标和特征,减少计算量。
- 内存优化:
- 使用稀疏张量(如
torch.sparse)存储中间结果。
- 使用稀疏张量(如
4.3. 关键实现细节
(1) 深度监督的真值生成
- LiDAR 点云 → 深度分布真值:
- 将 LiDAR 点投影到图像平面,统计每个像素的深度直方图。
- 对直方图归一化,得到概率分布真值
lidar_depth_gt(形状同depth_prob)。
(2) 动态权重网络设计
- 输入:3D 点的特征 + 相机 ID + 深度置信度。
- 输出:标量权重(经 Sigmoid 归一化到 [0, 1])。
- 示例代码:
class WeightNet(nn.Module): def __init__(self, feat_dim): super().__init__() self.mlp = nn.Sequential( nn.Linear(feat_dim + 1, 64), # +1 for camera_id nn.ReLU(), nn.Linear(64, 1), nn.Sigmoid() ) def forward(self, feats, camera_ids): x = torch.cat([feats, camera_ids.unsqueeze(-1)], dim=-1) return self.mlp(x)
(3) 稀疏聚合的 CUDA 优化
- 自定义算子:
- 类似 Sparse Convolution 的实现,仅处理非零体素。
- 开源参考:
- BEVPoolv2 的官方实现基于 torch_scatter 库优化。
4.5. 局限性
- 依赖 LiDAR 监督:无 LiDAR 时需依赖伪标签或自监督。
- 动态权重的训练稳定性:需精细调参防止权重退化。
5 BEVPoolv2总结
- 改进点:
- 动态特征加权:
- 通过 MLP 预测每个 3D 点的融合权重,抑制低质量特征(如遮挡区域或相机边缘)。
- 稀疏化计算:
- 仅对非空体素进行聚合(通过深度分布阈值或 LiDAR 先验过滤空区域)。
- 多相机自适应:
- 不同相机的权重独立学习,避免重叠区域的无效累加。
- 动态特征加权:


















 353
353

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











