







Segment Anything Model(SAM)可以从输入提示(如点或框)生成高质量的对象掩模,并可用于生成图像中所有对象的掩模。
SAM代码:https://github.com/facebookresearch/segment-anything
SAM官网:https://segment-anything.com
SAM论文:https://arxiv.org/pdf/2304.02643.pdf
这个模型主要是使用提示工程来训练一个根据提示进行分割的预训练大模型,该模型具有在下游分割任务应用的潜力,并且可以与其他视觉任务组合形成其他视觉任务的新解决方案。
影响力:
1、该工作目前发表在arXiv上,工作量非常大。
2、今年2024的CVPR 应该有一些SAM的延申研究的一席之地。
3、基于提示工程的可组合系统设计将实现更广泛的应用,超越那些仅针对固定任务集进行训练的模型。
接下来,从任务、模型和数据工程三个方面向我们介绍了Meta AI的工作。
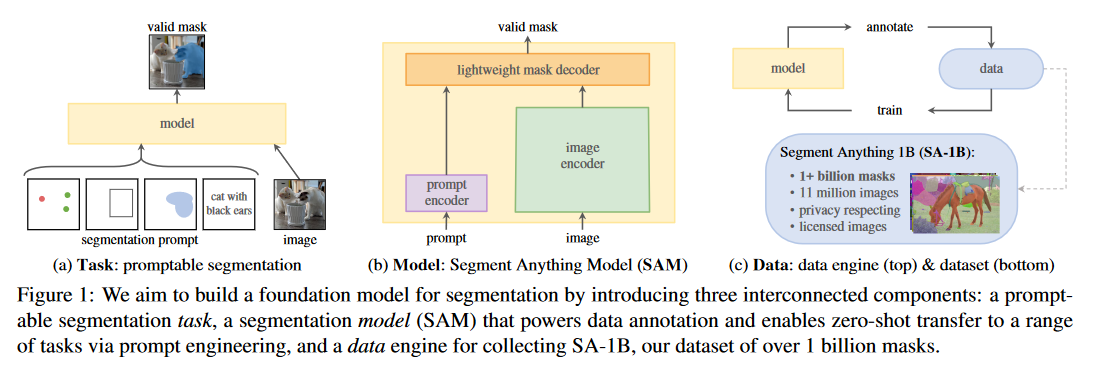
2. Segment Anything Task
受到自然语言处理(NLP)中通过预测下一个令牌进行基础模型预训练的启发,我们致力于构建一个分割任务的基础模型。我们的目标是定义一个任务,该任务具备与NLP中下一个令牌预测任务相类似的功能,从而为基础模型的预训练提供强有力的支撑,并通过prompt engineering(提示工程)灵活地应用于各种下游的分割任务。
We take inspiration from NLP, where the next token pre-diction task is used for foundation model pre-training and to solve diverse downstream tasks via prompt engineering [10]. To build a foundation model for segmentation, we aim to define a task with analogous capabilities
任务定义
我们首先将自然语言处理中的提示理念应用于图像分割,将其转化为分割掩码。这里的提示可以是明确的点、框、掩码,也可以是自由形式的文本,旨在指示图像中需要分割的内容。可提示的分割任务旨在根据给定的任何提示生成有效的分割掩码。即使提示存在歧义,指向多个对象,输出的掩码也应至少能覆盖其中一个对象的合理范围。这与期望语言模型对模糊提示产生一致响应的原理相似。我们选择此任务,是因为它能引导我们开发出一种自然的预训练算法,并通过提示实现零样本迁移到各种下游分割任务。
预训练过程
我们的可提示分割任务采用了自然的预训练策略。训练过程中,模型会为每个样本模拟各种提示,并将其预测结果与真实标签进行对比。我们借鉴了交互分割的灵感,但与之不同,我们的目标是使模型能够针对任何提示生成有效掩码,无论提示是否明确。这种设计确保了预训练模型在处理含歧义的场景时也能表现出色,对于自动标注等数据生成场景尤为重要。实现这一任务需要精心设计的模型和训练策略。
零样本迁移能力
通过预训练,我们的模型能够针对各种提示生成有效的分割掩码。这意味着,在推理阶段,通过设计适当的提示,下游任务可以无缝地利用我们的模型。例如,结合猫的边界框检测器,我们可以通过将检测到的边界框作为提示输入到模型中,来实现猫的实例分割。总的来说,各种实用的分割任务都可以被转化为提示的形式,由我们的模型来处理。我们在实验中探索了多个类似的零样本迁移任务。
任务泛化与应用
分割是一个涵盖广泛领域的任务,包括交互分割、边缘检测、超像素化等。我们的可提示分割任务旨在开发一个通用模型,通过提示工程来适应多种现有的和新出现的分割任务。这种能力体现了任务泛化的优势。与多任务分割系统不同,我们的模型在推理时可以作为一个组件,与其他算法结合,执行新的不同任务。例如,结合现有的对象检测器,我们的模型可以实现实例分割。
讨论与展望
提示和组合技术使单个模型能够以可拓展的方式执行各种任务,甚至包括设计时未预见到的任务。这与CLIP等模型在DALL·E图像生成系统中的应用类似。我们预见,基于提示工程的可组合系统设计将实现更广泛的应用,超越那些仅针对固定任务集进行训练的模型。此外,从组合的角度来看,我们的可提示分割模型与交互分割模型虽有所不同,但同样具备与其他算法系统集成的潜力。
3. Segment Anything Model
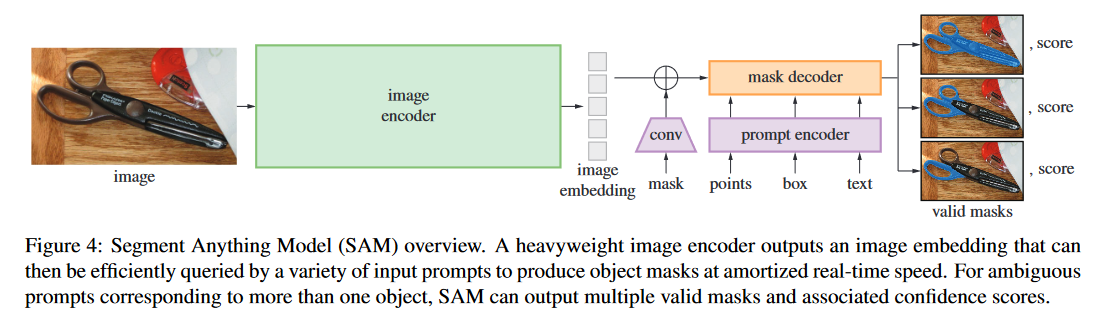
SAM有三个组件:图像编码器、灵活的提示编码器和快速掩码解码器。
图像编码器。Motivated by scalability and powerful pre-training methods, we use an MAE [47] pre-trained Vision Transformer (ViT) [33] minimally adapted to process high resolution inputs [62].
提示编码器。我们考虑两组提示:稀疏(点、框、文本)和密集(掩码)。稀疏提示通过位置编码表示点和框,并加上每个提示类型的嵌入和来自CLIP的现成文本编码器的自由形式文本。密集提示(即掩码)使用卷积嵌入,并与图像嵌入按元素求和。
掩码解码器。掩码解码器高效地将图像嵌入、提示嵌入和输出词元映射到掩码。此设计灵感来自,采用Transformer解码器块的修改,后跟动态掩码预测头。我们修改的解码器块使用两向(提示到图像嵌入和反向)的提示自注意力和交叉注意力来更新所有嵌入。运行两个块后,我们上采样图像嵌入,MLP将输出词元映射到动态线性分类器,然后在每个图像位置计算掩码前景概率。
解决歧义。有一个输出时,如果给出一个模棱两可的提示,模型将平均多个有效掩码。为了解决这个问题,我们修改模型以预测单个提示的多个输出掩码。我们发现3个掩码输出足以解决大多数常见情况(嵌套掩码通常最多三层:整体、部分和子部分)。在训练过程中,我们只回传掩码上的最小损失。为了排名掩码,模型预测每个掩码的置信度评分(即估计的IoU)。
效率。整个模型设计在很大程度上是出于效率考虑。给定预计算的图像嵌入,提示编码器和掩码解码器在网页浏览器中运行,在CPU上运行约50毫秒。此运行时性能使我们的模型无缝、实时交互式提示成为可能。
损失和训练。我们使用线性组合的focal loss和dice loss来监督掩码预测。我们使用几何提示的混合来训练可提示分割任务。我们通过每次掩码随机采样11次提示来模拟交互式设置,使SAM可以无缝集成到我们的数据引擎中。
4. Segment Anything Dataset
我们建立了一个数据引擎来使1.1B掩码数据集SA-1B的收集成为可能。数据引擎有三个阶段:
(1)模型辅助手工注释阶段;
(2)半自动阶段,其中自动预测的掩码与模型辅助注释的混合;
(3)完全自动阶段,在该阶段我们的模型在不需要注释者输入的情况下生成掩码。
我们将详细介绍每一个。
辅助手工阶段。在第一个阶段,类似于经典的交互式分割,一组专业注释者使用由SAM支持的浏览器内置的交互式分割工具,通过点击前景/背景对象点来标注掩码。掩码可以使用精确像素的“画笔”和“橡皮擦”工具进行精细调整。我们的模型辅助注释在浏览器内直接实时运行(使用预计算的图像嵌入),使真正的交互式体验成为可能。我们没有对标注对象施加语义约束,注释者自由标注“东西”和“事物”。我们建议注释者标注他们可以命名或描述的对象,但没有收集这些名称或描述。要求注释者按突出度标注对象,并鼓励在一个掩码需要超过30秒来注释时继续到下一张图像。
在这个阶段开始时,SAM使用常见的公共分割数据集进行训练。收集足够的数据注释后,SAM仅使用新注释的掩码重新训练。随着收集的掩码越来越多,图像编码器从ViT-B扩展到ViT-H,其他架构细节也在发展,总共我们重新训练了模型6次。随着模型的提高,每个掩码的平均注释时间从34秒降到14秒。我们注意到14秒比COCO的掩码注释快6.5倍,仅比extreme points的边界框标注慢2倍。随着SAM的提高,每个图像的平均掩码数从20个增加到44个。总体而言,在这个阶段我们从12万张图像中收集了430万个掩码。
半自动阶段。在这个阶段,我们的目标是增加掩码的多样性,以提高模型对任何东西进行分割的能力。为了让注释者关注较不显著的对象,我们首先自动检测可信的掩码。然后,我们向注释者展示预填充这些掩码的图像,并要求他们注释任何其他未注释的对象。为了检测可信的掩码,我们使用“对象”类别在第一个阶段的所有掩码上训练了一个边界框检测器。在这个阶段,我们在18万张图像中收集了额外的590万个掩码(总共1020万个掩码)。与第一个阶段一样,我们定期使用新收集的数据重新训练我们的模型(5次)。每个掩码的平均注释时间回升到34秒(不包括自动掩码),因为这些对象更难以标注。每个图像的平均掩码数从44个增加到72个(包括自动掩码)。
完全自动阶段。在最后一个阶段,注释是完全自动的。这是由于我们对模型进行了两大改进而变为可能的。首先,在这个阶段开始时,我们已经收集了足够的掩码来大大改进模型,包括前一阶段的多样化掩码。第二,到了这个阶段,我们已经开发出了考虑歧义的模型,这使我们即使在歧义的情况下也可以预测有效的掩码。具体来说,我们用32×32的定期网格提示模型,对每个点预测一组可能对应于有效对象的掩码。有了考虑歧义的模型,如果一个点位于部分或子部分上,我们的模型将返回子部分、部分和整个对象。我们模型的IoU预测模块用于选择可信的掩码。此外,我们只选择稳定的掩码(如果阈值概率图在0.5−δ和0.5+δ,我们认为一个掩码是稳定的)。最后,选择可信和稳定的掩码后,我们应用非最大值抑制(NMS)来过滤重复项。为了进一步提高较小掩码的质量,我们还处理多个重叠的放大图像裁剪。我们将完全自动的掩码生成应用于数据集中的1100万张图像,产生总共11亿个高质量掩码。下一步,我们将描述和分析所产生的数据集SA-1B。
参考
https://zhuanlan.zhihu.com/p/625459494
https://blog.csdn.net/shanglianlm/article/details/131370090

















 8810
8810

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









