







在CVPR 2025上,上海交通大学等机构提出了一种新的数据集蒸馏方法:NCFM(Neural Characteristic Function Matching)。这种方法显著降低了GPU显存占用,提升了训练速度,并在单张NVIDIA 2080 Ti GPU上成功完成了CIFAR-100的无损蒸馏。NCFM相比其他方法,GPU显存占用降低了300倍以上,训练速度提升了20倍。
论文
论文名:《Dataset Distillation with Neural Characteristic Function: A Minmax Perspective》(基于神经特征函数的数据集蒸馏:一个 Minmax 视角)
数据蒸馏 (Dataset Distillation) 的目标就像给数据集做“瘦身”, 用少量合成数据 (Synthetic Data) “浓缩” 原始大数据集 (Real Data) 的精华信息,让模型仅用这些“迷你”数据就能达到甚至超越在原始数据集上的训练效果。
现有方法的困境
-
存储压力山大: 动辄TB甚至PB级别的数据,存储成本高昂
-
训练耗时漫长: 在海量数据上训练模型,计算资源和时间成本都让人望而却步
-
内存瓶颈凸显:大模型 + 大数据,GPU显存分分钟被榨干
现有方法的困境: “像素级”匹配 vs. “分布级”差异
目前,数据集蒸馏方法主要分为两大类:
-
特征匹配 (Feature Matching): 这类方法就像“像素级”比对,直接比较合成数据和真实数据在特征空间的相似度。 例如,早期的 MSE (均方误差) 方法就是典型代表,但它往往忽略了数据的高维语义信息,效果有限。
-
分布匹配 (Distribution Matching): 这类方法更注重“分布级”的相似性,试图让合成数据和真实数据在分布上尽可能一致。 MMD (最大均值差异) 是常用的度量指标,但研究表明,MMD仅仅对齐了数据的低阶矩,并不能保证整体分布的相似性,而且计算复杂度较高。
简单来说,现有方法要么过于简单粗暴,无法捕捉数据的深层分布;要么计算复杂,效率不高。这就限制了数据集蒸馏技术的进一步发展。
NCFM: Minmax 博弈下的“神经特征函数”
为了突破现有方法的瓶颈,NCFM 从全新的 Minmax 博弈视角出发, 引入了 “神经特征函数差异 (Neural Characteristic Function Discrepancy, NCFD)” 这一创新度量指标。
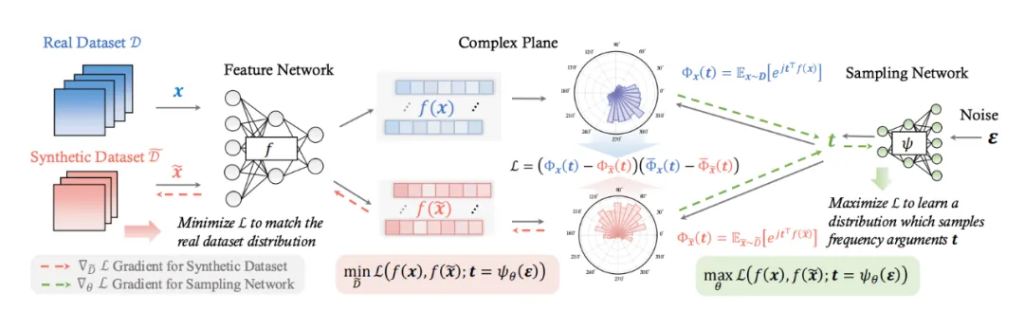
- Minmax 博弈: “矛与盾”的对抗学习
NCFM 将数据集蒸馏问题重新定义为一个 Minmax 优化问题,就像一场“矛与盾”的对抗游戏:
“矛” (Discrepancy Metric Network, 差异度量网络 ψ):它的目标是 最大化 (Max)合成数据和真实数据之间的差异 (Discrepancy), 努力找到一个最能区分二者分布的“判别器”。 这个“判别器”就是神经特征函数差异 (NCFD)
“盾” (Synthetic Data, 合成数据 D):它的目标是 最小化 (Min) 在 “矛” 的度量下,合成数据和真实数据之间的差异, 努力生成尽可能“逼真”的合成数据, “欺骗” “判别器”
通过 “矛与盾” 的不断对抗和迭代优化,NCFM 能够 自适应地学习到一个更鲁棒、更有效的差异度量指标 (NCFD), 并生成更高质量的合成数据。 这种 Minmax 框架与 GANs 的对抗生成思想有异曲同工之妙,但目标和实现方式却截然不同。
- NCFD: 基于“特征函数”的全面分布刻画
NCFD 的核心创新在于 “神经特征函数差异” 这一度量指标。 它巧妙地利用了特征函数 (Characteristic Function, CF)的强大能力来刻画数据分布
什么是特征函数 (CF)?简单来说, 特征函数就是概率密度函数的傅里叶变换。它具有以下关键优势:
唯一性:一个分布对应唯一的特征函数,反之亦然。这意味着特征函数能够完整、无损地编码分布的全部信息
全面性: 特征函数包含了分布的所有矩信息,比 MMD 仅对齐低阶矩更全面
NCFD 如何“神经”?NCFM 并没有直接使用传统的特征函数,而是引入了一个轻量级的神经网络 ψ 来学习特征函数的频率参数 t 的采样策略。这样做的好处是:
自适应性: 神经网络 ψ 可以根据数据分布的特点, 动态调整频率参数的采样策略, 最大化差异度量 (NCFD)
高效性:相比于 MMD 的二次复杂度, NCFD 的计算复杂度是线性的,更高效
- 相位 (Phase) 与幅度 (Amplitude) 的精妙平衡
NCFM 在 NCFD 的计算中, 特别关注了神经网络特征在复数域的 “相位 (Phase)” 和 “幅度 (Amplitude)” 信息
相位信息:编码了数据的 “中心” 和 “模式”, 对于保证合成数据的 “真实性 (Realism)”至关重要
幅度信息:反映了数据的“尺度” 和 “范围”, 有助于提升合成数据的“多样性 (Diversity)”。
NCFM 通过精妙地平衡相位和幅度信息, 使得合成数据既能保持真实感,又能兼顾多样性, 从而显著提升了蒸馏性能
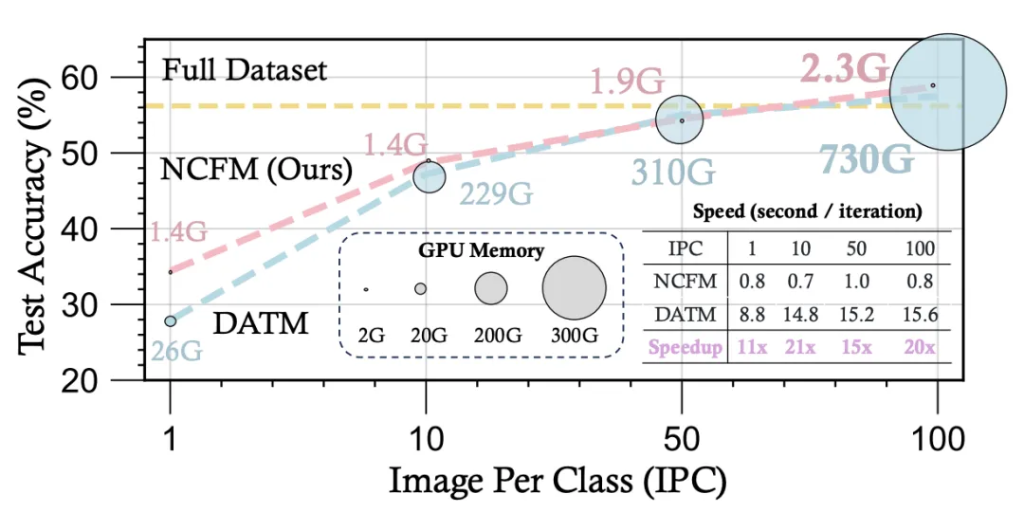
实验结果: 性能与效率的双重 “王炸”
实验结果充分证明了 NCFM 的卓越性能和效率:
性能大幅超越 SOTA: 在 CIFAR-10, CIFAR-100, Tiny ImageNet 以及高分辨率的 ImageNet 子集上,NCFM 都显著超越了现有最先进 (SOTA) 的数据集蒸馏方法。 在 ImageSquawk 高分辨率数据集上,NCFM 甚至取得了惊人的 20.5% 的精度提升!
资源效率惊人:相比于 DATM 等 SOTA 方法,NCFM 的 GPU 显存占用降低了 300 倍以上! 训练速度提升了 20 倍!更令人震惊的是,NCFM 仅用 2.3GB 显存,就在单张 NVIDIA 2080 Ti GPU 上成功完成了 CIFAR-100 的无损蒸馏! 这在之前是难以想象的

















 6157
6157

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









