







QuantML-Qlib开发版 | AAAI最佳论文Informer用于金融市场预测【附代码】
原创 QuantML QuantML 2024-04-24 07:26 上海

1. 模型介绍
论文:《Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting》 作者:Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, Wancai Zhang,来自北京航空航天大学、加州大学伯克利分校、罗格斯大学和SEDD公司
文章提出了一个名为Informer的模型,旨在提高长序列时间序列预测(LSTF)的预测能力。文章荣获2021 AAAI Best paper
摘要
-
背景:许多实际应用需要预测长序列时间序列,例如电力消费规划。这要求模型能够捕捉输入和输出之间的精确长距离依赖关系。
-
现有问题:现有的Transformer模型在处理长序列时间序列预测时存在一些问题,包括二次时间复杂度、高内存使用率和编码器-解码器架构的固有限制。
-
Informer模型:为了解决这些问题,作者设计了一个高效的基于Transformer的模型,具有三个显著特点:
-
ProbSparse自注意力机制:时间复杂度和内存使用为O(L log L),能够在序列依赖对齐上取得可比的性能。
-
自注意力蒸馏操作:通过减少层输入来突出显示主导注意力,有效处理极长输入序列。
-
生成式解码器:在一次前向操作中预测长期序列,而不是逐步方式,显著提高了长序列预测的推理速度。
-
引言
-
时间序列预测的重要性:在许多领域,如传感器网络监控、能源和智能电网管理、经济和金融、疾病传播分析等,时间序列预测都是一个关键因素。
-
长序列时间序列预测的挑战:现有的方法大多设计用于短期问题设置,例如预测48个点或更少。随着序列长度的增加,模型的预测能力受到挑战。
方法论
-
LSTF问题定义:在滚动预测设置下,输入Xt和输出Yt的定义,鼓励比以往工作更长的输出长度Ly。
-
编码器-解码器架构:许多流行的模型采用编码器-解码器架构,将输入表示编码为隐藏状态,然后从这些状态解码输出表示。
-
有效的自注意力机制:介绍了ProbSparse自注意力机制,通过概率形式的核平滑器定义查询的注意力,并通过经验近似来高效获取查询稀疏度测量。
模型概述
-
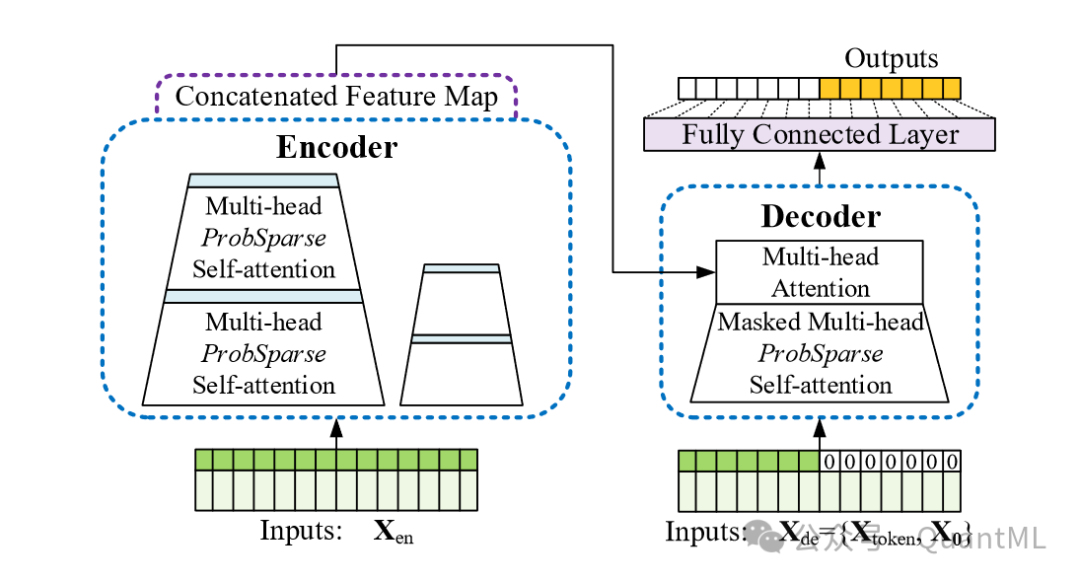
编码器:接收大量长序列输入,用ProbSparse自注意力替换了传统的自注意力。通过自注意力蒸馏操作提取主导注意力,减少网络尺寸。
-
解码器:接收长序列输入,将目标元素填充为零,测量特征图的加权注意力组合,并以生成式风格立即预测输出元素。
实验
-
数据集:在四个大规模数据集上进行了广泛的实验,包括两个收集的现实世界数据集和两个公共基准数据集。
-
基线比较:与五种时间序列预测方法进行了比较,包括ARIMA、Prophet、LSTMa、LSTnet和DeepAR。
-
超参数调整:对超参数进行了网格搜索,以找到最佳配置。
-
设置:每个数据集的输入都进行了零均值归一化处理。
结果与分析
-
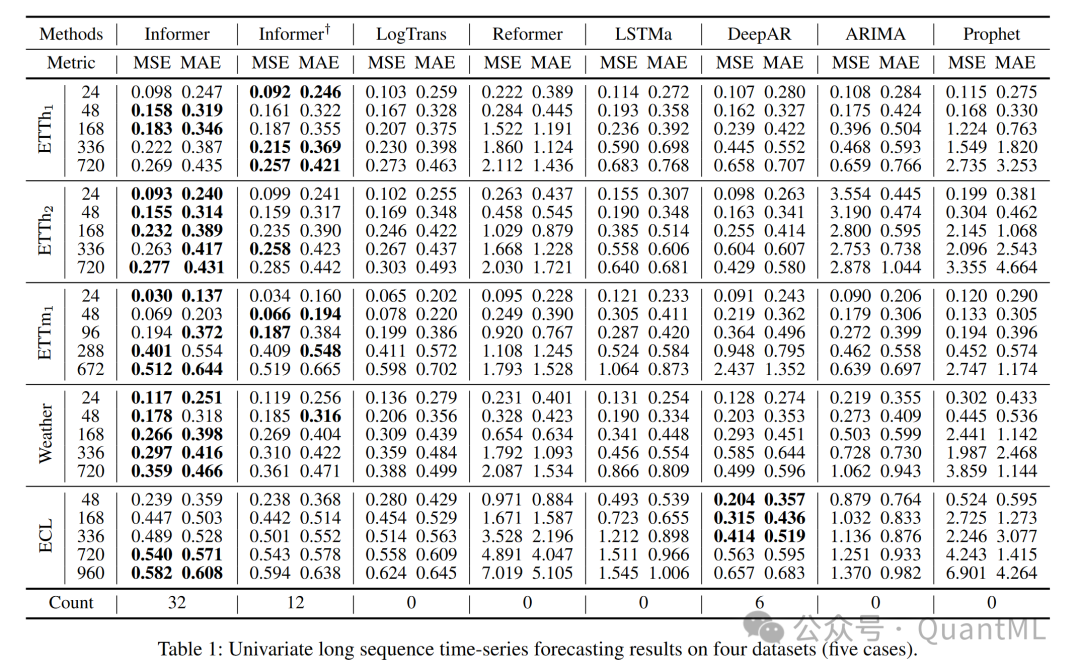
单变量时间序列预测:Informer在所有数据集上显著提高了推理性能,并且随着预测范围的增长,预测误差缓慢上升。
-
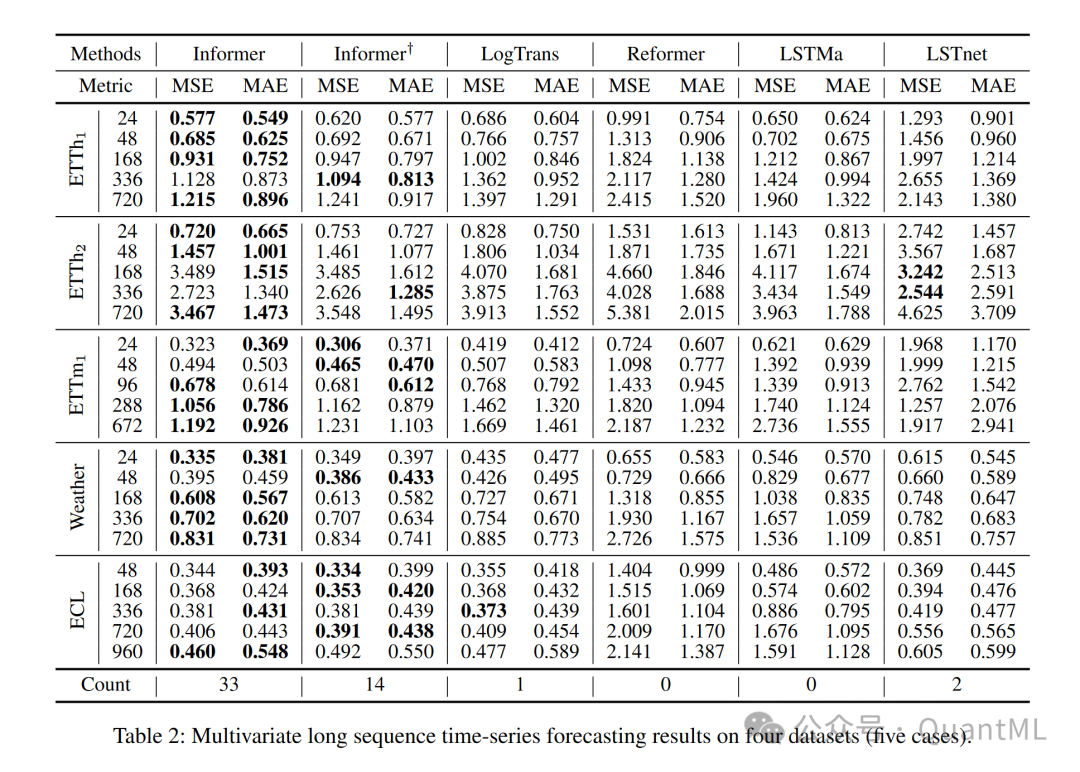
多变量时间序列预测:Informer在多变量设置中的表现仍然优于其他方法,并且在不同粒度级别的序列上表现更好。
参数敏感性分析
-
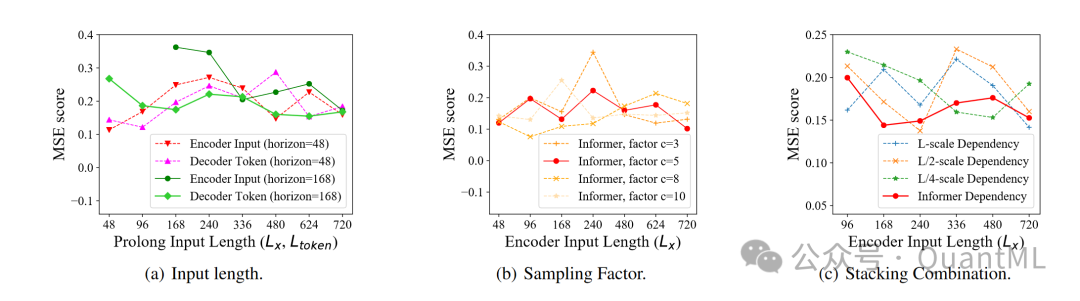
输入长度:对于短序列,最初增加编码器/解码器的输入长度会降低性能,但随着长度的进一步增加,性能会提高。
-
采样因子:控制ProbSparse自注意力中的信息带宽,从较小的因子开始逐渐增大,性能略有提升并最终稳定。
消融研究
-
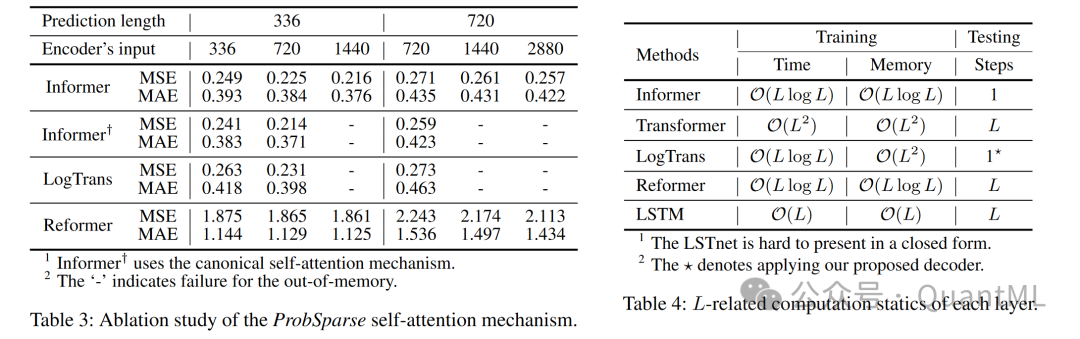
ProbSparse自注意力机制:与LogTrans和Reformer相比,ProbSparse自注意力在极端情况下表现更好。
-
自注意力蒸馏:去除蒸馏操作后,模型在更长输入下会出现内存溢出(OOM)。
-
生成式解码器:Informer的解码器能够通过时间戳捕捉个别的长距离依赖关系,避免误差累积。
计算效率
-
训练/测试时间:Informer在训练和测试阶段都展现出了优异的效率,尤其是在测试阶段,由于生成式解码器的使用,比其他方法快得多。
结论
文章提出的Informer模型在长序列时间序列预测问题上表现出色,通过ProbSparse自注意力机制和蒸馏操作有效处理了传统Transformer的挑战,并通过精心设计的生成式解码器缓解了传统编码器-解码器架构的限制。
2. 代码部分
我们在中QuantML-Qlib实现模型。由于有部分c代码,需要编译后再使用,在QuantML-Qlib根目录下运行以下命令进行编译
python setup.py build_ext --inplace然后将我们的代码拷贝进examples/benchmarks
在yaml文件中设置好数据路径,超参数后,运行run.py即可。
模型代码在Informer.py中, 代码下载地址见星球。
class Informer(Model):def __init__(self,enc_in: int,dec_in: int,c_out: int,seq_len: int,pred_len: int,embed_type: int = 0,d_model: int = 512,n_heads: int = 8,e_layers: int = 3,d_layers: int = 2,d_ff: int = 2048,dropout: float = 0.05,attn: str = "prob",embed: str = "fixed",freq: str = "d",activation: str = "gelu",output_attention: bool = False,distil: bool = False,mix: bool = False,device: str = "cuda",factor: int = 5,padding: bool = True,padding_var: float = 0.0,seq_len_out: int = 1,label_len: int = 1,pred_len_out: int = 1,num_workers: int = 0,batch_size: int = 32,eval_batch_size: int = 32,iter: int = 2,n_epochs: int = 10,early_stop: int = 2,lr: float = 0.001,warmup_prop: float = 0.1,weight_decay: float = 0.0001,gradient_clip_val: float = 0.1,loss: str = "mse",l1: float = 0.0,l2: float = 0.0,metric: str = "mse",optimizer: str = "adam",scheduler: str = "linear",seed: int = 42,verbose: bool = False,GPU: int = 0,**kwargs # other parameters):self.logger = get_module_logger("PatchTST")self.enc_in = enc_inself.dec_in = dec_inself.c_out = c_outself.seq_len = seq_lenself.pred_len = pred_lenself.embed_type = embed_typeself.d_model = d_modelself.n_heads = n_headsself.e_layers = e_layersself.d_layers = d_layersself.d_ff = d_ffself.dropout = dropoutself.attn = attnself.embed = embedself.freq = freqself.activation = activationself.output_attention = output_attentionself.distil = distilself.mix = mixself.device = deviceself.factor = factorself.padding = paddingself.padding_var = padding_varself.seq_len_out = seq_len_outself.label_len = label_lenself.pred_len_out = pred_len_outself.num_workers = num_workersself.batch_size = batch_sizeself.eval_batch_size = eval_batch_sizeself.iter = iterself.n_epochs = n_epochsself.early_stop = early_stopself.lr = lrself.warmup_prop = warmup_propself.weight_decay = weight_decayself.gradient_clip_val = gradient_clip_valself.loss = lossself.l1 = l1self.l2 = l2self.metric = metricself.optimizer = optimizerself.scheduler = schedulerself.seed = seedself.verbose = verboseself.device = torch.device("cuda:%d" % (GPU) if torch.cuda.is_available() and GPU >= 0 else "cpu")if self.seed is not None:np.random.seed(self.seed)torch.manual_seed(self.seed)self.model = InformerModel(self,).to(self.device)if optimizer.lower() == "adam":self.train_optimizer = optim.Adam(self.model.parameters(), lr=self.lr)elif optimizer.lower() == "gd":self.train_optimizer = optim.SGD(self.model.parameters(), lr=self.lr)else:raise NotImplementedError("optimizer {} is not supported!".format(optimizer))self.fitted = Falseself.model.to(self.device)@propertydef use_gpu(self):return self.device != torch.device("cpu")def mse(self, pred, label, weight):loss = weight * (pred - label) ** 2return torch.mean(loss)def loss_fn(self, pred, label, weight):mask = ~torch.isnan(label)if weight is None:weight = torch.ones_like(label)if self.loss == "mse":return self.mse(pred[mask], label[mask], weight[mask])raise ValueError("unknown loss `%s`" % self.loss)def metric_fn(self, pred, label):mask = torch.isfinite(label)if self.metric in ("", "loss"):return -self.loss_fn(pred[mask], label[mask], weight=None)raise ValueError("unknown metric `%s`" % self.metric)def train_epoch(self, train_loader):self.model.train()scores = []losses = []for _, (input_x, weight_x) in enumerate(tqdm(train_loader, mininterval=2)):seq_x, seq_y, emb_mark = input_xseq_x = seq_x.to(torch.float32)seq_y = seq_y.to(torch.float32)# seq_x = torch.concat([seq_x, seq_y], axis=2)seq_x = seq_x[:, :-self.pred_len, :]dec_x = torch.zeros_like(seq_y[:, -self.pred_len:, :]).float()dec_x = torch.cat([seq_y[:, :self.seq_len, :], dec_x], dim=1)seq_x_mark = emb_mark[:, :-self.pred_len, :]seq_y_mark = emb_markself.train_optimizer.zero_grad()if self.device.type == 'cuda':seq_x = seq_x.float().cuda()seq_y = seq_y.float().cuda()dec_x = dec_x.float().cuda()seq_x_mark = seq_x_mark.float().cuda()seq_y_mark = seq_y_mark.float().cuda()pred = self.model(seq_x,seq_x_mark, dec_x ,seq_y_mark)# use MSE lossoutputs = pred[:, -1:, -1:]label = seq_y[:, -1:, :]loss = self.loss_fn(outputs, label, weight=None)losses.append(loss.item())if loss.isnan():self.logger.info('loss is nan, checking inputs')score = self.metric_fn(outputs, label)scores.append(score.item())loss.backward()self.train_optimizer.step()return np.mean(losses), np.mean(scores)def test_epoch(self, data_loader):self.model.eval()scores = []losses = []try:for _, (input_x, weight_x) in enumerate(tqdm(data_loader, mininterval=2)):seq_x, seq_y, emb_mark = input_xseq_x = seq_x.to(torch.float32)seq_y = seq_y.to(torch.float32)# seq_x = torch.concat([seq_x, seq_y], axis=2)seq_x = seq_x[:, :-self.pred_len, :]dec_x = torch.zeros_like(seq_y[:, -self.pred_len:, :]).float()dec_x = torch.cat([seq_y[:, :self.seq_len, :], dec_x], dim=1)seq_x_mark = emb_mark[:, :-self.pred_len, :]seq_y_mark = emb_markself.train_optimizer.zero_grad()if self.device.type == 'cuda':seq_x = seq_x.float().cuda()seq_y = seq_y.float().cuda()dec_x = dec_x.float().cuda()seq_x_mark = seq_x_mark.float().cuda()seq_y_mark = seq_y_mark.float().cuda()pred = self.model(seq_x, seq_x_mark, dec_x, seq_y_mark)# use MSE lossoutputs = pred[:, -1:, -1:]label = seq_y[:, -1:, :]loss = self.loss_fn(outputs, label, weight=None)losses.append(loss.item())if loss.isnan():self.logger.info('loss is nan, checking inputs')score = self.metric_fn(outputs, label)scores.append(score.item())return np.mean(losses), np.mean(scores)except Exception as e:print(e)return 1, -1def fit(self,dataset,evals_result=dict(),save_path=None,reweighter=None,):sys.stdout.flush()dl_train = dataset.prepare("train", col_set=["feature", "label"], data_key=DataHandlerLP.DK_L)dl_valid = dataset.prepare("valid", col_set=["feature", "label"], data_key=DataHandlerLP.DK_L)if dl_train.empty or dl_valid.empty:raise ValueError("Empty data from dataset, please check your dataset config.")dl_train.config(fillna_type="ffill+bfill") # process nan brought by dataloaderdl_valid.config(fillna_type="ffill+bfill") # process nan brought by dataloaderif reweighter is None:wl_train = np.ones(len(dl_train))wl_valid = np.ones(len(dl_valid))elif isinstance(reweighter, Reweighter):wl_train = reweighter.reweight(dl_train)wl_valid = reweighter.reweight(dl_valid)else:raise ValueError("Unsupported reweighter type.")train_loader = DataLoader(ConcatDataset(dl_train, wl_train),batch_size=self.batch_size,shuffle=False,num_workers=self.num_workers,drop_last=True,# pin_memory=True,# persistent_workers=True,)valid_loader = DataLoader(ConcatDataset(dl_valid, wl_valid),batch_size=self.batch_size,shuffle=False,num_workers=self.num_workers,drop_last=False,# pin_memory=True,# persistent_workers=True,)save_path = get_or_create_path(save_path)self.fitted = Truestop_steps = 0train_loss = 0best_score = -np.infbest_epoch = 0evals_result["train"] = []evals_result["valid"] = []############################## 4. train the model ################################start_time = time.time()for epoch in range(1, self.n_epochs + 1):self.logger.info('batch num: {}'.format(len(train_loader)))step = 0self.logger.info("Epoch%d:", epoch)self.logger.info("training...")train_loss, train_score = self.train_epoch(train_loader)self.logger.info("evaluating...")# train_loss, train_score = self.test_epoch(train_loader)val_loss, val_score = self.test_epoch(valid_loader)self.logger.info("train %.6f, valid %.6f" % (train_score, val_score))if abs(train_score) < 1e-3:self.logger.info("train score is too small, break")evals_result["train"].append(train_score)evals_result["valid"].append(val_score)if val_score > best_score:best_score = val_scorestop_steps = 0best_epoch = stepbest_param = copy.deepcopy(self.model.state_dict())else:stop_steps += 1if stop_steps >= self.early_stop:self.logger.info("early stop")break# flush the outputsys.stdout.flush()end_time = time.time()total_time = end_time - start_timeself.logger.info('Total running time: {} seconds'.format(total_time))self.logger.info("best score: %.6lf @ %d" % (best_score, best_epoch))self.model.load_state_dict(best_param)torch.save(best_param, save_path)if self.use_gpu:torch.cuda.empty_cache()def predict(self, dataset):if not self.fitted:raise ValueError("model is not fitted yet!")dl_test = dataset.prepare("test", col_set=["feature", "label"], data_key=DataHandlerLP.DK_I)dl_test.config(fillna_type="ffill+bfill")test_loader = DataLoader(dl_test, batch_size=self.batch_size, num_workers=self.num_workers)self.model.eval()preds = []for _, input_x in enumerate(tqdm(test_loader, mininterval=2)):seq_x, seq_y, emb_mark = input_xseq_x = seq_x.to(torch.float32)seq_y = seq_y.to(torch.float32)# seq_x = torch.concat([seq_x, seq_y], axis=2)seq_x = seq_x[:, :-self.pred_len, :]dec_x = torch.zeros_like(seq_y[:, -self.pred_len:, :]).float()dec_x = torch.cat([seq_y[:, :self.seq_len, :], dec_x], dim=1)seq_x_mark = emb_mark[:, :-self.pred_len, :]seq_y_mark = emb_markself.train_optimizer.zero_grad()if self.device.type == 'cuda':seq_x = seq_x.float().cuda()dec_x = dec_x.float().cuda()seq_x_mark = seq_x_mark.float().cuda()seq_y_mark = seq_y_mark.float().cuda()with torch.no_grad():try:pred = self.model(seq_x, seq_x_mark, dec_x, seq_y_mark)outputs = pred[:, -1:, -1:]except Exception as e:print(e)print(' _ : ', _)preds.append(outputs.detach().cpu().numpy())return pd.Series(np.concatenate(preds).flatten(), index=dl_test.get_index())
QuantML-Qlib项目代码见星球。
QuantML-Qlib是一个非常强大的AI量化投资框架,基于QLIB底层开发,我们进行了一系列改进,包括数据接口优化,因子挖掘算法,各类深度学习模型,回测优化,大模型接入等等。后续会逐步在公众号更新。

















 1292
1292

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









