







LLMs之AnythingLLM:anything-llm的简介、安装和使用方法、案例应用之详细攻略
目录
4、部署方法:Docker、AWS、GCP、Digital Ocean、Render.com、Railway等
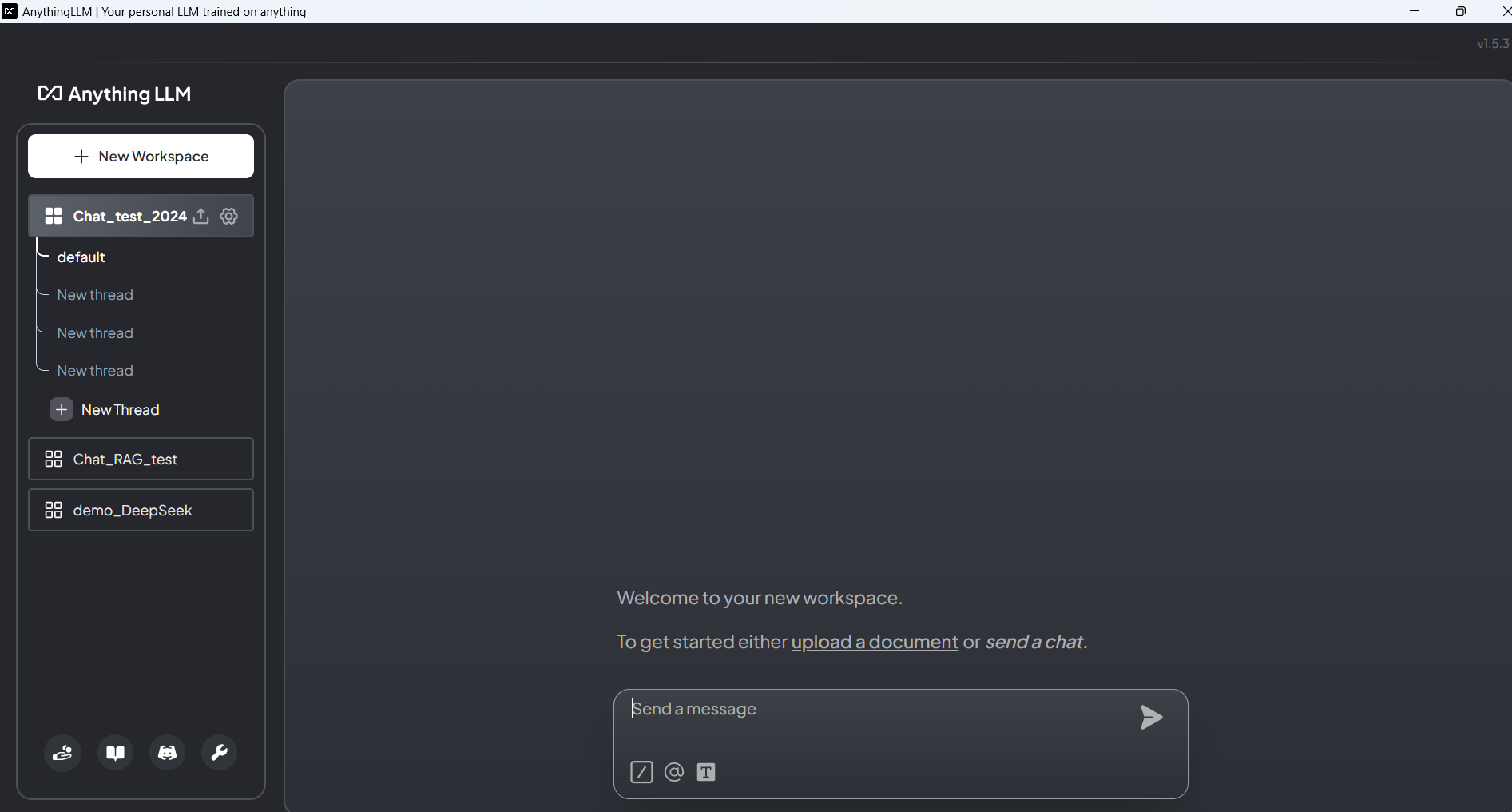
T2、新建工作区(workspace)并测试RAG功能:上传文档并在界面中实现对话查询
设置Chat Setting和Vector Database
AnythingLLM的简介
AnythingLLM是一款您正在寻找的一体化人工智能应用程序。与您的文档进行聊天,使用AI代理,超级可配置,多用户,并且无需烦人的设置。
AnythingLLM是一个全栈应用程序,可以使用商用或开源的LLM/嵌入器/语义向量数据库模型,帮助用户在本地或云端搭建个性化的聊天机器人系统,且无需复杂设置。
AnythingLLM是一个方便易用的端到端聊天机器人应用,支持丰富的模型和文档管理功能,且部署方式灵活多样,可以帮助用户轻松打造个性化的机器人系统。
AnythingLLM是一个全栈应用程序,可以让您将任何文档、资源或内容转化为任何LLM在聊天过程中可以用作参考的上下文。该应用程序允许您选择使用哪个LLM或矢量数据库,并支持多用户管理和权限。
AnythingLLM是一个全栈应用程序,您可以使用现成的商业LLM或流行的开源LLM和矢量数据库解决方案构建一个无需妥协的私人ChatGPT,您既可以在本地运行,也可以远程托管,并能够智能地与您提供的任何文档进行聊天。
AnythingLLM将您的文档划分为称为工作区的对象。工作区类似于线程,但额外添加了对文档的容器化。工作区可以共享文档,但它们彼此之间不会交流,因此您可以保持每个工作区的上下文清晰。
官网地址:AnythingLLM | The ultimate AI business intelligence tool
1、主要功能
>> 支持多线程、多用户、权限管理。每个用户可以有自己的工作空间;
>> 工作空间内可以使用智能代理,例如搜索网页或运行代码等;
>> 文档支持多种格式(PDF、TXT、DOCX等),且可以从UI管理归档到向量数据库;
>> 聊天模式有对话模式和查询模式之分。两种聊天模式:对话和查询。对话保留先前的问题和修订。查询是针对您的文档的简单问答;
>> 引文支持让用户在聊天中引用文档;
>> 成本效率高,每个文档的归档和调用成本很低;
>> 开放API支持自定义集成;
>> 在聊天中引用;
>> 100%云部署就绪;
>> “自带LLM”模型;
>> 用于管理非常大的文档的极其高效的节省成本措施。您永远不会因为嵌入大型文档或文本比多次而付费。比其他文档聊天机器人解决方案节省90%的成本;
>> 全面的开发人员API,用于自定义集成!
2、技术原理概述
前端使用React开发用户界面,后端使用Node.js搭建服务和向量数据库交互,支持Docker部署。文档处理使用单独的Node服务。此单体存储库包含三个主要部分:
>> 前端:一个viteJS + React前端,您可以运行它来轻松创建和管理LLM可以使用的所有内容。
>> 服务器:一个NodeJS express服务器,用于处理所有交互并进行所有矢量数据库管理和LLM交互。
>> Docker:Docker说明和构建过程+从源代码构建的信息。
>> 收集器:处理和解析来自UI的文档的NodeJS express服务器。
3、支持的LLM、嵌入器、转录模型和矢量数据库
支持广泛的LLM、嵌入器、转录和向量数据库模型,例如Google、微软、OpenAI、HuggingFace等主流模型。
(1)、支持的LLM
- Any open-source llama.cpp compatible model
- OpenAI
- Azure OpenAI
- Anthropic
- Google Gemini Pro
- Hugging Face (chat models)
- Ollama (chat models)
- LM Studio (all models)
- LocalAi (all models)
- Together AI (chat models)
- Perplexity (chat models)
- OpenRouter (chat models)
- Mistral
- Groq
(2)、支持的嵌入模型
(3)、支持的转录模型
- AnythingLLM Built-in (default)
- OpenAI
(4)、支持的矢量数据库
4、部署方法:Docker、AWS、GCP、Digital Ocean、Render.com、Railway等
除支持Docker部署外,还提供多种自助托管方案,如云平台、Digital Ocean等,也支持本地自行搭建。Mintplex Labs和社区维护了许多部署方法、脚本和模板,您可以使用这些方法在本地运行AnythingLLM。请参考下表,了解如何在您喜欢的环境中部署,或者自动部署。
Docker:anything-llm/docker/HOW_TO_USE_DOCKER.md at master · Mintplex-Labs/anything-llm · GitHub
Digital Ocean:anything-llm/cloud-deployments/digitalocean/terraform/DEPLOY.md at master · Mintplex-Labs/anything-llm · GitHub
Render.com:https://render.com/deploy?repo=https://github.com/Mintplex-Labs/anything-llm&branch=render
Railway:Deploy AnythingLLM on Railway | Railway
5、如何进行开发设置
yarn setup 填写每个应用程序部分所需的.env文件(从存储库的根目录)。
填写完毕后再继续。确保server/.env.development已填写,否则可能会出现问题。
yarn dev:server 启动本地服务器(从存储库的根目录)。
yarn dev:frontend 启动本地前端(从存储库的根目录)。
yarn dev:collector 然后运行文档收集器(从存储库的根目录)。
AnythingLLM的安装和使用方法
1、安装
第1步,下载软件
下载地址:Download AnythingLLM for Desktop
下载地址:💻 AnythingLLM Desktop | AnythingLLM
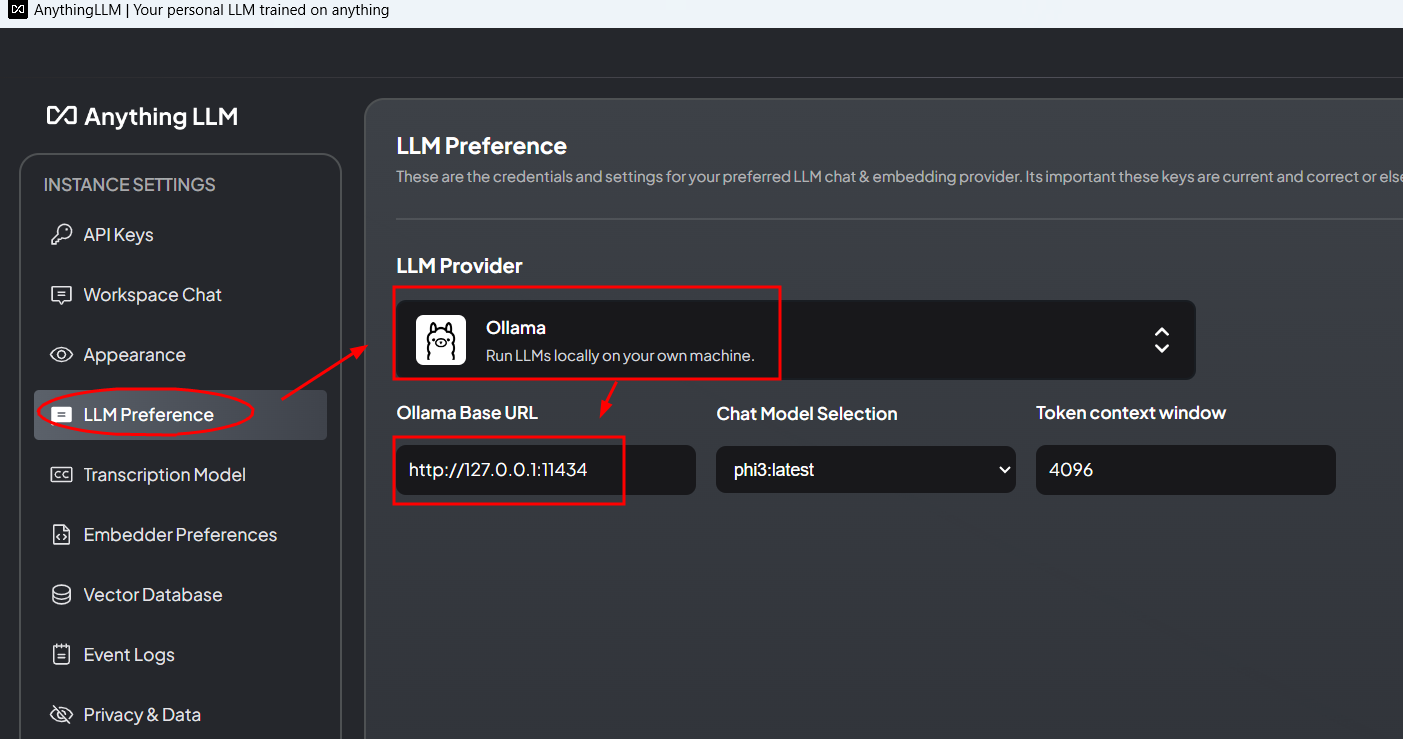
第2步,配置软件
URL参数:指定本地模型起服务的地址。可以简单理解为2个软件的对接接口,即AnythingLLM与Ollama的通讯地址。
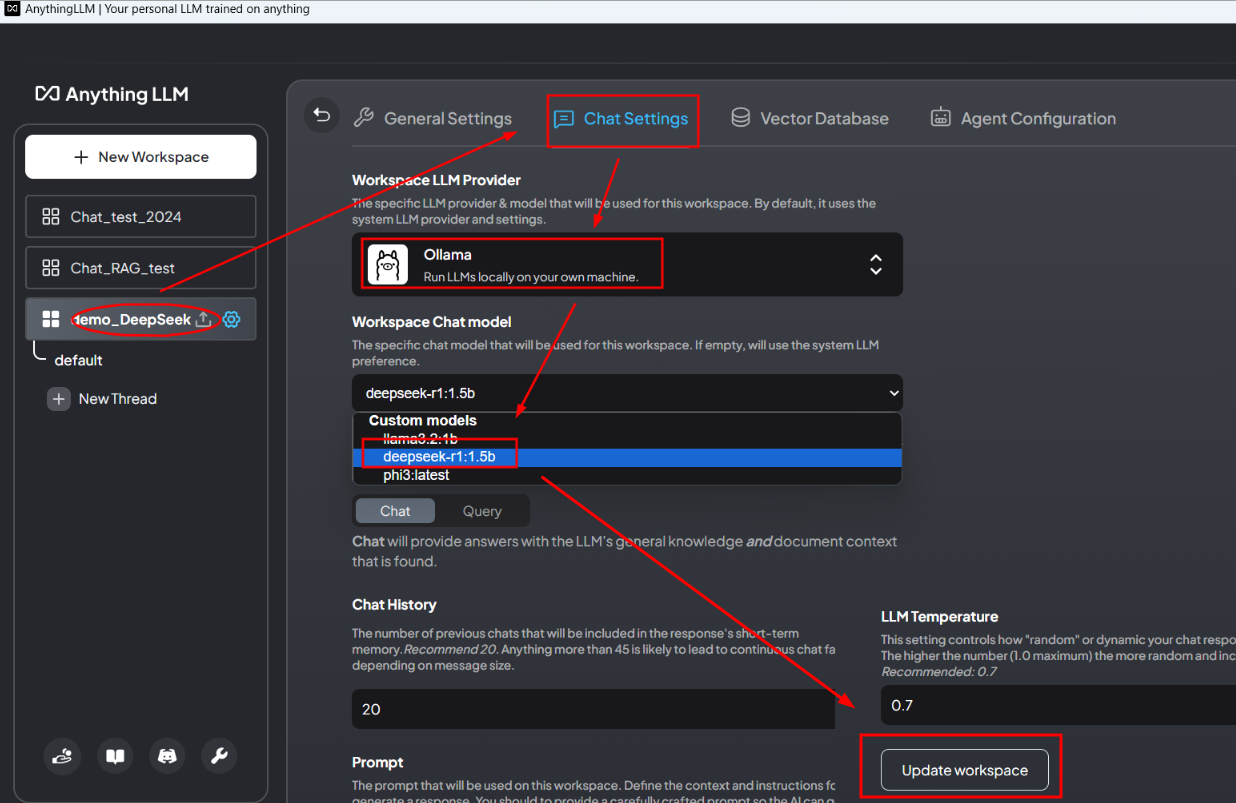
第3步,选择对话模型,以及各个模块的功能
| 模块名称 | 功能意义 |
| Chat History | 控制响应短时记忆中包含的前几次聊天的数量。推荐设置为20次,超过45次可能导致连续聊天失败。 |
| Prompt | 定义AI在此工作空间上使用的提示,用于指导AI生成响应。应提供精心设计的提示以确保AI能生成相关且准确的响应。 |
| Query mode refusal response | 当在查询模式下未找到任何上下文时,返回自定义拒绝响应。 |
| LLM Temperature | 控制聊天响应的随机性或动态性。数值越高(最高为1.0),响应越随机和不连贯。推荐设置为0.7。 |
2、使用方法
T1、新建工作区(workspace)并测试Chat功能

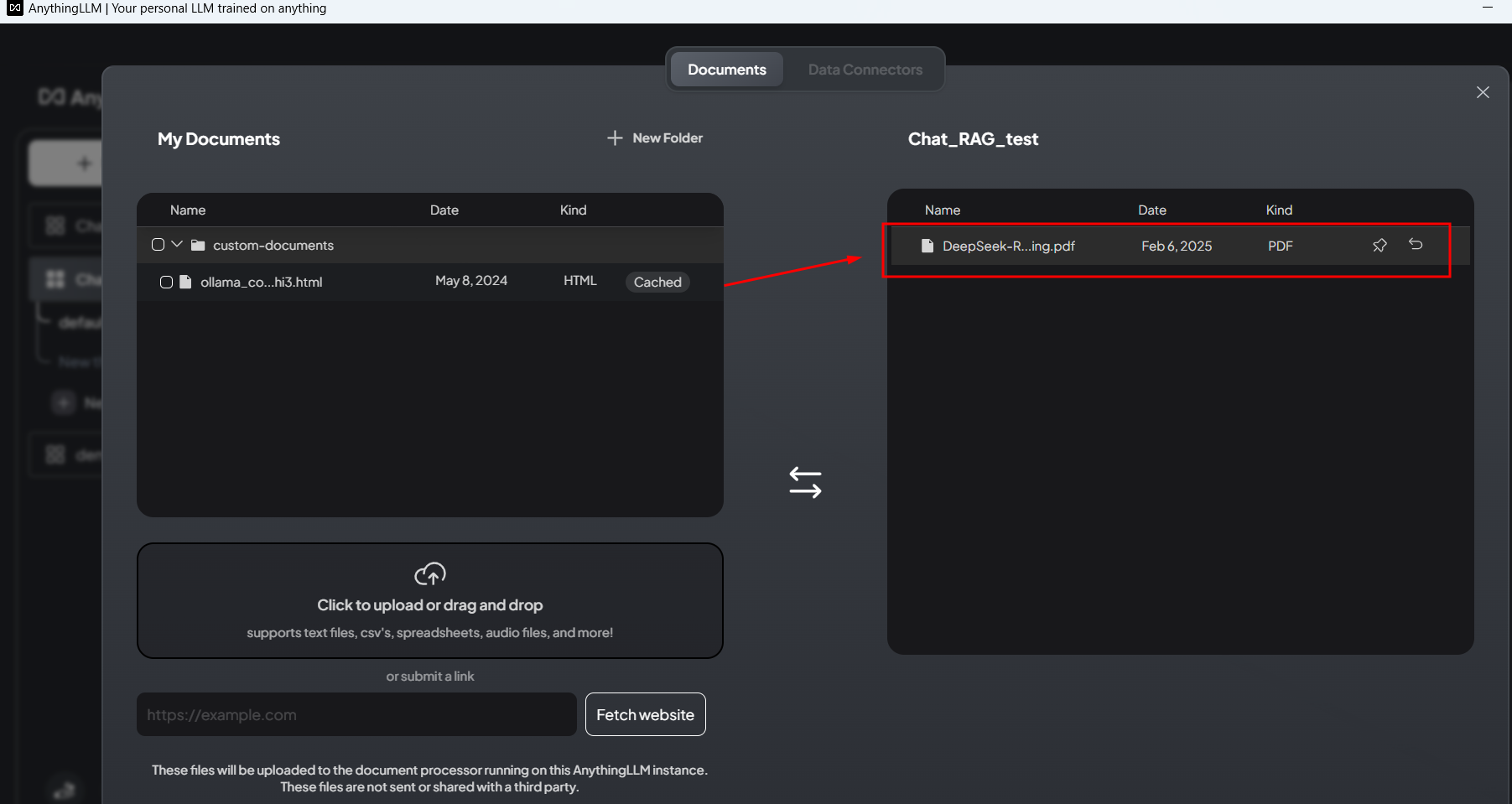
T2、新建工作区(workspace)并测试RAG功能:上传文档并在界面中实现对话查询
上传知识库并移至当前工作区
对话查询测试

3、进阶技巧
RAG应用中的优化技巧
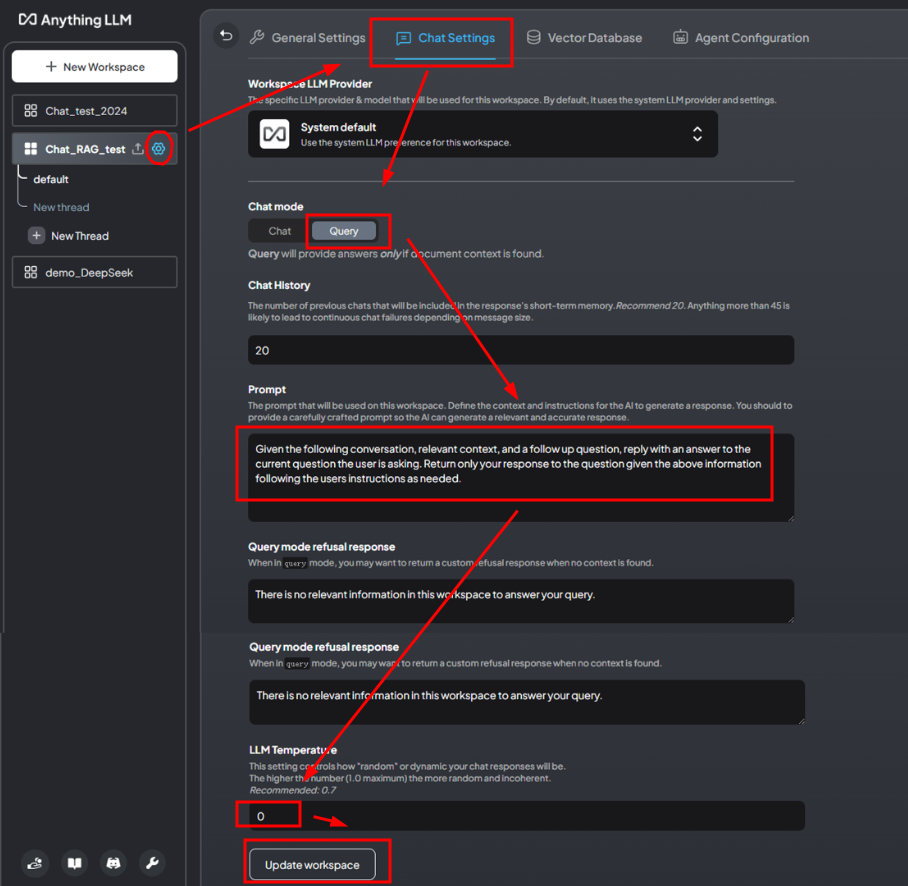
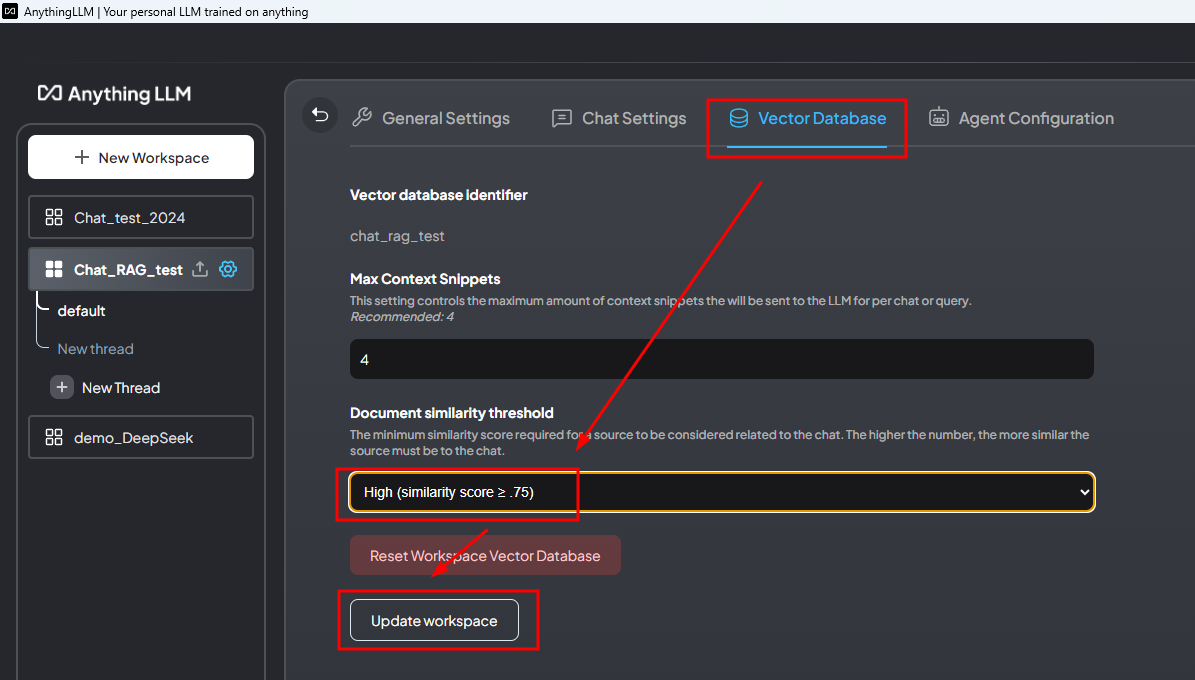
设置Chat Setting和Vector Database
- Chat模式(Chat/Query):Query 设置此参数为"Query"的原因是,这样模型仅在找到文档上下文时才提供答案。这意味着模型的回答将更加依赖于检索到的相关文档内容。这样做的好处是能够保证回答的准确性和相关性,避免在没有足够信息支持的情况下生成可能不准确或无关的回答。
- LLM温度(LLM Temperature) LLM(Large Language Model)温度参数的设置是为了控制聊天响应的"随机性"或动态性。设置该参数为0的原因是,这样可以使得模型的回答更加确定和一致。温度值越低,模型在生成回答时选择的单词或短语就越倾向于那些概率最高的,从而减少随机性和不连贯性。推荐的0值意味着模型将尽可能生成最可能的回答,而不是探索多样化的回答。
- 文档相似度阈值(Document similarity threshold) 设置文档相似度阈值是为了确定一个来源文档与聊天内容的相关性。较高的相似度分数(例如≥0.75)意味着只有与聊天内容非常相似的文档才会被考虑用于生成回答。这样做的原因是,可以确保模型在生成回答时使用的信息是高度相关的,从而提高回答的准确性和质量。通过设置较高的相似度阈值,可以过滤掉那些不太相关的文档,减少噪声,使得回答更加精准。
AnythingLLM的案例应用
持续更新中……



















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











