







LLMs之Qwen2:Qwen2的简介、安装和使用方法、案例应用之详细攻略
目录
T1、采用Hugging Face Transformers
6.1、硬件资源:微调Qwen2-72B-Instruct 至少需要6卡A100-80G
T2、采用8*910B-32GB 华为昇腾NPU+192G的CPU:采用Zero3技术,loss=1.18
6.2、微调方法或框架:Axolotl、Llama-Factory、Swift等
第一步,微调数据集,采用chatml格式(官方推荐,源自OpenAI):system-user-assistant
第二步,通过调用 finetune.sh 脚本来微调一个模型,支持使用 DeepSpeed 配置进行分布式训练,并可选择性地使用 LoRA 和量化 LoRA 技术来优化模型训练和推理的效率。
解读finetune.sh 文件代码,深度理解多卡训练的设置
T1、微调数据集,采用alpaca 格式: instruction-input-output-system-history
LLMs之FineTuning:LLaMA-Factory(高效统一100+语言模型的微调/通过一站式网页界面快速上手)的简介、安装和使用方法、案例应用(微调ChatGLM3等)之详细攻略
Qwen2的简介
2024年6月6日,发布Qwen2,Qwen2是从Qwen1.5进化而来,提供五种规模的预训练和指令微调模型(0.5B、1.5B、7B、57B-A14B和72B),支持多达27种语言,具有顶尖的基准测试性能,在编码和数学方面显著提升,并扩展了Qwen2-7B-Instruct和Qwen2-72B-Instruct模型的上下文长度至128K tokens,同时支持工具调用、RAG、角色扮演和AI Agent等功能。
经过数月的努力,我们很高兴地宣布从 Qwen1.5 进化到 Qwen2。这次,我们为您带来了:
>> 五种规模的预训练和指令微调模型,包括 Qwen2-0.5B、Qwen2-1.5B、Qwen2-7B、Qwen2-57B-A14B 和 Qwen2-72B;针对每种尺寸提供基础模型和指令微调模型,并确保指令微调模型按照人类偏好进行校准;
>> 基础模型和指令微调模型的多语言支持;除英语和中文外,还训练了27种额外语言的数据;
>> 在大量基准评估中表现优异,编码和数学性能显著提升;支持工具调用、RAG(检索增强文本生成)、角色扮演、AI Agent等;
>> 所有模型均稳定支持32K长度上下文;Qwen2-7B-Instruct与Qwen2-72B-Instruct可支持128K上下文(需额外配置)。Qwen2-7B-Instruct 和 Qwen2-72B-Instruct 支持最长 128K tokens 的上下文长度。
官网地址:Qwen
1、新闻
2024.06.06:我们发布了 Qwen2 系列。查看我们的博客!
2024.03.28:我们发布了 Qwen 的首个 MoE 模型:Qwen1.5-MoE-A2.7B!暂时只有 HF transformers 和 vLLM 支持该模型。我们将很快添加对 llama.cpp、mlx-lm 等的支持。查看我们的博客以获取更多信息!
2024.02.05:我们发布了 Qwen1.5 系列。
2、性能
更新中……
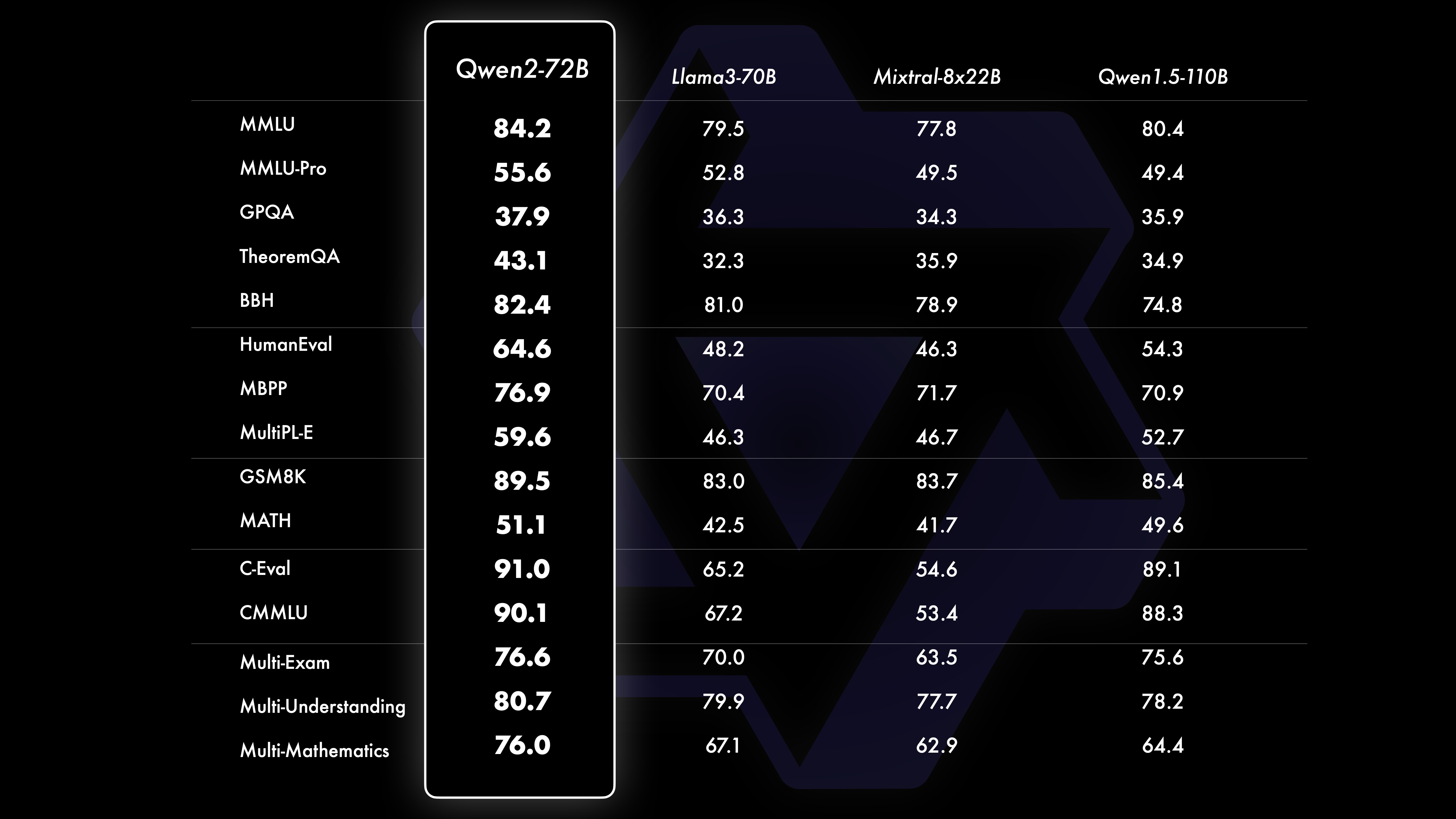
3、从脚本代码解读Qwen2模型架构
LLMs之Qwen2:Qwen2源码解读(qwen2_model.py)—实现了基于PyTorch的Qwen2大型语言模型—序列处理函数、模型基础类、基础构造模块、解码器层模块、完整模型结构、下游任务模型
https://yunyaniu.blog.csdn.net/article/details/144047788
Qwen2的安装和使用方法
1、安装
Qwen2 密集和 MoE 模型需要 transformers>=4.40.0。建议使用最新版本。
警告,这是必需的,因为 transformers 从 4.37.0 开始集成了 Qwen2 代码,从 4.40.0 开始集成了 Qwen2Moe 代码。
关于 GPU 内存要求和相应的吞吐量,见此处的结果。
2、模型使用方法
T1、采用Hugging Face Transformers
这里我们展示了一段代码片段,展示了如何使用 transformers 的聊天模型:
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen2-7B-Instruct"
device = "cuda" # the device to load the model onto
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]对于量化模型,我们建议使用 GPTQ 和 AWQ 对应的模型,即 Qwen2-7B-Instruct-GPTQ-Int8 和 Qwen2-7B-Instruct-AWQ。
T2、采用ModelScope
我们强烈建议用户,特别是中国大陆的用户,使用 ModelScope。snapshot_download 可以帮助您解决下载检查点的问题。
3、模型推理
3.1、本地运行
本地运行
T1、Ollama
警告,你需要 ollama>=0.1.42。
注意,Ollama 提供了一个与 OpenAI 兼容的 API,但不支持函数调用。对于工具使用功能,考虑使用 Qwen-Agent,它为 API 上的函数调用提供了一个包装器。
安装 ollama 后,可以用以下命令启动 ollama 服务:
ollama serve
# 在使用 ollama 时需要保持此服务运行要拉取模型检查点并运行模型,请使用 ollama run 命令。你可以通过在 qwen2 后添加后缀来指定模型大小,如 :0.5b、:1.5b、:7b 或 :72b:
ollama run qwen2:7b
# 要退出,请输入 "/bye" 并按回车你还可以通过其 OpenAI 兼容 API 访问 ollama 服务。请注意,您需要(1)在使用 API 时保持 ollama serve 运行,(2)在使用此 API 之前执行 ollama run qwen2:7b 以确保模型检查点已准备就绪。
from openai import OpenAI
client = OpenAI(
base_url='http://localhost:11434/v1/',
api_key='ollama', # required but ignored
)
chat_completion = client.chat.completions.create(
messages=[
{
'role': 'user',
'content': 'Say this is a test',
}
],
model='qwen2:7b',
)欲了解更多详情,请访问 ollama.ai。
T2、llama.cp
下载我们提供的 GGUF 文件或自行创建,然后可以直接使用最新的 llama.cpp 运行以下命令:
./main -m <path-to-file> -n 512 --color -i -cml -f prompts/chat-with-qwen.txt如果遇到 GPU 上量化模型的问题,请尝试传递 -fa 参数以在最新版本的 llama.cpp 中启用 flash attention 实现。
T3、MLX-LM
如果你在使用 Apple Silicon,我们也提供了兼容 mlx-lm 的检查点。在 HuggingFace Hub 上查找以 MLX 结尾的模型,如 Qwen2-7B-Instruct-MLX。
T4、LMStudio
Qwen2 已被 lmstudio.ai 支持。你可以直接使用 LMStudio 和我们的 GGUF 文件。
T5、OpenVINO
Qwen2 已被 OpenVINO 工具包支持。你可以安装并运行这个聊天机器人示例,使用 Intel CPU、集成 GPU 或独立 GPU。
3.2、Web UI
WEB UI
T1、文本生成 Web UI
你可以直接使用 text-generation-webui 创建一个 Web UI 演示。如果使用 GGUF,记得安装支持 Qwen2 的最新 llama.cpp 轮子。
T2、llamafile
克隆 llamafile,运行 source install,然后按照指南使用 GGUF 文件创建你自己的 llamafile。你可以运行一行命令,比如 ./qwen.llamafile,创建一个演示。
4、模型部署
部署
Qwen2 受多个推理框架支持。这里我们演示了 vLLM 和 SGLang 的使用。
警告,vLLM 和 SGLang 提供的 OpenAI 兼容 API 目前不支持函数调用。对于工具使用功能,Qwen-Agent 提供了一个围绕这些 API 的包装器,以支持函数调用。
T1、vLLM
我们建议使用 vLLM>=0.4.0 构建 OpenAI 兼容 API 服务。使用聊天模型启动服务器,例如 Qwen2-7B-Instruct:
python -m vllm.entrypoints.openai.api_server --served-model-name Qwen2-7B-Instruct --model Qwen/Qwen2-7B-Instruct然后按照下面的示例使用 chat API:
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Qwen2-7B-Instruct",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Tell me something about large language models."}
]
}'curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Qwen2-7B-Instruct",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Tell me something about large language models."}
]
}'
from openai import OpenAI
# Set OpenAI's API key and API base to use vLLM's API server.
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
chat_response = client.chat.completions.create(
model="Qwen2-7B-Instruct",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Tell me something about large language models."},
]
)
print("Chat response:", chat_response)T2、SGLang
注意,SGLang 目前不支持 Qwen2MoeForCausalLM 架构,因此 Qwen2-57B-A14B 不兼容。
请从源代码安装 SGLang。类似于 vLLM,你需要启动服务器并使用 OpenAI 兼容的 API 服务。首先启动服务器:
python -m sglang.launch_server --model-path Qwen/Qwen2-7B-Instruct --port 30000
你可以在 Python 中按如下所示使用它:
from sglang import function, system, user, assistant, gen, set_default_backend, RuntimeEndpoint
@function
def multi_turn_question(s, question_1, question_2):
s += system("You are a helpful assistant.")
s += user(question_1)
s += assistant(gen("answer_1", max_tokens=256))
s += user(question_2)
s += assistant(gen("answer_2", max_tokens=256))
set_default_backend(RuntimeEndpoint("http://localhost:30000"))
state = multi_turn_question.run(
question_1="What is the capital of China?",
question_2="List two local attractions.",
)
for m in state.messages():
print(m["role"], ":", m["content"])
print(state["answer_1"])5、Docker
为简化部署过程,我们提供了带有预构建环境的 Docker 镜像:qwenllm/qwen。你只需要安装驱动程序并下载模型文件,即可启动演示和微调模型。
docker run --gpus all --ipc=host --network=host --rm --name qwen2 -it qwenllm/qwen:2-cu121 bash6、模型微调—SFT阶段
6.1、硬件资源:微调Qwen2-72B-Instruct 至少需要6卡A100-80G
T1、采用8*A100-80G
LLMs之Qwen2:探讨多卡训练与单卡训练大模型的区别(硬件资源配置/代码改动)—多维度对比基于8卡A100-80G训练大模型(如Qwen2-72B-Instruct )、基于单卡A100-80G训练大模型(如Qwen2-7B-Instruct )
https://yunyaniu.blog.csdn.net/article/details/139667658
T2、采用8*910B-32GB 华为昇腾NPU+192G的CPU:采用Zero3技术,loss=1.18
有开发者使用了8*华为昇腾910B-32GB NPU+ Stage3技术训练Qwen2-72B,2K样例耗时80分钟左右,20K样本个数估计10个小时左右。

6.2、微调方法或框架:Axolotl、Llama-Factory、Swift等
我们建议使用包括 Axolotl、Llama-Factory、Swift 等训练框架,以使用 SFT、DPO、PPO 等进行模型微调。
训练
6.3、执行模型微调
T1、基于CLI的方式快速微调
第一步,微调数据集,采用chatml格式(官方推荐,源自OpenAI):system-user-assistant
数据集中的每个样本的两个示例。每个样本都是一个JSON对象,包含以下字段: type 、 messages 和 source 。其中, messages 是必填字段,而其他字段则是供您标记数据格式和数据来源的可选字段。 messages 字段是一个JSON对象列表,每个对象都包含两个字段: role 和 content 。其中, role 可以是 system 、 user 或 assistant ,表示消息的角色; content 则是消息的文本内容。而 source 字段代表了数据来源,可能包括 self-made 、 alpaca 、 open-hermes 或其他任意字符串。
{
"type": "chatml",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "Tell me something about large language models."
},
{
"role": "assistant",
"content": "Large language models are a type of language model that is trained on a large corpus of text data. They are capable of generating human-like text and are used in a variety of natural language processing tasks..."
}
],
"source": "unknown"
}第二步,通过调用 finetune.sh 脚本来微调一个模型,支持使用 DeepSpeed 配置进行分布式训练,并可选择性地使用 LoRA 和量化 LoRA 技术来优化模型训练和推理的效率。
针对不同类型的训练(例如单GPU训练、多GPU训练、全参数微调、LoRA或Q-LoRA),您可能需要不同的超参数设置。为您的模型指定 <model_path> ,为您的数据指定 <data_path> ,并为您的Deepspeed配置指定 <config_path> 。如果您使用LoRA或Q-LoRA,只需根据您的需求添加 --use_lora True 或 --q_lora True 。这是开始微调的最简单方式。如果您想更改更多超参数,您可以深入脚本并修改这些参数。
cd examples/sft
bash finetune.sh -m <model_path> -d <data_path> --deepspeed <config_path> [--use_lora True] [--q_lora True]解读finetune.sh 文件代码,深度理解多卡训练的设置
finetune.sh 这个脚本为例进行解释说明。要为分布式训练(或单GPU训练)设置环境变量,请指定以下变量: GPUS_PER_NODE 、 NNODES、NODE_RANK 、 MASTER_ADDR 和 MASTER_PORT 。不必过于担心这些变量,因为我们为您提供了默认设置。在命令行中,您可以通过传入参数 -m 和 -d 来分别指定模型路径和数据路径。您还可以通过传入参数 --deepspeed 来指定Deepspeed配置文件。我们为您提供针对ZeRO2和ZeRO3的两种配置文件,您可以根据需求选择其中之一。在大多数情况下,我们建议在多GPU训练中使用ZeRO3,但针对Q-LoRA,我们推荐使用ZeRO2。
有一系列需要调节的超参数。您可以向程序传递 --bf16 或 --fp16 参数来指定混合精度训练所采用的精度级别。此外,还有其他一些重要的超参数如下:
--GPUS_PER_NODE=4:设定每个计算节点中包含的GPU数量。例如,如果每个节点有4个GPU,则设置 GPUS_PER_NODE=4。
--NNODES=2: # 设定参与分布式训练的计算节点总数。如果有两个节点参与训练,则设置 NNODES=2。
--NODE_RANK=0 # 当前节点的排名(主节点为0).每个节点需要一个唯一的排名(编号)。第一个节点设置 NODE_RANK=0,第二个节点设置 NODE_RANK=1,以此类推。
# 用于指定分布式训练的主节点的地址和端口。所有节点将通过这个地址和端口进行通信。主节点通常是 NODE_RANK=0 的节点。确保所有节点在同一个训练任务中正确地进行同步和通信。
--MASTER_ADDR=<主节点IP地址> # 例如 192.168.1.1
--MASTER_PORT=12345 # 选择一个未被占用的端口号,例如 12345
--output_dir: 模型或适配器的输出路径。
--num_train_epochs: 训练周期的数量。
--gradient_accumulation_steps: 梯度累积步数。
--per_device_train_batch_size: 每个GPU的训练批量大小,总批量大小等于 per_device_train_batch_size * GPU数量 * gradient_accumulation_steps。
--learning_rate: 学习率。
--warmup_steps: 预热步数。
--lr_scheduler_type: 学习率调度器类型。
--weight_decay: 权重衰减值。
--adam_beta2: Adam优化器的beta2值。
--model_max_length: 最大序列长度。
--use_lora: 是否使用LoRA。添加 --q_lora 可以启用Q-LoRA。
--gradient_checkpointing: 是否使用梯度检查点。
T2、采用LLaMA-Factory高级训练库实现微调
第一步,设置微调数据集的格式:LLaMA-Factory 支持alpaca格式、sharegpt格式
T1、微调数据集,采用alpaca 格式: instruction-input-output-system-history
[
{
"instruction": "user instruction (required)",
"input": "user input (optional)",
"output": "model response (required)",
"system": "system prompt (optional)",
"history": [
["user instruction in the first round (optional)", "model response in the first round (optional)"],
["user instruction in the second round (optional)", "model response in the second round (optional)"]
]
}
]T2、微调数据集,采用sharegpt 格式:conversations{human【user instruction】-gpt【model response】}-system-tools
[
{
"conversations": [
{
"from": "human",
"value": "user instruction"
},
{
"from": "gpt",
"value": "model response"
}
],
"system": "system prompt (optional)",
"tools": "tool description (optional)"
}
]第二步,打开界面执行微调
LLMs之FineTuning:LLaMA-Factory(高效统一100+语言模型的微调/通过一站式网页界面快速上手)的简介、安装和使用方法、案例应用(微调ChatGLM3等)之详细攻略
https://yunyaniu.blog.csdn.net/article/details/134098674
7、模型微调—RLHF阶段
持续更新中……
Qwen2的案例应用
持续更新中……
1、基于langchain框架实现调用工具能力
LLMs之Qwen-2:基于langchain框架采用Qwen2模型实现工具调用功能(解决复杂的数学计算问题)——定义LLMs(qwen)→将计算器工具绑定到LLMs上→LLMs基于用户输入数学计算问题***参数→基于LLM的响应文本+系统通过if判断触发并执行工具运行动作并输出计算结果→将输出结果并结合用户query返回给LLM生成最终答案
https://yunyaniu.blog.csdn.net/article/details/139758101



















 24万+
24万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











