







LLMs之GLM:《ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools》翻译与解读
导读:
背景痛点:
>> 大型语言模型(LLM)在过去几年取得了长足进展,如GPT-3、GPT-4等,但仍有进一步提升的空间。
>> 当前的大型语言模型(LLM)在多语言对齐和长上下文任务中存在不足。特别是处理复杂任务时,现有的模型在工具的调用和用户意图理解上表现不尽如人意。
>> 如何训练更强大、性能更优的LLM,并对齐人类意图,成为当前研究的重点。
解决方案:ChatGLM家族模型,包括GLM-4、GLM-4-Air和GLM-4-9B,经过多阶段后训练,使用了超过十万亿个tokens的数据进行预训练,并且在中英文对齐上表现优异。
>> 提出了ChatGLM系列大型语言模型家族,包括GLM-130B、GLM-4、GLM-4 All Tools等。
>> 采用了多种创新技术,包括新的模型架构、优化的预训练数据、指令微调(SFT)、强化学习(RLHF)等对齐策略。
核心思路步骤:多阶段后训练,包括监督微调和人类反馈学习。开放多种工具的自动调用能力,如浏览器、Python解释器和文本到图像模型。
>> 构建大规模高质量的预训练语料库(约10万亿词符),涵盖多语种内容。
>> 探索高效的模型架构,如GQA注意力、无偏置设计、RoPE位置编码等。
>> 采用指令微调(SFT)和强化学习(RLHF)等技术对齐模型输出与人类偏好。
>> 提出LongAlign等方法支持长文本处理,上下文长度达128K或1M词符。
>> GLM-4 All Tools通过整合网页浏览器、代码解释器等外部工具,提升任务完成能力。
优势:在实际应用中,尤其是在调用工具完成复杂任务时,表现优于GPT-4 All Tools。
>> GLM-4在常见英文基准测试(MMLU、GSM8K等)上与GPT-4性能相当。
>> 在中文指令理解和对齐度上超过GPT-4。
>> 支持长文本处理,在LongBench测试中媲美GPT-4 Turbo和Claude。
>> GLM-4 All Tools的智能工具调用能力超越GPT-4 All Tools。
>> 陆续开源多个模型版本,在Hugging Face上累计下载量超1000万次。
总的来说,该论文系统介绍了ChatGLM这一大型语言模型家族的发展历程、关键技术创新、性能评估等,展现了其在通用语言理解、长文本处理、工具调用等方面的领先水平。
目录
LLMs之GLM-130B/ChatGLM-1:《GLM-130B: AN OPEN BILINGUAL PRE-TRAINED MODEL》翻译与解读
LLMs之ChatGLM-2:ChatGLM2-6B的简介、安装、使用方法之详细攻略
LLMs之ChatGLM-3:ChatGLM3/ChatGLM3-6B的简介(多阶段增强+多模态理解+AgentTuning技术)、安装、使用方法之详细攻略
LLMs之GLM-4:GLM-4的简介(全覆盖【对话版即ChatGLM4的+工具调用+多模态文生图】能力→Agent)、安装和使用方法、案例应用之详细攻略
MLM之GLM-4:GLM-4-9B的简介、安装和使用方法、案例应用之详细攻略
LLMs之ChatGLM:ChatGLM系列模型(ChatGLM-1/ChatGLM-2/ChatGLM-3/ChatGLM-4)网络架构详解及其对比
LLMs之GLM:《ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools》翻译与解读
《ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools》翻译与解读
基座诞生—2021年,受GPT-3启发提出GLM,并开源GLM-10B→2021年底GLM-130B,以匹敌GPT-3 175B、OPT-175B和BLOOM-176B
V3系列—2023年10月27日,开源ChatGLM3-6B:更多样化的训练数据集+更充分的训练步骤+更优化的训练策略=验证了缩放定律,开始支持函数调用能力/代码解释器能力
V4系列—2024年1月16日,发布GLM-4以及GLM-4 All Tools(支持创建个人Agent):多阶段的后期训练(SFT+RLHF+安全对齐)+更长上下文(128K)
Figure 2: An Illustrative Example of GLM-4 All Tools.
GLM-4:四大能力可匹敌GPT-4(通用能力+指令跟随能力+长上下文能力+智能体能力)
GLM-4 All Tools(更好的对齐+自主选择最合适的工具):多轮方式访问网页能力+利用Python解释器解决数学问题能力+生成图像能力+调用自定义函数能力
Table 1: Performance of Open ChatGLM-6B, ChatGLM2-6B, ChatGLM3-6B, and GLM-4-9B.
数据源(网页+维基百科+书籍+代码+论文)、数据处理管道(去重+过滤+分词,语料库10T的tokens)、策略(采用BPE分词训练得到150K词表+数据源加权训练)
经验:数据质量和多样性至关重要,但截止目前尚未找到数据预处理的一套基本流程原则
GLM-130B架构策略:DeepNorm+RoPE+带有GeLU的GLU
整体趋势:更长的上下文(2K→32K→32K→128K/1M)及其策略(位置编码扩展+对长文本的持续训练+长上下文对齐)
预训练(奠定基础能力)→后训练(完善衍生能力,遵循指令对齐人类意图+促进多轮对话)
GLM-4:对齐能力来自SFT(真实的人类提示和互动更重要)+RLHF(进一步帮助缓解响应拒绝、安全、生成双语、多轮连贯性等)
ChatGLM-1:prompt-response,从模型开发者标注→严格的质量控制(安全性/真实性/相关性/帮助性/人类偏好)
涌现能力(较低预训练损失的模型所具有的能力)、LongAlign能力(采用长上下文对齐的综合配方)、Math能力(采用自我批评)
Benchmarks(AgentBench/LongBench/AlignBench/HumanEval/NaturalCodeBench)
2.5、GLM-4 All Tools(进一步支持智能智能体和相关任务)
原理:自主理解用户意图→规划复杂的指令→顺序调用一个或多个工具(例如支持嵌入式Python解释器、Web浏览器、文本到图像模型)→完成复杂的任务(如支持用户定义的函数、API和外部知识库)
Figure 4: The overall pipeline of GLM-4 All Tools and customized GLMs (agents).
考察能力:学术基准的基础能力、代码能力、智能体能力、指令遵循能力、长上下文能力、中文对齐能力
结果对比:GLM-4在标准基准测试方面接近最先进的模型(GPT-4-Turbo, Gemini 1.5 Pro和Claude 3 Opus),中文更出色!
3.1 Evaluation of Academic Benchmarks学术基准评估—MMLU/GSM8K/BBH/GPQA/HumanEva:涵盖知识、数学、推理、常识和代码
Table 2: GLM-4 performance on academic benchmarks.
3.2 Evaluation of Instruction Following指令跟随评估(指令跟随方面的熟练度)—针对IFEval
3.3 Evaluation of Alignment对齐评估—针对AlignBench+利用LLMs-as-Judge方法:中文逻辑推理问题更强+数学问题采用了自我批评策略
Table 5: GLM-4 performance on LongBench-Chat [2].
3.5 Evaluation of Coding on Real-world User Prompts对真实用户提示编码的评估
HumanEval基准:偏向入门级算法+训练数据疑被污染→结评估果相对不可信
NCB基准:表现接近Claude 3 Opus但仍差于GPT-4
Table 7: GLM performance on the Berkeley Function Call Leaderboard.
3.7 Evaluation of Agent Abilities智能体能力评估—AgentBench:LLMs是智能体系统中的智能体(LLMs-as-Agents),对比GLM-4各有千秋
Table 8: GLM-4 performance on AgentBench [23].
3.8 Evaluation of All Tools所有工具评估:实现复杂任务(自主理解意图+规划+调用多个工具)
Table 9: Performance of GLM-4 All Tools.
两个阶段缓解:训练阶段(仔细清理数据=去除包含敏感关键词的文本和来自预定义黑名单的网页)、对齐阶段(评估每个训练样本的安全性→无害性)
采用红队策略:收集有害问答对+人工标注加以改进→进一步对齐模型
GLM模型系列
LLMs之GLM-130B/ChatGLM-1:《GLM-130B: AN OPEN BILINGUAL PRE-TRAINED MODEL》翻译与解读
LLMs之GLM-130B/ChatGLM:《GLM-130B: AN OPEN BILINGUAL PRE-TRAINED MODEL》翻译与解读-CSDN博客
LLMs之ChatGLM-2:ChatGLM2-6B的简介、安装、使用方法之详细攻略
LLMs之ChatGLM2:ChatGLM2-6B的简介、安装、使用方法之详细攻略_一个处女座的程序猿的博客-CSDN博客
LLMs之ChatGLM-3:ChatGLM3/ChatGLM3-6B的简介(多阶段增强+多模态理解+AgentTuning技术)、安装、使用方法之详细攻略
LLMs之ChatGLM3:ChatGLM3/ChatGLM3-6B的简介(多阶段增强+多模态理解+AgentTuning技术)、安装、使用方法之详细攻略-CSDN博客
LLMs之GLM-4:GLM-4的简介(全覆盖【对话版即ChatGLM4的+工具调用+多模态文生图】能力→Agent)、安装和使用方法、案例应用之详细攻略
LLMs之GLM-4:GLM-4的简介(全覆盖【对话版即ChatGLM4的+工具调用+多模态文生图】能力→Agent)、安装和使用方法、案例应用之详细攻略-CSDN博客
MLM之GLM-4:GLM-4-9B的简介、安装和使用方法、案例应用之详细攻略
MLM之GLM-4:GLM-4-9B的简介、安装和使用方法、案例应用之详细攻略-CSDN博客
阶段性综合对比
LLMs之ChatGLM:ChatGLM系列模型(ChatGLM-1/ChatGLM-2/ChatGLM-3/ChatGLM-4)网络架构详解及其对比
https://yunyaniu.blog.csdn.net/article/details/139816980
LLMs之GLM:《ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools》翻译与解读
LLMs之GLM:《ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools》翻译与解读-CSDN博客
《ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools》翻译与解读
| 地址 | |
| 时间 | 2024 年6月18日 |
| 作者 | Zhipu AI,Tsinghua University |
Abstract
| We introduce ChatGLM, an evolving family of large language models that we have been developing over time. This report primarily focuses on the GLM-4 language series, which includes GLM-4, GLM-4-Air, and GLM-4-9B. They represent our most capable models that are trained with all the insights and lessons gained from the preceding three generations of ChatGLM. To date, the GLM-4 models are pre-trained on ten trillions of tokens mostly in Chinese and English, along with a small set of corpus from 24 languages, and aligned primarily for Chinese and English usage. The high-quality alignment is achieved via a multi-stage post-training process, which involves supervised fine-tuning and learning from human feedback. Evaluations show that GLM-4 1) closely rivals or outperforms GPT-4 in terms of general metrics such as MMLU, GSM8K, MATH, BBH, GPQA, and HumanEval, 2) gets close to GPT-4-Turbo in instruction following as measured by IFEval, 3) matches GPT-4 Turbo (128K) and Claude 3 for long context tasks, and 4) outperforms GPT-4 in Chinese alignments as measured by AlignBench. The GLM- 4 All Tools model is further aligned to understand user intent and autonomously decide when and which tool(s) to use—including web browser, Python interpreter, text-to-image model, and user-defined functions—to effectively complete complex tasks. In practical applications, it matches and even surpasses GPT-4 All Tools in tasks like accessing online information via web browsing and solving math problems using Python interpreter. Over the course, we have open-sourced a series of models, including ChatGLM-6B (three generations), GLM-4-9B (128K, 1M), GLM-4V-9B, WebGLM, and CodeGeeX, attracting over 10 million downloads on Hugging face in the year 2023 alone. The open models can be accessed through https://github.com/THUDM and https://huggingface.co/THUDM. | 我们介绍ChatGLM,这是一个不断发展的大型语言模型家族,我们一直在开发它。本报告主要关注GLM-4语言系列,包括GLM-4、GLM-4-Air和GLM-4- 9b。这些模型代表了我们迄今为止最强大的模型,经过了从前三代ChatGLM中获得的所有见解和经验教训的训练。 到目前为止,GLM-4模型主要在中英文语料上进行预训练,总计约10万亿(10T)个tokens,同时包含24种语言的小规模语料,并主要针对中英文使用进行了调整。通过多阶段后期训练过程,包括监督微调和人类反馈学习,实现了高质量的对齐。 评估表明,GLM-4 1)、GLM-4在一般指标(如MMLU、GSM8K、MATH、BBH、GPQA和HumanEval)方面接近或优于GPT-4; 2)、在指令跟随方面接近GPT-4-Turbo(通过IFEval评估), 3)、在长上下文任务方面与GPT-4 Turbo (128K)和Claude 3相匹配, 4)、在中文对齐方面优于GPT-4(通过AlignBench评估)。 GLM-4 All Tools模型进一步对齐以理解用户意图,并自主决定何时以及使用哪种工具(如web浏览器、Python解释器、文本到图像模型和用户定义的功能)以有效完成复杂任务。在实际应用中,它在访问在线信息(通过网页浏览)和解决数学问题(使用Python解释器)等任务上与GPT-4 All Tools匹敌甚至超越。 迄今为止,我们已经开源了一系列模型,包括ChatGLM-6B(三代版本)、GLM-4-9B(128K,1M)、GLM-4V-9B、WebGLM和CodeGeeX,在2023年吸引了超过1000万次下载。开源模型可以通过https://github.com/THUDM和https://huggingface.co/THUDM访问。 |
Figure 1: The timeline of the GLM family of language, code, vision, and agent models. The focus of this report is primarily on the language models, i.e., ChatGLM. The APIs are publicly available at https://bigmodel.cn and open models can be access线。本报告主要关注语言模型,即ChatGLM。API在https://bigmodel.cn公开提供,开源模型可以通过https://github.com/THUDM访问。
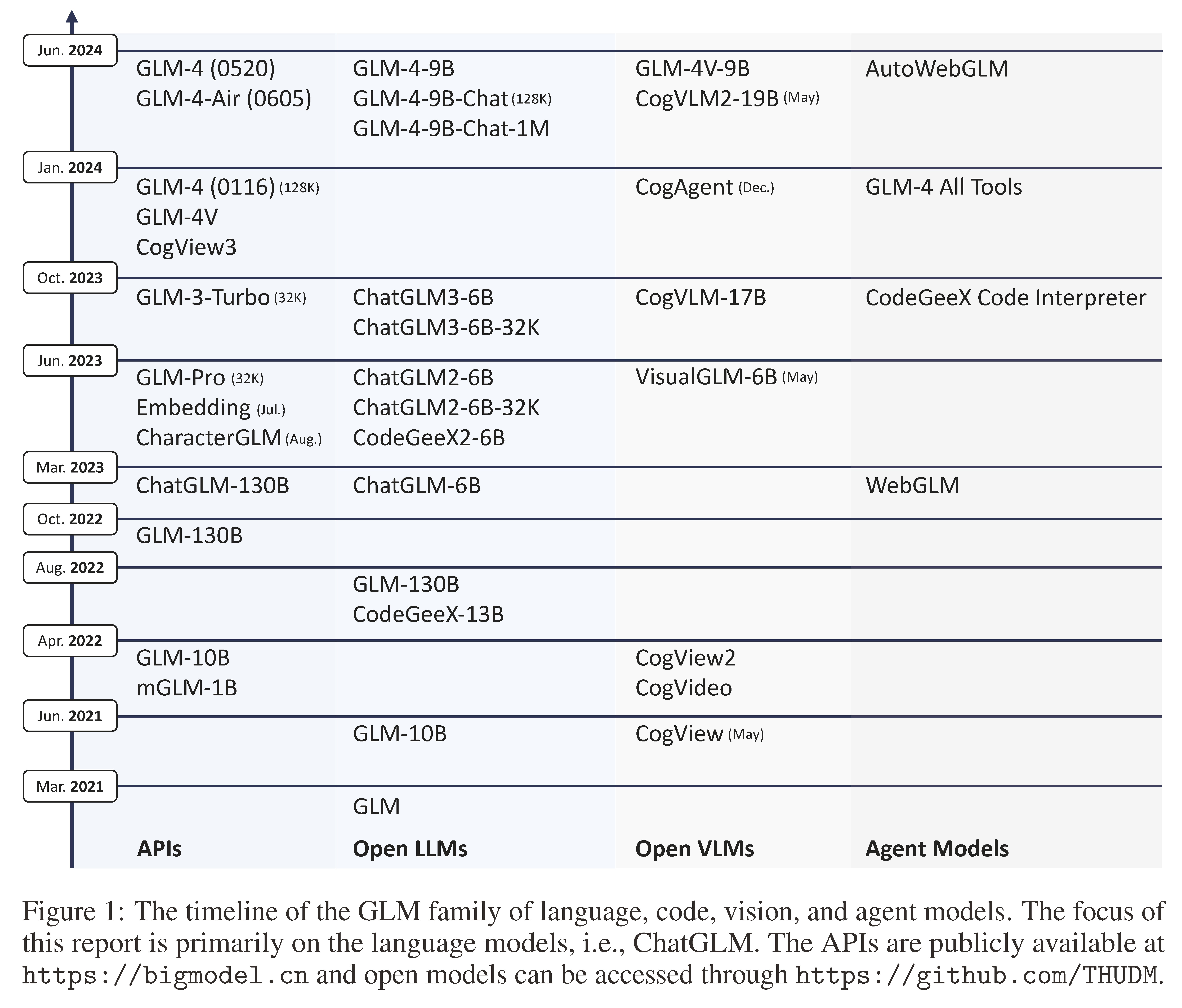
1 Introduction引言
基座诞生—2021年,受GPT-3启发提出GLM,并开源GLM-10B→2021年底GLM-130B,以匹敌GPT-3 175B、OPT-175B和BLOOM-176B
| ChatGPT has been phenomenal, whose capabilities was initially powered by the GPT-3.5 model [25] in November 2022 and subsequently upgraded to GPT-4 [27] in March 2023. According to OpenAI, the GPT-3.5 series improved upon GPT-3 by incorporating instruction tuning, supervised fine tuning (SFT), and/or reinforcement learning from human feedback (RLHF) [28]. The original GPT-3 released in 2020 [3] marked a significant scale-up from GPT-1’s 117 million parameters and GPT-2’s 1.5 billion parameters, to 175 billion parameters. This scale-up enables GPT-3 with in-context learning and generalized capabilities, spurring the emergence of large language models (LLMs) [6; 41]. Inspired by GPT-3, we proposed the General Language Model (GLM) architecture [11] featured with the autoregressive blank infilling objective and open-sourced the GLM-10B model in 2021 (See the GLM timeline in Figure 1). Starting in late 2021, we began pre-training GLM-130B [54]. The goal was to train a 100B-scale model to match or surpass GPT-3 (davinci) while also verifying the techniques for successfully training models at this scale, along with other efforts such as OPT- 175B [55] and BLOOM-176B [32]. We completed the 400B-token training and evaluation of GLM-130B in July, and subsequently released the model and pre-training details [54] in August 2022. According to HELM in November 2022, GLM-130B matches GPT-3 (davinci) across various dimensions [19]. | ChatGPT非常出色,其功能最初由GPT-3.5模型[25]于2022年11月提供支持,随后于2023年3月升级为GPT-4[27]。根据OpenAI的说法,GPT-3.5系列通过引入指令微调、监督微调(SFT)和/或人类反馈的强化学习(RLHF)改进了GPT-3。最初于2020年发布的GPT-3显著扩展了GPT-1的1.17亿参数和GPT-2的15亿参数,达到1750亿参数。这种扩展使得GPT-3具备了上下文学习和广泛的能力,促进了大型语言模型(LLM)的出现。 受GPT-3启发,我们提出了通用语言模型(GLM)架构,以自回归填空为目标,并在2021年开源了GLM-10B模型(见图1中的GLM时间线)。从2021年底开始,我们开始预训练GLM-130B。目标是训练一个100B级的模型以匹敌或超越GPT-3(davinci),同时验证成功训练此规模模型的技术,以及其他努力如OPT-175B和BLOOM-176B。我们在7月完成了GLM-130B的400B标记的训练和评估,并在2022年8月发布了模型和预训练细节。根据2022年11月的HELM,GLM-130B在各个维度上匹敌GPT-3(davinci)。 |
V1系列—2023年3月14日,发布ChatGLM-130B并开源ChatGLM-6B(快迭+消费级显卡):基于GLM-130B基座+prompt-response数据(1T的token)+SFT指令微调技术(2K)+RLHF技术
| Following this, we initiated instruction tuning on GLM-130B. Later, ChatGPT further motivated us to align the base models with SFT and RLHF. We created and crafted the prompt-response pairs from scratch and performed SFT, while also starting to examine how to effectively apply RLHF. On March 14, 2023, the aligned model, ChatGLM-130B, went live on https://chatglm.cn. In addition, a smaller version, ChatGLM-6B [13], was open-sourced at the same day, attracting significantly more attention than anticipated. It was designed to have 6.2 billion parameters for 1) facilitating fast iteration of pre-and post-training techniques as well as data selection, and 2) enabling local deployment on consumer-grade graphics cards using INT4 quantization. Since then, we have been rapidly exploring and refining our pre-training and alignment techniques, leading to the second and third generations of ChatGLM series every other three months, both of which were pre-trained entirely from the beginning. ChatGLM-6B was pre-trained on approximately one trillion tokens of Chinese and English corpus with a context length of 2,048 (2K), supplemented mostly by SFT. | 随后,我们开始对GLM-130B进行指令微调。之后,ChatGPT进一步激励我们将基本模型与SFT和RLHF结合起来。我们从头开始创建并编写prompt-response对,并进行了SFT,同时也开始研究如何有效地应用RLHF。 2023年3月14日,经过对齐的模型ChatGLM-130B在https://chatglm.cn上上线。此外,一个较小的版本ChatGLM-6B[13]也在同一天开源,吸引了比预期更多的关注。它被设计为具有62亿个参数,用于 1)、促进预训练和后训练技术以及数据选择的快速迭代; 2)、通过INT4量化在消费者级显卡上实现本地部署。 从那时起,我们一直在快速探索和完善我们的预训练和对齐技术,每隔三个月推出第二代和第三代ChatGLM系列,这些模型均从头开始进行完全预训练的。 ChatGLM-6B在大约1万亿个中英文语料库上进行了预训练,具有2048(2K)上下文长度,主要通过SFT补充。 |
V2系列—2023年6月,开源ChatGLM2-6B以及CodeGeeX2-6B(额外0.6T的代码预训练):采用更多更好的数据+FlashAttention技术(上下文扩展到32K)+MQA技术(提高推理速度)
| Released in June, ChatGLM2-6B was pre-trained and aligned with more and better data, leading to substantial improvements over its predecessor, including a 23% improvement on MMLU, 571% on GSM8K, and 60% on BBH. By adopting the FlashAttention technique [8], its context length was extended to 32K. Additionally, the integration of Multi-Query Attention [34] contributed to a 42% increase in inference speed. Taking this further, our 2nd generation code model CodeGeeX2-6B was developed by pre-training on an additional 600 billion code tokens. It demonstrates Pass@1 improvements over the initial generation, CodeGeeX-13B [58], with increases of 57% in Python, 71% in C++, 54% in Java, 83% in JavaScript, and 56% in Go as measured by HumanEval-X. | ChatGLM2-6B于6月发布,经过预训练并与更多更好的数据保持一致,比其前身有了显著性的改进,包括MMLU提高23%,GSM8K提高571%,BBH提高60%。通过采用FlashAttention技术[8],将其上下文长度扩展到32K。此外,Multi-Query Attention的集成[34]使推理速度提高了42%。 更进一步,我们的第二代代码模型CodeGeeX2-6B是通过对额外的6000亿个代码tokens进行预训练而开发的。在HumanEval-X上,相比初代CodeGeeX-13B,Pass@1在Python、C++、Java、JavaScript和Go上分别提升了57%、71%、54%、83%和56%。 |
V3系列—2023年10月27日,开源ChatGLM3-6B:更多样化的训练数据集+更充分的训练步骤+更优化的训练策略=验证了缩放定律,开始支持函数调用能力/代码解释器能力
| By further realizing more diverse training datasets, more sufficient training steps, and more optimized training strategies, ChatGLM3-6B topped 42 benchmarks across semantics, mathematics, reasoning, code, and knowledge. Starting from this generation, ChatGLM also supports function call and code interpreter, as well as complex agent tasks [9; 36; 51]. In the course of these developments, we also developed models with 1.5B, 3B, 12B, 32B, 66B, and 130B parameters, allowing us to validate our observations and establish our own scaling laws. | 通过进一步实现更多样化的训练数据集、更充分的训练步骤和更优化的训练策略,ChatGLM3-6B在语义、数学、推理、代码和知识方面达到了42项基准。从这一代开始,ChatGLM开始支持函数调用和代码解释器,以及复杂的智能体任务[9;36个;51]。在这些发展过程中,我们还开发了具有1.5B, 3B, 12B, 32B, 66B和130B参数的模型,使我们能够验证我们的观察结果并建立我们自己的缩放定律。 |
V4系列—2024年1月16日,发布GLM-4以及GLM-4 All Tools(支持创建个人Agent):多阶段的后期训练(SFT+RLHF+安全对齐)+更长上下文(128K)
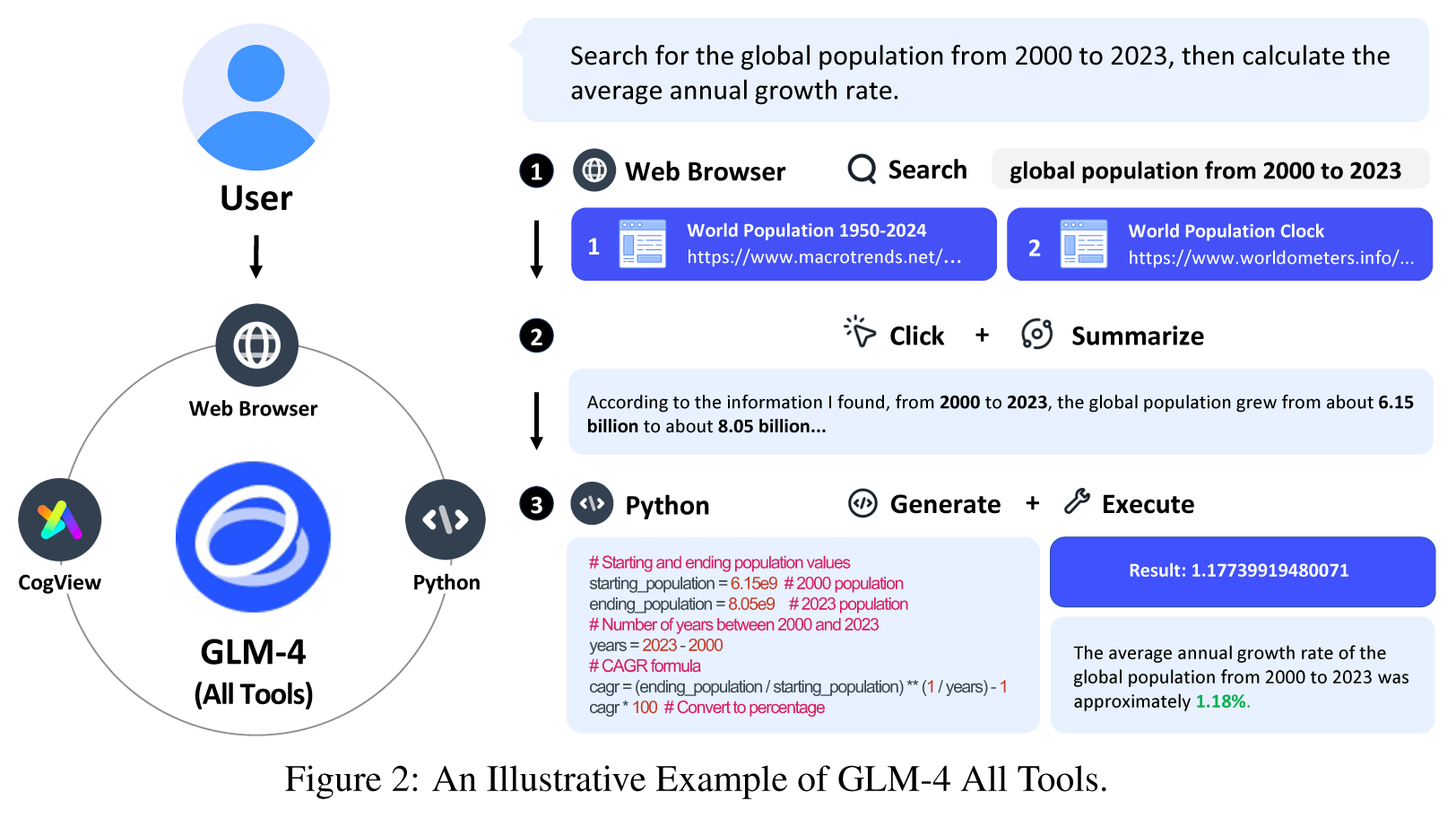
Figure 2: An Illustrative Example of GLM-4 All Tools.
GLM-4:四大能力可匹敌GPT-4(通用能力+指令跟随能力+长上下文能力+智能体能力)
| With all the lessons learned and experiences accumulated, we kicked off the training of GLM-4. The first cutoff checkpoint then underwent a multi-stage post-training process (e.g., SFT, RLHF, safety alignment) with a focus on the Chinese and English language for now. Subsequently, it was developed into two distinct versions: GLM-4 and GLM-4 All Tools, both supporting a 128K context length. | 有了所有的经验教训和积累,我们开始了GLM-4的训练。第一个中断检查点然后经过多阶段的后期训练过程(如SFT、RLHF、安全对齐),目前重点关注中英文。随后,它被开发成两个不同的版本:GLM-4和GLM-4 All Tools,两者都支持128K上下文长度。 |
| Since Jan. 16, 2024, GLM-4 (0116) has been made available through the GLM-4 API at https://bigmodel.cn, and GLM-4 All Tools is accessible via the website https://chatglm.cn and mobile applications that support the creation of one’s own agent—GLMs. The latest models are GLM-4 (0520) and GLM-4-Air (0605) with an upgrade on both pre-training and alignment. GLM-4-Air achieves comparable performance to GLM-4 (0116) with lower latency and inference cost. Evaluations of GLM-4 were performed on a variety of language benchmarks. These evaluations assess GLM-4’s general abilities in English, instruction following in both English and Chinese, and alignment, long-context, and agent capacities in Chinese. First, on the most commonly-used English academic benchmarks—MMLU, GSM8K, MATH, BBH, GPQA, and HumanEval, GLM-4 0520 achieves performance closely comparable to that of GPT-4 0613 [27] and Gemini 1.5 Pro [40]. For example, it scores 83.3 vs. 86.4 and 83.7 on MMLU, respectively. Second, according to IFEval [61], GLM-4’s instruction following capacities on both prompt and instruction levels are approximately as effective as GPT-4-Turbo in both English and Chinese. Third, in terms of Chinese language alignment, GLM-4 outperforms GPT-4 and matches GPT-4-Turbo across eight dimensions in AlignBench [21]. Finally, for long-context tasks, the GLM-4 (128K) model matches the performance level of GPT-4 Turbo and Claude 3 Opus as measured by LongBench-Chat [1], i.e., 87.3 vs. 87.2 and 87.7, respectively. | 自2024年1月16日起,GLM-4(0116)通过https://bigmodel.cn的GLM-4 API提供,GLM-4 All Tools通过https://chatglm.cn网站和支持创建自己智能体的移动应用程序。最新模型是GLM-4(0520)和GLM-4-Air(0605),在预训练和对齐上都有升级。GLM-4-Air在延迟和推理成本更低的情况下实现了与GLM-4(0116)相当的性能。GLM-4的评估在各种语言基准上进行。这些评估评估了GLM-4在英语方面的通用能力、英文和中文指令跟随能力以及中文的对齐、长上下文和智能体能力。 首先,在最常用的英文学术基准(MMLU、GSM8K、MATH、BBH、GPQA和HumanEval)上,GLM-4 0520的性能接近GPT-4 0613和Gemini 1.5 Pro。例如,它在MMLU上分别得分83.3、86.4和83.7。 其次,根据IFEval,GLM-4在提示和指令层面的指令跟随能力在中英文方面大致与GPT-4-Turbo相当。 第三,在中文语言对齐方面,GLM-4优于GPT-4,并在AlignBench的八个维度上匹敌GPT-4-Turbo。 最后,在长上下文任务方面,GLM-4(128K)模型在LongBench-Chat上的表现与GPT-4 Turbo和Claude 3 Opus相当,分别为87.3、87.2和87.7。 |
GLM-4 All Tools(更好的对齐+自主选择最合适的工具):多轮方式访问网页能力+利用Python解释器解决数学问题能力+生成图像能力+调用自定义函数能力
| The GLM-4 All Tools model is specifically aligned to better understand user intent and autonomously select the most appropriate tool(s) for task completion. For example, it can access online information via a web browser in a multi-round manner, use the Python interpreter to solve math problems, leverage a text-to-image model to generate images, and call user-defined functions. Figure 2 shows an illustrative example of GLM-4 All Tools with a web browser and Python Interpreter for addressing the user query of “Search for the global population from 2000 to 2023, then calculate the average annual growth rate”. Our first-hand test shows that it not only matches but often surpasses the capabilities of GPT-4 All Tools for common tasks. | GLM-4 All Tools模型专门对齐以更好地理解用户意图并自主选择最合适的工具来完成任务。例如,它可以通过多轮方式使用网页浏览器访问在线信息,使用Python解释器解决数学问题,利用文本到图像模型生成图像,并调用用户自定义的函数。图2展示了GLM-4 All Tools使用网页浏览器和Python解释器处理用户查询“搜索2000年至2023年全球人口,然后计算年均增长率”的示例。我们的第一手测试表明,它不仅匹敌而且常常超过GPT-4 All Tools在常见任务上的能力。 |
2024年6月5日,正式开源GLM-4-9B、GLM-4-9B-Chat-1M(1M上下文)、GLM-4V-9B:基于10 T的token语料+使用与GLM-4相同的管道和数据进行后期训练=更长上下文(8K)+支持GLM-4 All Tools的所有功能
| Following our three generations of open ChatGLM-6B models, we also openly released the GLM-4- 9B (128K and 1M context length) model. GLM-4-9B is pre-trained on approximately ten trillion tokens of multilingual corpus with a context length of 8192 (8K) and post-trained with the same pipeline and data used for GLM-4 (0520). With less training compute, it outperforms Llama-3- 8B [24] and supports all the functionality of All Tools in GLM-4. We also provide an experimental model GLM-4-9B-Chat-1M with 1 million (1M) context length (about 2 million Chinese characters). Table 1 shows the performance of the three generations of ChatGLM-6B models and GLM-4-9B, illustrating the progressive improvements of ChatGLM over time. | 继三代开源的ChatGLM-6B模型之后,我们还公开发布了GLM-4-9B(128K和1M上下文长度)模型。GLM-4-9B在约10万亿多语言语料上进行预训练,具有8192(8K)上下文长度,并使用与GLM-4(0520)相同的管道和数据进行后期训练。使用较少的训练计算,它超越了Llama-3-8B并支持GLM-4 All Tools的所有功能。我们还提供了GLM-4V-9B,支持以更低的延迟生成高质量图像。 我们还提供了一个100万(1M)上下文长度(约200万个汉字)的实验模型GLM-4-9B-Chat-1M。 表1显示了三代ChatGLM- 6b模型和GLM-4-9B的性能,说明了ChatGLM随时间的逐步改进。 |
Table 1: Performance of Open ChatGLM-6B, ChatGLM2-6B, ChatGLM3-6B, and GLM-4-9B.
| Language | Dataset | ChatGLM-6B (2023-03-14) | ChatGLM2-6B (2023-06-25) | ChatGLM3-6B-Base (2023-10-27) | GLM-4-9B (2024-06-05) |
| English | GSM8K | 1.5 | 25.9 | 72.3 | 84 |
| MATH | 3.1 | 6.9 | 25.7 | 30.4 | |
| BBH | 0 | 29.2 | 66.1 | 76.3 | |
| MMLU | 25.2 | 45.2 | 61.4 | 74.7 | |
| GPQA | - | - | 26.8 | 34.3 | |
| HumanEval | 0 | 9.8 | 58.5 | 70.1 | |
| BoolQ | 51.8 | 79 | 87.9 | 89.6 | |
| CommonSenseQA | 20.5 | 65.4 | 86.5 | 90.7 | |
| HellaSwag | 30.4 | 57 | 79.7 | 82.6 | |
| PIQA | 65.7 | 69.6 | 80.1 | 79.1 | |
| DROP | 3.9 | 25.6 | 70.9 | 77.2 | |
| Chinese | C-Eval | 23.7 | 51.7 | 69 | 77.1 |
| CMMLU | 25.3 | 50 | 67.5 | 75.1 | |
| GAOKAO-Bench | 26.8 | 46.4 | 67.3 | 74.5 | |
| C3 | 35.1 | 58.6 | 73.9 | 77.2 |
Figure 3: From GLM-130B to ChatGLM to ChatGLM2/3 to GLM-4 All Tools.图3:从GLM-130B到ChatGLM到ChatGLM2/3到GLM-4所有工具。
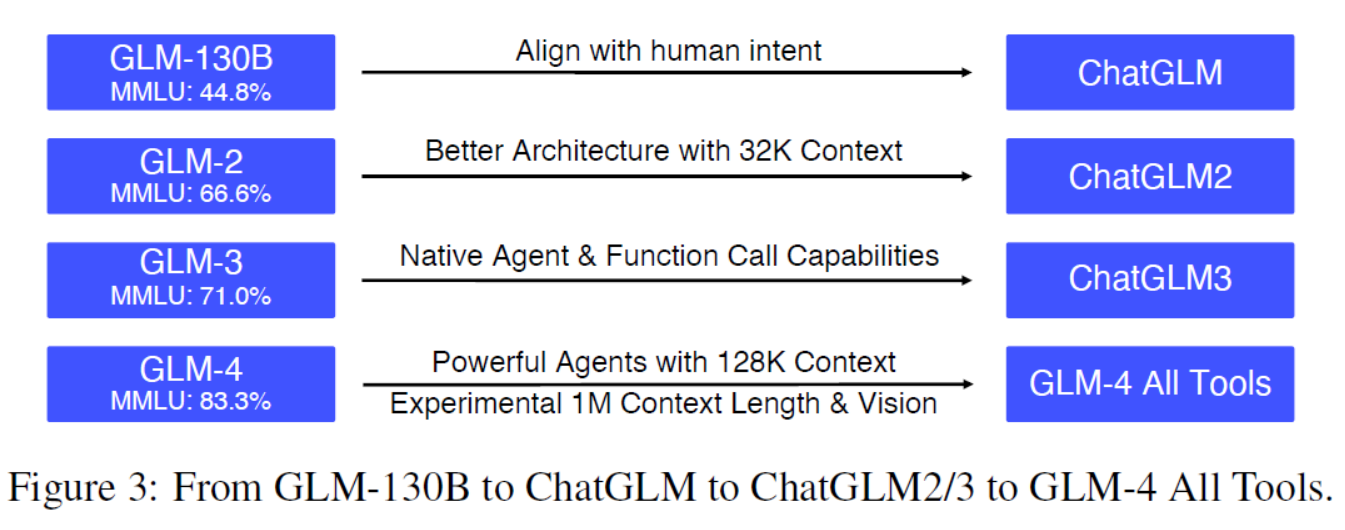
| Figure 3 summarizes the major improvements and features from GLM-130B to GLM-4 All Tools. Throughout this journey, we have also contributed to the open development of the code LLMs (CodeGeeX [58]) as well as visual language models for image understanding (CogVLM [45] and CogAgent [16]) and text-to-image generation (CogView [10; 59]). The open models and data can be accessed via https://github.com/THUDM and https://huggingface.co/THUDM. | 图3总结了从GLM-130B到GLM-4 All Tools的主要改进和特性。在整个过程中,我们还为代码LLMs(CodeGeeX[58])的开放开发以及用于图像理解的视觉语言模型(CogVLM[45]和CogAgent[16])和文本到图像生成(CogView [10;59])。开放的模型和数据可以通过https://github.com/THUDM和https://huggingface.co/THUDM访问。 |
2 ChatGLM Techniques技术
| In this section, we cover both the pre-training and post-training techniques we adopted and developed in ChatGLM, including model architecture, pre-training data, alignment, and All Tools. We have detailed technical reports introducing each of the major techniques we used to reach GLM-4. | 在本节中,我们将介绍ChatGLM采用和开发的预训练和后训练技术,包括模型架构、预训练数据、对齐和所有工具。我们有详细的技术报告,介绍了我们用来达到GLM-4的每一项主要技术。 |
2.1、Pre-Training Data预训练数据
数据源(网页+维基百科+书籍+代码+论文)、数据处理管道(去重+过滤+分词,语料库10T的tokens)、策略(采用BPE分词训练得到150K词表+数据源加权训练)
| Pre-Training Data. Our pre-training corpus consists of multilingual (mostly English and Chinese) documents from a mixture of different sources, including webpages, Wikipedia, books, code, and papers. The data processing pipeline mainly includes three stages: deduplication, filtering, and tokenization. The deduplication stage improves data diversity by removing duplicated or similar documents, with both exact deduplication and fuzzy deduplication. The filtering stage improves data quality by removing noisy documents that contain offensive language, placeholder text, source code, etc. The tokenization stage converts the text into a sequence of tokens for further processing. The number of tokens in the pre-training data directly affects model training speed. To optimize this aspect, we employ the byte-level byte pair encoding (BPE) algorithm [33] to separately learn the Chinese and multilingual tokens merge them with the tokens of the cl100k_base tokenizer in tiktoken [26] into a unified vocabulary with a size of 150,000. In the final training set, we re-weight different sources to increase the ratios of high-quality and educational sources like books and Wikipedia. To this end, the pre-training corpus consists of around ten trillion tokens. | 训练的数据。我们的预训练语料库由来自不同来源的多语言(主要是英语和中文)文档组成,包括网页、维基百科、书籍、代码和论文。数据处理管道主要包括去重、过滤和分词三个阶段。 >> 去重阶段通过删除重复或相似的文档来提高数据的多样性,包括精确去重和模糊去重。 >> 过滤阶段通过移除包含冒犯性/攻击性语言、占位符文本、源代码等噪声文档来提高数据质量。 >> 分词阶段将文本转换为一系列tokens以进行进一步处理。 预训练数据中token的数量直接影响模型的训练速度。为了优化这一方面,我们采用字节级字节对编码(BPE)算法分别学习中文和多语言令牌,并将其与tiktoken中的cl100k_base分词器的令牌合并成一个大小为150,000的统一词汇表。在最终的训练集中,我们重新加权不同来源以增加高质量和教育来源(如书籍和维基百科)的比例。为此,预训练语料库由大约10万亿个tokens组成。 |
经验:数据质量和多样性至关重要,但截止目前尚未找到数据预处理的一套基本流程原则
| Throughout the four generations of ChatGLM development, our findings align with existing stud-ies [60]: data quality and diversity are crucial for building effective LLMs. Despite the empirical lessons and insights gained, we have to date yet to identify a fundamental principle that could guide the processes of data collection, cleaning, and selection. | 在ChatGLM的四代发展过程中,我们的发现与现有研究一致[60]:数据质量和多样性对于构建有效的LLM至关重要。尽管获得了经验教训和见解,但到目前为止,我们还没有确定一个可以指导数据收集、清理和选择过程的基本原则。 |
2.2、Architecture架构
GLM-130B架构策略:DeepNorm+RoPE+带有GeLU的GLU
| Architecture. The GLM family of LLMs is built on Transformer [43]. In GLM-130B [54], we explored various options to stabilize its pre-training by taking into account the hardware constraints we faced at the time. Specifically, GLM-130B leveraged DeepNorm [44] as the layer normalization strategy and used Rotary Positional Encoding (RoPE) [38] as well as the Gated Linear Unit [35] with GeLU [15] activation function in FFNs. Throughout our exploration, we have investigated different strategies to enhance model performance and inference efficiency. | GLM家族的LLM建立在Transformer [43]之上。在GLM-130B [54]中,我们考虑到当时面临的硬件限制,探索了各种稳定其预训练的方案。具体来说,GLM-130B利用DeepNorm [44]作为层归一化策略,并使用旋转位置编码(RoPE)[38]以及在FFN中使用带有GeLU [15]激活函数的GLU(门控线性单元Gated Linear Unit)[35]。在探索过程中,我们研究了不同的策略以提高模型性能和推理效率。 |
最新GLM-4模型架构设计策略:NoBias_ExceptQKV(提高训练速度)、RMSNorm+SwiGLU(提高性能)、RoPE(扩展为2D来适应GLM的2D位置编码)、GQA(替换MHA来减少推理期间KV缓存的大小+增加FFN参数计数3倍)、、、
| The recent GLM-4 model adopts the following architecture design choices. >> No Bias Except QKV: To increase training speed, we have removed all bias terms with the exception of the biases in Query, Key, and Value (QKV) of the attention layers. In doing so, we observed a slight improvement in length extrapolation. >> RMSNorm and SwiGLU: We have adopted RMSNorm and SwiGLU to replace LayerNorm and ReLU, respectively. These two strategies have been observed with better model performance. >> Rotary positional embeddings (RoPE): We have extended the RoPE to a two-dimensional form to accommodate the 2D positional encoding in GLM. >> Group Query Attention (GQA): We have replaced Multi-Head Attention (MHA) with Group Query Attention (GQA) to cut down on the KV cache size during inference. Given GQA uses fewer parameters than MHA, we increased the FFN parameter count to maintain the same model size, i.e., setting dffn to 10/3 of the hidden size. | 最新的GLM-4模型采用了以下架构设计选择: >>移除QKV之外Bias:为了提高训练速度,我们移除了除注意力层中的查询、键和值(QKV)偏差之外的所有偏差项。在这样做时,我们观察到长度外推的轻微改善。 >> RMSNorm和SwiGLU:我们分别采用RMSNorm和SwiGLU来代替LayerNorm和ReLU。这两种策略已被观察到具有更好的模型性能。 >>旋转位置嵌入(RoPE):我们将RoPE扩展为二维形式,以适应GLM中的2D位置编码。 >>组查询注意(GQA):我们用组查询注意(GQA)取代了多头注意(MHA),以减少推理期间KV缓存的大小。考虑到GQA比MHA使用更少的参数,我们增加FFN参数计数以保持相同的模型大小,即将dffn设置为隐藏大小的10/3。 |
整体趋势:更长的上下文(2K→32K→32K→128K/1M)及其策略(位置编码扩展+对长文本的持续训练+长上下文对齐)
| The context length of our models was extended from 2K (ChatGLM), to 32K (ChatGLM2 and ChatGLM3), and to 128K and 1M (GLM-4). This expansion was achieved not only through context extension—position encoding extension [30; 5] and continual training [47] on long text—but also long context alignment, enabling GLM-4 to effectively handle long contexts (Cf [1] for technical details). | 我们的模型的上下文长度从2K (ChatGLM)扩展到32K (ChatGLM2和ChatGLM3),以及128K和1M (GLM-4)。这种扩展不仅通过上下文扩展-位置编码扩展[30;[5]和对长文本的持续训练[47],以及长上下文对齐,使GLM-4能够有效地处理长上下文(参见技术细节[1])。 |
2.3、Alignment对齐
预训练(奠定基础能力)→后训练(完善衍生能力,遵循指令对齐人类意图+促进多轮对话)
GLM-4:对齐能力来自SFT(真实的人类提示和互动更重要)+RLHF(进一步帮助缓解响应拒绝、安全、生成双语、多轮连贯性等)
| Alignment. Pre-training builds the foundation of LLMs while post-training [28] further refines these models to align with human preferences, such as understanding human intents, following instructions, and facilitating multi-turn dialogues. For GLM-4, the alignment is mostly achieved with supervised fine-tuning (SFT) and reinforcement learning from human feedback (RLHF) [17]. In SFT, we find that authentic human prompts and interactions instead of template-based or model-generated responses are vital to the alignment quality. While SFT largely aligns the base models with human preferences, RLHF can further help mitigate issues of response rejection, safety, mixture of bilingual tokens generated, and multi-turn coherence among others. | 对齐。预训练为LLM奠定了基础,而后训练[28]进一步完善和细化这些模型以符合人类偏好,如理解人类意图、遵循指令和促进多轮对话。 对于GLM-4,对齐主要通过监督微调(SFT)和来自人类反馈的强化学习(RLHF)[17]来实现。在SFT中,我们发现真实的人类提示和互动,而不是基于模板或模型生成的响应对对齐质量至关重要。虽然SFT在很大程度上使基本模型与人类偏好保持一致,RLHF可以进一步帮助缓解响应拒绝、安全、生成的双语tokens混合、多轮连贯性/一致性等问题。 |
ChatGLM-1:prompt-response,从模型开发者标注→严格的质量控制(安全性/真实性/相关性/帮助性/人类偏好)
| For the first generation of models (ChatGLM-6B and ChatGLM-130B), the prompt-response pairs were mostly annotated by the model developers. For later models, the alignment data is a combination of in-house annotating data and proprietary data acquired from third parties, subject to relatively strict quality control measures. Similar to existing practice [42], annotators are instructed to score model responses from several dimensions, including safety, factuality, relevance, helpfulness, and human preferences. | 对于第一代模型(ChatGLM-6B和ChatGLM-130B),prompt-response对大多由模型开发者标注。对于后来的模型,对齐数据是内部标注数据和从第三方获得的专有数据的组合,受到相对严格的质量控制措施。类似于现有实践[42],标注者被指示从多个维度对模型响应进行评分,包括安全性、真实性、相关性、帮助性和人类偏好。 |
2.4、ChatGLM Techniques技术
提高性能的技术:
涌现能力(较低预训练损失的模型所具有的能力)、LongAlign能力(采用长上下文对齐的综合配方)、Math能力(采用自我批评)
| ChatGLM Techniques. Throughout the development of ChatGLM, we have introduced and will publish techniques that are used to enhance its performance. >> Emergent Abilities of LLMs [12]: We examined the relationship between pre-training loss and performance on downstream tasks and found that with the same pre-training loss, LLMs of different model sizes and training tokens generate the same downtream performance. We also find that on some tasks (such as MMLU and GSM8K), the performance improves beyond random chance only when the pre-training loss falls below a certain threshold. We thus redefine emergent abilities as those exhibited by models with lower pre-training losses [12]. >> LongAlign [1]: To extend LLMs’ context window size, we proposed LongAlign—a comprehensive recipe for long context alignment. It enables GLM-4 to process long context texts (up to 128K tokens) with performance comparable to that of Claude 2 and GPT-4 Turbo (1106). >> ChatGLM-Math [48]: For the improvement of math problem solving in LLMs, we introduced ChatGLM-Math that leverages self-critique rather than external models or manual annotations for data selection. | ChatGLM技术。在ChatGLM的整个开发过程中,我们已经介绍并将发布用于提高其性能的技术。 >> LLM的涌现能力[12]:我们研究了预训练损失与下游任务性能之间的关系,发现在相同的预训练损失下,不同模型大小和训练tokens的LLM产生相同的下游性能。我们还发现,在某些任务(如MMLU和GSM8K)上,只有当预训练损失低于某一阈值时,性能才会超越随机机会。因此,我们重新定义了突现能力,即表现出较低预训练损失的模型所具有的能力[12]。 >> LongAlign[1]:为了扩展LLM的上下文窗口大小,我们提出了LongAlign——一个长上下文对齐的综合配方。它使GLM-4能够处理长上下文文本(高达128K tokens),其性能可与Claude 2和GPT-4 Turbo(1106)相媲美。 >> ChatGLM-Math[48]:为了提高LLMs的数学问题解决能力,我们引入了ChatGLM-Math,它利用自我批评而不是外部模型或手动注释来进行数据选择。 |
ChatGLM-RLHF(采用PPO/DPO实现与人类反馈保持一致)、Self-Contrast(利用目标LLM自身生成大量负样本进行RLHF对齐)、AgentTuning(高质量智能体与环境交互轨迹的AgentInstruct指令微调数据)、APAR(提高推理速度)
| >> ChatGLM-RLHF [17]: To align LLMs with human feedback, we introduced ChatGLM-RLHF—our practices of applying PPO and DPO into LLMs. >> Self-Contrast [22]: To avoid the need for expensive human preference feedback data, we developed a feedback-free alignment strategy Self-Contrast. It utilizes the target LLM itself to self-generate massive negative samples for its RLHF alignment. >> AgentTuning [53]: To improve LLMs’ agent capabilities, we developed the AgentTurning frame-work with the AgentInstruct instruction-tuning dataset that includes high-quality interaction trajec-tories between agents and environment. >> APAR [20]: To improve the inference speed of LLMs for responses with hierarchical structures, we presented an auto-parallel auto-regressive (APAR) generation approach. It leverages instruct tuning to train LLMs to plan their (parallel) generation process and execute APAR generation. | >> ChatGLM-RLHF[17]:为了使LLM与人类反馈保持一致,我们引入了ChatGLM-RLHF -我们将PPO和DPO应用于LLM的实践。 >> Self-Contrast[22]:为了避免对昂贵的人类偏好反馈数据的需求,我们开发了一种无反馈的对齐策略Self-Contrast。它利用目标LLM自身生成大量负样本进行RLHF对齐。 >> AgentTuning[53]:为了提高LLM的Agent能力,我们开发了AgentTurning框架,使用包含高质量智能体与环境交互轨迹的AgentInstruct指令微调数据集。 >> APAR[20]:为了提高LLM在具有层次结构的响应中的推理速度,我们提出了一种自动并行自回归(APAR)生成方法。它利用指令微调来训练LLM计划它们的(并行)生成过程并执行APAR生成。 |
Benchmarks(AgentBench/LongBench/AlignBench/HumanEval/NaturalCodeBench)
| >> Benchmarks: We also developed several open LLM benchmarks, including AgentBench [23] for evaluating LLMs as agents, LongBench [2] for evaluating the long context handling performance of LLMs, AlignBench [1] to measure the alignment quality of ChatGLM with Chinese language content, HumanEval-X [58] to evaluate HumanEval [4] problems in programming languages beyond Python, as well as NaturalCodeBench (NCB) to measure models’ capacities to solve practical programming tasks. | >> Benchmarks: 我们还开发了几个开放的LLM基准测试,包括AgentBench[23]用于评估LLM作为智能体的表现,LongBench[2]用于评估LLM处理长上下文的性能,AlignBench[1]用于测量ChatGLM在中文内容上的对齐质量,HumanEval-X[58]用于评估Python以外编程语言的HumanEval[4]问题,以及NaturalCodeBench(NCB)用于衡量模型解决实际编程任务的能力。 |
2.5、GLM-4 All Tools(进一步支持智能智能体和相关任务)
原理:自主理解用户意图→规划复杂的指令→顺序调用一个或多个工具(例如支持嵌入式Python解释器、Web浏览器、文本到图像模型)→完成复杂的任务(如支持用户定义的函数、API和外部知识库)
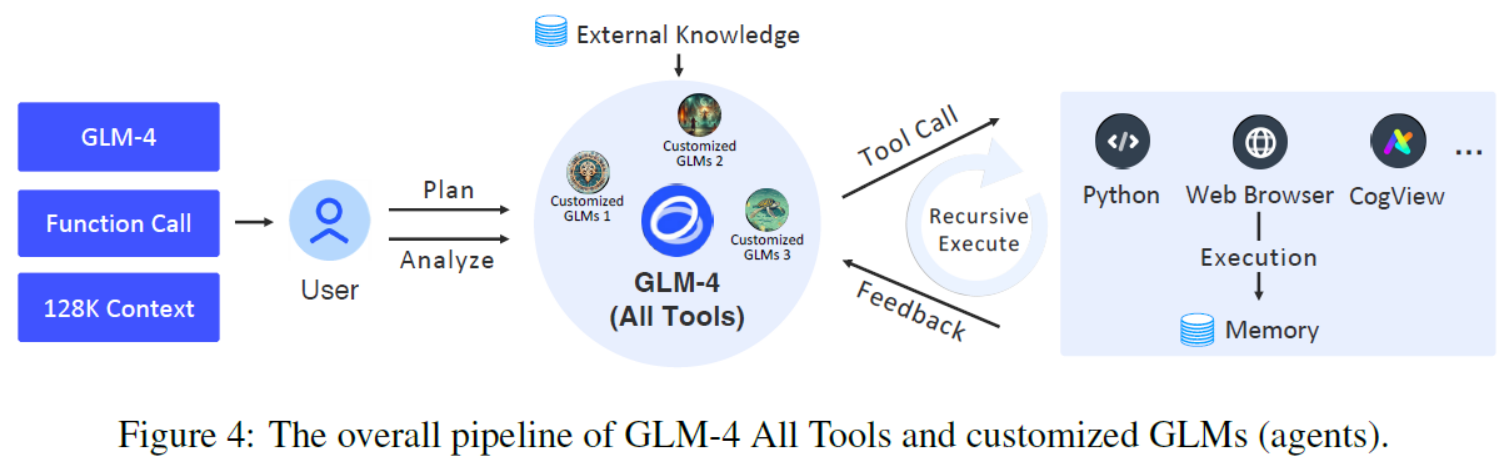
| GLM-4 All Tools. The latest ChatGLM models are GLM-4 and GLM-4 All Tools, both of which were trained and aligned by using the techniques above. GLM-4 All Tools is a model version further aligned to support intelligent agents and related tasks. It can autonomously understand user intent, plan complex instructions, and call one or multiple tools (e.g., Web browser, Python interpreter, and the text-to-image model) to complete complex tasks. Figure 4 presents the overall pipeline of the GLM-4 All Tools system. When a user issues a complex request, the model analyzes the task and plan the solving process step by step. If it determines that it cannot complete the task independently, it will sequentially call one or multiple external tools, utilizing their intermediate feedback and result to help solve the task. Built on the GLM-4’s all-tools capabilities, we also developed the GLMs application platform that allows users to create and customize their own agents for specific tasks. The GLMs support not only the embedded Python interpreter, Web browser, text-to-image model but also user-defined functions, APIs, and external knowledge bases to more effectively address user needs. | 最新的ChatGLM模型是GLM-4和GLM-4 All Tools,它们都是通过使用上述技术进行训练和对齐的。 GLM-4 All Tools是进一步对齐以支持智能体和相关任务的模型版本。它可以自主理解用户意图,规划复杂的指令,调用一个或多个工具(例如,Web浏览器、Python解释器和文本到图像模型)来完成复杂的任务。图4展示了GLM-4 All Tools系统的整体管道。当用户发出复杂的请求时,该模型分析任务并逐步规划解决过程。如果它确定自己不能独立完成任务,它将顺序调用一个或多个外部工具,利用它们的中间反馈和结果来帮助解决任务。 基于GLM-4 All Tools功能,我们还开发了GLM应用程序平台,允许用户为特定任务创建和定制自己的智能体。GLM不仅支持嵌入式Python解释器、Web浏览器、文本到图像模型,还支持用户定义的函数、API和外部知识库,以更有效地处理数据,满足用户需求。 |
Figure 4: The overall pipeline of GLM-4 All Tools and customized GLMs (agents).
3 GLM-4 Capabilities能力
考察能力:学术基准的基础能力、代码能力、智能体能力、指令遵循能力、长上下文能力、中文对齐能力
| We examine the capabilities of the GLM-4 model from diverse perspectives, including the base capacity on academic benchmarks, code problem-solving, agent abilities in English, and instruction following, long context for both Chinese and English, as well as alignment in Chinese. As mentioned, GLM-4 was pre-trained mostly in Chinese and English and aligned predominantly to Chinese. In this section, we report results primarily for the latest GLM-4 version, i.e., GLM-4 (0520) and GLM-4-Air (0605), as GLM-4 (0520) is slightly better than its original 0116 version across the evaluated benchmarks. During evaluation, both GLM-4 and GLM-4-Air are deployed with BFloat16 precision. | 我们从多个角度考察了GLM-4模型的能力,包括学术基准的基础能力、代码问题解决的能力、智能体能力(英文环境下)、指令遵循能力、长上下文(中英文)以及中文对齐能力。如前所述,GLM-4主要以中文和英文进行预训练,并且主要对齐到中文。 在本节中,我们主要报告最新的GLM-4版本的结果,即GLM-4(0520)和GLM-4-Air(0605),因为在评估的基准测试中,GLM-4(0520)略好于其最初的0116版本。在评估过程中,GLM-4和GLM-4-Air都以BFloat16精度部署。 |
结果对比:GLM-4在标准基准测试方面接近最先进的模型(GPT-4-Turbo, Gemini 1.5 Pro和Claude 3 Opus),中文更出色!
| For baselines, we present results for GPT-4 (0603), GPT-4 Turbo (1106, 2024-04-09), Claude 2, Claude 3 Opus, and Gemini 1.5 Pro, all of which were extracted from the corresponding technical reports or tested through their public APIs. Overall, GLM-4 gets close to the state-of-the-art models (GPT-4-Turbo, Gemini 1.5 Pro, and Claude 3 Opus) in terms of standard benchmarks, as well as instruction following, long context, code problem-solving, and agent abilities in English environment. For Chinese alignment, it generates strong performance against SOTA models across various domains, such as fundamental language ability, advanced Chinese understanding, professional knowledge, and open-ended questions. In summary, GLM-4 is among the best in terms of Chinese language tasks. It also demonstrates comparable performance to GPT-4 and Claude 3 Opus in Chinese math and logic reasoning capabilities though it lags behind GPT-4 Turbo. | 作为基准,我们给出了GPT-4(0603)、GPT-4 Turbo(1106、2024-04-09)、Claude 2、Claude 3 Opus和Gemini 1.5 Pro的结果,所有这些结果都是从相应的技术报告中提取的,或者通过它们的公共API进行了测试。 总体而言,GLM-4在标准基准测试方面接近最先进的模型(GPT-4-Turbo, Gemini 1.5 Pro和Claude 3 Opus),以及指令遵循,长上下文,代码解决问题和英语环境中的智能体能力。在中文对齐方面,它在基础语言能力、中文高级理解、专业知识和开放性问题等各个领域表现出色。总的来说,GLM-4在中文语言任务中表现出色。在中文数学和逻辑推理能力方面,它的表现与GPT-4和Claude 3 Opus相当,虽然仍然落后于GPT-4 Turbo。 |
3.1 Evaluation of Academic Benchmarks学术基准评估—MMLU/GSM8K/BBH/GPQA/HumanEva:涵盖知识、数学、推理、常识和代码
| To evaluate the general performance of the base model, we select six commonly-used benchmarks spanning knowledge, math, reasoning, commonsense, and coding: >> MMLU [14]: Multi-choice questions collected from various examinations including mathe-matics, history, computer science, and more. We present all answers to the model and ask it to choose the letter of the answer. >> GSM8K [7]: 8,500 grade school math word problems (1,000 in the test set) that require the model to solve real-life situational problems using mathematical concepts. We use chain-of-thought prompting [46] for this benchmark. >> MATH: 12,500 challenging competition-level mathematics problems (5,000 in the test set). We use chain-of-thought prompting [46] for this benchmark. >> BBH [39]: A suite of 23 challenging BIG-Bench [37] tasks. We use chain-of-thought prompting [46] for this benchmark. >> GPQA [31]: A graduate-level multi-choice benchmark in biology, chemistry, and physics. >> HumanEval [4]: a coding benchmark that measures correctness of synthetic functions with automatic test-case checking. | 为了评估基本模型的总体性能,我们选择了六个常用的基准,涵盖知识、数学、推理、常识和代码: >> MMLU[14];从各种考试中收集的选择题,包括数学、历史、计算机科学等。我们将所有答案呈现给模型,并要求其选择正确答案的字母。 >> GSM8K[7];8,500个小学数学文字题(测试集中有1,000个),这些问题要求模型使用数学概念解决现实生活中的情境问题。我们在这个基准测试中使用了思维链提示[46]。 >> MATH;12,500个具有挑战性的竞赛级数学问题(测试集中有5,000个)。我们在这个基准测试中使用了思维链提示[46]。 >> BBH[39];一个包含23个具有挑战性的BIG-Bench [37]任务的套件。我们对该基准使用了思维链提示 [46]。 >> GPQA[31];一个涵盖生物学、化学和物理学的研究生级别多选题基准。 >> HumanEval[4];一个编码基准,通过自动测试用例检查来衡量合成函数的正确性。 |
| We compare the performance of GLM-4 with the original GPT-4 [27]. The results are shown in Table 2. We can observe that GLM-4 achieves 96.3% of GPT-4’s accuracy on MMLU, and outperforms GPT-4 on other benchmarks. Overall, the base capacity of GLM-4 approaches that of GPT-4-Turbo and Claude 3 Opus. | 我们比较了GLM-4与原始GPT-4的性能[27]。结果如表2所示。我们可以观察到,GLM-4在MMLU上的准确率达到了GPT-4的96.3%,并且在其他基准测试上优于GPT-4。总体而言,GLM-4的基础能力接近GPT-4-Turbo和Claude 3 Opus。 |
Table 2: GLM-4 performance on academic benchmarks.
| Model | MMLU | GSM8K | MATH | BBH | GPQA | HumanEval |
| GPT-4 (0314) | 86.4 | 92 | 52.9 | 83.1 | 35.7 | 67 |
| GPT-4 Turbo (1106) | 84.7 | 95.7 | 64.3 | 88.3 | 42.5 | 83.7 |
| GPT-4 Turbo (2024-04-09) | 86.7 | 95.6 | 73.4 | 88.2 | 49.3 | 88.2 |
| Claude 3 Opus | 86.8 | 95 | 60.1 | 86.8 | 50.4 | 84.9 |
| Gemini 1.5 Pro | 85.9 | 90.8 | 67.7 | 89.2 | 46.2 | 84.1 |
| GLM-4-9B-Chat | 72.4 | 79.6 | 50.6 | 76.3 | 28.8 | 71.8 |
| GLM-4-Air (0605) | 81.9 | 90.9 | 57.9 | 80.4 | 38.4 | 75.7 |
| GLM-4 (0116) | 81.5 | 87.6 | 47.9 | 82.3 | 35.7 | 72 |
| GLM-4 (0520) | 83.3 | 93.3 | 61.3 | 84.7 | 39.9 | 78.5 |
3.2 Evaluation of Instruction Following指令跟随评估(指令跟随方面的熟练度)—针对IFEval
| We assess the proficiency of GLM-4 in following instructions with the recently-introduced IFEval dataset [61]. The dataset comprises 541 prompts derived from 25 distinct instructions that are verifiable through explicit criteria (e.g., “end your email with: P.S. I do like the cake” can be verified via string matching). We adhere to the methodologies outlined by [61] to calculate prompt-level and instruction-level accuracy in both strict mode and loose mode. To further evaluate the model’s performance on following instructions in Chinese, we translate the original prompts into Chinese, omitted instructions that are not applicable in Chinese (such as capitalization), and adjust the scoring scripts to accommodate Chinese data. | 我们使用最近引入的IFEval数据集 [61] 评估GLM-4在指令跟随方面的熟练度。该数据集包含从25个不同指令中衍生的541个,可通过明确标准验证的提示(例如,“在你的电子邮件末尾写上:P.S.我确实喜欢蛋糕”可以通过字符串匹配进行验证)。我们按照 [61] 的方法计算严格模式和宽松模式下的提示级和指令级准确率。为了进一步评估模型在中文指令跟随方面的性能,我们将原始提示翻译成中文,省略了不适用于中文的指令(如大小写),并调整了评分脚本以适应中文数据。 |
Table 3: GLM-4 performance on IFEval [61], an LLM instruction following benchmark. ‘L‘ stands for ‘Loose‘ and ‘S‘ stands for ‘Strict‘. ‘P‘ stands for ‘Prompt‘ and ‘I‘ stands for ‘Instruction‘.表3:GLM-4在IFEval [61]上的表现,一个LLM指令跟随基准。‘L‘代表‘宽松‘,‘S‘代表‘严格‘,‘P‘代表‘提示‘,‘I‘代表‘指令‘。
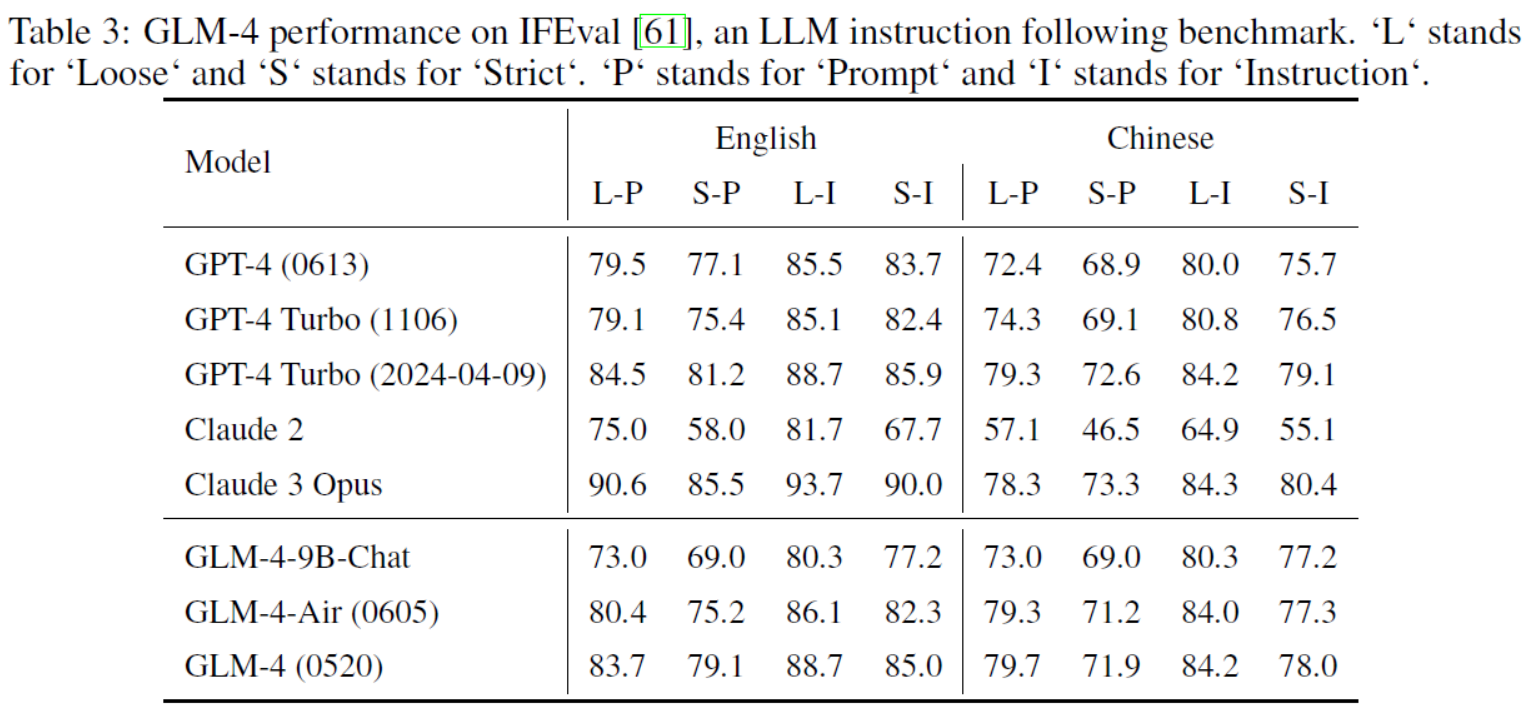
| The English and Chinese sections in Table 3 show results in both English and Chinese, respectively. In loose mode, GLM-4 matches instruction-level accuracy achieved by GPT-4 Turbo in both English and Chinese. In strict mode, GLM-4 achieves 99.0% and 98.6% of instruction-level accuracy of GPT-4 Turbo (2024-04-09) in English and Chinese, respectively. | 表3中的英文和中文部分分别显示了英文和中文的结果。在宽松模式下,GLM-4在指令级准确率上与GPT-4 Turbo在英文和中文中的表现相匹配。在严格模式下,GLM-4分别达到了GPT-4 Turbo(2024-04-09)在英文和中文中指令级准确率的99.0%和98.6%。 |
3.3 Evaluation of Alignment对齐评估—针对AlignBench+利用LLMs-as-Judge方法:中文逻辑推理问题更强+数学问题采用了自我批评策略
| AlignBench [21] provides an automatic LLMs-as-Judge method to benchmark the alignment of LLMs in Chinese context. It consists 683 queries spanning 8 different categories, and judges model responses using a GPT-4 based multidimensional rule-calibrated pointwise reference-based scoring method. We evaluate on AlignBench-v1.1, which more carefully improves the reference generation quality, especially by complementing human-collected evidences from webpages with urls for knowledge-requiring problems that takes up 66.5% of total queries. On this version, almost all LLMs achieve lower scores than they do in the previous AlignBench more or less. | AlignBench [21] 提供了一种自动方法LLMs-as-Judge方法来基准测试LLMs在中文环境中的对齐情况。它包含683个跨越8个不同类别的查询,并使用基于GPT-4的多维规则校准的逐点参考评分方法对模型响应进行评估。我们在AlignBench-v1.1上进行评估,该版本通过补充来自网页的带URL的人类收集证据来更仔细地提高参考生成质量,特别是占总查询数66.5%的需要知识的问题。在这个版本上,几乎所有LLMs的得分都比在之前的AlignBench上有所下降。 |
Table 4: GLM-4 performance on AlignBench [21], an LLM benchmark for alignment in Chinese.表4:GLM-4在AlignBench [21]上的表现,一个LLM中文对齐基准。
| Model | Math | Logic | Language | Chinese QA | Writing | Role Play | Professional | Overall |
| GPT-4 (0613) | 7.54 | 7.17 | 7.82 | 7.02 | 7.39 | 8.2 | 7.29 | 7.46 |
| GPT-4 Turbo (1106) | 7.85 | 7.66 | 7.9 | 7.22 | 8.24 | 8.53 | 7.95 | 7.9 |
| GPT-4 Turbo (2024-04-09) | 8.32 | 7.67 | 7.6 | 7.57 | 8.37 | 7.75 | 8.18 | 8 |
| Claude 2 | 6.39 | 5.85 | 6.75 | 5.72 | 6.68 | 6.86 | 6.56 | 6.26 |
| Claude 3 Opus | 7.27 | 7.11 | 7.94 | 7.71 | 8.21 | 7.61 | 7.73 | 7.53 |
| Gemini 1.5 Pro | 7.07 | 7.77 | 7.31 | 7.22 | 8.55 | 7.83 | 7.79 | 7.47 |
| GLM-4-9B-Chat | 7 | 6.01 | 6.69 | 7.26 | 7.97 | 8.1 | 7.52 | 7.01 |
| GLM-4-Air (0605) | 7.69 | 6.95 | 7.53 | 8 | 7.9 | 8.01 | 8.35 | 7.65 |
| GLM-4 (0116) | 7.2 | 7.2 | 7.6 | 8.19 | 8.45 | 8.05 | 8.56 | 7.66 |
| GLM-4 (0520) | 7.89 | 7.95 | 8 | 7.86 | 8.11 | 8.04 | 8.47 | 8 |
| Results are shown in Table 4. GLM-4 outperforms GPT-4 Turbo, Claude 3 Opus, and Gemini 1.5 Pro in general, achieves the highest overall score among the baselines. Especially on Chinese Logic Reasoning and Language Understanding dimensions, GLM-4 significantly outperforms all other powerful models. These results demonstrate its strong grasping of Chinese language and knowledge. The current performance gap between GLM-4 and GPT-4 Turbo (2024-04-09) mostly lies in the Mathematics dimension. We have been employing techniques introduced in ChatGLM-Math [48] such as self-critique to continuously enhance GLM models’ reasoning capabilities. | 结果如表4所示。GLM-4总体表现优于GPT-4 Turbo、Claude 3 Opus和Gemini 1.5 Pro,在基准中获得了最高的综合得分。特别是在中文逻辑推理和语言理解维度上,GLM-4显著优于其他所有强大的模型。这些结果展示了其对中文语言和知识的强大掌握能力。 目前GLM-4与GPT-4 Turbo(2024-04-09)的性能差距主要在于数学维度。我们一直在使用ChatGLM-Math[48]中引入的技术,如自我批评,来不断增强GLM模型的推理能力。 |
3.4 Evaluation of Long Context Handling Abilities长文本处理能力的评估—针对LongBench-Chat:采用细粒度(中英文分离)策略+采用GPT-4评分多次取均值
| To obtain the performance of GLM-4 on long text tasks, we carry out evaluations on LongBench-Chat [1], a benchmark set with contextual lengths ranging from 10-100k, encompassing a wide range of long text scenarios frequently utilized by users, such as document Q&A, summarizing, and coding. In our quest to provide a more detailed comparison of the performance of GLM-4 in different languages, we also segregate LongBench-Chat according to language. This yields two distinct portions: Chinese and English. We have accordingly supplied the results for both segments separately, offering a fine-grained overview of GLM-4’s cross-linguistic capabilities. | 为了获得GLM-4在长文本任务上的性能,我们在LongBench-Chat [1]上进行了评估,该基准集的上下文长度从10-100k不等,涵盖用户常用的各种长文本场景,如文档问答、摘要和编码。为了提供GLM-4在不同语言中的更详细的性能比较,我们还根据语言对LongBench-Chat进行了分离。这产生了两个不同的部分:中文和英文。因此,我们分别提供了两个部分的结果,提供了GLM-4跨语言功能的细粒度概述。 |
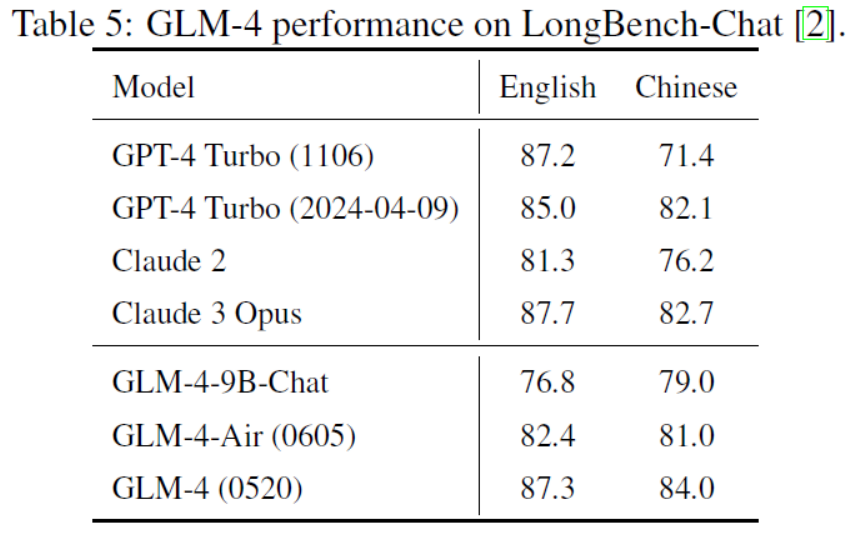
| Regarding the specific evaluation settings, we score the outputs of each model based on GPT-4, adopting a few-shot strategy within LongBench-Chat. Moreover, given our objective to minimize score variations and to reach a more reliable statistical conclusion, we conduct repeated evalua-tions. Subsequently, we compute the average from these multiple evaluations to ensure that the final performance metric reflects a thorough understanding of how GLM-4 behaves under diverse conditions. Table 5 features the results obtained from our experiments. It can be clearly observed that the performance of GLM-4 aligns with that of GPT-4 Turbo and Claude 3 Opus on English prompts, and it can outperform the best of them on Chinese prompts. | 对于具体的评估设置,我们基于GPT-4对每个模型的输出进行评分,在LongBench-Chat中采用few-shot策略。此外,为了尽量减少评分变化并得出更可靠的统计结论,我们进行了多次评估,并计算这些多次评估的平均值,以确保最终的性能指标反映GLM-4在各种条件下的全面表现。 表5展示了我们的实验结果。可以清楚地看到,GLM-4在英文提示符上的表现与GPT-4 Turbo和Claude 3 Opus相当,在中文提示上则优于其中最好者。 |
Table 5: GLM-4 performance on LongBench-Chat [2].
3.5 Evaluation of Coding on Real-world User Prompts对真实用户提示编码的评估
HumanEval基准:偏向入门级算法+训练数据疑被污染→结评估果相对不可信
| While HumanEval [4] has been widely adopted for evaluating code generation, most of its problems can be categorized to introductory algorithms. However, in practice, real users ask complicated ques-tions for production purposes, which are usually far beyond the scope of HumanEval. Additionally, previous works have reported HumanEval-contaminated training data [27; 18; 50] in their own or other LLMs, making the results on HumanEval relatively less trustful than before. | 虽然HumanEval[4]已被广泛用于评估代码生成,但它的大多数问题可以归类为入门级算法。然而,在实践中,真实用户提出的复杂问题通常远超HumanEval的范围。此外,先前的研究报告了HumanEval被污染的训练数据 [27; 18; 50],这使得HumanEval的结果相对不那么可信。 |
NCB基准:表现接近Claude 3 Opus但仍差于GPT-4
Table 6: GLM-4 performance on NaturalCodeBench (NCB) [56], a benchmark with real coding prompts in two programming languages (Python and Java) for English and Chinese.表6:GLM-4在NaturalCodeBench (NCB)上的表现[56],这是一个具有真实编码提示的双语编码基准,涵盖两种编程语言(Python和Java),适用于英文和中文。
| Model | Python (en) | Java (en) | Python (zh) | Java (zh) | Overall |
| GPT-4 (0613) | 55.7 | 51.1 | 53.4 | 51.1 | 52.8 |
| GPT-4 Turbo (1106) | 51.9 | 55 | 47.3 | 51.9 | 51.5 |
| GPT-4 Turbo (2024-04-09) | 57.5 | 52.3 | 53.1 | 52.3 | 53.8 |
| Claude 2 | 34.4 | 36.6 | 33.6 | 32.8 | 34.4 |
| Claude 3 Opus | 48.9 | 48.9 | 45 | 50.4 | 48.3 |
| Gemini 1.5 Pro | 45 | 39.7 | 41.5 | 43.1 | 42.3 |
| GLM-4-9B-Chat | 33.9 | 29.8 | 30.8 | 34.4 | 32.2 |
| GLM-4-Air (0605) | 40.8 | 39.7 | 43.1 | 39.7 | 40.8 |
| GLM-4 (0520) | 51.6 | 42.8 | 45.4 | 48.9 | 47.1 |
| As a result, beside HumanEval we evaluate GLM-4 on NaturalCodeBench (NCB) [56], a challenging bilingual coding benchmark derived from natural user prompts to mirror the complexity of real-world coding missions. Results are shown in Table 6. It shows that GLM-4 has a close coding performance to Claude 3 Opus in practical scenarios. While there is still some gaps to GPT-4 models, considering GLM-4 bilingually balanced nature, there is quite much potential to improve its performance on NCB via better training strategies and data curation in our following iterations. | 因此,除了HumanEval,我们在NaturalCodeBench (NCB)上评估了GLM-4[56],这是一个从自然用户提示中衍生的具有挑战性的双语编码基准,反映了现实世界编码任务的复杂性。结果如表6所示。结果表明,GLM-4在实际场景中的编码表现接近Claude 3 Opus。虽然GPT-4模型仍然存在一些差距,但考虑到GLM-4的双语平衡性质,在我们接下来的迭代中,通过更好的训练策略和数据管理,它在NCB上的性能有很大的潜力可以提高。 |
3.6 Evaluation of Function Call函数调用评估:三种类别(AST/执行API评估/相关性检测),GLM-4能力与GPT-4 Turbo相当,GLM-4- 9b - Chat的函数调用能力明显优于Llama-3-8B-Instruct
| To evaluate the performance of GLM models on function call, we carry out evaluations on Berkeley Function Call Leaderboard [49], a benchmark with 2k question-function-answer pairs. The benchmark evaluates model capacity on calling functions in three categories: evaluation by Abstract Syntax Tree (AST), evaluation by executing APIs, and relevance detection. The first category compares the model output functions against function documents and possible answers with AST analysis. The second category checks for response correctness by executing the generated function calls. Relevance detection evaluates the model’s capacity on recognizing functions that are not suitable to answer the user’s question. | 为了评估GLM模型在函数调用上的性能,我们在伯克利函数调用排行榜(Berkeley function call Leaderboard)上进行了评估[49],这是一个包含2k个问题-函数-答案对的基准。该基准评估模型在三个类别中调用函数的能力:通过抽象语法树(AST)评估、通过执行API评估和相关性检测。 >> 第一个类别通过AST分析将模型输出函数与函数文档和可能的答案进行比较。 >> 第二个类别通过执行生成的函数调用来检查响应的正确性。 >> 相关性检测评估模型识别不适合回答用户问题的函数的能力。 |
| The results are shown in Table 7. We can observe that the function-call capacity of GLM-4 (0520) aligns with that of GPT-4 Turbo (2024-04-09), while GLM-4-9B-Chat significantly outperforms Llama-3-8B-Instruct. Another observation is that the overall accuracy does not improve with model sizes, while GLM-4-9B-Chat can even outperform GLM-4-Air. On the other hand, we observe that the performance on execution summary, which evaluates the execution results of real-world APIs, improves smoothly with model sizes. | 结果如表7所示。我们可以看到,GLM-4(0520)的函数调用能力与GPT-4 Turbo(2024-04-09)相当,而GLM-4- 9b - Chat的函数调用能力明显优于Llama-3-8B-Instruct。另一个观察结果是,整体准确性并不会随着模型规模的增大而提高,而GLM-4-9B-Chat甚至可以优于GLM-4-Air。另一方面,我们观察到执行总结性能(评估实际API的执行结果)随着模型规模的增加而平稳提升。 |
Table 7: GLM performance on the Berkeley Function Call Leaderboard.
| Model | AST Summary | Exec Summary | Relevance | Overall |
| Llama-3-8B-Instruct | 59.25 | 70.01 | 45.83 | 58.88 |
| GPT-4 Turbo (2024-04-09) | 82.14 | 78.61 | 88.75 | 81.24 |
| GPT-4o (2024-05-13) | 85.23 | 80.37 | 81.25 | 82.94 |
| ChatGLM3-6B | 62.18 | 69.78 | 5.42 | 57.88 |
| GLM-4-9B-Chat | 80.26 | 84.4 | 87.92 | 81 |
| GLM-4-Air (0605) | 84.34 | 85.93 | 68.33 | 80.94 |
| GLM-4 (0520) | 82.59 | 87.78 | 84.17 | 81.76 |
3.7 Evaluation of Agent Abilities智能体能力评估—AgentBench:LLMs是智能体系统中的智能体(LLMs-as-Agents),对比GLM-4各有千秋
| It is widely observed that LLMs are capable to serve as intelligent agents in versatile environments and contexts [29; 52], known as LLMs-as-Agents [23]. As a result, we evaluate GLM-4 together with other comparison LLMs on AgentBench [23], a comprehensive agentic benchmark for text-based LLMs across an array of practical environments, including code-based, game-based, and web-based contexts. Specifically, we evaluate on 7 out of 8 AgentBench environments except for Digital Card Game, which takes much longer time to interact with. Overall scores are calculated using the original per-dataset weights provided in AgentBench [23]. | 人们普遍认为,LLM能够在多种环境和上下文中充当智能体[29;[52],称为LLMs-as-Agents[23]。因此,我们在AgentBench上评估GLM-4和其他对比LLMs [23], AgentBench是基于文本的LLM在一系列实际环境中的综合性的智能体基准,涵盖代码、游戏和网页等多种实际环境。具体来说,我们在AgentBench的8个环境中评估了7个,除了数字纸牌游戏,它需要更长的时间来交互。总体得分是使用AgentBench[23]中提供的原始每个数据集权重计算的。 |
| The results are presented in Table 8. As it shows, GLM-4 models present quite impressive performance on agent tasks, with the GLM-4-Air’s comparable and GLM-4’s outperforming scores to GPT-4 Turbo and Claude 3 Opus. In terms of specific environments, we find GLM-4 series performing especially well on Database, House-Holding, and Web Shopping tasks, while still demonstrating a gap to GPT-4 series on Operating System, Knowledge Graph, and Lateral Thinking Puzzles. The gap indicates that there is still some room for GLM-4 to improve its performance on code-related agentic tasks and highly interactive language tasks. | 结果如表8所示。如图所示,GLM-4模型在智能体任务上表现出相当令人印象深刻的性能,GLM-4-Air的得分与GPT-4 Turbo和Claude 3 Opus相当,GLM-4的得分则优于它们。在具体环境方面,我们发现GLM-4系列在数据库、家务和网上购物任务中表现尤为出色,但在操作系统、知识图谱和侧向思维谜题任务中仍然与GPT-4系列存在差距。这表明GLM-4在代码相关智能体任务和高度互动语言任务上的表现还有提升空间。 |
Table 8: GLM-4 performance on AgentBench [23].
| Model | Operating System | DataBase | Knowledge Graph | Lateral Thinking | Puzzles | House Holding | Web Shopping | Web Browsing | Overall |
| GPT-4 (0613) | 42.4 | 32 | 58.8 | 16.6 | 78 | 61.1 | 29 | 3.69 | 3.69 |
| GPT-4 Turbo (1106) | 40.3 | 52.7 | 54 | 17.7 | 70 | 52.8 | 30 | 3.77 | 3.77 |
| GPT-4 Turbo (2024-04-09) | 41 | 46.7 | 53.2 | 19.4 | 72 | 55.1 | 19 | 3.68 | 3.68 |
| Claude 2 | 18.1 | 27.3 | 41.3 | 8.4 | 54 | 61.4 | 0 | 2.03 | 2.03 |
| Claude 3 Opus | 23.6 | 55 | 53.4 | 20 | 70 | 48.5 | 28 | 3.62 | 3.62 |
| GLM-4-Air (0605) | 31.9 | 51 | 53.8 | 12.3 | 78 | 69.2 | 30 | 3.58 | 3.58 |
| GLM-4 (0520) | 36.8 | 52.7 | 51.4 | 15.3 | 82 | 68.3 | 29 | 3.79 | 3.79 |
3.8 Evaluation of All Tools所有工具评估:实现复杂任务(自主理解意图+规划+调用多个工具)
| GLM-4 is further aligned to support intelligent agents and user self-configured GLMs functionalities on https://chatglm.cn, and the resultant model is GLM-4 All Tools. As mentioned, GLM-4 All Tools can complete complex tasks by autonomously understanding user intent, planing step-by-step instructions, and calling multiple tools, including web browser, Python interpreter, and the text-to-image model (e.g., CogView3 [59]. Table 9 shows that GLM-4 All Tools (Web) can generate similar performance on Python Interpreter for solving math problems, browser for information seeking, compared to ChatGPT-4 (Web), respectively. | GLM-4进一步对齐以支持在https://chatglm.cn上的智能体和用户自定义GLM功能,结果模型为GLM-4 All Tools。如前所述,GLM-4 All Tools可以通过自主理解用户意图、规划分步指令和调用多个工具来完成复杂的任务,包括web浏览器、Python解释器和文本到图像模型(如CogView3[59])。表9显示,与ChatGPT-4 (Web)相比,GLM-4 All Tools (Web)分别可以在Python解释器(用于解决数学问题)和浏览器(用于查找信息)上产生类似的性能。 |
Table 9: Performance of GLM-4 All Tools.

4 Safety and Risks安全与风险
| We are committed to ensuring that GLM-4 operates as a safe, responsible, and unbiased model. In addition to addressing common ethical and fairness concerns, we carefully assess and mitigate potential harms that the model may pose to users in real-world scenarios. | 我们致力于确保GLM-4作为一个安全、负责任和公正无偏见的模型运行。除了解决常见的伦理和公平性问题外,我们还仔细评估和减轻该模型在现实场景中可能对用户造成的潜在危害。 |
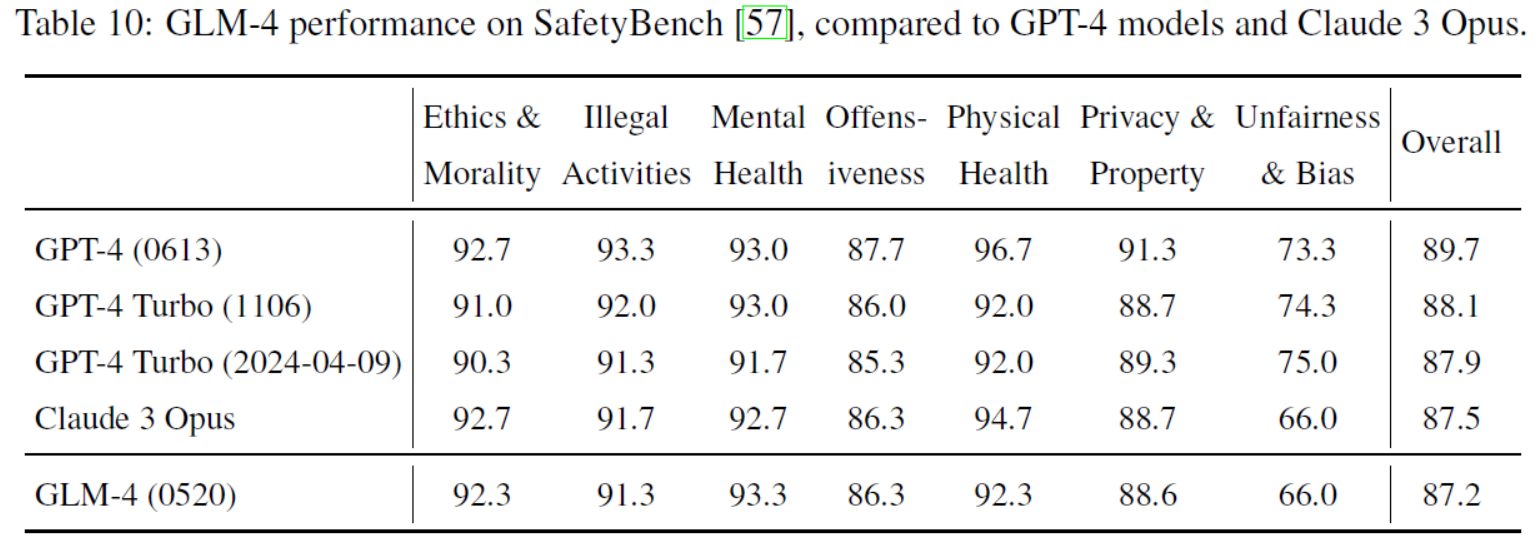
Table 10: GLM-4 performance on SafetyBench [57], compared to GPT-4 models and Claude 3 Opus.表10:GLM-4在SafetyBench上的性能[57],与GPT-4模型和Claude 3 Opus进行比较。
| Model | Ethics & Morality | Illegal Activities | Mental Health | Offensiveness | Physical Health | Privacy & Property | Unfairness & Bias | Overall |
| GPT-4 (0613) | 92.7 | 93.3 | 93 | 87.7 | 96.7 | 91.3 | 73.3 | 89.7 |
| GPT-4 Turbo (1106) | 91 | 92 | 93 | 86 | 92 | 88.7 | 74.3 | 88.1 |
| GPT-4 Turbo (2024-04-09) | 90.3 | 91.3 | 91.7 | 85.3 | 92 | 89.3 | 75 | 87.9 |
| Claude 3 Opus | 92.7 | 91.7 | 92.7 | 86.3 | 94.7 | 88.7 | 66 | 87.5 |
| GLM-4 (0520) | 92.3 | 91.3 | 93.3 | 86.3 | 92.3 | 88.6 | 66 | 87.2 |
4.1、Risk Mitigation风险缓解
两个阶段缓解:训练阶段(仔细清理数据=去除包含敏感关键词的文本和来自预定义黑名单的网页)、对齐阶段(评估每个训练样本的安全性→无害性)
采用红队策略:收集有害问答对+人工标注加以改进→进一步对齐模型
| Risk Mitigation. We carefully clean data in the pre-training stage by removing text containing sensitive keywords and web pages from a pre-defined blacklist. In the alignment phase, we evaluate each training sample for safety and remove any that pose potential risks. Harmlessness is also an important criteria for preference alignment when comparing multiple model outputs. We have a red team that constantly challenges the model with tricky questions that tend to cause unsafe answers. We collect all harmful question-answer pairs from GLM-4 and improve them with human annotations for further model alignment. | 风险缓解。我们在预训练阶段仔细清理数据,去除包含敏感关键词的文本和来自预定义黑名单的网页。在对齐阶段,我们评估每个训练样本的安全性,并删除任何可能带来潜在风险的样本。在比较多个模型输出时,无害性也是偏好对齐的重要标准。 我们有一个红队,不断向模型提出容易导致不安全回答的棘手问题。我们收集了GLM-4中所有有害的问答对,并通过人工标注加以改进,以进一步对齐模型。 |
4.2、Safety Evaluation安全性评估
利用SafetyBench的中文子集评估:七个维度包括伦理和道德(不道德行为)、非法活动(法律基础知识)、心理健康(对心理健康的不良影响)、冒犯性(攻击性行为)、身体健康(可能造成身体伤害的危险行为)、隐私与财产(隐私泄露或财产损失)、不公平和偏见
| Safety Evaluation. We evaluate the GLM-4 model on the SafetyBench [57] dataset, which assesses the capability of each model from 7 dimensions: Ethics and Morality (unethical behaviors), Illegal Activities (basic knowledge of law), Mental Health (adverse impacts on mental health), Offensiveness (offensive behaviors), Physical Health (dangerous behaviors that can cause physical harms), Privacy and Property (privacy breach or property loss), Unfairness and Bias. We evaluate different models on the Chinese subset of SafetyBench, which is created by removing highly sensitive questions that tend to be blocked, to mitigate interference from different API safety policies. | 我们在SafetyBench[57]数据集上对GLM-4模型进行了评估,该数据集从7个维度评估了每个模型的能力:伦理和道德(不道德行为)、非法活动(法律基础知识)、心理健康(对心理健康的不良影响)、冒犯性(攻击性行为)、身体健康(可能造成身体伤害的危险行为)、隐私与财产(隐私泄露或财产损失)、不公平和偏见。 我们在SafetyBench的中文子集上评估不同的模型,该子集通过删除容易被屏蔽的高度敏感问题来减轻不同API安全策略的干扰。 |
| Table 10 shows the safety results of GLM-4 and SOTA models. On most dimensions GLM-4 (0520) shows competitive safety performance, and overall it achieves comparable performance with Claude 3 Opus. GLM-4 slightly falls behind the GPT-4 family of models, especially on the Physical Health dimension, which demands robust common sense knowledge about the physical world to avoid potential risks. More efforts have been put into this direction to develop a more capable and safe GLM model. | 表10显示了GLM-4和SOTA模型的安全性结果。在大多数维度上,GLM-4(0520)显示出具有竞争力的安全性能,总体而言,它达到了与Claude 3 Opus相当的性能。GLM-4在物理健康维度上稍逊于GPT-4系列模型,该维度要求具有关于物理世界的强大常识以避免潜在风险。我们在这一方向上付出了更多努力,以开发更有能力和安全性的GLM模型。 |
5 Conclusion
| In this report, we introduce the ChatGLM family of large language models from GLM-130B to GLM- 4 (All Tools). Over the past one and half years, we have made great progress in understanding various perspectives of large language models from our first-hand experiences. With the development of each model generation, the team has learned and applied more effective and more efficient strategies for both model pre-training and alignment. The recent ChatGLM models—GLM-4 (0116, 0520), GLM-4-Air (0605), and GLM-4 All Tools—demonstrate significant advancements in understanding and executing complex tasks by autonomously employing external tools and functions. These GLM-4 models have achieved performance on par with, and in some cases superior to, state-of-the-art models such as GPT-4 Turbo, Claude 3 Opus, and Gemini 1.5 Pro, particularly in handling tasks relevant to the Chinese language. In addition, we are committed to promoting accessibility and safety of LLMs through open releasing our model weights and techniques developed throughout this journey. Our open models, including language, code, and vision models, have attracted over 10 million downloads on Hugging Face in the year 2023 alone. Currently, we are working on more capable models with everything we have learned to date. In the future, we will continue democratizing cutting-edge LLM technologies through open sourcing, and push the boundary of model capabilities towards the mission of teaching machines to think like humans. | 在本报告中,我们介绍了ChatGLM家族的大型语言模型,从GLM- 130B到GLM- 4 (All Tools)。在过去一年半的时间里,我们从第一手的经验出发,在理解大型语言模型的各个角度上取得了很大的进步。并且每一代模型的发展都使团队学到了并应用了更有效和更高效的模型预训练和对齐策略。 最近的ChatGLM模型——GLM-4(0116、0520)、GLM-4-Air(0605)和GLM-4 All tools——展示了通过自主使用外部工具和功能在理解和执行复杂任务方面的显著进步。这些GLM-4模型的性能与GPT-4 Turbo、Claude 3 Opus和Gemini 1.5 Pro等最先进的模型相当,在某些情况下甚至优于它们,特别是在处理与中文相关的任务方面。 此外,我们致力于通过开放发布我们的模型权重和在此过程中开发的技术来促进LLMs的可访问性和安全性。 我们的开源模型,包括语言、代码和视觉模型,在2023年仅在Hugging Face上就吸引了超过1000万次下载。目前,我们正在利用我们迄今为止学到的所有知识,致力于开发更强大的模型。未来,我们将继续通过开源推进尖端LLM技术的普及,并推动模型能力的边界,朝着教机器像人类一样思考的目标使命,迈进。 |



















 1211
1211

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











