









LLMs之Agent之vision-agent:vision-agent的简介、安装和使用方法、案例应用之详细攻略
目录
1、在 va.landing.ai 上尝试 Vision Agent 实时使用
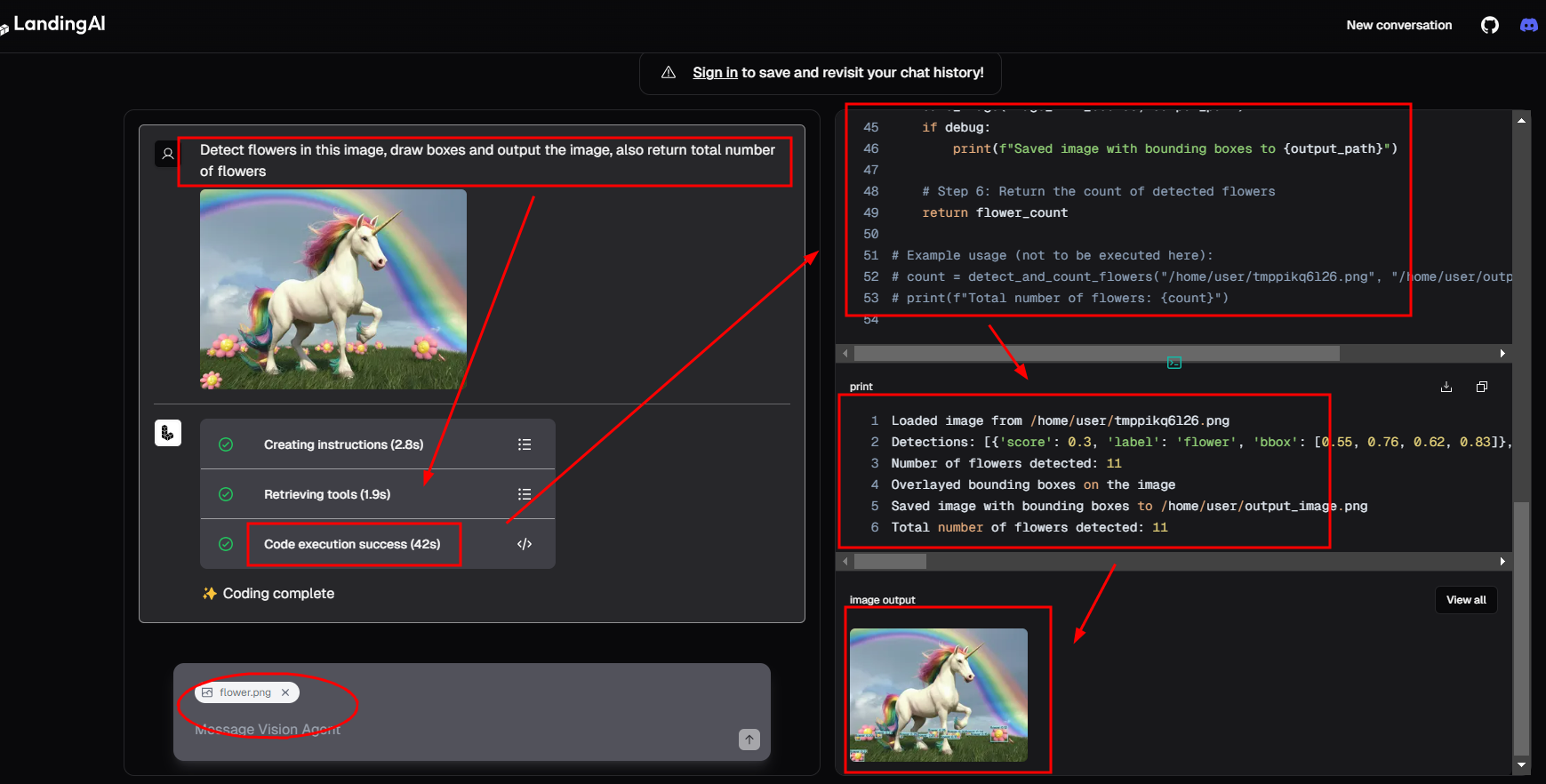
案例01:检测此图像中的花,绘制方框并输出图像,同时返回花的总数
vision-agent的简介
2024年6月6日,Andrew Ng在Snowflake活动上发布vision-agent。Vision Agent 是一个库,可以帮助您利用代理框架生成代码来解决视觉任务。许多当前的视觉问题需要数小时甚至数天才能解决,您需要找到合适的模型,弄清楚如何使用它并编程以完成您想要的任务。Vision Agent 旨在通过允许用户用文本描述他们的问题,并让代理框架生成解决任务的代码,提供几秒钟内的体验。
官方地址:GitHub - landing-ai/vision-agent: Vision agent
视频地址:https://www.youtube.com/watch?v=cJTvBBFb6Yo
vision-agent的安装和使用方法
1、安装
要开始使用,您可以使用 pip 安装该库:
pip install vision-agent确保您有一个 OpenAI API 密钥并将其设置为环境变量(如果您使用 Azure OpenAI,请参阅 Azure 设置部分):
export OPENAI_API_KEY="your-api-key"关于 API 使用的重要说明
请注意,使用此项目中的 API 需要您拥有 API 余额(至少五美元)。这与本聊天机器人使用的 OpenAI 订阅不同。如果您没有余额,请在此处找到更多信息
2、使用方法
2.1、基本使用
您可以像与任何 LLM 或 LMM 模型交互一样与代理交互:
>>> from vision_agent.agent import VisionAgent
>>> agent = VisionAgent()
>>> code = agent("What percentage of the area of the jar is filled with coffee beans?", media="jar.jpg")这会生成以下代码:
from vision_agent.tools import load_image, grounding_sam
def calculate_filled_percentage(image_path: str) -> float:
# Step 1: Load the image
image = load_image(image_path)
# Step 2: Segment the jar
jar_segments = grounding_sam(prompt="jar", image=image)
# Step 3: Segment the coffee beans
coffee_beans_segments = grounding_sam(prompt="coffee beans", image=image)
# Step 4: Calculate the area of the segmented jar
jar_area = 0
for segment in jar_segments:
jar_area += segment['mask'].sum()
# Step 5: Calculate the area of the segmented coffee beans
coffee_beans_area = 0
for segment in coffee_beans_segments:
coffee_beans_area += segment['mask'].sum()
# Step 6: Compute the percentage of the jar area that is filled with coffee beans
if jar_area == 0:
return 0.0 # To avoid division by zero
filled_percentage = (coffee_beans_area / jar_area) * 100
# Step 7: Return the computed percentage
return filled_percentage要更好地理解模型如何得出答案,您可以通过传入 verbose 参数以调试模式运行它:
>>> agent = VisionAgent(verbose=2)2.2、详细使用
您还可以通过调用 chat_with_workflow 返回更多信息。输入格式是一个包含键 role、content 和 media 的字典列表:
>>> results = agent.chat_with_workflow([{"role": "user", "content": "What percentage of the area of the jar is filled with coffee beans?", "media": ["jar.jpg"]}])
>>> print(results)
{
"code": "from vision_agent.tools import ..."
"test": "calculate_filled_percentage('jar.jpg')",
"test_result": "...",
"plan": [{"code": "...", "test": "...", "plan": "..."}, ...],
"working_memory": ...,
}通过这种方式,您可以检查更多详细信息,例如测试代码、测试结果、计划或它用来完成任务的工作记忆。
2.3、多轮对话
您还可以与 Vision Agent 进行多轮对话,向它反馈代码并进行更新。只需将代码作为助手的响应添加:
agent = va.agent.VisionAgent(verbosity=2)
conv = [
{
"role": "user",
"content": "Are these workers wearing safety gear? Output only a True or False value.",
"media": ["workers.png"],
}
]
result = agent.chat_with_workflow(conv)
code = result["code"]
conv.append({"role": "assistant", "content": code})
conv.append(
{
"role": "user",
"content": "Can you also return the number of workers wearing safety gear?",
}
)
result = agent.chat_with_workflow(conv)2.4、工具
模型或用户可以使用多种工具。有些是在本地执行的,有些是为您托管的。您还可以直接要求 LMM 为您构建工具。例如:
>>> import vision_agent as va
>>> llm = va.llm.OpenAILMM()
>>> detector = llm.generate_detector("Can you build a jar detector for me?")
>>> detector(va.tools.load_image("jar.jpg"))
[{"labels": ["jar",],
"scores": [0.99],
"bboxes": [
[0.58, 0.2, 0.72, 0.45],
]
}]您还可以为代理添加自定义工具:
import vision_agent as va
import numpy as np
@va.tools.register_tool(imports=["import numpy as np"])
def custom_tool(image_path: str) -> str:
"""My custom tool documentation.
Parameters:
image_path (str): The path to the image.
Returns:
str: The result of the tool.
Example
-------
>>> custom_tool("image.jpg")
"""
return np.zeros((10, 10))您需要确保调用 @va.tools.register_tool 并包含它可能使用的任何导入,并确保文档格式与上述相同,包括描述、参数、返回值和示例。您可以在此处找到一个用例示例。
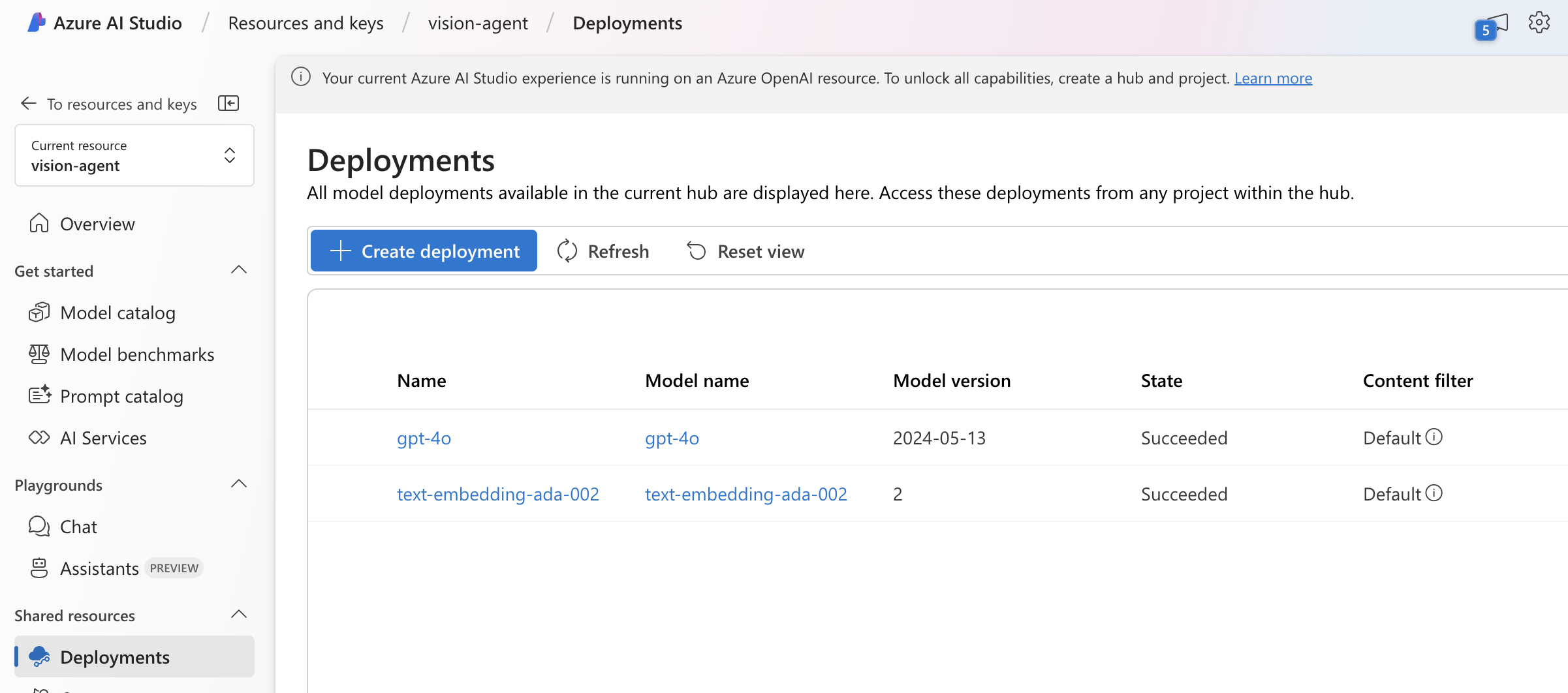
3、Azure 设置
如果您想使用 Azure OpenAI 模型,您需要有两个 OpenAI 模型部署:
OpenAI GPT-4o 模型
OpenAI 文本嵌入模型
然后您可以设置以下环境变量:
export AZURE_OPENAI_API_KEY="your-api-key"
export AZURE_OPENAI_ENDPOINT="your-endpoint"
# The deployment name of your Azure OpenAI chat model
export AZURE_OPENAI_CHAT_MODEL_DEPLOYMENT_NAME="your_gpt4o_model_deployment_name"
# The deployment name of your Azure OpenAI text embedding model
export AZURE_OPENAI_EMBEDDING_MODEL_DEPLOYMENT_NAME="your_embedding_model_deployment_name"注意:确保您的 Azure 模型部署有足够的配额(每分钟的令牌数)以支持它。默认值 8000 TPM 是不够的。
然后您可以使用 Azure OpenAI 模型运行 Vision Agent:
import vision_agent as va
agent = va.agent.AzureVisionAgent()4、问答
如何开始使用 OpenAI API 余额
访问 OpenAI API 平台以注册 API 密钥。
按照说明购买和管理您的 API 余额。
确保您的 API 密钥在项目设置中正确配置。
如果没有足够的 API 余额,可能会导致依赖 OpenAI API 的功能受到限制或无法使用。
有关管理您的 API 使用和余额的更多详细信息,请参阅 OpenAI API 文档。
vision-agent的案例应用
持续更新中……
1、在 va.landing.ai 上尝试 Vision Agent 实时使用
地址:Vision Agent
案例01:检测此图像中的花,绘制方框并输出图像,同时返回花的总数



















 405
405

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











