







LLMs之Qwen-2:《Qwen2.5 Technical Report》翻译与解读
导读:2024年 12月19日,Qwen团队介绍了Qwen2.5,一系列旨在满足多种需求的大型语言模型 (LLM)。Qwen2.5 代表了大型语言模型发展的一个重要里程碑,其强大的性能、丰富的模型选择和开源特性使其成为学术研究和工业应用的宝贵资源。未来研究将集中在改进基础模型的鲁棒性、开发多模态模型和增强模型的推理能力等方面。
>> 背景痛点:
● 模型能力提升的瓶颈:虽然大型基础模型,特别是大型语言模型 (LLM) 发展迅速,但在模型和数据规模化方面仍存在提升空间,尤其是在常识、专业知识和推理能力方面。现有模型在长文本生成、结构化数据分析和指令遵循方面也存在不足。
● 开源模型的局限性:开源大型语言模型虽然 democratized (民主化)了 LLM 的访问,但许多开源模型在不同参数规模上的覆盖不够全面,尤其缺乏在资源受限场景下更具成本效益的中等规模模型。
>> 具体的解决方案:Qwen2.5 通过在预训练和后训练阶段进行显著改进,来解决上述痛点:
● 扩大高质量预训练数据集:将预训练数据从之前的 7 万亿 tokens 扩展到 18 万亿 tokens,并特别关注知识、编码和数学领域的数据。
● 改进后训练技术:采用复杂的监督微调 (SFT) 技术,使用超过 100 万个样本,并结合离线学习 (DPO) 和在线学习 (GRPO) 的多阶段强化学习,显著提升了模型对人类偏好的对齐程度,并改进了长文本生成、结构化数据分析和指令遵循能力。
● 提供丰富的模型配置:发布了包含 0.5B、1.5B、3B、7B、14B、32B 和 72B 参数量的基础模型和指令微调模型,以及量化版本,总计超过 100 个模型,并通过 Hugging Face Hub、ModelScope 和 Kaggle 等平台提供访问。此外,还提供了专有的混合专家 (MoE) 模型 Qwen2.5-Turbo 和 Qwen2.5-Plus,可在阿里云模型工作室访问。
>> 核心思路步骤:
● 分阶段预训练:采用多阶段预训练策略,在不同数据混合之间进行过渡,并对超参数进行优化。
● 数据质量控制:使用 Qwen2-Instruct 模型进行数据质量过滤,并通过策略性地混合数据,平衡不同领域的数据分布,减少过拟合。
● 长文本预训练:采用两阶段预训练方法,先用 4096 tokens 的上下文长度进行训练,然后扩展到更长的序列(32768 tokens,Qwen2.5-Turbo 扩展到 262144 tokens),并使用 YARN 和 DCA 技术提高推理效率,Qwen2.5-Turbo 最终支持百万 tokens 的上下文长度。
● 多阶段后训练:包含监督微调 (SFT)、离线强化学习 (DPO) 和在线强化学习 (GRPO) 三个阶段,分别针对不同类型的任务和能力进行优化。SFT 阶段特别关注长序列生成、数学、编码、指令遵循、结构化数据理解、逻辑推理和跨语言迁移等方面。
● 奖励模型训练:使用精心设计的标注标准(真实性、帮助性、简洁性、相关性、无害性和去偏见),训练奖励模型,用于引导在线强化学习。
>> 优势:
● 强大的性能:在各种基准测试中表现出色,旗舰模型 Qwen2.5-72B-Instruct 的性能与 Llama-3-405B-Instruct(参数量约为其 5 倍)相当,甚至在某些方面超越。Qwen2.5-Turbo 和 Qwen2.5-Plus 在成本效益方面也具有优势。
● 丰富的模型选择:提供多种参数规模的模型,满足不同场景的需求,包括资源受限的边缘设备。
● 多语言支持:在多种语言上都表现良好,并进行了专门的多语言评估。
● 长上下文处理能力:通过长上下文预训练和推理优化技术,显著提升了长文本处理能力,Qwen2.5-Turbo 支持百万 tokens 的上下文长度。
● 开源和易用性:提供了大量开源模型,并支持 Hugging Face Transformers 等框架,方便用户使用和微调。
>> 结论和观点:
● Qwen2.5 在多个方面都取得了显著的改进,在性能、成本效益和模型选择方面都具有竞争力。
● 大规模高质量数据对于提升 LLM 性能至关重要。
● 多阶段强化学习能够有效地提升模型与人类偏好的对齐程度。
● 长上下文处理能力是未来 LLM 发展的重要方向。
● 需要开发更有效的奖励模型评估方法,以更好地预测 RL 模型的性能。
● Qwen2.5 不仅是一个强大的语言模型,也为其他专用模型的训练提供了基础。
目录
《Qwen2.5 Technical Report》翻译与解读
《Qwen2.5 Technical Report》翻译与解读
| 地址 | |
| 时间 | 2024年 12月19日 |
| 作者 | Qwen Team |
Abstract
| In this report, we introduce Qwen2.5, a comprehensive series of large language models (LLMs) designed to meet diverse needs. Compared to previous iterations, Qwen 2.5 has been significantly improved during both the pre-training and post-training stages. In terms of pre-training, we have scaled the high-quality pre-training datasets from the previous 7 trillion tokens to 18 trillion tokens. This provides a strong foundation for common sense, expert knowledge, and reasoning capabilities. In terms of post-training, we implement intricate supervised finetuning with over 1 million samples, as well as multistage reinforcement learning. Post-training techniques enhance human preference, and notably improve long text generation, structural data analysis, and instruction following. To handle diverse and varied use cases effectively, we present Qwen2.5 LLM series in rich sizes. Open-weight offerings include base and instruction-tuned models, with quantized versions available. In addition, for hosted solutions, the proprietary models currently include two mixture-of-experts (MoE) variants: Qwen2.5-Turbo and Qwen2.5-Plus, both available from Alibaba Cloud Model Studio. Qwen2.5 has demonstrated top-tier performance on a wide range of benchmarks evaluating language understanding, reasoning, mathematics, coding, human preference alignment, etc. Specifically, the open-weight flagship Qwen2.5-72B-Instruct outperforms a number of open and proprietary models and demonstrates competitive performance to the state-of-the-art open-weight model, Llama-3-405B-Instruct, which is around 5 times larger. Qwen2.5-Turbo and Qwen2.5-Plus offer superior cost-effectiveness while performing competitively against GPT-4o-mini and GPT-4o respectively. Additionally, as the foundation, Qwen2.5 models have been instrumental in training specialized models such as Qwen2.5-Math, Qwen2.5-Coder, QwQ, and multimodal models. | 在本报告中,我们介绍了 Qwen2.5,这是一系列全面的大型语言模型(LLM),旨在满足各种需求。与之前的版本相比,Qwen 2.5 在预训练和后训练阶段都有了显著的改进。在预训练方面,我们将高质量的预训练数据集从之前的 7 万亿个标记扩展到了 18 万亿个标记。这为常识、专业知识和推理能力奠定了坚实的基础。在后训练方面,我们实施了复杂的监督微调,使用了超过 100 万个样本,并采用了多阶段强化学习。后训练技术增强了人类偏好,并显著提高了长文本生成、结构化数据分析和指令遵循的能力。为了有效处理多样化的用例,我们提供了 Qwen2.5 LLM 系列的丰富规模。开源版本包括基础模型和指令调优模型,还有量化版本可供选择。此外,对于托管解决方案,专有模型目前包括两个专家混合(MoE)变体:Qwen2.5-Turbo 和 Qwen2.5-Plus,均可从阿里云模型工作室获取。Qwen2.5 在评估语言理解、推理、数学、编程、人类偏好对齐等广泛基准测试中展现出了顶级性能。具体而言,开放权重的旗舰版 Qwen2.5-72B-Instruct 超过了众多开源和专有模型,并且在性能上与规模约大五倍的最先进的开放权重模型 Llama-3-405B-Instruct 相当。Qwen2.5-Turbo 和 Qwen2.5-Plus 在成本效益方面表现出色,同时在性能上分别与 GPT-4o-mini 和 GPT-4o 竞争力相当。此外,作为基础模型,Qwen2.5 系列在训练诸如 Qwen2.5-Math、Qwen2.5-Coder、QwQ 以及多模态模型等专业模型方面发挥了重要作用。 |
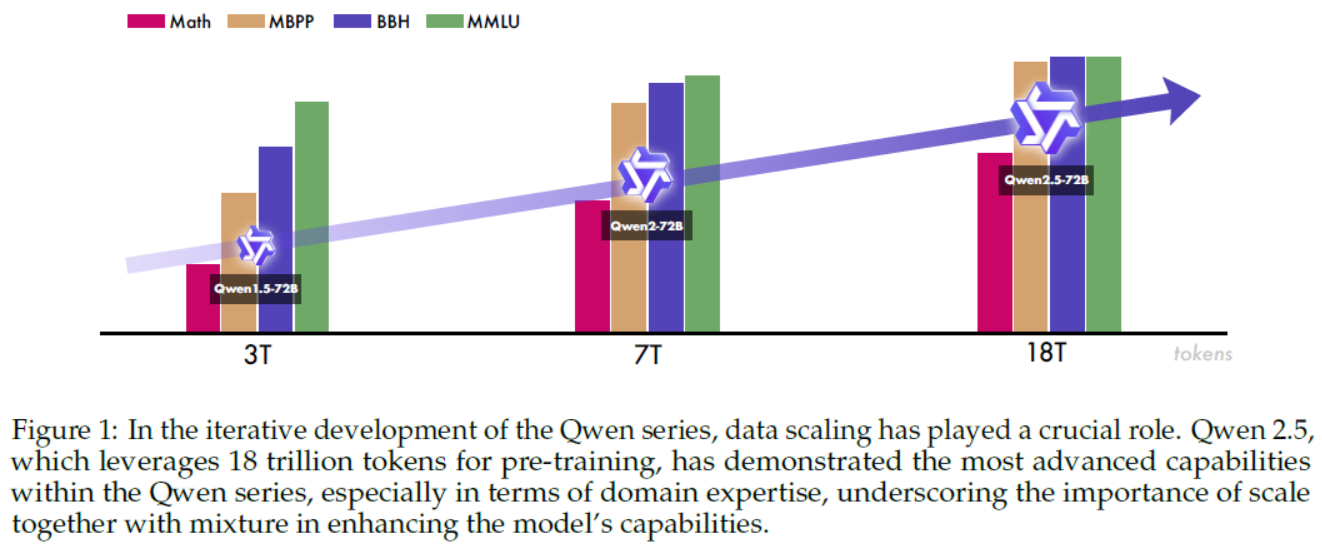
Figure 1: In the iterative development of the Qwen series, data scaling has played a crucial role. Qwen 2.5, which leverages 18 trillion tokens for pre-training, has demonstrated the most advanced capabilities within the Qwen series, especially in terms of domain expertise, underscoring the importance of scale together with mixture in enhancing the model’s capabilities.图 1:在 Qwen 系列的迭代开发过程中,数据规模发挥了关键作用。Qwen 2.5 利用 18 万亿个标记进行预训练,在 Qwen 系列中展现出了最先进的能力,尤其是在领域专业知识方面,这突显了规模与混合在提升模型能力方面的重要性。
1 Introduction
| The sparks of artificial general intelligence (AGI) are increasingly visible through the fast development of large foundation models, notably large language models (LLMs) (Brown et al., 2020; OpenAI, 2023; 2024a; Gemini Team, 2024; Anthropic, 2023a;b; 2024; Bai et al., 2023; Yang et al., 2024a; Touvron et al., 2023a;b; Dubey et al., 2024). The continuous advancement in model and data scaling, combined with the paradigm of large-scale pre-training followed by high-quality supervised fine-tuning (SFT) and reinforcement learning from human feedback (RLHF) (Ouyang et al., 2022), has enabled large language models (LLMs) to develop emergent capabilities in language understanding, generation, and reasoning. Building on this foundation, recent breakthroughs in inference time scaling, particularly demonstrated by o1 (OpenAI, 2024b), have enhanced LLMs’ capacity for deep thinking through step-by-step reasoning and reflection. These developments have elevated the potential of language models, suggesting they may achieve significant breakthroughs in scientific exploration as they continue to demonstrate emergent capabilities indicative of more general artificial intelligence. Besides the fast development of model capabilities, the recent two years have witnessed a burst of open (open-weight) large language models in the LLM community, for example, the Llama series (Touvron et al., 2023a;b; Dubey et al., 2024), Mistral series (Jiang et al., 2023a; 2024), and our Qwen series (Bai et al., 2023; Yang et al., 2024a; Qwen Team, 2024a; Hui et al., 2024; Qwen Team, 2024c; Yang et al., 2024b). The open-weight models have democratized the access of large language models to common users and developers, enabling broader research participation, fostering innovation through community collaboration, and accelerating the development of AI applications across diverse domains. | 随着大型基础模型,尤其是大型语言模型(LLMs)(Brown 等人,2020 年;OpenAI,2023 年;2024 年 a;Gemini 团队,2024 年;Anthropic,2023 年 a;b;2024 年;Bai 等人,2023 年;Yang 等人,2024 年 a;Touvron 等人,2023 年 a;b;Dubey 等人,2024 年)的快速发展,通用人工智能(AGI)的火花愈发明显。模型和数据规模的持续扩大,加上大规模预训练后进行高质量监督微调(SFT)和基于人类反馈的强化学习(RLHF)(Ouyang 等人,2022 年)这一范式,使大型语言模型(LLMs)在语言理解、生成和推理方面展现出新兴能力。在此基础上,近期在推理时间缩放方面的突破,特别是 o1(OpenAI,2024 年 b)所展示的成果,增强了 LLMs 通过逐步推理和反思进行深度思考的能力。这些发展提升了语言模型的潜力,表明它们在继续展现更广泛的人工智能迹象时,可能在科学探索方面取得重大突破。除了模型能力的快速发展之外,近来两年在大型语言模型(LLM)领域还涌现出了大量开源(开放权重)的大型语言模型,例如 Llama 系列(Touvron 等人,2023a;b;Dubey 等人,2024)、Mistral 系列(Jiang 等人,2023a;2024)以及我们的 Qwen 系列(Bai 等人,2023;Yang 等人,2024a;Qwen 团队,2024a;Hui 等人,2024;Qwen 团队,2024c;Yang 等人,2024b)。开放权重模型使大型语言模型能够为普通用户和开发者所用,促进了更广泛的研究参与,通过社区协作推动创新,并加速了人工智能在各个领域的应用发展。 |
| Recently, we release the details of our latest version of the Qwen series, Qwen2.5. In terms of the open-weight part, we release pre-trained and instruction-tuned models of 7 sizes, including 0.5B, 1.5B, 3B, 7B, 14B, 32B, and 72B, and we provide not only the original models in bfloat16 precision but also the quantized models in different precisions. Specifically, the flagship model Qwen2.5-72B-Instruct demonstrates competitive performance against the state-of-the-art open-weight model, Llama-3-405B-Instruct, which is around 5 times larger. Additionally, we also release the proprietary models of Mixture-of-Experts (MoE, Lepikhin et al., 2020; Fedus et al., 2022; Zoph et al., 2022), namely Qwen2.5-Turbo and Qwen2.5-Plus1, which performs competitively against GPT-4o-mini and GPT-4o respectively. | 最近,我们发布了 Qwen 系列的最新版本 Qwen2.5 的详细信息。在开放权重部分,我们发布了 7 种不同规模的预训练和指令微调模型,包括 0.5B、1.5B、3B、7B、14B、32B 和 72B,不仅提供了原始的 bfloat16 精度模型,还提供了不同精度的量化模型。具体而言,旗舰型号 Qwen2.5-72B-Instruct 在性能上与最先进的开源模型 Llama-3-405B-Instruct 相当,而 Llama-3-405B-Instruct 的规模约为其 5 倍。此外,我们还发布了专家混合模型(MoE,Lepikhin 等人,2020 年;Fedus 等人,2022 年;Zoph 等人,2022 年)的专有模型,即 Qwen2.5-Turbo 和 Qwen2.5-Plus1,它们在性能上与 GPT-4o-mini 和 GPT-4o 相当。 |
| In this technical report, we introduce Qwen2.5, the result of our continuous endeavor to create better LLMs. Below, we show the key features of the latest version of Qwen: >> Better in Size: Compared with Qwen2, in addition to 0.5B, 1.5B, 7B, and 72B models, Qwen2.5 brings back the 3B, 14B, and 32B models, which are more cost-effective for resource-limited scenarios and are under-represented in the current field of open foundation models. Qwen2.5-Turbo and Qwen2.5-Plus offer a great balance among accuracy, latency, and cost. >> Better in Data: The pre-training and post-training data have been improved significantly. The pre-training data increased from 7 trillion tokens to 18 trillion tokens, with focus on knowledge, coding, and mathematics. The pre-training is staged to allow transitions among different mixtures. The post-training data amounts to 1 million examples, across the stage of supervised finetuning (SFT, Ouyang et al., 2022), direct preference optimization (DPO, Rafailov et al., 2023), and group relative policy optimization (GRPO, Shao et al., 2024). >> Better in Use: Several key limitations of Qwen2 in use have been eliminated, including larger generation length (from 2K tokens to 8K tokens), better support for structured input and output,(e.g., tables and JSON), and easier tool use. In addition, Qwen2.5-Turbo supports a context length of up to 1 million tokens. | 在这份技术报告中,我们介绍了 Qwen2.5,这是我们在打造更优大型语言模型方面持续努力的成果。以下是 Qwen 最新版本的关键特性: >> 更优的规模:与 Qwen2 相比,除了 0.5B、1.5B、7B 和 72B 模型外,Qwen2.5 还重新引入了 3B、14B 和 32B 模型,这些模型在资源有限的场景中更具成本效益,且在当前开源基础模型领域中代表性不足。Qwen2.5-Turbo 和 Qwen2.5-Plus 在准确率、延迟和成本之间实现了很好的平衡。 >> 更优的数据:预训练和后训练数据得到了显著改进。预训练数据从 7 万亿个标记增加到 18 万亿个标记,重点在于知识、编程和数学领域。预训练分阶段进行,以实现不同混合数据集之间的转换。后训练数据量达 100 万例,涵盖了监督微调(SFT,Ouyang 等人,2022 年)、直接偏好优化(DPO,Rafailov 等人,2023 年)和组相对策略优化(GRPO,Shao 等人,2024 年)阶段。 >> 实用性更强:Qwen2 在实际使用中的几个关键限制已被消除,包括生成长度更大(从 2000 个标记增加到 8000 个标记)、对结构化输入和输出的支持更好(例如表格和 JSON),以及工具使用更简便。此外,Qwen2.5-Turbo 支持长达 100 万个标记的上下文长度。 |
Conclusion
| Qwen2.5 represents a significant advancement in large language models (LLMs), with enhanced pre-training on 18 trillion tokens and sophisticated post-training techniques, including supervised fine-tuning and multi-stage reinforcement learning. These improvements boost human preference alignment, long text generation, and structural data analysis, making Qwen2.5 highly effective for instruction-following tasks. Available in various configurations, Qwen2.5 offers both open-weight from 0.5B to 72B parameters and proprietary models including cost-effective MoE variants like Qwen2.5-Turbo and Qwen2.5-Plus. Empirical evaluations show that Qwen2.5-72B-Instruct matches the performance of the state-of-the-art Llama-3-405B-Instruct, despite being six times smaller. Qwen2.5 also serves as a foundation for specialized models, demonstrating its versatility for domain-specific applications. We believe that Qwen2.5’s robust performance, flexible architecture, and broad availability make it a valuable resource for both academic research and industrial applications, positioning it as a key player of future innovations. | Qwen2.5 在大型语言模型(LLM)领域取得了重大进展,其在 18 万亿个标记上进行了增强的预训练,并采用了包括监督微调和多阶段强化学习在内的复杂后训练技术。这些改进提升了与人类偏好的一致性、长文本生成能力和结构化数据分析能力,使 Qwen2.5 在指令遵循任务中表现出色。Qwen2.5 提供了多种配置,包括从 0.5B 到 72B 参数的开放权重以及专有模型,如经济高效的 MoE 变体 Qwen2.5-Turbo 和 Qwen2.5-Plus。实证评估表明,尽管 Qwen2.5-72B-Instruct 的规模只有最先进的 Llama-3-405B-Instruct 的六分之一,但其性能却与之相当。Qwen2.5 还是专门化模型的基础,展示了其在特定领域应用中的灵活性。我们认为,Qwen2.5 出色的性能、灵活的架构和广泛的可用性使其成为学术研究和工业应用的宝贵资源,使其成为未来创新的关键参与者。 |
| In the future, we will focus on advancing robust foundational models. First, we will iteratively refine both base and instruction-tuned large language models (LLMs) by incorporating broader, more diverse, higher-quality data. Second, we will also continue to develop multimodal models. Our goal is to integrate various modalities into a unified framework. This will facilitate seamless, end-to-end information processing across textual, visual, and auditory domains. Third, we are committed to enhancing the reasoning capabilities of our models. This will be achieved through strategic scaling of inference compute resources. These efforts aim to push the boundaries of current technological limitations and contribute to the broader field of artificial intelligence. | 未来,我们将专注于推进强大的基础模型的发展。首先,我们将通过纳入更广泛、更多样化、更高质量的数据,对基础语言模型和指令微调的大规模语言模型(LLM)进行迭代优化。其次,我们还将继续开发多模态模型。我们的目标是将各种模态整合到一个统一的框架中。这将有助于实现文本、视觉和听觉领域无缝、端到端的信息处理。第三,我们致力于提升模型的推理能力。这将通过战略性地扩大推理计算资源来实现。这些努力旨在突破当前的技术限制,并为更广泛的人工智能领域做出贡献。 |



















 1102
1102

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











