







衡量基因相对表达量的RPKM和FPKM、及TPM
1.RPKM(Reads Per Kilobase per Million)和FPKM(Fragments Per Kilobase per Million)
1.引入“每一千碱基(per kilobase)”的原因在于,不同的RNA可能有不同长度,长度越长,对应的reads就越多。当每个RNA都除以自身长度(以1000碱基,即kb为单位)时,就可以比较同一个样本中不同基因的相对表达量了。
2.引入“每一百万reads”的原因是,不同的样本可能测序的深度不一样,深度越深,当然对应的reads就越多了。如果结果除以各自库的数量(以一百万reads为单位),那么我们就能很好地衡量两个不同样本中同一个基因的相对表达量。
计算方法
第一步先将测序深度标准化,计算方法很简单,先分别计算出每个样本的总reads数,然后将表中数据分别除以总reads数即可,这样就得到了reads per million。
第二步是基因长度的标准化。将第一步的read per million直接除以基因长度即可。
FPKM和RPKM的定义是相同的,唯一的区别是FPKM适用于双端测序文库,而RPKM适用于单端测序文库。是衡量基因相对表达量的一个公式,
RPKM是将Map到基因的Reads数除以Map到Genome的所有Read数(以Million为单位)与RNA的长度(以KB为单位),是衡量基因相对表达量的一个公式,适用于单端测序
FPKM是将Map到基因的Fragments数除以Map到Genome的所有Read数(以Million为单位)与RNA的长度(以KB为单位)。适用于单端和双端测序。
它们2者的不同:
在single-end(单端测序)测序中,FPKM将read当做fragment计算,此时FPKM和RPKM是相同的。
而在pair-end(双端测序)测序 中, 若一堆paired-read 都比对上了,当做一个fragment。
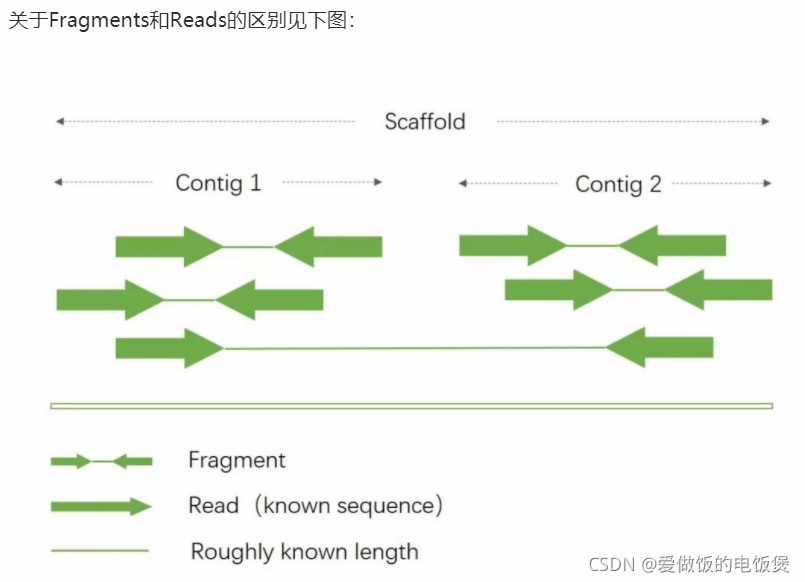
TPM:Transcripts Per Kilobase per Million mapped reads (每千个碱基的转录每百万映射读取的Transcripts):它先对每个基因的read数用基因的长度进行校正,之后再用校正后的这个基因read数(nr/Lr)与校正后的这个样本的所有校正后的read数(sum( nr/Lr+………+ nm/Lm ))求商,是衡量基因相对表达量的一个手段
TPM的出现:
TPM的不同在于它的处理顺序是不同的。即先考虑基因长度,再考虑测序深度。
它的好处是,上边FPKM:
FPKM = (10^6 * nf) / (L * N)
其中:
nf 代表比对至目标基因的fragment数量;
L代表目标基因的外显子长度之和除以1000,单位是Kb;
N是总的有效比对至基因组的fragment数量。
FPKM中N同样会受到各个转录基因长度(distribution of transcript lengths)的影响,也就是说:FPKM/RPKM是不准确的。而TPM在一个样本中一个基因的TPM:先对每个基因的read数用基因的长度进行校正,之后再用校正后的这个基因read数(nr/Lr)与校正后的这个样本的所有校正后的read数(sum( nr/Lr+………+ nm/Lm ))求商。TPM除以经过基因长度归一化后的有效比对的read总数,即归一化后的测序深度。
————————————————
杨梦磊
20211024


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











