








显著性目标检测(SOD):旨在模拟人类视觉系统,通过自动分析图像或视频中最吸引注意力的区域或目标。
RGB-D:是指结合红绿蓝(RGB)图像和深度(D)图像的一种技术。在RGB-D中,RGB图像提供了颜色信息,而深度图像则提供了场景中物体的距离信息。这两个信息源可以相互补充,为计算机视觉和机器人领域的各种任务提供更丰富的数据。
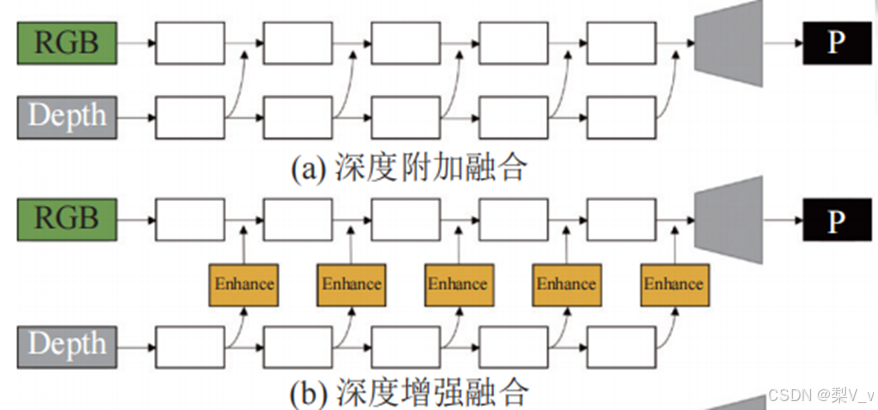
(a)利用一个独立的子网络来提取深度特征, 然后将这些特征直接合并到 RGB 特征中 。
(b)从通道和空间注意力中挖掘深度信息线索, 然后将深度信息以辅助方式融合进 RGB 特征中。
然而,大多数融合策略并未实现深度特征与 RGB 特征的双向交互,导致 SOD 在一些深度特征较差的情况下所取得的检测效果并不理想。而且现有的 CNN 方法主要通过增大感受野的方式以获取全局信息, 这种操作会导致图像分辨率下降以及大量语义信息丢失。
它提出了一种新的基于跨模态交互融合与全局感知的 RGB-D 显著性目标检测方法。
基于 CNN-Transformer 的模型框架图
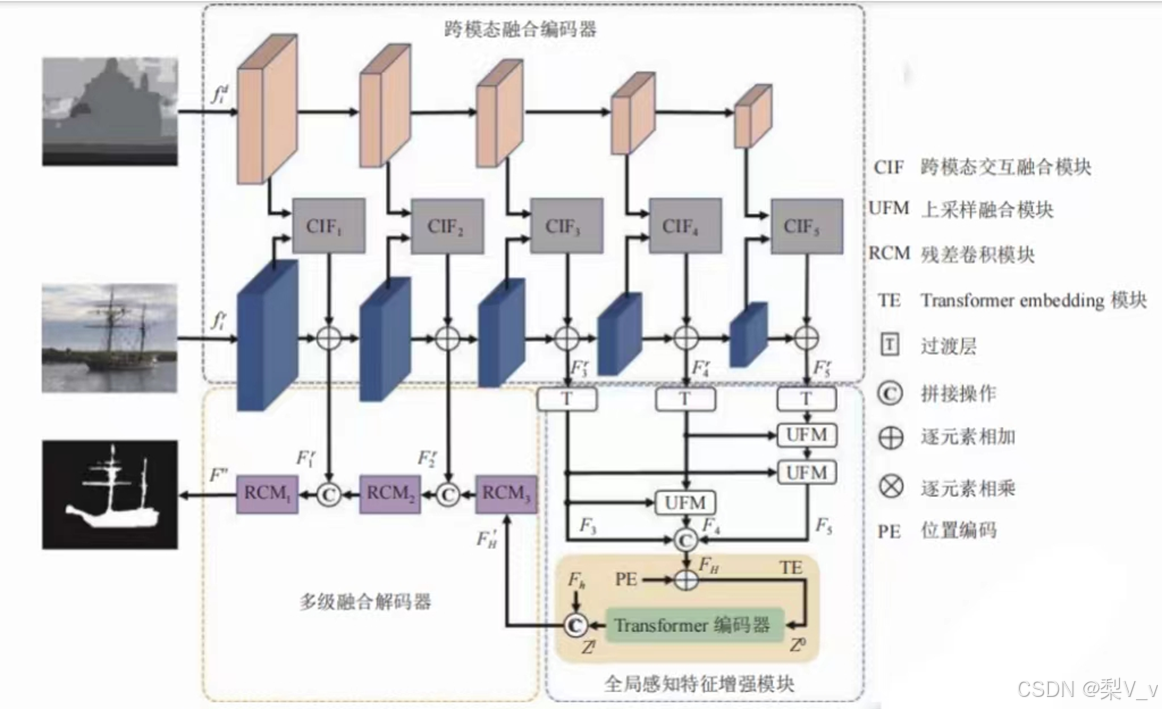
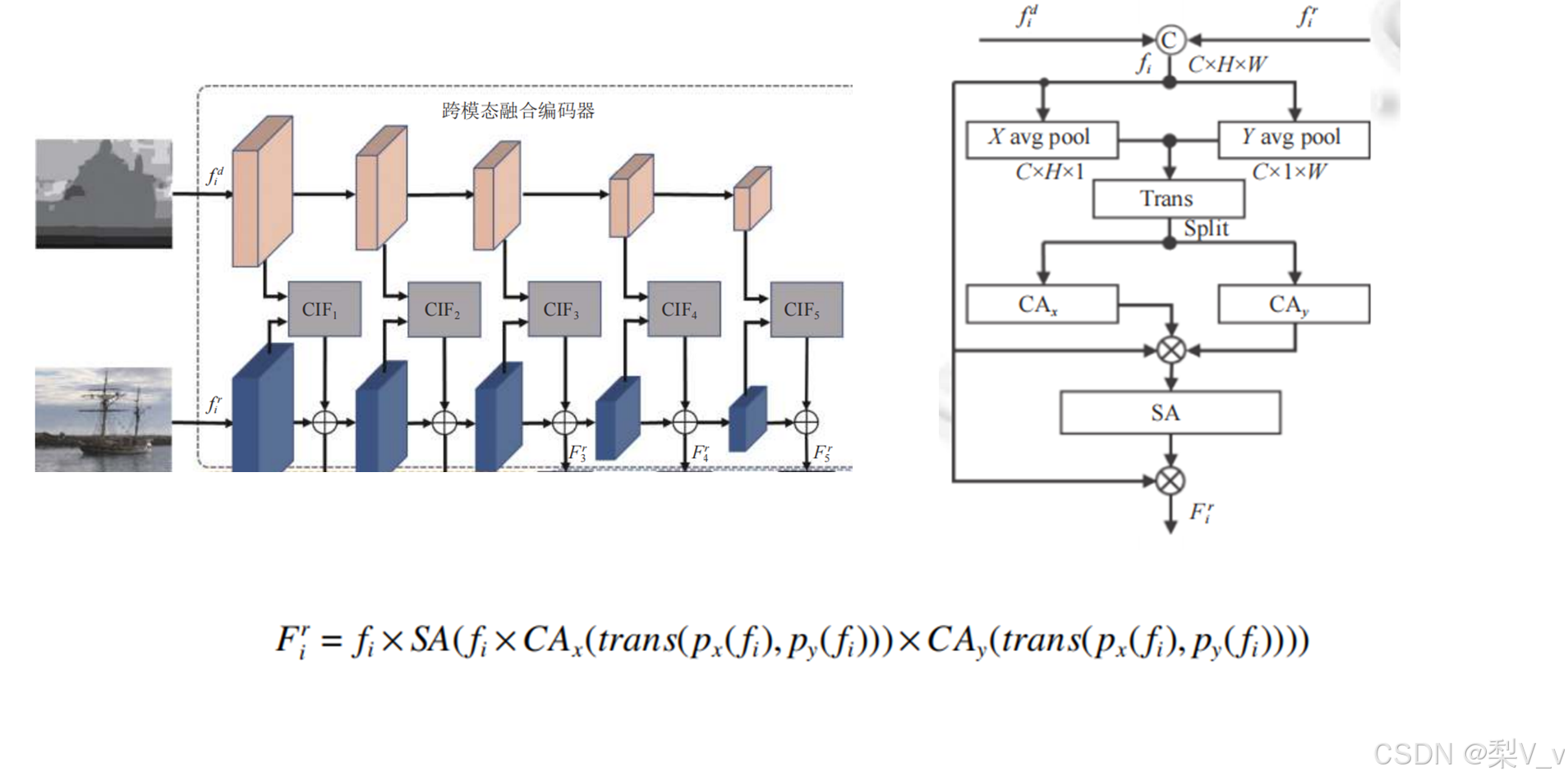
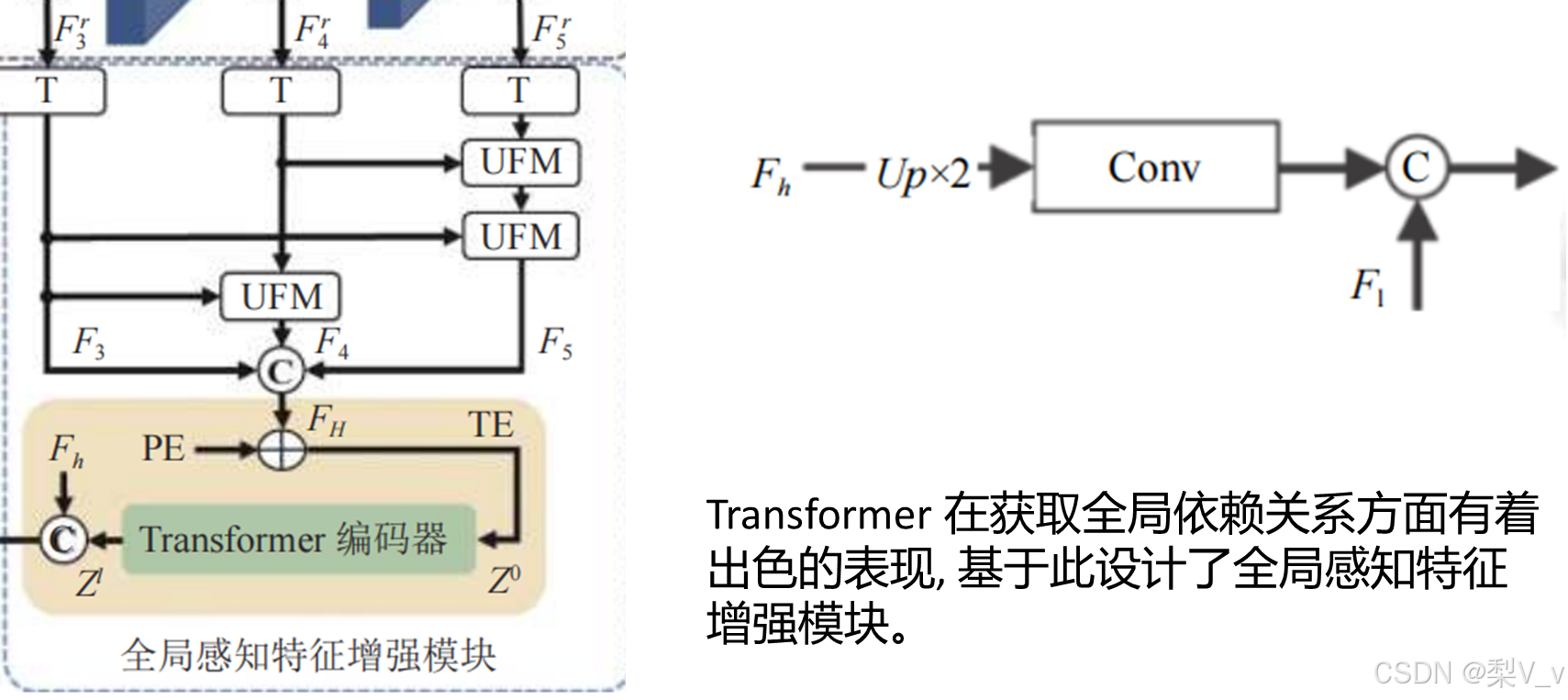
我们针对 RGB-D 显著目标检测如何更好地挖掘局部和全局信息的问题,从 CNN 和 Transformer 各自的优势及局限性出发将 Transformer 与 U-Net 框架相结合,设计了一个新的 RGB-D 显著目标检测框架.我们利用跨模态交互融合模块对深度特征和 RGB 特征进行互补融合,并利用 Transformer 全局感知特征增强模块学习不同层级高级特征间的长距离依赖关系以增强特征表示,此外,设计了多级融合解码器以实现显著特征图的精确生成。
跨模态融合编码器
全局感知特征增强模块
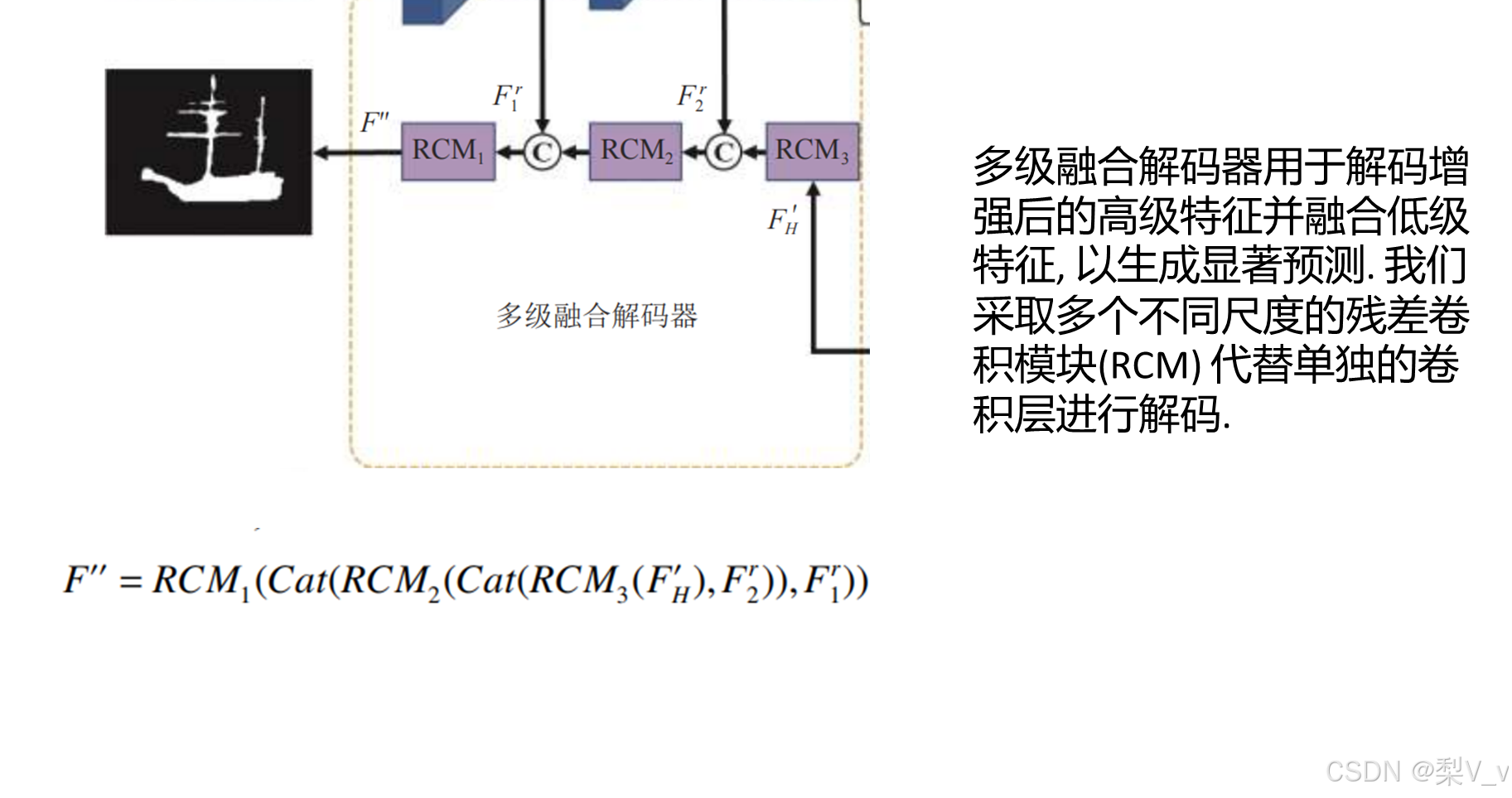
多级融合解码器
实验结果
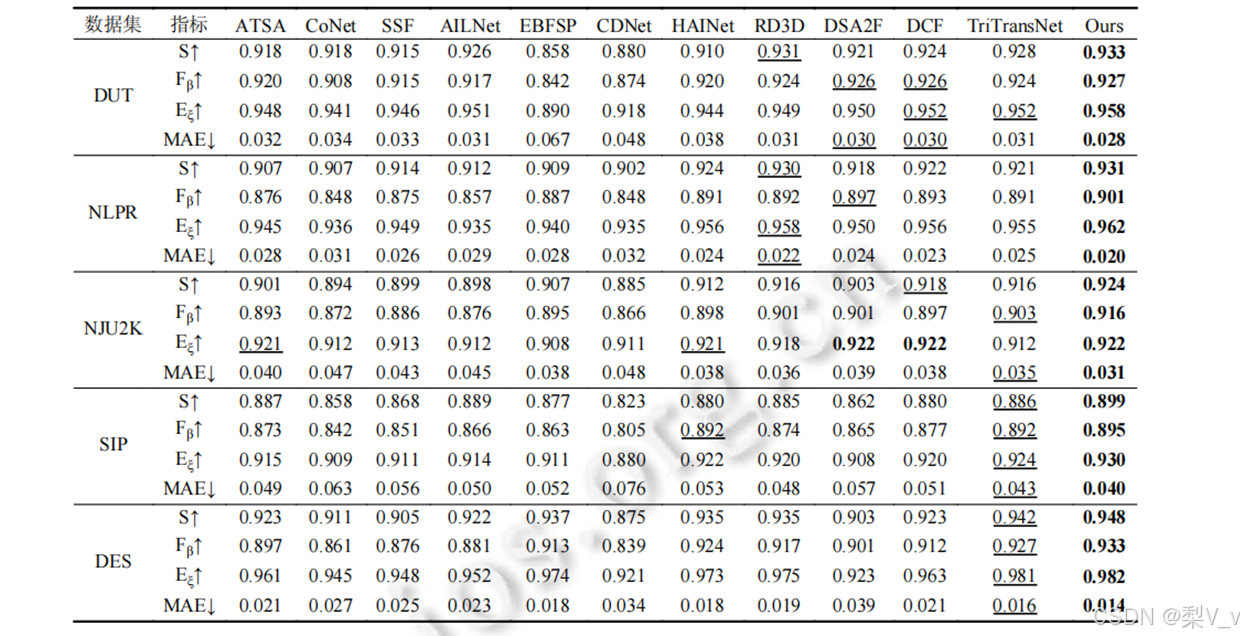
数据集:DUT包含 Lytro 相机在现实生活场景中捕获的1200张图像; NLPR包括具有单个或多个显著对象的1000 张图像; NJU2K包括2003张不同分辨率的立体图像; SIP包含1000 幅突出人物的高分辨率图像; DES包含135幅由微软 Kinect 采集的室内图像.
评价指标:E指标:用来衡量局部像素级误差和全局图像级误差,可帮助评估图像处理算法对每个像素的影响程度以及整体图像质量的损失情况。
S指标:用于评估显著图的区域感知和对象感知的空间结构相似性,有助于分析显著图的结构特征和对目标的关注程度。
F指标:是查准率和查全率的加权调和均值,可以帮助综合衡量算法在精度和召回率方面的表现。
MAE(平均绝对误差):测量显著图和真值图之间的每像素绝对差值的平均值,用于评估显著图质量和真实标注之间的差异程度。
实验结果
将本文模型与 CoNet、TriTransNet、SSF、ATSA、AILNet、EBFSP、CDNet、HAINet、RD3D和 DSA2F、DCF这11种最新的RGB-D SOD模型进行了比较.
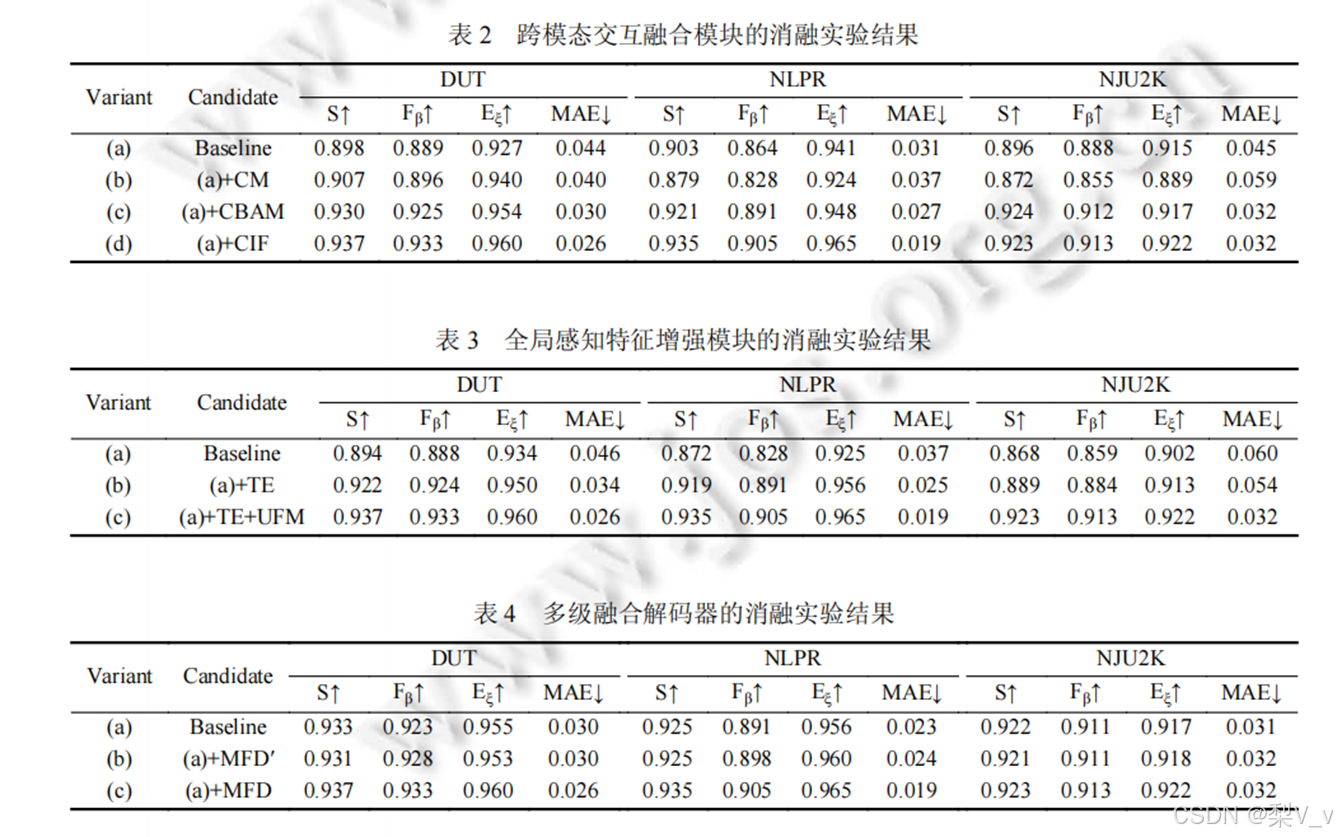
根据三个表的结果, 我们可以观察到, 基线模型加入融合模块,特征增强模块和解码器后, 在3个数据集的4个评价指标上的效果都有明显的提升.
总结
1.设计了一个 CNN-Transformer 网络架构, 将 Transformer 全局感知特征增强模块嵌入到 U-Net 框架中, 通过 CNN 提取局部特征, 利用 Transformer学习跨层级的长距离依赖关系以增强特征表示.
2. 设计了跨模态交互融合模块, 借助注意力机制学习深度图像和 RGB 图像之间的互补信息, 并且将跨模态融合特征作为 RGB 的补充, 以充分利用不同模态的特征信息.
3.设计了一个多级融合解码器, 通过不同大小的残差卷积块逐级解码, 并且在解码的过程中融合低级特征,保留了更多的原始信息.

















 566
566

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









