







 本文详细介绍了如何搭建一个基于fastText的中文文本多标签分类系统,涵盖了环境配置、服务框架搭建、输入预处理、图谱匹配、模型训练、模型保存、部署到tf-serving等多个环节。系统通过图谱匹配和概率调整等方法,处理匹配歧义,以提高标签的准确性。此外,文章还讨论了模型的多进程训练和多线程预测,确保高效服务。
本文详细介绍了如何搭建一个基于fastText的中文文本多标签分类系统,涵盖了环境配置、服务框架搭建、输入预处理、图谱匹配、模型训练、模型保存、部署到tf-serving等多个环节。系统通过图谱匹配和概率调整等方法,处理匹配歧义,以提高标签的准确性。此外,文章还讨论了模型的多进程训练和多线程预测,确保高效服务。

智能文本分类系统:又称为中文标签化系统, 针对一段中文文本, 根据其内容, 打上一个或多个合适的标签的系统。
举例文本: “我最喜欢的歌手是周杰伦,因为他的七里香很好听,雨下整夜,我的爱溢出就像雨水。” 文本标签: “音乐”
系统的应用场景:
- 这是一款公司内部使用的产品,支持个性化推荐系统, 商品画像等.
- 以个性化推荐系统为例, 基于用户的兴趣爱好进行推荐, 需要根据用户行为日志打上一个或多个标签, 通过标签匹配, 来完成基于兴趣的推荐工作.

- 系统输入为: 文章, 评论, 描述等具体的非结构化文本.
- 系统输出为: 该文本涉及的主要标签,主要标签预测概率以及关联的父级标签列表.
自主构建系统的优势:
- 我们这里更专注于泛娱乐垂直领域的精细分类, 更好的把握该领域的用户需求。
- 标签迭代速度更快,满足泛娱乐领域多变的标签情况。

智能文本分类整体系统搭建的六个环节

- 后端服务搭建
学习构建起对外提供restAPI的服务框架,使成果能被非技术人员调用. - 输入预处理
学习对输入的文本做长度验证, 分词, 去停用词等处理操作. - 图谱匹配
学习使用输入文本中的词汇进入到图谱中进行匹配, 找出所有可能的标签. - 匹配歧义判断
学习使用模型对所有不确定的标签进行判断, 找出最合适的标签. - 概率调整
学习调整标签的概率, 满足随着相关词汇增多, 概率逐渐增大. - 概率标签化与父标签检索
学习对概率进行归一化处理, 并检索匹配标签的父级标签列表.
一、整体系统搭建
1、安装环境
1.1 安装Anconda科学计算环境
Anconda科学计算环境, 它包括python3, pip,pandas, numpy等科学计算包。
下载Anaconda3-5.2.0-Linux-x86_64.sh
curl -O https://repo.anaconda.com/archive/Anaconda3-2019.07-Linux-x86_64.sh
将环境包安装在/root/目录下
[root@whx ~]cd /root
[root@whx ~]# curl -O https://repo.anaconda.com/archive/Anaconda3-2019.07-Linux-x86_64.sh
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 516M 100 516M 0 0 1785k 0 0:05:56 0:05:56 --:--:-- 2241k
[root@whx ~]#
安装Anaconda3-2019.07-Linux-x86_64.sh
sh Anaconda3-2019.07-Linux-x86_64.sh
[root@ainlp ~]# sh Anaconda3-2019.07-Linux-x86_64.sh
配置~/.bashrc, .bashrc为隐藏文件,用 ll -la 显示查看
Anaconda3-2019.07-Linux-x86_64.sh安装时自动配置环境变量
[root@centos608 ~]# ll -la
# .bashrc
# User specific aliases and functions
alias rm='rm -i'
alias cp='cp -i'
alias mv='mv -i'
# Source global definitions
if [ -f /etc/bashrc ]; then
. /etc/bashrc
fi
# >>> conda initialize >>>
# !! Contents within this block are managed by 'conda init' !!
__conda_setup="$('/root/anaconda3/bin/conda' 'shell.bash' 'hook' 2> /dev/null)"
if [ $? -eq 0 ]; then
eval "$__conda_setup"
else
if [ -f "/root/anaconda3/etc/profile.d/conda.sh" ]; then
. "/root/anaconda3/etc/profile.d/conda.sh"
else
export PATH="/root/anaconda3/bin:$PATH"
fi
fi
unset __conda_setup
# <<< conda initialize <<<
更早的版本需要手动在最后一行添加一行export PATH="/root/anaconda3/bin:$PATH":
export PATH=/root/anaconda3/bin/:$PATH
修改后的 .bashrc文件
# .bashrc
# User specific aliases and functions
alias rm='rm -i'
alias cp='cp -i'
alias mv='mv -i'
# Source global definitions
if [ -f /etc/bashrc ]; then
. /etc/bashrc
fi
# added by Anaconda3 installer
export PATH="/root/anaconda3/bin:$PATH"
重新打开命令行窗口后,命令行前有一个(base):
(base) [root@whx ~]#
1.2 安装必备组件supervisor, nginx
yum install supervisor -y
yum install nginx -y
在centos 上用 yum 来安装 nginx ,则需要做以下配置
# vim /etc/yum.repos.d/nginx.repo
[nginx]
name=nginx repo
baseurl=http://nginx.org/packages/centos/7/$basearch/
gpgcheck=0
enabled=1
然后 执行 yum install -y nginx 就可以自动安装nginx了。
1.3 安装pip
wget https://bootstrap.pypa.io/2.7/get-pip.py
python get-pip.py
wget https://bootstrap.pypa.io/2.7/get-pip.py
python get-pip.py
1.4 安装编译工具
yum install -y gcc* pcre-devel openssl-devel
...
Dependency Updated:
e2fsprogs.x86_64 0:1.42.9-19.el7 e2fsprogs-libs.x86_64 0:1.42.9-19.el7 glibc.x86_64 0:2.17-323.el7_9 glibc-common.x86_64 0:2.17-323.el7_9 krb5-libs.x86_64 0:1.15.1-50.el7 krb5-workstation.x86_64 0:1.15.1-50.el7
libcom_err.x86_64 0:1.42.9-19.el7 libgcc.x86_64 0:4.8.5-44.el7 libgomp.x86_64 0:4.8.5-44.el7 libkadm5.x86_64 0:1.15.1-50.el7 libselinux.x86_64 0:2.5-15.el7 libselinux-python.x86_64 0:2.5-15.el7
libselinux-utils.x86_64 0:2.5-15.el7 libsepol.x86_64 0:2.5-10.el7 libss.x86_64 0:1.42.9-19.el7 libstdc++.x86_64 0:4.8.5-44.el7 openssl.x86_64 1:1.0.2k-21.el7_9 openssl-libs.x86_64 1:1.0.2k-21.el7_9
zlib.x86_64 0:1.2.7-19.el7_9
Complete!
[root@ainlp django-uwsgi]#
1.5 安装python依赖
yum install -y python-devel
[root@ainlp django-uwsgi]# yum install -y python-devel
Loaded plugins: fastestmirror, langpacks
Loading mirror speeds from cached hostfile
* base: mirrors.aliyun.com
* epel: mirror.sjtu.edu.cn
* extras: mirrors.aliyun.com
* updates: mirrors.aliyun.com
Package python-devel-2.7.5-90.el7.x86_64 already installed and latest version
Nothing to do
[root@ainlp django-uwsgi]#
1.6 安装项目需要的python工具包,uwsgi,tensorflow,keras,django等,我们使用requirements.txt一同安装。
cd /data/django-uwsgi/
pip install -r requirements.txt
其中requirements.txt包括:
## The following requirements were added by pip freeze:
neo4j-driver==1.7.1
pandas>=0.20.3
numpy>=1.19.5
jieba>=0.39
Django>=1.11.7
djangorestframework>=3.7.3
django-filter>=1.1.0
flower>=0.9.2
uwsgi>=2.0.15
requests>=2.18.4
django-cors-headers
tensorflow
keras==2.2.4
celery>=3.1.25
typed-ast>=1.3.0
查看是否已经安装Django和安装的版本:python -m django --version。如果这行命令输出了一个版本号,证明你已经安装了Django且展示当前安装的版本;如果你得到的是一个“No module named django”的错误提示,则表明你还未安装。
(base) [root@whx django-uwsgi]# python -m django --version
3.1.7
(base) [root@whx django-uwsgi]#
1.7 安装图数据库neo4j
Nosql数据库:Neo4j图数据库【py2neo:对Neo4j数据库进行增删改查的python第三方库】
1.8 启动图数据库并查看数据库状态
cd /data/django-uwsgi
启动图数据库
neo4j start
查看状态
neo4j status
(base) [root@whx data]# neo4j start
Active database: graph.db
Directories in use:
home: /var/lib/neo4j
config: /etc/neo4j
logs: /var/log/neo4j
plugins: /var/lib/neo4j/plugins
import: /var/lib/neo4j/import
data: /var/lib/neo4j/data
certificates: /var/lib/neo4j/certificates
run: /var/run/neo4j
Starting Neo4j.
Started neo4j (pid 3060). It is available at http://0.0.0.0:7474/
There may be a short delay until the server is ready.
See /var/log/neo4j/neo4j.log for current status.
(base) [root@whx data]# neo4j status
Neo4j is running at pid 3060
(base) [root@whx data]#
1.9 使用supervisor启动主服务,并查看服务状态
- 使用supervisord启动主服务,-c是读取自定义配置文件的意思
- supervisord.conf是在工程主目录下的配置文件,里面包含了监控和守护django以及nginx进程的内容
cd /data/django-uwsgi
[root@ainlp django-uwsgi]# supervisord -c supervisord.conf
[root@ainlp django-uwsgi]#
查看所有监控和守护进程的状态
[root@ainlp django-uwsgi]# supervisorctl status all
main_server BACKOFF Exited too quickly (process log may have details)
nginx RUNNING pid 3096, uptime 0:00:06
[root@ainlp django-uwsgi]#
如果有错误,查看错误日志:/log
1.9.1 错误01
uwsgi: error while loading shared libraries: libssl.so.1.1: cannot open shared object file: No such file or directory
uwsgi: error while loading shared libraries: libcrypto.so.1.1: cannot open shared object file: No such file or directory
- 进入你的anaconda目录,再进入lib,在这里你能找到上面报错需要的文件;
- 执行:cp XXX /lib64。即可
(base) [root@whx lib]# cp libssl.so.1.1 /lib64
(base) [root@whx lib]# cp libcrypto.so.1.1 /lib64
1.9.2 错误02
警告:?: (urls.W005) URL namespace ‘admin’ isn’t unique. You may not be able to reverse all URLs in this namespace
- 在urls.py中的urlpatterns中重复定义了admin,所以会有此警告,将重复定义的url注释掉即可。
urlpatterns = [
# url(r'^admin/', admin.site.urls), # 注释掉此行
url(r'', include('api.urls')),
]+static(settings.STATIC_URL, document_root=settings.STATIC_ROOT)
2、后端服务搭建
后端服务的主要作用:封装所有的文本处理环节, 对外提供可以调用的restAPI, 让其他部门的同事或者不了解内部细节的人员都可以使用。
2.1 搭建django服务框架四步曲
2.1.1 第一步: 拷贝服务框架的基本文件
- 文件已经存放在/data/django-uwsgi目录下.
- 在服务器中进行文件查看.
2.1.2 第二步: 安装必备的组件
- nginx: 用于负载均衡, 增强服务的健壮性.
- supervisor: 用于django服务的守护和监控, 当服务出现异常时自动重启.
- neo4j: 图数据库, 用于存储和查询数据.
- 组件安装过程: 请参考附录部分的环境安装部署手册.
2.1.3 第三步: 启动图数据库并查看数据库状态
cd /data/django-uwsgi
# 启动图数据库
neo4j start
# 查看状态
neo4j status
2.1.4 第四步: 使用supervisor启动主服务,并查看服务状态
# 使用supervisord启动主服务
# -c是读取自定义配置文件的意思
# supervisord.conf是在工程主目录下的配置文件
# 里面包含了监控和守护django以及nginx进程的内容
supervisord -c supervisord.conf
# 查看所有监控和守护进程的状态
supervisorctl status all
2.2 使用服务内部的三个python文件运行一个请求的demo
2.2.1 第一步: 认识三个python文件
-
urls.py, 位于/data/django-uwsgi/api/目录下, 用于将前端的请求url转发到views函数中.
-
views.py, 位于/data/django-uwsgi/api/目录下, 用于接收来自前端请求的数据, 并传给api.py中的函数执行, 并获得结果, 封装成响应体返回.
-
api.py, 位于/data/django-uwsgi/text_labeled/目录下, 用于执行主要的逻辑处理部分, 并返回结果给views.py中的函数.
2.2.2 第二步: 编写三个文件中的代码内容
代码位置: 代码将写在/data/django-uwsgi/api/urls.py文件中
# 编写urls.py文件
from django.conf.urls import url
from django.contrib import admin
from . import views
urlpatterns = [
url(r'^admin/', admin.site.urls),
# 定义路径api/get_label, 前端将请求该路径
# 请求后, 该条语句将其转发到views中的get_label函数上
# get_label函数将在views.py中实现
# views即是同目录下的views.py文件
url(r'^api/get_label[/]?$', views.get_label)
]
代码位置: 代码将写在/data/django-uwsgi/api/views.py文件中
# 编写views.py文件
# 首先导入django服务必备的工具包
from django.http import HttpResponse
from rest_framework import viewsets
from rest_framework.response import Response
from rest_framework.decorators import api_view
from rest_framework.permissions import IsAuthenticated
from rest_framework.decorators import authentication_classes
from rest_framework.decorators import permission_classes
import json
# 从text_labeled文件中导入了api.py文件
from text_labeled import api
# 该装饰器用于保证函数能够接收POST请求
@api_view(['POST'])
def get_label(request):
"""获取标签接口, 参数request是请求体, 包含前端传来的数据"""
# 通过请求体接收前端传来的数据text
# request.POST >>> {"text": "xxxx"}
text = request.POST.get("text")
# 调用text_labeled/api.py文件中的label函数进行处理
result = api.label(text)
# 返回json格式的结果,并使用HttpResponse进行封装
return HttpResponse(json.dumps(result, ensure_ascii=False))
代码位置: 代码将写在/data/django-uwsgi/text_labeled/api.py文件中
# 编写api.py文件
def label(text):
label = "嘻哈音乐"
return label
重启服务【代码位置: 代码将写在/data/django-uwsgi/目录下的终端中.】
# 服务文件改变后, 需要重新启动才能生效
supervisorctl restart all
2.2.3 第三步: 编写测试脚本test.py, 并发送请求
代码位置: 代码将写在/data/django-uwsgi/test.py文件中
# 编写test.py
# 导入发送请求的工具包
import requests
def test():
url = "http://127.0.0.1:8087/api/get_label"
data = {
"text": "我抽着差不多的烟,又过了差不多的一天!"}
# 使用requests发送post请求
res = requests.post(url, data=data)
print(res.text)
if __name__ == "__main__":
test()
3、输入预处理
输入预处理在整个系统中的作用:保证用户输入的合理性,避免系统因为接受异常数据而过载,同时为下一步处理做必要的准备.
输入预处理的三步曲:
- 第一步:对输入进行长度限制.
- 第二步:对输入进行分词处理.
- 第三步:对分词结果进行去停用词处理.
代码位置: 代码将写在/data/django-uwsgi/text_labeled/api.py中.
# 代码首先引入三个必备的package,分别是os主要用于操作文件路径,
# jieba用于分词处理,fileinput用于从文件读取数据到内存.
import os
import jieba
import fileinput
# 定义了用户自定义词典路径,和停用词典路径,即在该代码文件路径下应有userdict.txt和stopdict.txt文件
userdict_path = os.path.join(os.path.dirname(__file__), "userdict.txt")
stopdict_path = os.path.join(os.path.dirname(__file__), "stopdict.txt")
# 加载用户自定义词典
jieba.load_userdict(userdict_path)
# 定义输入文本最大长度限制为200
MAX_LIMIT = 200
def handle_cn_text(text: str):
"""用于完成预处理的主要流程, 以原始文本为输入,以分词和去停用词后的词汇列表为输出."""
# 对输入进行合法性检验
if not text: return []
# 使用jieba的cut方法对使用最大限制进行切片的输入文本进行分词
word_list = jieba.cut(text[:MAX_LIMIT])
def _load_stop_dict():
"""用于从文件中加载停用词词表"""
# 使用fileinput加载停用词表至内存,使用字符串的strip()方法去除两端空白符
stop_word_set = set(map(lambda x: x.strip(), fileinput.FileInput(stopdict_path)))
return stop_word_set
# 调用_load_stop_dict()函数
stop_word_set = _load_stop_dict()
# 使用高阶函数filter进行循环过滤操作生成最终结果
word_list = list(filter(lambda x: x not in stop_word_set and len(x)>1, word_list))
return word_list
输入实例:
"我的眼睛很大很大,可以装得下天空,装得下高山,装得下大海,装得下整个世界;我的眼睛又很小很小,有心事时,就连两行眼泪,也装不下."
输出效果:
['眼睛', '很大', '很大', '装得', '天空', '装得', '高山', '装得', '大海', '装得', '整个', '世界', '眼睛', '很小', '很小', '心事', '两行', '眼泪', '装不下']
4、图谱匹配(简介)
图谱匹配在整个系统中的作用:通过匹配词汇召回所有可能的标签。
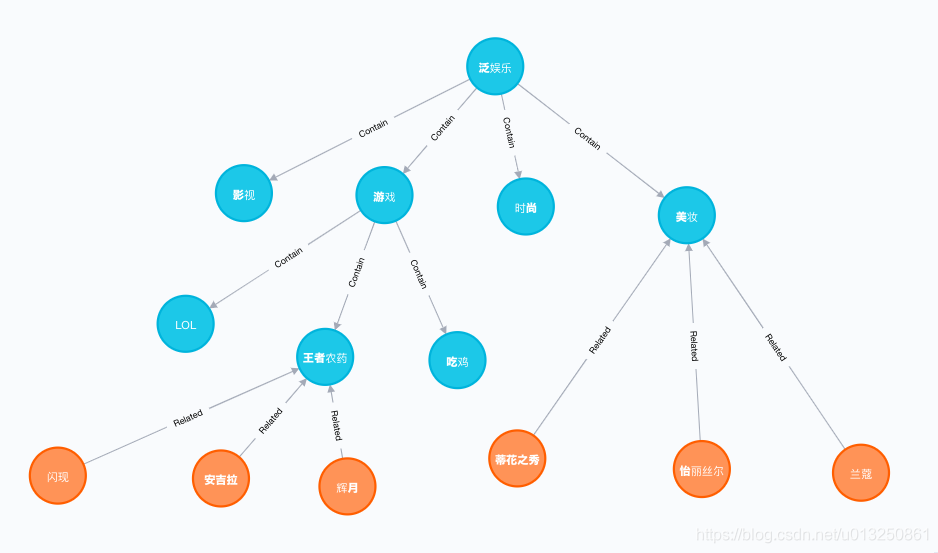
标签词汇图谱分析:
- 图谱由节点和关系(边)组成.
- 蓝色节点代表标签,橘色节点代表词汇.
- 在节点与节点之间存在着不同类型的边.
- 蓝色节点(标签节点)之间的边表示包含关系,没有权重值.
- 蓝色节点与橘色节点(词汇节点)之间的边表示隶属关系,有权重值,代表该词汇属于该标签的概率.
- 所有的节点与边组成了一个树结构,也就是我们的图谱.
- 图谱匹配的过程,即将分词列表中的词汇与词汇节点进行匹配,相同则返回该标签节点名称和边上的权重.
实现图谱匹配过程的代码分析【代码位置: 代码将写在/data/django-uwsgi/text_labeled/api.py中.】:
# 首先导入操作图数据库neo4j的必备官方工具neo4j-driver,
# 从settings.py配置文件中导入数据库配置NEO4J_CONFIG
from neo4j.v1 import GraphDatabase
from settings import NEO4J_CONFIG
# 导入用于扁平化列表的chain方法
from itertools import chain
def get_index_map_label(word_list):
"""
用于获取每个词汇在图谱中对应的类别标签
该函数以词汇列表为输入, 以词汇出现在词汇列表
中的索引和对应的[标签, 权重]列表为输出.
"""
# 对word_list进行合法性检验
if not word_list: return []
# 使用GraphDatabase开启一个driver.
_driver = GraphDatabase.driver(**NEO4J_CONFIG)
# 开启neo4j的一个session
with _driver.session() as session:
def _f(index, word):
"""以词汇列表中一组词索引和词作为输入,
返回该索引和词对应的标签列表."""
# 进行输入的合法性判断
if not word: return []
# 建立cypher语句, 它匹配一条图中的路径, 该路径以一个词汇为开端通过一条边连接一个Label节点,
# 返回标签的title属性,和边的权重, 这正是我们图谱构建时定义的连接模式.
cypher = "MATCH(a:Vocabulary{
name:%r})-[r:Related]-(b:Label) \
RETURN b.title, r.weight" % (word)
record = session.run(cypher)
result = list(map(lambda x: [x[0], x[1]], record))
if not result: return []
return [str(index), result]
# 将word_list的索引和词汇作为输入传给_f()函数,并将返回结果做chain操作
index_map_label = list(
chain(*map(lambda x: _f(x[0], x[1]), enumerate(word_list))))
return index_map_label
输入实例:
['眼睛', '很大', '很大', '装得', '天空', '装得', '高山', '装得', '大海', '装得', '整个', '世界', '眼睛', '很小', '很小', '心事', '两行', '眼泪', '装不下']
输出效果:
[] # 因为我们图谱还没有构建, 因此暂时会返回一个空列表, 实际上应该返回类似结构: ["0", [["美妆", 0.654], ["情感故事":0.765]]]
5、匹配歧义判断(简介)
什么是匹配歧义:在图谱匹配过程中, 一个词汇可能一起匹配到多个标签, 这时说明我们的词汇出现了歧义现象,这就是匹配歧义。
匹配歧义判断的作用:在词汇出现歧义时,通过模型重新计算所属标签的概率,从语义层面获得更真实的标签概率。

"闪现"一词匹配到两个标签, LOL和王者农药, 说明这个词汇在句子中具有歧义,需要进行更深层次的判断.
实现匹配歧义判断的过程【注意: 函数中会调用多模型预测函数, 我们会在后面实现, 这里我们会编写一个空壳函数暂时充当.】
代码位置: 代码将写在/data/django-uwsgi/text_labeled/model_train/multithread_predict.py中.
def request_model_serve(word_list, label_list):
return [["情感故事", 0.865]]
实现匹配歧义判断过程的代码分析【代码位置: 代码将写在/data/django-uwsgi/text_labeled/api.py中.】
# 导入多模型预测函数
from model_train.multithread_predict import request_model_serve
def weight_update(word_list, index_map_label):
"""该函数将分词列表和具有初始概率的标签-概率列表作为输入,将模型预测后的标签-概率列表作为输出"""
# 首先将列表转化为字典的形式
# index_map_label >>> ["1", [["美食", 0.735], ["音乐", 0.654]], "2", [["美妆", 0.734]] >>>
# {"1": [["美食", 0.735],["音乐", 0.654]], "2": [["美妆", 0.734]]}
index_map_label = dict(zip(index_map_label[::2], index_map_label[1::2]))
for k, v in index_map_label.items():
# v的长度大于1说明存在歧义现象
if len(v) > 1:
# 获取对应的标签作为参数,即通知服务应该调用哪些模型进行预测.
label_list = list(map(lambda x: x[0], v))
# 通过request_model_serve函数获得标签最新的预测概率,并使用字典方式更新.
# v >>> [["美食": 0.954]]
v = request_model_serve(word_list, label_list)
index_map_label.update({
k:v})
# 将字典转化为列表形式
index_map_label_ = list(chain(*map(lambda x: [x[0], x[1]], index_map_label.items())))
return index_map_label_
输入实例:
# word_list
['眼睛', '很大', '很大', '装得', '天空', '装得', '高山', '装得', '大海', '装得', '整个', '世界', '眼睛', '很小', '很小', '心事', '两行', '眼泪', '装不下']
# index_map_label
["0", [["美妆", 0.654], ["情感故事", 0.765]]]
输出效果:
["0", [["情感故事", 0.865]]]
6、概率调整(简介)
什么是概率调整:当句子中的多个词都指向同一标签时, 这个标签概率将成为所有的概率之和。
概率调整的作用:保证随着某一类别词汇出现的次数增多,这个类别的概率会随之增加。
举个栗子:
我爱苹果! -------> [["水果", 0.654], ["电影", 0.654], ["公司", 0.654]]
出现了一次苹果, 可能是在说水果,电影,或者公司, 他们的概率基本上是相同的. 这句话打上什么标签不能确定。
我爱苹果,橘子,香蕉! --------> [["水果", 0.654], ["电影", 0.654], ["公司", 0.654], ["水果", 0.654], ["水果", 0.654]]
全句共出现了三次有关水果的词,如果水果的概率是苹果,橘子,香蕉为水果的概率和,这样就大于了电影或者公司的概率. 基本上可以打上一个确定的标签了.
实现概率调整过程的代码分析【代码位置: 代码将写在/data/django-uwsgi/text_labeled/api.py中】:
# 导入可以进行扁平化操作的reduce
# 导入进行合并操作的pandas
from functools import reduce
import pandas as pd
def control_increase(index_map_label_):
"""以模型预测后的标签-权重列表为输入, 以标签归并后的结果为输出"""
if not index_map_label_: return []
# index_map_label_ >>>
# ["2", [["情感故事", 0.765]], "3", [["情感故事", 0.876], ["明星", 0.765]]]
# 将index_map_label_奇数项即[label, score]取出放在字典中
# k的数据结构形式:
# [{'label': '情感故事', 'score': 0.765}, {'label': '情感故事', 'score': 0.876},
# {'label': '明星', 'score': 0.765}]
k = list(map(lambda x: {
"label": x[0], "score": x[1]}, reduce(
lambda z, y: z + y, index_map_label_[1::2])))
# 使用pandas中的groupby方法进行合并分值
df = pd.DataFrame(k)
df_ = df.groupby(by=['label'])['score'].sum()
return df_
输入实例:
["2", [["情感故事", 0.765]], "3", [["情感故事", 0.876], ["明星", 0.765]]]
输出效果:
label
情感故事 1.641
明星 0.765
Name: score, dtype: float64
7、概率归一化与父标签检索(简介)
什么是概率归一化:对超过1的概率进行归一化处理。
概率归一化的作用:使标签概率的结果在(0到1)的概率值域内。
父标签检索的作用:找到当前标签的父标签列表,丰富系统的返回结果。
实现概率归一化与父标签检索过程的代码分析【代码位置: 代码将写在/data/django-uwsgi/text_labeled/api.py中】:
import numpy as np
def father_label_and_normalized(df_):
"""
以概率调整后的DataFrame对象为输入, 以整个系统的最终结果为输出
输入样式为:DataFrame<[[“LOL”, 1.465]]>
输出样式为:[{“label”: “LOL”, “score”: “0.811”, “related”:[“游戏”]}]
"""
def _sigmoid(x):
y = 1.0 / (1.0 + np.exp(-x))
return round(y, 3)
def _sg(pair):
"""获得单个标签的父级标签和归一化概率"""
# 使用GraphDatabase开启一个driver.
_driver = GraphDatabase.driver(**NEO4J_CONFIG)
with _driver.session() as session:
# 通过关系查询获得从该标签节点直到根节点的路径上的其他Label节点的title属性
cypher = "MATCH(a:Label{
title:%r})<-[r:Contain*1..3]-(b:Label) \
WHERE b.title<>'泛娱乐' RETURN b.title" % pair[0]
record = session.run(cypher)
result = list(map(lambda x: x[0], record))
return {
"label": pair[0], "score": _sigmoid(pair[1]), "related": result}
# 遍历所有的标签
return list(map(_sg, df_.to_dict().items()))
输入实例:
label
情感故事 1.641
明星 0.765
Name: score, dtype: float64
输出效果:
# 因为没有构建图谱,所以related匹配不到任何父标签
[{
'label': '情感故事', 'score': 0.838, 'related': []}, {
'label': '明星', 'score': 0.682, 'related': []}]
二、构建标签词汇图谱
使用图数据库neo4j构建起标签词汇图谱,用于基于词汇的标签匹配工作.

图中的蓝色节点代表标签,因为给文本打上什么标签是和业务紧密相连的,因此它是我们根据业务设计的,设计完成后,我们使用图数据库语言cypher在图数据库中构建它.
图中的橘色节点代表词汇,词汇一般是指与连接标签相关的名词,这些名词来自于所谓的原始数据,我们这里的原始是由公司内部的人员提供的.在有了原始数据后,我们便可以从中进行获取词汇集,最后将词汇集导入图谱。
构建标签词汇图谱的五个步骤:

1、设计标签树
1.1 第一步: 明确设计原则
业务导向原则: 就是说标签设计必须与公司业务强相关, 明确产品长期稳定需求, 尽量减少标签变动,这需要我们去了解自己公司的产品,不要一味去追求大而全.
最小可行化原则: 要记住我们的标签体系就像模型一样,是不断迭代的,所以初期设计要遵循最小可行化.
1.2 第二步: 确定一级和二级标签
# 一级标签:
{"泛娱乐": ["明星", "美妆", "时尚", "影视", "音乐", "游戏", "美食"]}
# 二级标签:
{
"游戏":[
"LOL",
"王者农药",
"吃鸡"
],
"影视":[
"喜剧",
"综艺",
"科幻",
"恐怖"
],
"音乐":[
"摇滚乐",
"民谣",
"Rap",
"流行乐"
]
}
1.3 第三步: 标签存储
# 必须使用扁平化的存储结构:
LABEL_STRUCTURE = [
{
"泛娱乐":[
"明星",
"时尚",
"游戏",
"影视",
"音乐",
"美妆"
]
},
{
"游戏":[
"LOL",
"王者农药",
"吃鸡"
],
"影视":[
"喜剧",
"综艺",
"科幻",
"恐怖"
],
"音乐":[
"摇滚乐",
"民谣",
"Rap",
"流行乐"
]
}
]
2、构建标签树
构建标签树的四步曲:
- 第一步: 删除数据库中之前的与标签相关的节点和边, 以免重复创建.
- 第二步: 遍历标签结构列表(LABEL_STRUCTURE)中的每一个字典.
- 第三步: 遍历字典中的每一组key和value,根据key, MERGE每一个等级的父标签节点.
- 第四步: 遍历value列表,创建每一个等级的子标签节点及其关系.
标签结构列表:
LABEL_STRUCTURE = [
{
"泛娱乐":[
"明星",
"时尚",
"游戏",
"影视",
"音乐",
"美妆"
]
},
{
"游戏":[
"LOL",
"王者农药",
"吃鸡"
],
"影视":[
"喜剧",
"综艺",
"科幻",
"恐怖"
],
"音乐":[
"摇滚乐",
"民谣",
"Rap",
"流行乐"
]
}
]
构建标签树的代码
# ================================================================================== 构建标签树:开始 ==================================================================================
import sys # 因为我们需要导入settings.py中的配置信息,所以需要将上一级路径导入到系统路径中
sys.path.append('../')
from neo4j import GraphDatabase
from settings import NEO4J_CONFIG, LABEL_STRUCTURE
def create_label_node_and_rel():
_driver = GraphDatabase.driver(**NEO4J_CONFIG) # 该函数用于创建标签树的节点和边
with _driver.session() as session:
cypher = "MATCH(a:Label) DETACH DELETE a" # 删除所有Label节点以及相关联的边
session.run(cypher)
def _create_node_rel(l: dict): # 根据标签树结构中的每一个字典去创建节点和关系
if not l:
return
for k, v in l.items(): # 遍历字典中的k,v即父子标签
cypher = "MERGE(a:Label{title:%r})" % (k) # MERGE一个父标签节点
session.run(cypher)
def __c(word): # 用于创建子标签节点以及与父标签之间的关系
cypher = "CREATE(a:Label{title:%r}) SET a.name=%r WITH a MATCH(b:Label{title:%r}) MERGE(b)-[r:Contain]-(a)" % (word, word, k)
session.run(cypher)
list(map(__c, v)) # 遍历子标签列表
list(map(_create_node_rel, LABEL_STRUCTURE)) # 遍历标签树列表
# ================================================================================== 构建标签树:结束 ==================================================================================
if __name__ == "__main__":
create_label_node_and_rel()
输出效果: 在neo4j可视化页面中查看: http://localhost:7474

3、获取原始数据
原始数据来源:公司作为内容生产商,有各种类型内容的生产小组,提供各种文本语料.
原始数据的基本属性:
- 文章为短文,在几百至几千字不等.
- 内容围绕明确的主题展开,其中涉猎很多相关命名实体.
- 完整句子使用句号分割,小段使用换行符分割.
3.1 明星类
玩笑归玩笑,谈到录制感受和评选标准时,沈腾自爆自己是最心软的观察员,给的yes最多,“可能是年纪大了,特别容易被选手感染,之前一个歌手刚开口,我就忍不住想哭”。
相对而言,金星算是比较严格的梦想观察员,她心目中的“达人”要在自己的普通生活之外,有着与众不同且足够极致的长处,“我对每个节目有40秒的忍耐期,如果在这之后没有打动我的东西,我就会按no。”
作为团内最年轻的成员,活泼的杨幂表现出了鲜明的“团宠属性”。不仅亲切地称呼沈腾为“二舅”、金星为“金姨”,还和口中的“我哥”蔡国庆共享暗号。节目录制下来,杨幂谦虚表示,自己在《达人秀》的舞台上见识了很多震撼的表演,是一次长见识的旅程。至于评判标准,杨幂坦言,自己对于一些专业表演没有太多见解,主要尊崇内心做选择。

3.2 时尚
采访中她曾提到希望大家包容她善待她,不管是她饰演的角色还是她本人。她为角色发声,为校园霸凌发声,同样为自己发声,希望观众对于她这个新人演员,能在给予严格的要求同时更给予情感的包容。而面对一些diss和嘲讽她的言语,她也表示不会因此而改变,而是会选择坚持自我,不忘初心,做自己。她曾说过“人生本无意义,人的存在就是为了创造意义。”年龄虽小,却是个有主见有自我坚持的女孩。
坚定如初
上衣:Hollister
裤子:Hollister
鞋:Mizuno
耳环:Inch Edition
耳夹:Thing In Thing
青春少女持刀出行,刀韧锋利却不敌她眼中的坚定与炙热。让我们看到了一个不到20岁的少女超出常人的成熟,和年轻充满活力的小性感。
粉色套装:Isabel Marant
鞋子:Stuart Weitzman
耳环:Atelier Swarovski

3.3 影视
电影有无限的可能性,原声音乐也能给电影创作提供灵感,电影和音乐的关系是开放的。为发出这样的讯号,FIRST影展今年与MOO音乐携手合作,在电影节期间提供了一个电影和音乐交叉的场景。
MOO音乐隶属于腾讯音乐娱乐集团,创立以来受到不少深度音乐爱好者的青睐。以天然的曲库优势为依托,MOO音乐致力于融合先锋与经典,拓展当代流行音乐的边界,为用户提供纯粹的沉浸式音乐体验,致力于成为一个引领当代青年人发现、探索新鲜流行乐的新一代潮流音乐APP。
作为FIRST影展音乐平台合作伙伴,MOO音乐赞助了场外奖“先锋音乐突破奖”,这也是FIRST首次设立电影音乐方向的专项奖。为《春潮》配乐的音乐人半野喜弘获得了这一奖项,MOO音乐产品负责人王宝华为他颁奖,称赞“这是先锋的音乐”。
半野喜弘的作品经常出现在侯孝贤和贾樟柯导演的电影里,《戏梦人生》《海上花》《山河故人》中的配乐都体现了他成熟的音乐思维和对影像独立、立体的理解。《春潮》导演杨荔钠曾这样描述他们的创作过程:“他隔空对话,视频传送,反覆修改你的旋律,《春梦》《春潮》都留有他谱写的乐章。”《春潮》同时将在宣发阶段得到MOO和QQ音乐的推广资源,等待早日与观众见面。

3.3 美妆
怡丽丝尔优悦活颜眼唇抚纹精华霜睛采上市
9周淡纹,眼证为实,新一线女性生活真相代表papi酱带你一同见证
2018年5月10日,怡丽丝尔于北京虞社演艺空间举办全新优悦活颜眼唇抚纹精华霜新品发布会.品牌总监上田典史先生亲临现场,更携手知名原创视频达人papi酱作为特邀真相见证人,揭晓《新一线女性生活真相》白皮书,盛邀来自全国各地的主流时尚美妆媒体、众多知名美妆博主及护肤达人共同加入“9周淡纹,眼证为实”的见证人行列中来。
首先映入眼帘的是一个数字“9”造型的通道,置身其中,一条条关于护肤的“真相”弹幕袭来:“中年少女选购护肤品有多挑剔”、“猜猜你的衰老临界点在几点”等问题让来宾会心一笑的同时,亦引发了护肤真相的诸多思考.怡丽丝尔始终致力于亚洲女性之美,本次联合中国领先的社会化商业资讯提供机构Kantar Media CIC,将多年来对中国女性的关注汇聚为一本独具见解与洞察力的《新一线女性生活真相》白皮书,通过大数据破解新一线女性的皱纹秘密,从社会热点、生活方式和护肤习惯三个方面唤起大家对皱纹的认知及重视。
怡丽丝尔品牌总监上田典史先生表示: “自2017年在中国开展品牌革新以来,怡丽丝尔从未停下脚步,不断向前.我们始终关注亚洲女性之美,致力于为消费者提供持续创新的产品和价值体验。在这样的品牌愿景下,怡丽丝尔将目光聚焦于当下中国新一线女性的生活。我们发现尽管大部分中国女性十分注重抗老化问题,但却普遍认为护肤产品效果不尽人意。为满足广大中国消费者对于抚纹的护肤诉求,此次全新推出了功效认证的怡丽丝尔优悦活颜眼唇抚纹精华霜,不仅是品牌价值的有力证明,更标志着怡丽丝尔又一次的创新与突破。我们期待这款产品让更多中国女性绽放自信与健康的光芒,成就积极向上与自信坚强的魅力人生,遇见更好的自己。 “

4、获取词汇集
获取词汇集过程的三步曲:
- 第一步: 读取原始数据到内存.
- 第二步: 获取句子中的名词并进行长度过滤.
- 第三步: 将词汇写入到csv文件和userdict.txt之中.
import os
import jieba.posseg as pseg # 使用jieba中的词性标注功能
n_e = ["nr", "n", "ns", "nt", "nz"] # jieba中预定义的名词性类型,分别表示: 人名,名词,地名,机构团体名,其他专有名词
csv_path = "./labels" # 写入csv的路径
userdict_path = "../userdict.txt" # 用户自定义词典路径
# 函数将读取文章路径下的所有文章文本,并转化为词汇写入词汇csv文件
def get_vocabulary(article_path, csv_name):
if not os.path.exists(article_path): return
if not os.path.exists(csv_path): os.mkdir(csv_path)
# 用于获取名词列表
def _get_n_list(text):
r = []
for g in pseg.lcut(text): # 使用jieba的词性标注方法切分文本,获得具有词性属性flag和词汇属性word的对象
if g.flag in n_e: # 判断flag是否在我们定义的名词性列表中,来返回对应的词汇
r.append(g.word)
return r
with open(os.path.join(csv_path, csv_name), "a", encoding="utf-8") as u:
for article in os.listdir(article_path):
with open(os.path.join(article_path, article), "r", encoding="utf-8") as f:
text = f.read()
n_list = list(filter(lambda x: len(x) >= 2, set(_get_n_list(text)))) # 只获取长度大于等于2的名词
list(map(lambda x: u.write(x + "\n"), n_list))
with open(os.path.join(csv_path, csv_name), "r", encoding="utf-8") as o:
word = o.read()
with open(userdict_path, "a", encoding="utf-8") as f:
f.write(word)
return
if __name__ == "__main__":
article_path_list = ["./beauty", "./fashion", "./movie", "./star"] # 原始文章路径
csv_name_list = ["美妆-词汇.csv", "时尚-词汇.csv", "影视-词汇.csv", "明星-词汇.csv"] # 生成的csv文件名字(该文件在./labels目录下)
article_vocab = zip(article_path_list, csv_name_list)
for article_path, csv_name in article_vocab:
get_vocabulary(article_path, csv_name)


5、将词汇集导入图谱
将词汇集导入图谱过程三步曲:
- 第一步: 删除所有词汇节点及其相关的边
- 第二步: 遍历labels文件夹下的词汇csv文件.
- 第三步: 遍历csv文件中的每一个词汇去创建节点,并与对应的标签建立关系.
# ================================================================================== 将词汇集导入图谱:开始 ==================================================================================
sys.path.append('../')
from neo4j import GraphDatabase
from settings import NEO4J_CONFIG, LABEL_STRUCTURE
import os
import random
import fileinput
# 该函数用于创建词汇节点和关系
def create_vocabulary_node_and_rel(csv_path):
_driver = GraphDatabase.driver(**NEO4J_CONFIG)
with _driver.session() as session:
cypher = "MATCH(a:Vocabulary) DETACH DELETE a" # 删除所有词汇节点及其相关的边
session.run(cypher)
# 读取单个csv文件, 并写入数据库创建节点并与对应的标签建立关系
def _create_v_and_r(csv_name):
path = os.path.join(csv_path, csv_name)
word_list = list(set(map(lambda x: x.strip(), fileinput.FileInput(files=path, openhook=fileinput.hook_encoded("utf-8"))))) # 使用fileinput的FileInput方法从持久化文件中读取数据, 并进行strip()操作去掉两侧空白符, 再通过set来去重.
# 创建csv中单个词汇的节点和关系
def __create_node(word):
weight = round(random.uniform(0.5, 1), 3) # 定义词汇的初始化权重,即词汇属于某个标签的初始概率,因为词汇本身来自该类型文章,因此初始概率定义在0.5-1之间的随机数
cypher = "CREATE(a:Vocabulary{name:%r}) WITH a MATCH(b:Label{title:%r}) MERGE(a)-[r:Related{weight:%f}]-(b)" % (word, csv_name[:-4], weight) # 使用cypher语句创建词汇节点,然后匹配这个csv文件名字至后四位即类别名,在两者之间MERGE一条有权重的边
session.run(cypher)
list(map(__create_node, word_list)) # 遍历词汇列表
label_list = os.listdir(csv_path) # 遍历标签列表 ["影视.csv", "时尚.csv", "明星.csv", "美妆.csv"]
list(map(_create_v_and_r, label_list))
# ================================================================================== 将词汇集导入图谱:结束 ==================================================================================
if __name__ == "__main__":
# create_label_node_and_rel()
csv_path = "./labels" # 词汇集csv文件路径
create_vocabulary_node_and_rel(csv_path)


三、特征工程
1、提取各个分类下的 “正样本” 句子
先提取正样本语料,再在正样本基础上,提取正负样本语料.
# ================================================================================== 提取正样本:开始 ==================================================================================
import os
MIN_LENGTH = 5 # 限制句子的最小字符数
MAX_LENGTH = 500 # 限制句子的最大字符数
# 获取单篇文章的句子列表
def get_p_text_list(single_article_path):
with open(single_article_path, "r", encoding="utf-8") as f:
text = f.read()
cl = text.replace("\n", ".").split("。") # 去掉换行符, 并以句号划分
cl = list(filter(lambda x: MIN_LENGTH < len(x) < MAX_LENGTH, cl)) # 过滤掉长度范围之外的句子
return cl
# 该函数用于获得正样本的csv, 以文章路径和正样本csv写入路径为参数
def get_p_sample(a_path, p_path): # a_path: 原始文章所属文件夹; p_path: 句子列表保存位置
if not os.path.exists(a_path): return
if not os.path.exists(p_path): os.mkdir(p_path)
fp = open(os.path.join(p_path, "p_sample.csv"), "a", encoding="utf-8") # 以追加的方式打开预写入正样本的csv
for u in os.listdir(a_path): # 遍历文章目录下的每一篇文章
cl = get_p_text_list(os.path.join(a_path, u))
for clc in cl:
fp.write("1" + "\t" + clc + "\n")
fp.close()
# ================================================================================== 提取正样本:结束 ==================================================================================
if __name__ == "__main__":
a_path_list = ["../create_graph/beauty/", "../create_graph/fashion/", "../create_graph/movie/", "../create_graph/star/"] # 原始语料位置
p_path_list = ["./beauty", "./fashion", "./movie", "./star"] # 定义用于保存正样本csv文件所属的文件夹位置
path_tuple_list = zip(a_path_list, p_path_list)
for a_path, p_path in path_tuple_list:
get_p_sample(a_path, p_path) # 获得各个分类的正样本csv文件【p_sample.csv包含该分类下的所有句子】


2、构建各个分类的 “正负样本” 句子
将文章中的每一条句子作为该类别的正样本; 将其他类别文章中的每一条句子作为负样本.
先提取正样本语料,再在正样本基础上,提取正负样本语料.
# ================================================================================== 提取正负样本:开始 ==================================================================================
import os
# 该函数用于获取样本集包括正负样本, 以正样本csv文件路径和负样本csv文件路径列表为参数
def get_sample(p_path, n_path_csv_list): # p_path: 样本句子文件所在目录; n_path_csv_list: 负样本文件列表【将本分类之外的其他文件都归为负样本】
fp = open(os.path.join(p_path, "sample.csv"), "w", encoding="utf-8")
with open(os.path.join(p_path, "p_sample.csv"), "r", encoding="utf-8") as f:
text = f.read()
fp.write(text) # 先将正样本写入样本csv之中
for n_p_c in n_path_csv_list: # 遍历负样本的csv列表
with open(n_p_c, "r", encoding="utf-8") as f:
text = f.read().replace("1", "0") # 将其中的标签1改写为0
fp.write(text) # 然后写入样本的csv之中
fp.close()
# ================================================================================== 提取正负样本:结束 ==================================================================================
if __name__ == "__main__":
p_path_list = ["./beauty", "./fashion", "./movie", "./star"] # 文件目录
a_path_csv_list = ["./beauty/p_sample.csv", "./fashion/p_sample.csv", "./movie/p_sample.csv", "./star/p_sample.csv"] # 正样本文件列表
file_tuple_list = zip(p_path_list, a_path_csv_list)
for p_path, a_path_csv in file_tuple_list:
n_path_csv_list = a_path_csv_list.copy()
n_path_csv_list.remove(a_path_csv)
print("p_path = {}----n_path_csv_list = {}".format(p_path, n_path_csv_list))
get_sample(p_path, n_path_csv_list)

3、数据分析
文本数据必要的分析过程:
- 获取正负样本的分词列表和对应的标签.
- 获取正负标签数量分布.
- 获取句子长度分布.
- 获取常见词频分布.
获取正负样本的分词列表和对应的标签的作用
- 为进行可视化数据分析, 如获取正负标签数量分布, 获取句子长度分布, 获取常见词频分布等作数据准备.
获取正负标签数量分布的作用
- 用于帮助调整正负样本比例, 而调整正负样本比例, 对我们进行接下来的数据分析和判断模型准确率基线起到关键作用.
获取句子长度分布的作用
- 用于帮助判断句子合理的截断对齐长度, 而合理的截断长度将有效的避免稀疏特征或冗余特征的产生, 提升训练效率.
获取常见词频分布的作用
- 指导之后模型超参数max_feature(最大的特征总数)的选择和初步评估数据质量.
- 模型超参数max_feature的选定在NLP领域一般是大于所有语料涉及的词汇总数的, 但是又不能选择过于大, 否则会导致网络参数激增, 模型过于复杂,容易过拟合.因此需要参考词汇总数.
- 同时, 词频分布可以看出高频词汇与类别的相关性, 判断正负样本的是否对分类产生效果.
3.1 获取正负样本分词列表和对应的标签
# ================================================================================== 获取正负样本分词列表和对应的标签:开始 ==================================================================================
import pandas as pd
import jieba
# 获得训练数据和对应的标签, 以正负样本的csv文件路径为参数
def get_data_labels(csv_path):
df = pd.read_csv(csv_path, header=None, sep="\t") # 使用pandas读取csv文件至内存
x_train = list(map(lambda x: list(filter(lambda x: len(x) > 1, jieba.lcut(x))), df[1].values)) # 对句子进行分词处理并过滤掉长度为1的词
y_train = df[0].values # 取第0列的值作为训练标签
return x_train, y_train
# ================================================================================== 获取正负样本分词列表和对应的标签:结束 ==================================================================================
if __name__ == "__main__":
csv_path_list = ["./beauty/sample.csv", "./fashion/sample.csv", "./movie/sample.csv", "./star/sample.csv"] # 各个分类的政府样本csv文件路径
for csv_path in csv_path_list:
print("=" * 50, csv_path, "=" * 50)
x_train, y_train = get_data_labels(csv_path)
print("len(x_train) = {0}----x_train[:10] = {1}".format(len(x_train), x_train[:10]))
print("len(y_train) = {0}----y_train = {1}".format(len(y_train), y_train))
打印结果:
len(x_train) = 8412----x_train[:10] =
[
['最近', '新品', '很大', '这不娇兰', '日本', '上市', '限定', '粉饼', '真的', '橘子', '君萌', '一萌', '确实', '有点', '可爱'],
['就是', '娇兰家', '日本', '上市', '粉饼', '两只', '胖鹅', '一只', '一只', '可爱', '有木有', '粉饼', '本身', '不是', '很大', '放在', '包包', '随身携带', '刚刚'],
['哈哈哈哈', '哈哈哈', '莫名', '两只', '鹅萌'],
['其实', '里面', '两个', '颜色'],
['..', '白色', '其实', '可以', '用来', '高光', '看起来', '感觉', '实用', '木有', '内里', '银色', '拼接', '质感'],
['最后', '一句', '两只', '胖鹅', '你们', '喜欢', '月份', '上市', '...'],
['昨天', '糖糖', 'ins', '一张', '自拍照', '没有', '化妆', '还离', '镜头', '这么', '果然', '颜值', '就是', '任性', '不过', '素颜', '状态', '女神', '肌肤', '依然', '这么', '真让人', '羡慕', '不光', '自拍照', '杂志', '封面', '素颜', '快来', '橘子', '君看', '最近', '唐嫣', '封面', '大片', '出炉', '服饰', '素雅', '妆容', '清秀', '裸妆', '尽显', '自然', '纯粹', '之美'],
['白色', '蕾丝', '优雅', '甜美', '八分', '偏分', '微卷', '长发', '更是', '女神', '范儿', '十足'],
['不同于', '以前', '精致', '妆容', '这次', '非常', '自然', '素雅', '裸妆', '淡淡的', '眉形', '唇色', '还有', '几乎', '没画', '眼妆', '卸下', '浓妆', '之后', '一样', '感觉'],
['当然', '毕竟', '颜值', '估计', '一般', '不敢', '轻易', '尝试', '这么', '妆容']
]
len(y_train) = 8412----y_train = [1 1 1 ... 0 0 0]
================================================== ./fashion/sample.csv ==================================================
len(x_train) = 8412----x_train[:10] = [['春天', '橘子', '发现', '街头', '妹子', '轻装', '不少', '感觉', '新一轮', '换装', '正在', '悄无声息', '开始', '什么', '这个', '课题', '有句', '这么', '时尚', '潮人', '季节', '总是', '来得', '很早', '今天', '咱们', '看看', '那些', '已经', '早春', '人们', '什么', '单品', 'look1', '低调', '灰色', '针织', '高领', '外套', '一件', '红色', '连体', '米色', '黑色', '平底鞋', '足够', '闪亮', '街头'], ['推荐', '单品', '红色', '连体', 'look2', '灰色', '针织衫', '搭配', '一套', '牛仔', '单品', '拼接', '短靴', '夸张', '耳环', '更是', '增添', '几分', '帅气'], ['推荐', '单品', '牛仔', '套装', 'look3', '纯色', '衬衫', '条纹', '衬衫', '层次感', '很强', '搭配', '上格纹', '不规则', '裁剪', '半裙', '视觉', '冲击力'], ['推荐', '单品', '格纹', '不规则', '半裙', 'look4', '牛仔', '高领', '彩色', '条纹', '外套', '下身', '简约', '牛仔裤', '皮鞋', '多彩', '醒目'], ['推荐', '单品', '彩色', '条纹', '外套', 'look5', 'T恤', '印花', '纱裙', '休闲', '不失', '女人', '味儿', '披上', '一件', '西装', '外套', '一种', '强大', '气场'], ['推荐', '单品', '印花', '纱裙', 'look6', '黑色', '高领', '配一字', '风衣', '白色', '九分', '高跟鞋', '一整套', '感觉', '就是', '简约', '经典', '却是', '时髦'], ['推荐', '单品', '一字', '风衣', 'look7', '黄色', '卫衣', '牛仔裤', '搭配', '轻松', '休闲', '米色', '风衣', '搭配', '上后', '丰富', '整体', '层次感', '黑色', '高跟鞋', '和谐', '融合'], ['推荐', '单品', '黄色', '卫衣', 'look8', '水洗', '牛仔裤', '印花', '丝质', '衬衫', '经典', '早春', '搭配', '方法', '简单', '容易', '吸睛'], ['推荐', '单品', '印花', '丝质', '衬衫', 'look9', '格纹', '西装', '套装', '粉色', '衬衫', '英伦', '范儿', '套装', '中多', '一丝', '跳跃', '整体', '瞬间', '活泼', '许多'], ['推荐', '单品', '粉色', '衬衫', 'look10', '拼接', '风衣', '棒球帽', '皮靴子', 'look', '橘子', '喜欢', '造型', '休闲', '舒适', '同时', '风度']]
len(y_train) = 8412----y_train = [1 1 1 ... 0 0 0]
================================================== ./movie/sample.csv ==================================================
len(x_train) = 8412----x_train[:10] = [['今日', '捉妖', '北京', '举办', '全球', '首映礼', '发布会', '导演', '许诚毅', '各位', '主演', '亮相', '现场', '各位', '演员', '大家', '讲述', '自己', '拍摄', '过程', '发生', '趣事', '大家', '分享', '自己', '过年', '计划', '现场', '布置', '十分', '喜庆', '放眼望去', '一片', '红彤彤', '颜色', '感受', '浓浓的', '年味'], ['胡巴', '遭遇', '危险', '全民', '追击', '发布', '预告片', '当中', '胡巴', '遭到', '追杀', '流落', '人间', '梁朝伟', '收留', '与此同时', '李宇春', '饰演', '钱庄', '老板', '通缉', '胡巴', '胡巴', '处境', '可谓', '四面楚歌', '不过', '胡巴', '幸运', '孩子', '逃避', '追捕', '过程', '胡巴', '跟着', '朋友', '逃跑', '专家', '笨笨', '几次', '死里逃生', '没有', '落到', '起来', '关进', '笼子', '下场', '虽然', '如此', '几次', '惊险', '场面', '还是', '人们', '不禁', '电影', '胡巴', '捏一把汗'], ['百合', '井柏然', '一家', '三口', '聚首', '捉妖', '白百何', '井柏然', '战斗力', '全面', '升级', '二人', '时隔', '三年', '胡巴', '再度', '团圆', '对于', '胡巴', '不减', '影片', '得知', '胡巴', '失踪', '消息', '之后', '白百何', '井柏然', '忧心忡忡', '踏上', '寻子', '之路', '为了', '找到', '胡巴', '请来', '杨佑宁', '饰演', '天师', '帮忙'], ['导演', '许诚毅', '告诉', '大家', '白百何', '井柏然', '胡巴', '一家', '三口', '电影', '曲折', '团圆', '经历', '将会', '第二部', '最大', '看点', '现场', '百合', '井柏然', '表示', '拍摄', '胡巴', '重逢', '一场', '时候', '想到', '一家', '三口', '之前', '温馨', '回忆', '忍不住', '眼泪', '下来'], ['梁朝伟', '赌棍', '李宇春', '爆笑', '互动', '发布会', '谈到', '自己', '这次', '饰演', '角色', '梁朝伟', '描述', '自己', '电影', '中是', '一个', '赌徒', '这个', '赌徒', '虽然', '老千', '但是', '没有', '很多', '反而', '十赌', '九输', '债台高筑', '债主', '遍布', '人界', '妖界', '可谓', '倾家荡产'], ['李宇春', '电影', '饰演', '一位', '有钱', '任性', '钱庄', '老板', '而且', '这个', '角色', '梁朝伟', '饰演', '屠四谷', '上演', '一段', '非常', '搞笑', '戏码', '二人', '一个', '一个', '爆笑', '互动', '背后', '一段', '十分', '纠结', '感情'], ['最后', '一句', '大年初一', '胡巴'], ['赵涛', '贾樟柯', '电影', '专属', '女主角'], ['站台', '江湖', '儿女', '2000', '2018', '十八年', '一如既往'], ['有人', '他们', '这种', '恩爱', '方式', '甜到', '有人', '已经', '审美疲劳']]
len(y_train) = 8412----y_train = [1 1 1 ... 0 0 0]
================================================== ./star/sample.csv ==================================================
len(x_train) = 8412----x_train[:10] = [['最近', '汪小菲', '大S', '一家', '四口', '出去玩', '汪小菲', '还给', '大S', '照片', '照片', '大S', '宛如', '少女', '般的', '美貌', '完全', '看不出', '年纪', '橘子', '君一', '起来', '看看', '不得不', '大S', '真的', '瘦下来', '弯弯的', '眼笑', '起来', '可真甜', '浑身', '透露', '妈妈', '味道', '这样', '迷人', '再来', '看看', '别人', '大S', '汪小菲', '有木有', '看到', '汪小菲', '痴汉', '般的', '眼神', '哈哈哈哈', '简直', '就是', '老婆', '向日葵', '无疑', '..', '网友', '纷纷', '赞扬', '大S', '脸好', '瘦下来', '太美', '杉菜', '本人', '橘子', '记忆', '..', '真正', '开心', '幸福', '笑容', '果然', '大家', '感受', '还有', '网友', '汪小菲', '眼里', '真的', '幸福', '这话', '毛病', '..', '就是', '嫁给', '爱情', '样子', '开心', '对方', '开心', '看到', '大S', '这么', '甜美', '笑容', '感受', '他们', '一家人', '多么', '幸福', '欢乐', '橘子', '觉得', '能力', '满满', '希望', '大家', '找到', '属于', '自己', '幸福', '最后', '一句', '早上', '就让', '我们', '甜蜜', '消息', '开始', '....'], ['昨天', '娱姬', '小妖', '爆料', '杜志国', '杨姓', '女子', '疑似', '婚外恋', '消息'], ['刚刚', '曝光', '电话录音', '录音', '两人', '应该', '感情纠葛', '而且', '杜志国', '自己', '名字', '孩子', '下来', '他养', '但是', '不了', '家庭', '只能', '感情', '....', '这是', '整理', '对话', '内容', '大家', '感受一下', '之前', '爆料', '橘子', '君带', '你们', '回顾', '一下', '一位', '女士', '爆料', '自己', '喝了酒', '之后', '神志不清', '醒来', '之后', '发现自己', '裸露'], ['自己', '怀孕', '证据', '自己', '联系', '杜志国', '杜志国', '说会', '离婚', '结婚', '....', '不过', '后来', '这位', '女士', '甲状腺癌', '所以', '只能', '打掉', '孩子'], ['不仅如此', '提供', '聊天记录', '杜志国', '照片'], ['随后', '杜志国', '回应', '这件', '女子', '言论', '自己', '已经', '报警', '提供', '女子', '多次', '犯案', '记录'], ['但是', '这波', '录音', '出来', '推翻', '杜志国', '之前', '说法', '看来', '真相', '还有', '确认', '我们', '等等', '杜志国', '这边', '回应', '真是', '一瓜', '未平', '一瓜'], ['来源', '娱姬', '小妖', '最后', '一句', '怎么', '..'], ['昨晚', '迪丽', '热巴', '粉丝', '一封', '长信', '致嘉行'], ['本来', '粉丝', '公司', '这种', '已经', '司空见惯', '橘子', '还是', '惊人', '转发', '下面', '跟着', '橘子', '君一', '起来', '看看', '这篇', '长文', '不得不', '热巴', '粉丝', '公司', '这方面', '堪称', '粉圈', '一股', '清流', '不仅', '写下', '千字', '长文', '还配']]
len(y_train) = 8412----y_train = [1 1 1 ... 0 0 0]
3.2 获取标签类别数量分布
# ================================================================================== 获取正负样本分词列表和对应的标签:开始 ==================================================================================
import pandas as pd
import jieba
# 获得训练数据和对应的标签, 以正负样本的csv文件路径为参数
def get_data_labels(csv_path):
df = pd.read_csv(csv_path, header=None, sep="\t") # 使用pandas读取csv文件至内存
x_train = list(map(lambda x: list(filter(lambda x: len(x) > 1, jieba.lcut(x))), df[1].values)) # 对句子进行分词处理并过滤掉长度为1的词
y_train = df[0].values # 取第0列的值作为训练标签
return x_train, y_train
# ================================================================================== 获取正负样本分词列表和对应的标签:结束 ==================================================================================
# ================================================================================== 获取标签类别数量分布:开始 ==================================================================================
import matplotlib.pyplot as plt
from collections import Counter
# 获取正负样本数量的基本分布情况
def get_labels_distribution(y_train):
class_dict = dict(Counter(y_train)) # class_dict >>> {1: 3995, 0: 4418}
plt.figure(figsize=(10, 10), dpi=100)
plt.bar(list(class_dict.keys()), list(class_dict.values()), width=0.2, color=['b', 'r'])
plt.show()
# ================================================================================== 获取标签类别数量分布:结束 ==================================================================================
if __name__ == "__main__":
csv_path_list = ["./beauty/sample.csv", "./fashion/sample.csv", "./movie/sample.csv", "./star/sample.csv"] # 各个分类的政府样本csv文件路径
for csv_path in csv_path_list:
print("=" * 50, csv_path, "=" * 50)
x_train, y_train = get_data_labels(csv_path)
class_dict = dict(Counter(y_train)) # class_dict >>> {1: 3995, 0: 4418}
print("class_dict = {0}".format(class_dict))
cut_num = class_dict[0] - class_dict[1] # 负样本比正样本多出的数量
print("负样本比正样本多出:{0}".format(cut_num))
get_labels_distribution(y_train) # 获取正负样本数量的基本分布情况
打印结果:
================================================== ./beauty/sample.csv ==================================================
class_dict = {
1: 2367, 0: 6045}
负样本比正样本多出:3678
================================================== ./fashion/sample.csv ==================================================
class_dict = {
1: 1399, 0: 7013}
负样本比正样本多出:5614
================================================== ./movie/sample.csv ==================================================
class_dict = {
1: 3995, 0: 4417}
负样本比正样本多出:422
================================================== ./star/sample.csv ==================================================
class_dict = {
1: 651, 0: 7761}
负样本比正样本多出:7110

为了使正负样本均衡, 让它们的比例为1:1, 我们将在之后进行的该类别的数据分析和模型训练中, 去掉多出来的负样本的数量.
3.3 获取句子长度分布
# ================================================================================== 获取正负样本分词列表和对应的标签:开始 ==================================================================================
import pandas as pd
import jieba
# 获得训练数据和对应的标签, 以正负样本的csv文件路径为参数
def get_data_labels(csv_path):
df = pd.read_csv(csv_path, header=None, sep="\t") # 使用pandas读取csv文件至内存
x_train = list(map(lambda x: list(filter(lambda x: len(x) > 1, jieba.lcut(x))), df[1].values)) # 对句子进行分词处理并过滤掉长度为1的词
y_train = df[0].values # 取第0列的值作为训练标签
return x_train, y_train
# ================================================================================== 获取句子长度分布:开始 ==================================================================================
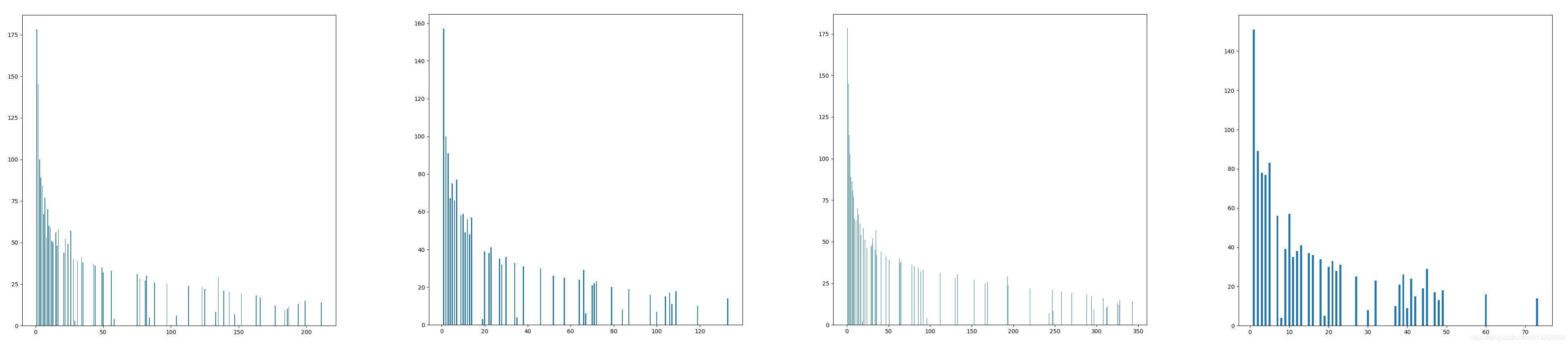
# 该函数用于获得句子长度分布情况
def get_sentence_length_distribution(x_train):
print("get_sentence_length_distribution---->x_train[:10] = {0}".format(x_train[:10]))
sentence_len_list = list(map(len, x_train))
print("sentence_len_list = {0}".format(sentence_len_list))
counter = Counter(sentence_len_list) # counter = Counter({14: 211, 15: 199, 13: 194, 11: 187, 10: 186, 9: 184, 12: 177,...})
print("counter = ", counter)
len_dict = dict(counter) # len_dict >>> {38: 62, 58: 18, 40: 64, 35: 83,....}
print("len_dict = {}".format(len_dict))
len_list = list(zip(len_dict.keys(), len_dict.values()))
print("len_list = {}".format(len_list))
len_list.sort(key=(lambda x: x[0])) # len_list >>> [(15, 199), (19, 152), (5, 84), (4, 58), (14, 211), (9, 184), ...]
x_list = list(map(lambda x: x[1], len_list))
y_list = list(map(lambda x: x[0], len_list))
plt.figure(figsize=(10, 10))
plt.bar(x_list, y_list, width=0.5)
plt.show()
# ================================================================================== 获取句子长度分布:结束 ==================================================================================
if __name__ == "__main__":
csv_path_list = ["./beauty/sample.csv", "./fashion/sample.csv", "./movie/sample.csv", "./star/sample.csv"] # 各个分类的政府样本csv文件路径
for csv_path in csv_path_list:
print("=" * 50, csv_path, "=" * 50)
x_train, y_train = get_data_labels(csv_path)
class_dict = dict(Counter(y_train)) # class_dict >>> {1: 3995, 0: 4418}
cut_num = class_dict[0] - class_dict[1] # 负样本比正样本多出的数量
print("负样本比正样本多出:{0}".format(cut_num))
x_train = x_train[:-cut_num] # 将多出的负样本切掉
get_sentence_length_distribution(x_train) # 获得句子长度分布情况
================================================== ./beauty/sample.csv ==================================================
get_sentence_length_distribution---->x_train[:10] = [['最近', '新品', '很大', '这不娇兰', '日本', '上市', '限定', '粉饼', '真的', '橘子', '君萌', '一萌', '确实', '有点', '可爱'], ['就是', '娇兰家', '日本', '上市', '粉饼', '两只', '胖鹅', '一只', '一只', '可爱', '有木有', '粉饼', '本身', '不是', '很大', '放在', '包包', '随身携带', '刚刚'], ['哈哈哈哈', '哈哈哈', '莫名', '两只', '鹅萌'], ['其实', '里面', '两个', '颜色'], ['..', '白色', '其实', '可以', '用来', '高光', '看起来', '感觉', '实用', '木有', '内里', '银色', '拼接', '质感'], ['最后', '一句', '两只', '胖鹅', '你们', '喜欢', '月份', '上市', '...'], ['昨天', '糖糖', 'ins', '一张', '自拍照', '没有', '化妆', '还离', '镜头', '这么', '果然', '颜值', '就是', '任性', '不过', '素颜', '状态', '女神', '肌肤', '依然', '这么', '真让人', '羡慕', '不光', '自拍照', '杂志', '封面', '素颜', '快来', '橘子', '君看', '最近', '唐嫣', '封面', '大片', '出炉', '服饰', '素雅', '妆容', '清秀', '裸妆', '尽显', '自然', '纯粹', '之美'], ['白色', '蕾丝', '优雅', '甜美', '八分', '偏分', '微卷', '长发', '更是', '女神', '范儿', '十足'], ['不同于', '以前', '精致', '妆容', '这次', '非常', '自然', '素雅', '裸妆', '淡淡的', '眉形', '唇色', '还有', '几乎', '没画', '眼妆', '卸下',  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









