








MobileNet模型是Google针对手机等嵌入式设备提出的一种轻量级的深层神经网络,其使用的核心思想便是depthwise separable convolution(深度可分离卷积)。
MobelNets-v1重点放在优化延迟(latency),兼顾模型大小。
一、“深度可分离卷积”(Mobilenet-v1提出)
假设某一网络卷积层,其卷积核大小为3×3,输入通道为16(下图中通道数为 3 3 3 作为示例),输出通道为32;
- 常规卷积操作是将32个3×3×16的卷积核作用于16通道的输入图像,则根据卷积层参数量计算公式,卷积计算+卷积参数量+卷积计量量,得到所需参数为
32
∗
(
3
∗
3
∗
16
+
1
)
=
4640
32*(3*3*16+1)= 4640
32∗(3∗3∗16+1)=4640个。

- 深度可分离卷积:若先用16个、大小为3×3的卷积核(331)作用于16个通道的输入图像,得到了16个特征图,在做融合操作之前,接着用32个大小为1×1的卷积核
(
1
∗
1
∗
16
)
(1*1*16)
(1∗1∗16) 遍历上述得到的16个特征图,根据卷积层参数计算公式,所需参数为
(
3
∗
3
∗
1
∗
16
+
16
)
+
(
1
∗
1
∗
16
∗
32
+
32
)
=
706
(3*3*1*16+16) + (1*1*16*32+32) = 706
(3∗3∗1∗16+16)+(1∗1∗16∗32+32)=706个。

上述即为深度可分离卷积的作用,通俗的讲,普通卷积层的特征提取与特征组合一次完成并输出,而深度可分离卷积将特征提取与特征组合分开进行:
- 先用厚度为1的 3 × 3 3×3 3×3 的卷积核(depthwise分层卷积;depthwise convolutions/深度卷积 );
- 再用 1 × 1 1×1 1×1 的卷积核(pointwise 卷积;pointwise convolutions/逐点卷积)调整通道数;
由此可以看出,深度可分离卷积可大大减少模型的参数,其具体结构如下图(左边为普通卷积层结构,右边为深度可分离卷积结构):
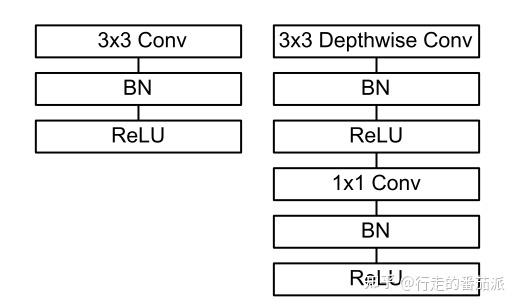
- 在进行 deepthwise(DW) 卷积时只使用了一种维度为in_channels的卷积核进行特征提取(没有进行特征组合);
- 在进行 pointwise(PW) 卷积时只使用了output_channels 种 维度为in_channels 1*1 的卷积核进行特征组合。
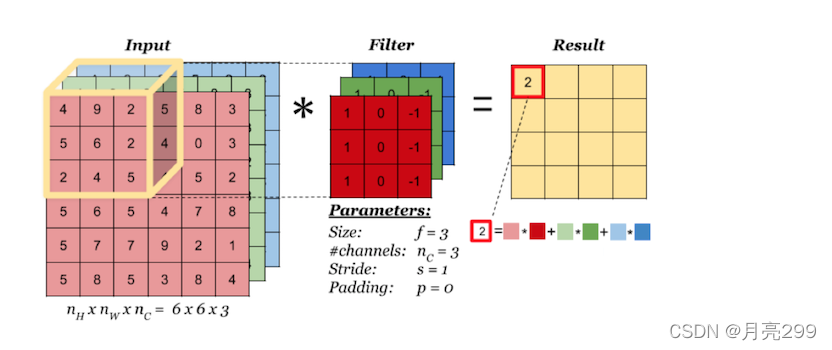
1、普通卷积
原理:普通卷积是,一个卷积核与input的所有通道都进行卷积,然后不同通道相同位置卷积后的结果再相加,如下图所示,:⾸先,每个通道内对应位置元素相乘再相加,最后计算所有通道的总和作为最终结果。卷积核的Channel通道数等于Input输⼊的通道数,Output输出的通道数等于卷积核的个数。
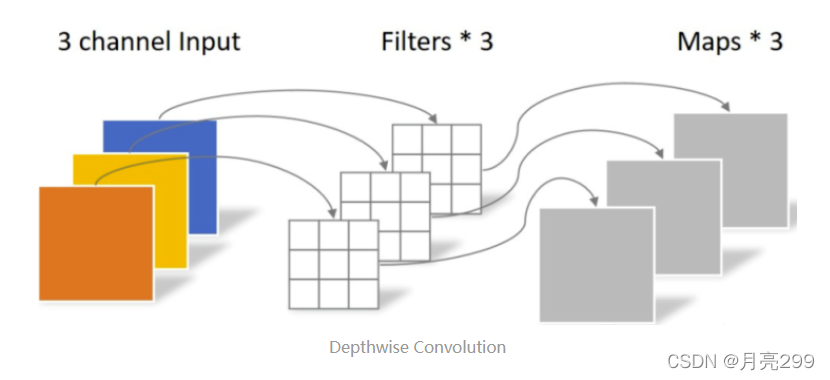
2、Depthwise 卷积
原理:Depthwise 卷积的一个卷积核只负责一个通道,一个卷积核只与一个通道卷积。那么卷积核数需要与输入的通道数相等,输出的通道数也不变,等于输入的通道数,等于卷积核数。所以depthwise卷积只改变特征图的大小,不改变通道数。但这种运算对输入层的每个通道独立进行卷积运算,没有有效的利用不同通道在相同空间位置上的feature信息。
depthwise卷积,只改变feature map的大小,不改变通道数。
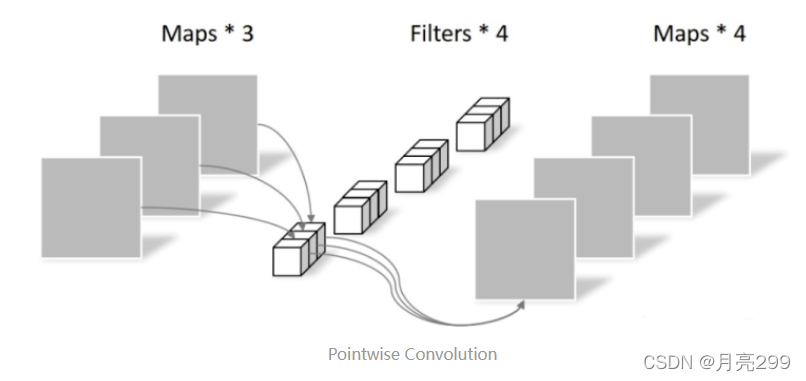
3、Pointwise卷积
Pointwise Convolution的运算与常规卷积运算相似,它的卷积核的尺寸为 1×1×M,M为上一层的通道数。所以这里的卷积运算会将上一步的map在深度方向上进行加权组合,生成新的Feature map。有几个卷积核就有几个输出Feature map。
Pointwise卷积,不改变feature map的大小,只改变通道数。
4、Depthwise separable convolution(深度可分离卷积)
深度可分离卷积depthwise separable convolution,由depthwise(DW)和pointwise(PW)结合起来组成。相比常规的卷积操作,其参数数量和运算成本比较低。轻量化模型中常用,例如MobileNet
二、Pytorch中实现“深度可分离卷积”:Pytorch 中 nn.Conv2d 的 groups 参数
Shape:
- Input: :math: ( N , C i n , H i n , W i n ) (N, C_{in}, H_{in}, W_{in}) (N,Cin,Hin,Win) or :math: ( C i n , H i n , W i n ) (C_{in}, H_{in}, W_{in}) (Cin,Hin,Win)
- Output: :math: ( N , C o u t , H o u t , W o u t ) (N, C_{out}, H_{out}, W_{out}) (N,Cout,Hout,Wout) or :math: ( C o u t , H o u t , W o u t ) (C_{out}, H_{out}, W_{out}) (Cout,Hout,Wout),
其中:
H
o
u
t
=
⌊
H
i
n
+
2
×
padding
[
0
]
−
dilation
[
0
]
×
(
kernel_size
[
0
]
−
1
)
−
1
stride
[
0
]
+
1
⌋
H_{out} = \left\lfloor\frac{H_{in} + 2 \times \text{padding}[0] - \text{dilation}[0] \times (\text{kernel\_size}[0] - 1) - 1}{\text{stride}[0]} + 1\right\rfloor
Hout=⌊stride[0]Hin+2×padding[0]−dilation[0]×(kernel_size[0]−1)−1+1⌋
W o u t = ⌊ W i n + 2 × padding [ 1 ] − dilation [ 1 ] × ( kernel_size [ 1 ] − 1 ) − 1 stride [ 1 ] + 1 ⌋ W_{out} = \left\lfloor\frac{W_{in} + 2 \times \text{padding}[1] - \text{dilation}[1] \times (\text{kernel\_size}[1] - 1) - 1}{\text{stride}[1]} + 1\right\rfloor Wout=⌊stride[1]Win+2×padding[1]−dilation[1]×(kernel_size[1]−1)−1+1⌋
class Conv2d(_ConvNd):
__doc__ = r"""Applies a 2D convolution over an input signal composed of several input
planes.
In the simplest case, the output value of the layer with input size
:math:`(N, C_{\text{in}}, H, W)` and output :math:`(N, C_{\text{out}}, H_{\text{out}}, W_{\text{out}})`
can be precisely described as:
.. math::
\text{out}(N_i, C_{\text{out}_j}) = \text{bias}(C_{\text{out}_j}) +
\sum_{k = 0}^{C_{\text{in}} - 1} \text{weight}(C_{\text{out}_j}, k) \star \text{input}(N_i, k)
where :math:`\star` is the valid 2D `cross-correlation`_ operator,
:math:`N` is a batch size, :math:`C` denotes a number of channels,
:math:`H` is a height of input planes in pixels, and :math:`W` is
width in pixels.
""" + r"""
This module supports :ref:`TensorFloat32<tf32_on_ampere>`.
* :attr:`stride` controls the stride for the cross-correlation, a single
number or a tuple.
* :attr:`padding` controls the amount of padding applied to the input. It
can be either a string {{'valid', 'same'}} or a tuple of ints giving the
amount of implicit padding applied on both sides.
* :attr:`dilation` controls the spacing between the kernel points; also
known as the à trous algorithm. It is harder to describe, but this `link`_
has a nice visualization of what :attr:`dilation` does.
{groups_note}
The parameters :attr:`kernel_size`, :attr:`stride`, :attr:`padding`, :attr:`dilation` can either be:
- a single ``int`` -- in which case the same value is used for the height and width dimension
- a ``tuple`` of two ints -- in which case, the first `int` is used for the height dimension,
and the second `int` for the width dimension
Note:
{depthwise_separable_note}
Note:
{cudnn_reproducibility_note}
Note:
``padding='valid'`` is the same as no padding. ``padding='same'`` pads
the input so the output has the shape as the input. However, this mode
doesn't support any stride values other than 1.
Args:
in_channels (int): Number of channels in the input image
out_channels (int): Number of channels produced by the convolution
kernel_size (int or tuple): Size of the convolving kernel
stride (int or tuple, optional): Stride of the convolution. Default: 1
padding (int, tuple or str, optional): Padding added to all four sides of
the input. Default: 0
padding_mode (string, optional): ``'zeros'``, ``'reflect'``,
``'replicate'`` or ``'circular'``. Default: ``'zeros'``
dilation (int or tuple, optional): Spacing between kernel elements. Default: 1
groups (int, optional): Number of blocked connections from input
channels to output channels. Default: 1
bias (bool, optional): If ``True``, adds a learnable bias to the
output. Default: ``True``
""".format(**reproducibility_notes, **convolution_notes) + r"""
Shape:
- Input: :math:`(N, C_{in}, H_{in}, W_{in})` or :math:`(C_{in}, H_{in}, W_{in})`
- Output: :math:`(N, C_{out}, H_{out}, W_{out})` or :math:`(C_{out}, H_{out}, W_{out})`, where
.. math::
H_{out} = \left\lfloor\frac{H_{in} + 2 \times \text{padding}[0] - \text{dilation}[0]
\times (\text{kernel\_size}[0] - 1) - 1}{\text{stride}[0]} + 1\right\rfloor
.. math::
W_{out} = \left\lfloor\frac{W_{in} + 2 \times \text{padding}[1] - \text{dilation}[1]
\times (\text{kernel\_size}[1] - 1) - 1}{\text{stride}[1]} + 1\right\rfloor
Attributes:
weight (Tensor): the learnable weights of the module of shape
:math:`(\text{out\_channels}, \frac{\text{in\_channels}}{\text{groups}},`
:math:`\text{kernel\_size[0]}, \text{kernel\_size[1]})`.
The values of these weights are sampled from
:math:`\mathcal{U}(-\sqrt{k}, \sqrt{k})` where
:math:`k = \frac{groups}{C_\text{in} * \prod_{i=0}^{1}\text{kernel\_size}[i]}`
bias (Tensor): the learnable bias of the module of shape
(out_channels). If :attr:`bias` is ``True``,
then the values of these weights are
sampled from :math:`\mathcal{U}(-\sqrt{k}, \sqrt{k})` where
:math:`k = \frac{groups}{C_\text{in} * \prod_{i=0}^{1}\text{kernel\_size}[i]}`
Examples:
>>> # With square kernels and equal stride
>>> m = nn.Conv2d(16, 33, 3, stride=2)
>>> # non-square kernels and unequal stride and with padding
>>> m = nn.Conv2d(16, 33, (3, 5), stride=(2, 1), padding=(4, 2))
>>> # non-square kernels and unequal stride and with padding and dilation
>>> m = nn.Conv2d(16, 33, (3, 5), stride=(2, 1), padding=(4, 2), dilation=(3, 1))
>>> input = torch.randn(20, 16, 50, 100)
>>> output = m(input)
.. _cross-correlation:
https://en.wikipedia.org/wiki/Cross-correlation
.. _link:
https://github.com/vdumoulin/conv_arithmetic/blob/master/README.md
"""
def __init__(
self,
in_channels: int,
out_channels: int,
kernel_size: _size_2_t,
stride: _size_2_t = 1,
padding: Union[str, _size_2_t] = 0,
dilation: _size_2_t = 1,
groups: int = 1,
bias: bool = True,
padding_mode: str = 'zeros', # TODO: refine this type
device=None,
dtype=None
) -> None:
factory_kwargs = {'device': device, 'dtype': dtype}
kernel_size_ = _pair(kernel_size)
stride_ = _pair(stride)
padding_ = padding if isinstance(padding, str) else _pair(padding)
dilation_ = _pair(dilation)
super(Conv2d, self).__init__(
in_channels, out_channels, kernel_size_, stride_, padding_, dilation_,
False, _pair(0), groups, bias, padding_mode, **factory_kwargs)
def _conv_forward(self, input: Tensor, weight: Tensor, bias: Optional[Tensor]):
if self.padding_mode != 'zeros':
return F.conv2d(F.pad(input, self._reversed_padding_repeated_twice, mode=self.padding_mode),
weight, bias, self.stride,
_pair(0), self.dilation, self.groups)
return F.conv2d(input, weight, bias, self.stride,
self.padding, self.dilation, self.groups)
def forward(self, input: Tensor) -> Tensor:
return self._conv_forward(input, self.weight, self.bias)
1、普通卷积
我们先来简单复习一下普通的卷积行为。
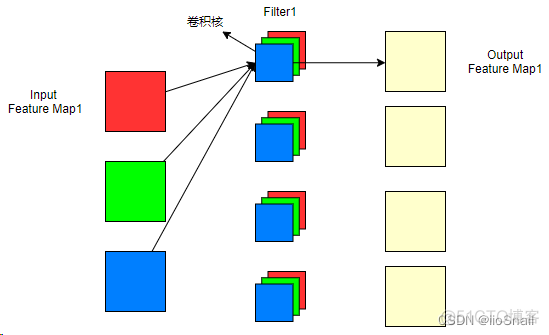
从上图可以看到,输入特征图为3,经过4个filter卷积后生成了4个输出特征图。对于普通的卷积操作,我们可以得到几个重要的结论:
- 输入通道数 = 每个filter的卷积核的个数。(注意区分卷积核和Filter,它们俩的关系是:多个卷积核组成一个Filter)
- Filter的个数 = 输出通道数
2、Groups是如何改变卷积方式的
那现在我们不想按照上面的方式,我想让一个Filter只负责一部分输入通道,例如:
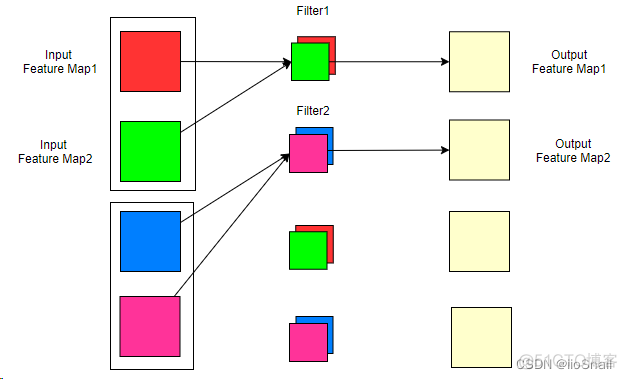
上图中,我们将输入通道分成了2组(也就是groups=2),每一组对应一个Filter,这样我们的参数量就下降了1倍。此时,我们还是有4个卷积核(因为有4个输出通道),但每个Filter只有2个卷积核,所以一个Filter只对2个输入通道进行卷积。
为了巩固,我们再举个例子:
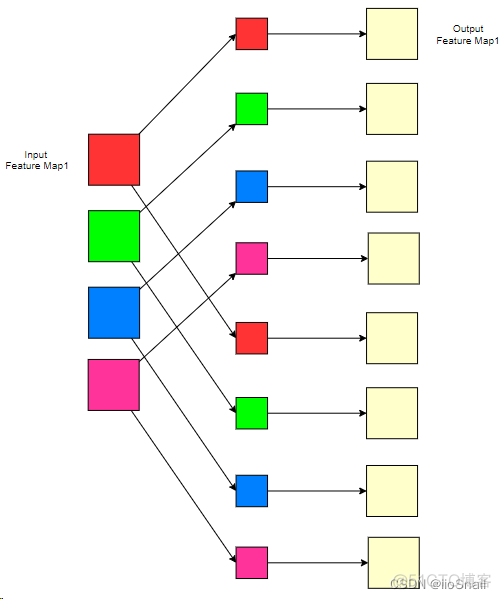
在该例子中,我们的输入通道为4,输出通道为8。这次我们将4个输入通道分成了4组,也就是groups=4,此时我们的每个Filter的卷积核数量就是1。
从上面两个例子,大家应该很清楚group的作用了,这里进行一个总结:
- Groups做的事情:将输入通道进行分组,groups的值就是具体分的组数。所以,in_channel ÷ groups 一定要是整数,要不然就没法分组了。每个Filter负责处理一组输入通道,所以Filter的卷积核数量也会随之改变,即每个Filter的卷积核数 = groups
- Groups的作用:减少计算量和参数量。
- Groups其他注意事项:输出通道 ÷ groups 也一定要是整数,要不然就会有几组没有Filter与之对应了。
综上,如果加入了groups,则卷积参数量的计算公式为:
参考资料:
Depthwise 卷积 ,Pointwise 卷积与普通卷积的区别
图解 Pytorch 中 nn.Conv2d 的 groups 参数
轻量化网络——MobileNet
深度学习在图像处理中的应用(tensorflow2.4以及pytorch1.10实现)
轻量级网络-Mobilenet系列(v1,v2,v3)
CNN模型合集 | 21 MobileNet V1/V2
网络解析(二):MobileNets详解
https://pytorch.org/docs/stable/generated/torch.nn.Conv2d.html
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









