







 超级会员免费看
超级会员免费看
 本文介绍了如何使用 CCNET 清洗 Common Crawl 的大规模数据集,包括预处理、去重、语言识别和质量筛选四个步骤。通过去重、语言识别和 perplexity 分数筛选,构建高质量的单语言数据集。该流程在 5000 CPU 核心上运行,针对 Common Crawl 的快照进行处理,为 NLP 领域提供有价值的预训练资源。
本文介绍了如何使用 CCNET 清洗 Common Crawl 的大规模数据集,包括预处理、去重、语言识别和质量筛选四个步骤。通过去重、语言识别和 perplexity 分数筛选,构建高质量的单语言数据集。该流程在 5000 CPU 核心上运行,针对 Common Crawl 的快照进行处理,为 NLP 领域提供有价值的预训练资源。
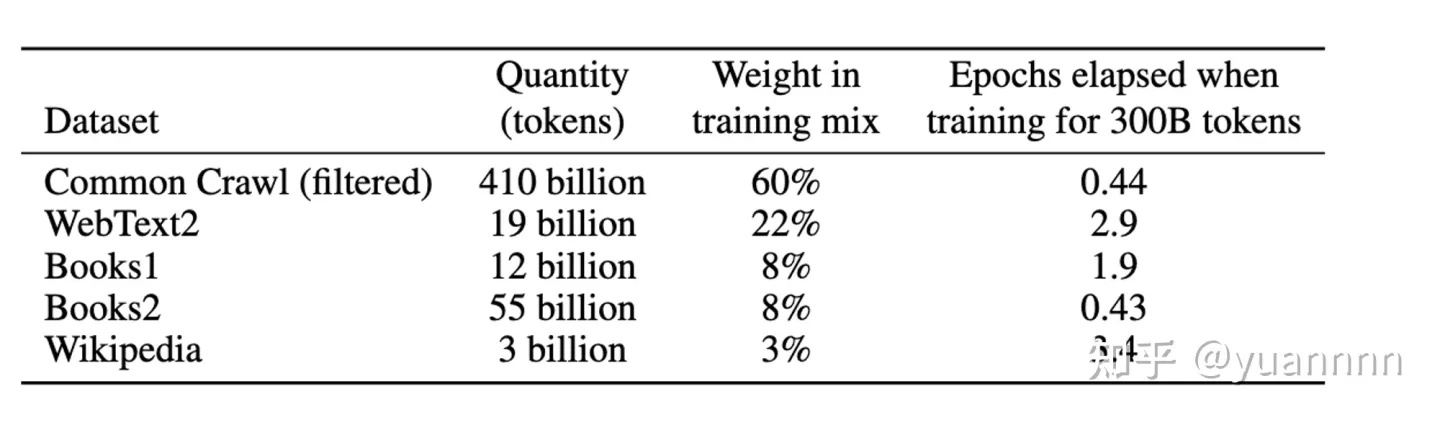
预训练的文本表征在 NLP 领域带来了非常大的影响,而预训练数据的文本质量和数量会十分影响预训练模型的效果。在 GPT-3 的训练中,Common Crawl 占了百分之六十(如下图所示),是一个非常重要的数据来源。
Common Crawl 是一个海量的、非结构化的、多语言的网页数据集。它包含了超过 8 年的网络爬虫数据集,包含原始网页数据(WARC)、元数据(WAT)和文本提取(WET),拥有PB级规模,可从 Amazon S3 上免费获取。
然而从网络上爬取下来的原始数据非常杂乱,因此这篇文章介绍一下 facebook 的一个工作,对 common crawl 的清洗策略,CCNET。
数据地址: http://commoncrawl.org/the-data/

 订阅专栏 解锁全文
订阅专栏 解锁全文


















 1687
1687

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









